|
1
Таблица 3.9-Показатели технической сложности для
рассматриваемой системы
|
Показатель
|
Вес
|
Значение
|
Значение
с учетом веса
|
|
T1
|
2
|
3
|
6
|
|
T2
|
1
|
2
|
2
|
|
T3
|
1
|
4
|
4
|
|
T4
|
1
|
4
|
4
|
|
T5
|
1
|
3
|
3
|
|
T6
|
0,5
|
3
|
1,5
|
|
T7
|
0,5
|
4
|
2
|
|
T8
|
2
|
1
|
2
|
|
T9
|
1
|
3
|
3
|
|
T10
|
1
|
3
|
3
|
|
T11
|
1
|
4
|
4
|
|
T12
|
1
|
4
|
4
|
|
T13
|
1
|
1
|
1
|
|
|
Сумма
|
39,5
|
Техническая сложность проекта информационной
системы вычисляется по формуле:
 (3.11) (3.11)
По формуле (3.11) получим:

В таблице 3.10 приведены показатели
уровня квалификации разработчиков.
Таблица 3.10-Показатели уровня квалификации
разработчиков
|
Показатель
|
Описание
|
Вес
|
|
F1
|
Знакомство
с технологией
|
1,5
|
|
F2
|
Опыт
разработки приложений
|
0,5
|
|
F3
|
Опыт
использования объектно-ориентированного подхода
|
1
|
|
F4
|
Наличие
ведущего аналитика
|
0,5
|
|
F5
|
Мотивация
|
1
|
|
F6
|
Стабильность
требований
|
2
|
|
F7
|
Частичная
занятость
|
-1
|
|
F8
|
Сложные
языки программирования
|
-1
|
Каждому показателю присваивается значение в
диапазоне от 0 до 5.
Для показателей F1 - F4: 0 означает отсутствие,
3 - средний уровень, 5 - высокий уровень.
Для показателя F5: 0 означает отсутствие
мотивации, 3 - средний уровень мотивации, 5 - высокий уровень мотивации.
Для показателя F6: 0 - это высокая
нестабильность требований, 3 - средняя нестабильность требований, 5 -
стабильные требования.
Для показателя F7: 0 означает отсутствие
специалистов с частичной занятостью, 3 - средний уровень, 5 - все специалисты с
частичной занятостью.
Для показателя F8: 0 - это простой язык
программирования, 3 - средняя сложность языка программирования, 5 - высокая
сложность языка программирования.
В таблице 3.11 представлены показатели уровня
квалификации разработчиков для разрабатываемой системы.
Таблица 3.11-Показатели уровня квалификации
разработчиков
|
Показатель
|
Вес
|
Значение
|
Значение
с учетом веса
|
|
F1
|
1,5
|
4
|
6
|
|
F2
|
0,5
|
4
|
2
|
|
F3
|
1
|
4
|
4
|
|
F4
|
0,5
|
3
|
1,5
|
|
F5
|
1
|
5
|
5
|
|
F6
|
2
|
4
|
8
|
|
F7
|
-1
|
2
|
-2
|
|
F8
|
-1
|
4
|
-4
|
|
|
Сумма
|
20,5
|
Уровень квалификации разработчиков вычисляется
по формуле:
 (3.12) (3.12)
По формуле (3.12) получим:

С учетом показателей технической
сложности (TCF) и уровня квалификации разработчиков (EF) окончательное значение
указателя вариантов использования (UCP) определяется по формуле:
 (3.13) (3.13)
По формуле (3.13) получим:

Для того чтобы пересчитать величину
UCP в человеко-часы необходимо определить количество человеко-часов,
приходящихся на одну UCP. Этот показатель зависит от принятой на предприятии
методики определения вариантов использования, квалификации разработчиков,
используемых инструментальных средств, накопленного опыта производства ПО.
Предполагается использовать 15
человеко-часов в качестве начального значения на один UCP. Отсюда,
общее количество человеко-часов на весь проект рассчитывается по формуле: 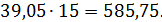
При сорокачасовой рабочей неделе -
это составляет 15 недель разработки с учетом того, что над проектом работает
один человек.
4. Разработка информационного
обеспечения системы
.1 Информационный анализ предметной
области и выделение информационных объектов
Для построения
информационно-логической модели данных был проведен информационный анализ
предметной области, а также выделены информационные объекты.
В таблице 4.1 представлен набор
информационных объектов, который был определен на основе анализа предметной
области и требований к разрабатываемой системе.
Таблица 4.1-Информационные объекты
|
Название
информационного объекта (ИО)
|
Обозначение
ИО
|
Семантика
ИО
|
|
Пользователи
|
User
|
Содержит
информацию о пользователях
|
|
Социальные
сети
|
SocialNetwork
|
Содержит
информацию о подключенных социальных сетях
|
|
Группы
|
Group
|
Содержит
информацию о подключенных группах
|
|
Данные
последнего сканирования пользователей
|
ScanLastPoint
|
Содержит
информацию о сканировании пользователей группы и о ее последнем состоянии
|
|
Данные
предыдущих
сканирований
пользователей
|
ScanPrevPoint
|
Содержит
информацию о данных предыдущего сканирования пользователей группы
|
|
Данные
сканирования публикаций
|
ScanPosts
|
Содержит
информацию о данных последнего сканирований постов
|
|
Данные
о сканировании последних публикаций
|
ScanPostPoint
|
Содержит
информацию о публикациях, созданных менее недели назад
|
|
Данные
о сканировании публикаций
|
ScanPostsData
|
Содержит
информацию о показателях публикаций, созданных более 2 недель назад
|
|
Расписание
публикаций
|
Schedule
|
Содержит
информацию о расписании публикаций
|
Представленные информационные объекты являются
документами, описывающими предметную область. На основании этих документов, а
также дополнительных сведений из описания предметной области необходимо
определить роль реквизитов, содержащихся в документах.
Каждый пользователь имеет свой порядковый номер,
от которого зависят почта и пароль.
Каждая подключенная социальная сеть имеет
идентификатор, от которого зависят имя и фотография страницы пользователя, ключ
доступа к социальной сети, идентификатор в социальной сети и пользователя, к
которой привязана страница.
Каждая группа также имеет свой номер. От него
зависят идентификатор, название и фотография станицы в социальной сети, а также
пользователь, который добавил эту группу.
Данные последнего сканирования группы зависят от
идентификатора группы и содержат информацию о времени предыдущего и следующего
сканирований, количестве онлайн пользователей и списке подписанных пользователе
на момент последнего сканирования.
Данные предыдущих сканирований групп зависят от
идентификатора группы и даты сканирования, от которых зависят количество онлайн
пользователей и списки отписавшихся и подписавшихся пользователей.
Данные сканирования публикаций зависят от группы
и содержат информацию о датах сканирования (начала, последнего и следующего).
Данные о сканировании последних публикаций
зависят от идентификатора группы, номера публикации в социальной сети и даты
сканирования, а также содержат информацию о показателях публикаций. Учитываются
публикации, созданные не более одной недели назад.
Данные о сканировании публикаций
идентифицируются хэш-суммой, от которой зависят идентификатор группы, время
публикации от начала недели и значения показателей публикаций.
Расписание публикаций зависит от номера группы,
и хранит настройки расписания, даты предыдущего и следующего анализа и время от
начала для публикаций.4.2 Построение логической модели данных
Для реквизитов, представленных в документах,
необходимо установить их функциональную зависимость. Функциональная зависимость
реквизитов представлена таблице 4.2.


После анализа предметной области с помощью
функциональных связей необходимо установить ключевые и описательные реквизиты.
Соответствие описательных и ключевых реквизитов представлено в таблице 4.3.
Таблица 4.3-Соответствие описательных и ключевых
реквизитов
|
Описательные
реквизиты
|
Ключевые
реквизиты
|
Вид
ключа
|
Имя
ИО, включающего реквизит
|
|
1
|
2
|
3
|
4
|
|
Пользователи
|
|
Email SocEmail Password
|
Id
|
П.У.
|
Пользователи
|
|
Социальные
сети
|
|
Uid Social Sid Main AccessToken
Name Photo
|
Id
|
П.У.
|
Социальные сети
|
|
Группы
|
|
Uid SocNetwork SocNetworkId Gid
Name Photo
|
Id
|
П.У.
|
Группы
|
|
Данные
последнего сканирования пользователей
|
|
UsersCount Online NextScan Updated
Users
|
Gid
|
П.У.
|
Данные
последнего сканирования пользователей
|
|
Данные
предыдущих
сканирований
пользователей
|
|
NewUsersCount LostUsersCount
Online NewUsers LostUsers
|
Gid Date
|
С.У.
|
Данные
предыдущих
сканирований
пользователей
|
|
Данные
сканирования публикаций
|
|
NextScan PrevScan StartScan
|
Gid
|
П.У.
|
Данные
сканирования публикаций
|
|
Данные
о сканировании последних публикаций
|
|
LikesCount RepostsCount
CommentsCount ViewsCount
|
Gid PostId Date
|
С.У.
|
Данные
о сканировании последних публикаций
|
|
1234
|
|
|
|
|
Данные
о сканировании публикаций
|
|
Gid Time LikesCount RepostsCount
CommentsCount ViewsCount
|
Hash
|
П.У.
|
Данные
о сканировании публикаций
|
|
Расписание
публикаций
|
|
PostsPerDay MinBetweenPosts
NextScan PrevScan Times
|
Gid
|
П.У.
|
Расписание
публикаций
|
В таблице 4.4. рассмотрены сгруппированные
реквизиты по информационным объектам.
Таблица 4.4-Соответствие описательных и ключевых
реквизитов
|
Реквизиты
|
Признак
ключа
|
Имя
ИО
|
Семантика
ИО
|
|
1
|
2
|
3
|
4
|
|
Документ
"Пользователи"
|
|
Id Email SocEmail Password
|
П.У.
|
Пользователи
|
Содержит
информацию о пользователях
|
|
Документ
"Социальные сети"
|
|
Id Uid Social Sid Main AccessToken
Name Photo
|
П.У.
|
Социальные
сети
|
Содержит
информацию о подключенных социальных сетях
|
|
Документ
"Группы"
|
|
Id Uid SocNetwork SocNetworkId Gid
Name Photo
|
П.У.
|
Группы
|
Содержит
информацию о подключенных группах
|
|
1
|
2
|
3
|
4
|
|
Документ
"Данные последнего сканирования пользователей"
|
|
Gid UsersCount Online NextScan
Updated Users
|
|
Данные
последнего сканирования пользователей
|
Содержит
информацию о сканировании групп
|
|
Документ
"Данные предыдущих сканирований пользователей"
|
|
Gid Date NewUsersCount
LostUsersCount Online NewUsers LostUsers
|
С.У.
|
Данные
предыдущих сканирований пользователей
|
Содержит
информацию о предыдущих результатах сканирования
|
|
Документ
"Данные сканирования публикаций"
|
|
Gid NextScan PrevScan StartScan
|
П.У.
|
Данные
сканирования публикаций
|
Содержит
информацию о датах сканирования (начала, предыдущего и следующего)
|
|
Документ
"Данные о сканировании последних публикаций"
|
|
Gid PostId Date LikesCount
RepostsCount CommentsCount ViewsCount
|
С.У.
|
Данные
о сканировании последних публикаций
|
Содержит
информацию о показателях публикаций в различные моменты времени
|
|
Документ
"Данные о сканировании публикаций"
|
|
Hash Gid Time LikesCount
RepostsCount CommentsCount ViewsCount
|
П.У.
|
Данные
о сканировании публикаций
|
Содержит
информацию о показателях публикаций, начиная с начала недели
|
|
Документ
"Расписание публикаций"
|
|
Gid PostsPerDay MinBetweenPosts
NextScan PrevScan Times
|
П.У.
|
Расписание
публикаций
|
Содержит
информацию расписании публикаций
|
После группировки реквизитов по информационным
объектам необходимо установить связи между ними. Типы связей между
информационными объектами представлены в таблице 4.5.
Таблица 4.5-Типы связей между информационными
объектами
|
Номер
связи отношений
|
Главный
ИО
|
Подчиненный
ИО
|
Тип
реального отношения
|
|
1
2 3 4 5 6 7 8
|
Пользователи
Пользователи Группы Группы Группы Группы Группы Группы
|
Социальные
сети Группы Данные последнего сканирования пользователей Данные предыдущих
сканирований пользователей Данные сканирования публикаций Данные о
сканировании последних публикаций Данные о сканировании публикаций Расписание
публикаций
|
1:M 1:M
1:M
1:M
1:M
1:M
1:M
1:M
|
Логическая модель описывает понятия предметной
области, их взаимосвязь, а также ограничения на данные, налагаемые предметной
областью. При построении логической модели используются три ее подуровня:
диаграмма сущность-связь, модель данных, основанная на ключах и полная
атрибутная модель.
Диаграмма сущность-связь включает сущности и
взаимосвязи, отражающие основные бизнес-правила предметной области. Такая
диаграмма не слишком детализирована, в нее включаются основные сущности и связи
между ними, которые удовлетворяют основным требованиям, предъявленным к
информационной системе [15]. Диаграмма сущность-связь представлена на рисунке
4.1.

Рисунок 4.1-Диаграмма сущность-связь
Модель данных, основанная на ключах - это
логическая модель, включающая описание всех сущностей и ключевых атрибутов,
которые соответствуют предметной области. Целью этой модели является дальнейшая
детализация модели сущность-связь и идентификация сущностей путем выбора
ключевых атрибутов [16]. Модель данных, основанная на ключах, представлена на
рисунке 4.2.

Рисунок 4.2-Модель данных, основанная на ключах
Полная атрибутивная модель включает в себя все
сущности, атрибуты и является наиболее детальным представлением структуры
данных. Эта модель представляет данные в третьей нормальной форме [15]. Полная
атрибутивная модель представлена на рисунке 4.3.

Рисунок 4.3-Полная атрибутивная модель
.3 Описание таблиц базы данных
При описании таблиц базы данных необходимо
учесть наименование и обозначение атрибутов, признак ключа и формат поля. В
таблице 4.6 представлено полное описание таблиц базы данных.
Таблица 4.6-Описание таблиц реляционной базы
данных
|
Атрибут
|
Признак
ключа
|
Формат
поля
|
|
|
Обозначение
|
Наименование
|
|
Тип
|
Длина
|
Точность
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
|
|
ИО
"Пользователи"
|
|
Id
|
П.У.
|
Числовой
|
11
|
0
|
|
|
Email
|
Email-адрес
|
|
Строка
|
70
|
|
|
|
SocEmail
|
Email-адрес,
полученный из социальной сети
|
|
Строка
|
70
|
|
|
|
Password
|
Пароль
|
|
Строка
|
255
|
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
|
|
ИО
"Социальные сети"
|
|
Id
|
Идентификатор
|
П.У.
|
Числовой
|
11
|
0
|
|
|
Uid
|
Идентификатор
пользователя
|
|
Числовой
|
11
|
0
|
|
|
Social
|
Социальная
сеть
|
|
Строка
|
2
|
|
|
|
Sid
|
Идентификатор
пользователя в социальной сети
|
|
Строка
|
20
|
|
|
|
Main
|
Используется
для авторизации
|
|
Числовой
|
1
|
0
|
|
|
AccessToken
|
Ключ
для работы с социальной сетью
|
|
Строка
|
150
|
|
|
|
Name
|
Имя
страницы
|
|
Строка
|
100
|
|
|
|
Photo
|
Фото
страницы
|
|
Строка
|
150
|
|
|
|
ИО
"Группы"
|
|
Id
|
Идентификатор
|
П.У.
|
Числовой
|
11
|
0
|
|
|
Uid
|
Идентификатор
пользователя
|
|
Числовой
|
11
|
0
|
|
|
SocNetwork
|
Социальная
сеть
|
|
Строка
|
2
|
|
|
|
SocNetworkId
|
Идентификатор
страницы владельца
|
|
Числовой
|
11
|
0
|
|
|
Gid
|
Идентификатор
группы в социальной сети
|
|
Строка
|
20
|
|
|
|
Name
|
Название
группы
|
|
Строка
|
100
|
|
|
|
Photo
|
Ссылка
на изображение
|
|
Строка
|
150
|
|
|
|
ИО
"Данные последнего сканирования пользователей"
|
|
Gid
|
Идентификатор
группы
|
П.У.
|
Числовой
|
11
|
0
|
|
|
UsersCount
|
Количество
подписанных пользователей
|
|
Числовой
|
11
|
0
|
|
|
Online
|
Количество
онлайн пользователей
|
|
Числовой
|
11
|
0
|
|
|
NextScan
|
Дата
следующего сканирования
|
|
Дата/время
|
|
|
|
|
Updated
|
Дата
последнего сканирования
|
|
Дата/время
|
|
|
|
|
Users
|
Список
идентификаторов подписанных пользователей
|
|
Массив
строк
|
|
|
|
|
ИО
"Данные предыдущих сканирований пользователей"
|
|
Gid
|
Идентификатор
группы
|
С.У.
|
Числовой
|
11
|
0
|
|
|
Date
|
Дата
сканирования
|
|
|
|
|
|
|
NewUsersCount
|
Количество
подписавшихся пользователей
|
|
Числовой
|
11
|
0
|
|
|
LostUsersCount
|
Количество
отписавшихся пользователе
|
|
Числовой
|
11
|
0
|
|
|
Online
|
Количество
онлайн пользователей
|
|
Числовой
|
11
|
0
|
|
|
NewUsers
|
Список
идентификаторов подписавшихся пользователей
|
|
Массив
строк
|
|
|
|
|
LostUsers
|
Список
идентификаторов отписавшихся пользователей
|
|
Массив
строк
|
|
|
|
|
1
|
2
|
3
|
4
|
5
|
6
|
|
|
ИО
"Данные сканирования публикаций"
|
|
Gid
|
Идентификатор
группы
|
П.У.
|
Числовой
|
11
|
0
|
|
|
NextScan
|
Дата
следующего сканирования
|
|
Дата/время
|
|
|
|
|
PrevScan
|
Дата
предыдущего сканирования
|
|
Дата/время
|
|
|
|
|
StartScan
|
Дата
начала сканирования
|
|
Дата/время
|
|
|
|
|
ИО
"Данные о сканировании последних публикаций"
|
|
Gid
|
Идентификатор
группы
|
С.У.
|
Числовой
|
11
|
0
|
|
|
PostId
|
Идентификатор
публикации в социальной сети
|
|
Строка
|
30
|
|
|
|
Date
|
Дата
сканирования
|
|
Дата/время
|
|
|
|
|
LikesCount
|
Количество
"лайков"
|
|
Числовой
|
11
|
0
|
|
|
RepostsCount
|
Количество
"репостов"
|
|
Числовой
|
11
|
0
|
|
|
Comments-Count
|
Количество
"комментариев"
|
|
Числовой
|
11
|
0
|
|
|
ViewsCount
|
Количество
"просмотров"
|
|
Числовой
|
11
|
0
|
|
|
ИО
"Данные о сканировании публикаций"
|
|
Hash
|
Хэш-сумма
|
П.У.
|
Строка
|
200
|
|
|
|
Gid
|
Идентификатор
группы
|
|
Числовой
|
11
|
0
|
|
|
Time
|
Время
от начала недели
|
|
Время
|
|
|
|
|
LikesCount
|
Список
показателей "лайки"
|
|
Массив
чисел
|
|
|
|
|
RepostsCount
|
Список
показателей "репосты"
|
|
Массив
чисел
|
|
|
|
|
Comments-Count
|
Список
показателей "комментарии"
|
|
Массив
чисел
|
|
|
|
|
ViewsCount
|
Список
показателей "просмотры"
|
|
Массив
чисел
|
|
|
|
|
ИО
"Расписание публикаций"
|
|
Gid
|
Идентификатор
группы
|
П.У.
|
Числовой
|
11
|
0
|
|
|
PostsPerDay
|
Количество
публикаций в сутки
|
|
Числовой
|
3
|
0
|
|
|
MinBetweenPosts
|
Минимальное
время между публикациями
|
|
Числовой
|
3
|
0
|
|
|
NextScan
|
Дата
следующего анализа
|
|
Дата/время
|
|
|
|
|
PrevScan
|
Дата
предыдущего анализа
|
|
Дата/время
|
|
|
|
|
Times
|
Список
точек времени от начала недели
|
|
Массив
чисел
|
|
|
|
5. Разработка программного
обеспечения системы
.1 Описание программных средств
Выбор программных средств при разработке зависит
от технологий, которые будут использоваться в программе. Для реализации web-API
желательно использование компилируемого кроссплатформенного языке со строгой
типизацией. Для этого подойдет универсальная платформа разработки.Net
Core и язык
программирования C#. Для разработки на этом языке программирования
использовался программное средство Microsoft
Visual Studio.
Microsoft
Visual Studio является мощнейшей интегрированной средой разработки, включающей
в себя редактор исходного кода, возможности рефакторинга кода, встроенный
отладчик, веб-редактор, редактор форм и дизайнер схемы баз данных. На данном
программном продукте можно разрабатывать как консольные приложения, так и
приложения с графическим интерфейсом, а также web-сайты
и - приложения. Редактор позволяет использовать языки программирования C#,
C++, Visual
Basic, F#
и TypeScript.
Для реализации web-приложения
желательно использовать привычные для их разработки языки программирования PHP
и JavaScript. Т.к. в
стандартном JavaScript
не реализованы правила строгой типизации и традиционного
объектно-ориентированного подхода, то для его замены можно взять язык
программирования TypeScript.
Этот язык разработан компанией Microsoft,
позиционируемый как средство разработки web-приложений, расширяющий возможности
JavaScript. TypeScript является обратно совместимым с JavaScript и
компилируется в последний. Для разработки на языках программирования PHP
и TypeScript использовались
программные средства JetBrains
PhpStorm и Visual
Studio Code
соответственно.
JetBrains
PhpStorm представляет собой
интегрированную среду разработки web-приложений
на языке PHP.
Особенностью данного программного средства является встроенный интеллектуальный
редактор для HTML, CSS,
PHP и JavaScript, с
возможностью анализа кода, автоматизированными средствами рефакторинга кода и
автодополнением кода программы. PhpStorm
разработан на основе платформы IntelliJ
IDEA, что позволяет
устанавливать дополнительные сторонние плагины при работе с программой.Studio
Code представляет собой простой редактор исходного кода для кроссплатформенной
разработки web-приложений. Программа разработана компанией Microsoft и является
бесплатной с открытым исходным кодом. В редакторе имеется встроенный отладчик,
средства рефакторинга, автодополнение, а также удобные инструменты для работы с
Git. Основные языки и технологии, поддерживаемые программой: JavaScript,
TypeScript, C#, PHP, Docker, HTML, CSS.
Для автоматизации развертывания программного
средства и удобного тестирования при разработке используется программное
обеспечение Docker. С помощью
данного программного средства можно собрать приложение со всеми зависимостями в
контейнер, который может быть запущен на любой операционной системе,
поддерживающей программное обеспечение Docker.
В качестве СУБД используются MySQL
и Tarantool. MySQL
- бесплатная кроссплатформенная реляционная СУБД. Она необходима для хранения
данных, таких как пользователь, список подключенных групп и другие. Tarantool
- бесплатная NoSQL СУБД,
которая может хранить часть данных в оперативной памяти для более быстрого
доступа. В случае переполнения лимита памяти, данные помещаются на жесткий диск
и при необходимости оттуда загружаются в оперативную память. Tarantool
используется для хранения данных большего объема. К таким данным относятся:
результаты сканирования списка пользователей, результаты сканирования
публикаций и другие.
Для администрирования СУБД MySQL
используется программное обеспечение HeidiSQL.
Оно является бесплатным и позволяет работать с СУБД через SSH-туннель.
Данное программное средство поддерживает такие СУБД, как MySQL,
Microsoft
SQL Server
и PostgreSQL.
Для ведения истории разработки и управления
версиями используется программное средство Git.
5.2 Алгоритм решения задачи
В ходе проектирования автоматизированной системы
была разработана структурная схема автоматизированной системы для анализа групп
в социальных сетях и выбора оптимального расписания для публикаций. Схема
приведена на рисунке 5.1.

Рисунок 5.1-Структурная схема программного
обеспечения системы
Модульное программирование является одним из
способов программирования, при котором вся программа разбивается на группу
компонентов, называемых модулями. Каждый из них имеет свой контролируемый размер,
четкое назначение и детально проработанный интерфейс с внешней средой.
Схема состоит из 11 модулей и базы данных.
Модуль Web-API
реализует набор правил для взаимодействия с системой, с помощью которых внешние
приложения смогут получать необходимые данные.
Модуль взаимодействия с социальными сетями
используется для реализации взаимодействия в целом. При обращении к социальной
сети этот модуль переводит процесс управления на модуль взаимодействия с
соответствующей социальной сетью.
Для каждой социальной сети необходим свой модуль
взаимодействия, который будет реализовывать необходимые функции: получение
списка групп пользователя, получение информации о пользователях, состоящих в
группе, получение информации о публикациях в группе и другие.
Модуль сбора данных запускает сканирование групп
с некоторой периодичностью и собирает данные. Затем данные поступают в модуль
анализа, и часть данных сохраняется в базе данных. Блок-схема алгоритма анализа
данных представлена на рисунке 5.2.

Рисунок 5.2-Блок-схема алгоритма анализа данных
Сначала производится исследование показателя
"Количество онлайн пользователей" методом корреляционного анализа.
Далее аналогичная операция производится над
показателями публикаций: "Лайки", "Репосты",
"Комментарии" и "Просмотры".
На следующем этапе производится проверка того,
что хотя бы один из показателей функционально зависит от времени, т.е., по
крайней мере, один показатель можно использовать для дальнейшего анализа. Если
условие неверно, то попытка сканирования этой группы будет произведена снова
через час. Если условие верно, то для показателей публикаций, функционально
зависимых от времени, выполняется определение показателя
"Виральность". Если ни один из показателей публикаций функционально
не зависит от времени, то показатель "Виральность" является функцией
от нуля:
 . (5.1) . (5.1)
Далее при условии, что показатель
"Онлайн" функционально зависим от времени, выполняется его исследование
методом временных рядов и прогнозирование на ближайшие семь дней для
составления расписания. Иначе, если показатель функционально не зависит от
времени, то значение на всем промежутке семи дней становится равным нулю.
Затем аналогичное исследование
выполняется для показателя "Виральность".
На следующем этапе устанавливается
функциональная зависимость показателя "Эффективность публикации" от
показателей "Онлайн" и "Виральность" на прогнозируемом
промежутке семи дней методом регрессионного анализа.
После этого выполняется сохранение
полученных результатов в базе данных и завершение анализа. Следующий анализ
группы будет выполняться через шесть часов.
Регрессионный анализ подразумевает
вычисление функции некоторого параметра по одному или нескольким независимым
переменным с соответствующими коэффициентами. Так для показателя
"Виральность" экспериментально была выбрана следующая зависимость:
 , (5.2) , (5.2)
где Y(t) - значение
показателя "Виральность" в момент времени t, L(t) -
"Лайки", R(t) -
"Репосты", C(t) -
"Комментарии", V(t) -
"Просмотры". Для показателя "Эффективности публикации"
выбрана следующая зависимость:
 , (5.3) , (5.3)
где E(t) - значение
показателя "Эффективность публикации" в момент времени t, Y(t) -
"Виральность", O(t) -
"Онлайн".
Метод корреляционного анализа
подразумевает проверку существования функциональной зависимости исследуемого
параметра от времени. Блок-схема алгоритма анализа данных методом
корреляционного анализа представлена на рисунке 5.3.
Сначала выполняется вычисление
линейного коэффициента корреляции Пирсона. После этого проверяется условие
того, что коэффициент корреляции отличен от нуля. Если условие неверно, то
функция возвращает отрицательный результат. Иначе производится вычисление
средней ошибки и выполняется проверка, что коэффициент корреляции в три раза
больше своей ошибки. Если условие неверно, то функция возвращает отрицательный
результат.
Иначе проверяем гипотезу о том, что
коэффициент корреляции значимо отличается от нуля (то есть существует
взаимосвязь между величинами). Для этого рассчитывается значение тестовой
статистики и проверяется условие о том, что оно больше табличного значения
коэффициента Стьюдента t(0,95, ∞), равного 1,96. Если
условие неверно, то функция возвращает отрицательный результат. Иначе функция
возвращает положительный результат.
Если функция вернула положительный
результат, то исследуемый параметр функционально зависим от времени.

Рисунок 5.3-Блок-схема алгоритма анализа данных
методом корреляционного анализа
Метод анализа временных рядов необходим для сглаживания
ряда и прогнозирования будущих значений. Блок-схема алгоритма анализа данных
методом временных рядов представлена на рисунке 5.4.

Рисунок 5.4-Блок-схема алгоритма анализа данных
методом временных рядов
Вначале необходимо разбить данные на равные
интервалы времени. Далее выполняется вычисление порядка авторегрессии.
Минимальным порядком является единица, максимальным - половина количества
факторов, но не более 128.
После этого производится расчет значения показателя
на каждые 15 минут в течение семи дней. Для каждого расчета показателя в первую
очередь рассчитывается белый шум, как ряд случайных чисел. Так же
рассчитываются коэффициенты, показывающие влияние предыдущих факторов.
После расчета необходимого числа точек функция
возвращает полученный результат прогнозирования.
5.3 Тестирование и оценка надежности
программного продукта
Тестирование выполняется исходя из
предположения, что у некоторого пользователя подключены группы с
идентификаторами 3, 4 и 8, а также пользователь имеет ключ доступа
"a4112sfda".
.3.1 Структурное тестирование
В качестве способа структурного тестирования был
выбран способ тестирования базового пути. Для этого рассматривается Функция
отключения группы. Это один из методов API.
При выполнении запроса, в параметрах должны быть access_token
(ключ доступа пользователя) и id
(идентификатор группы, которой нужно удалить). Функция отключения группы
представлена ниже.
|
№ п.п.
|
Текст функции
|
|
1
|
public async Task<object>
Remove(Models.Api.DefaultRequest query, int? id)
|
|
1
|
{
|
|
1
|
SetCrossDomain();
|
|
1
|
query.SetDBContext(dbContext);
|
|
1
|
if
(!await query.CheckAccess())
|
|
2
|
{
|
|
2
|
return new ApiResults().ErrorResult(ApiResults.Action.Api,
"access_token_invalid");
|
|
2
|
}
|
|
3
|
var group =
dbContext.Groups.Where(g => g.Id == id && g.Uid ==
query.GetUserId()).FirstOrDefault();
|
|
3
|
if
(group == null)
|
|
4
|
{
|
|
4
|
return new
ApiResults().ErrorResult(ApiResults.Action.Api, "group_not_found");
|
|
4
|
}
|
|
5
|
dbContext.Groups.Remove(group);
|
|
5
|
if
(await dbContext.SaveChangesAsync() == 0)
|
|
6
|
{
|
|
6
|
return new
ApiResults().ErrorResult(ApiResults.Action.Api,
"error_saving_data");
|
|
6
|
}
|
|
7
|
var scanLastPoint =
dbContext.ScanLastPoint.Where(s => s.Gid == id).FirstOrDefault();
|
|
7
|
if (scanLastPoint != null
&& scanLastPoint.Gid == id)
|
|
8
|
{
|
await scanLastPoint.ClearTable();
|
|
8
|
}
|
|
9
|
foreach (var scanPrevPoint in
dbContext.ScanPrevPoint.Where(s => s.Gid == id))
|
|
10
|
{
|
|
10
|
await scanPrevPoint.ClearTable();
|
|
10
|
}
|
|
11
|
dbContext.ScanPosts.RemoveRange(dbContext.ScanPosts.Where(s
=> s.Gid == id));
|
|
11
|
dbContext.Schedules.Remove(new
Schedule() { Gid = (int)id });
|
|
11
|
var gid = (uint)id;
|
|
11
|
await
ScanPostPoint.ClearTable(gid);
|
|
11
|
await
ScanPostsData.ClearTable(gid);
|
|
11
|
await Schedule.ClearTable(gid);
|
|
11
|
await
ScheduleGraph.ClearTable(gid);
|
|
11
|
await
dbContext.SaveChangesAsync();
|
|
12
|
return
new ApiResults().SuccessResult();
|
|
13
|
}
|
Затем используется потоковый граф для
представления программы. Потоковый граф программы представлен на рисунке 5.5.

Рисунок 5.5-Потоковый граф программы
Затем рассчитывается цикломатическая сложность я
тремя способами.
Первый способ предполагает, что цикломатическая
сложность равна количеству регионов потокового графа:
 (5.4) (5.4)
Используя формулу (5.4) получается:

Во втором способе цикломатическая
сложность может быть вычислена по формуле:
 (5.5) (5.5)
где E - количество дуг, а N - количество узлов
потокового графа.
По формуле (5.5) получается:

В третьем способе цикломатическая сложность рассчитывается
по формуле:
 (5.6) (5.6)
где p - количество предикатных
вершин в потоковом графе G.
По формуле (5.6) получается:

После того, как цикломатическая
сложность вычислена, необходимо построить маршруты:
1) 1-2-13
) 1-3-4-13
) 1-3-5-6-13
) 1-3-5-7-9-11-12-13
) 1-3-5-7-8-9-10-9-10-9-10-9-11-12-13
) 1-3-5-7-8-9-10-9-10-9-10-9-10-9-10-9-11-12-13
)
1-3-5-7-8-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-11-12-13
)
1-3-5-7-8-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-11-12-13
)
1-3-5-7-8-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-10-9-11-12-13
Теперь необходимо построить тестовые варианты:
1) ИД:
access_token = null,= 3
Ож Рез: ошибка с сообщением "ключ доступа
не действителен";
2) ИД:
access_token = "a4112sfda"= null
Ож Рез: ошибка с сообщением "необходимо
задать параметр id";
3) ИД:
access_token = "a4112sfda"= 5
Ож Рез: ошибка с сообщением "группа не найдена";
4) ИД:
access_token = "a4112sfda"= 3
Ож Рез: сообщение "группа успешно
отключена".
.3.2 Функциональное тестирование
Функциональное тестирование было проведено с
помощью метода эквивалентных разбиений. Классы эквивалентности представлены в
таблице 5.1.
Таблица 5.1-Классы эквивалентности
|
Показатель
|
Правильный
класс эквивалентности
|
Неправильный
класс эквивалентности
|
|
Идентификатор
подключенной группы
|
Числа
3, 4, 8
|
Числа,
отличные от 3, 4, 8
|
|
Ключ
доступа
|
Строка
"a4112sfda"
|
Строка,
отличная от a4112sfda"
|
|
Количество
публикаций в сутки
|
Числа
от 10 до 50
|
Числа
меньше 10, больше 50
|
|
Минимальное
время между публикациями
|
Числа
от 10 до 60
|
Числа
меньше 10, больше 60
|
Для проверки правильности предположения о
поведении программы при столкновении с определенным классом эквивалентности
нужно представить тестовые наборы, которые соответствуют каждому классу.
Тестовые наборы включают в себя название
показателя, которому соответствуют классы эквивалентности, входные данные для
тестирования, предполагаемый результат и результат, полученные в ходе
непосредственного тестирования программы. Результат тестирования считается
положительным, если получен предполагаемый результат. Классы эквивалентности
представлены в таблице 5.2.
Таблица 5.2-Классы эквивалентности
|
Показатель
|
Входные
данные для тестирования
|
Предполагаемый
результат
|
Результат
тестирования
|
|
Идентификатор
подключенной группы
|
3
|
Разрешается
выполнять действия над группой
|
+
|
|
Идентификатор
подключенной группы
|
5
|
Сообщение
"группа не подключена"
|
+
|
|
Ключ
доступа
|
a4112sfda
|
Разрешается
выполнять действия
|
+
|
|
Ключ
доступа
|
asf455yhf3
|
Сообщение
"ключ доступа не действителен"
|
+
|
|
Количество
публикаций в сутки
|
25
|
Сохраняется
указанное значение
|
+
|
|
Количество
публикаций в сутки
|
91
|
Сообщение
"значение должно быть от 10 до 50"
|
+
|
|
Минимальное
время между публикациями
|
30
|
Сохраняется
указанное значение
|
+
|
|
Минимальное
время между публикациями
|
5
|
Сообщение
"значение должно быть от 10 до 60"
|
+
|
.3.3 Оценка надежности программного
средства
Для оценки надежности программного средства была
применена модель Коркорэна. В данной модели не используются параметры времени
тестирования, а учитывается только результат N испытаний, в которых выявлено Ni
ошибок i-го типа.
По этой модели оценивается вероятность
безотказного выполнения ПС на момент оценки:
 (5.7) (5.7)
где k - известное
число ошибок, N - общее
число прогонов, N0 - число безотказных выполнений
программы.
Вероятность появления ошибки
рассчитывается по формуле:
 , (5.8) , (5.8)
где αi -
вероятность выявления ошибок i-го типа при тестировании [17].
При выполнении 150 тестов, 8 из них
завершились с ошибками. Ошибки программы по категориям и вероятности их
появления представлены в таблице 5.3.
Таблица 5.3-Таблица ошибок программы
|
Тип
ошибки
|
Вероятность
появления ошибки αi
|
Число
появления ошибок Ni при испытании
|
|
Ошибки
вычислений
|
0,09
|
3
|
|
Логические
ошибки
|
0,26
|
4
|
|
Ошибки
ввода-вывода
|
0,16
|
2
|
|
Ошибки
манипулирования данными
|
0,18
|
5
|
|
Ошибки
сопряжения
|
0,17
|
0
|
|
Ошибки
определения данных
|
0,08
|
4
|
|
Ошибки
в БД
|
0,06
|
0
|
Подставив в формулу 5.7, получаем вероятность
безотказного выполнения программы:
 . .
Исходя из приведенных предположений
и расчетов получается, что разрабатываемое программное средство надежно с
вероятностью 0,96.
6. Компьютерная реализация системы
.1 Назначение системы
Разрабатываемая автоматизированная
система предназначена для анализа групп в социальных сетях и выбора
оптимального расписания для публикаций.
Система включает в себя следующие
функции: добавление групп, сканирование и анализ данных, вывод результатов.
Для начала работы с программой
необходимо пройти авторизацию с помощью какой-либо социальной сети. После этого
пользователь может подключить группы, в которых он является администратором.
Для этих групп будет выполняться сканирование и анализ данных для составления
оптимального расписания публикаций. Страница добавления группы представлена на
рисунке 6.1
Рисунок 6.1-Страница добавления
группы
После подключения групп, система
начинает сбор данных выбранной группы: динамика показателей недавних
публикаций, значения показателей публикаций, опубликованных больше двух недель
назад, списки подписанных пользователей, недавно подписавшихся и отписавшихся
пользователей, показатель количество онлайн пользователей.
После завершения сканирования и
получения некоторых данных, запускается анализ данных. Затем на основе
собранных и проанализированных данных представляется график эффективности
публикации на ближайшую неделю. График показывает вероятность того, что
публикация, сделанная в это время, будет иметь максимальное значение
показателей и данную публикацию просмотрит наибольшее число подписчиков. На
рисунках 6.2-6.4 показана страница "Расписание" при выборе разных
дней недели.

Рисунок 6.2-Страница
"Расписание" для среды

Рисунок 6.3-Страница
"Расписание" для пятницы

Рисунок 6.4-Страница
"Расписание" для воскресенья
Таким образом, для группы было
составлено оптимальное расписание для публикаций. Публикация в указанное время,
позволяет увеличить показатели охват пользователей и активность пользователей,
тем самым повышая количество подписывающихся пользователей.
Также пользователь может настроить
отображение сканируемых данных на главной странице. Пользователь может
настраивать главную страницу с помощью виджетов. Каждый виджет имеет
соответствующие настройки и вид. Выбор доступных виджетов представлен на
рисунке 6.5.

Рисунок 6.5-Список доступных
виджетов на главной странице
После выбора одного из виджетов
открывается окно настроек. В нем предлагается выбрать группу, для которой будут
собираться данные и дополнительные настройки, в зависимости от выбранного
виджета. Окно настройки виджета "График подписок" представлено на
рисунке 6.6.
После добавления нескольких виджетов
главная страница может выглядеть, как представлено на рисунке 6.7.

Рисунок 6.6-Окно настройки виджета "График
подписок"

Рисунок 6.7-Вид главной страницы после настройки
виджетов
Заключение
В выпускной квалификационной работе была
разработана автоматизированная система для анализа групп в социальных сетях и
выбора оптимального расписания для публикаций. Данная система позволила
автоматизировать сбор данных и анализ групп в социальных сетях с целью выбора
оптимального расписания для публикаций.
В работе были рассмотрены особенности социальных
сетей, их использование как средство продвижения товаров и услуг, а также
описана информационно-аналитическая поддержка работы с социальными сетями.
На предпроектной стадии создания системы были
проведены сбор и анализ материалов обследования. При анализе предметной области
определена постановка задачи, разработана функциональная структура
автоматизированной системы, а также описаны требования к системе. Также были
рассмотрены функции и виды обеспечения, которые должны быть реализованы в
системе.
При проектировании визуальной модели системы
были разработаны диаграммы вариантов использования, диаграммы
последовательности, диаграммы классов и компонентов. Также были описаны методы
анализа данных и проведена оценка трудоемкости разработки автоматизированной
системы, в ходе чего было установлено, что на разработку проекта понадобится 15
недель учитывая, что проект будет разрабатываться одним человеком.
В ходе разработки информационного обеспечения
системы выделены информационные объекты, построена логическая модель данных, а
также описаны таблицы базы данных.
Во время разработки программного обеспечения
системы было приведено описание программных средств и рассмотрен алгоритм
решения задачи. Также были проведены структурное тестирование, основанное на
способе тестировании базового пути, и функциональное тестирование, основанное
на методе эквивалентных разбиений. Проведена оценка надежности программного
средства с помощью модели Коркорэна, на основании которой получили, что
информационная система надежна с вероятностью 0,96.
Было описано назначение автоматизированной системы
для анализа групп в социальных сетях и выбора оптимального расписания для
публикаций. Также представлены основные принципы работы с системой.
Список использованных источников
1. Бурко, Р.А. Социальные сети в
современном обществе / Р.А. Бурко, Т.В. Терёшина // Молодой ученый. 2014. - №7.
- С. 607-608.
. Мингазов, И.М. Социальные сети как
инструмент продвижения / И.М. Мингазов, В.Н. Макашова // Сборник научных трудов
- Магнитогорск: МГТУ, 2015. - Т.1.
. Ермолова, Н. Продвижение бизнеса в
социальных сетях Facebook, Twitter, Google+ / Н. Ермолова - Москва: Альпина
паблишер, 2014. - 365 с.
. Халилов, Д. Маркетинг в социальных
сетях / Д. Халилов - Москва: Манн, Иванов и Фербер, 2013. - 376 с.
. Базенков, Н.И. Обзор
информационных систем анализа социальных сетей / Н.И. Базенков, Д.А. Губанов -
Москва: ИПУ РАН, 2013. - 37 с.
. Коршунов, А.В. Анализ социальных
сетей: методы и приложения / А.В. Коршунов - Москва: ИСП РАН, 2013. - 17 с.
. Леоненков, А.В
Объектно-ориентированный анализ и проектирование с использованием UML и IBM
Rational Rose / А.В. Леоненков - Москва: БИНОМ, 2006. - 319 с.
. Трофимов, С.А. CASE-технологии.
Практическая работа в Rational Rose / С.А. Трофимов - Москва: Бином-Пресс,
2002. - 288 с.
. Поручиков, М.А. Анализ данных /
М.А. Поручиков - Самара: СамГУ, 2016. - 88 с.
. Сажин, Ю.В. Анализ временных рядов
и прогнозирование / Ю.В. Сажин, А.В. Катынь, Ю.В. Сарайкин - Саранск:
Мордовский университет, 2013. - 192 с.
. Лукашин, Ю.П. Адаптивные методы
краткосрочного прогнозирования временных рядов / Ю.П. Лукашин - Москва: Мир,
2003. - 415 с.
. Харченко, М.А. Корреляционный
анализ: Учебное пособие для ВУЗов / М.А. Харченко, Л.М. Носилова - Воронеж:
ВГУ, 2008. - 31 с.
. Гайдышев, И.П. Анализ и обработка
данных: специальный справочник / И.П. Гайдышев - Санкт-Петербург: Питер, 2001.
- 752 с.
. Барковский, С.С. Многомерный
анализ данных методами прикладной статистики: Учебное пособие / С.С.
Барковский, В.М. Захаров, А.М. Лукашов, А.Р. Нурутдинова - Казань: КГТУ, 2010.
- 126 с.
. Маклаков, С.В. BPwin и ERwin:
CASE-средства для разработки информационных систем / С.В. Маклаков - Москва:
Диалог-МИФИ, 1999. - 256 с.
. Сибилев, В.Д. Моделирование и
проектирование баз данных. Учебное пособие для вузов / В.Д. Сибилев - Томск:
ТУСУР, 2002. - 144 с.
. Воронин, А.А. Надежность
информационных систем: Учебное пособие / А.А. Воронин, Б.И. Морозов -
Санкт-Петербург: СПбГТУ, 2001. - 89 с.
Похожие работы на - Разработка автоматизированной системы
|