|
Случайные цифры
|
Равномерно распределенные от 0 до 1 случайные числа
|
|
9
|
2
|
9
|
2
|
0
|
4
|
2
|
6
|
0,929
|
|
9
|
5
|
7
|
3
|
4
|
9
|
0
|
3
|
0,204
|
|
5
|
9
|
1
|
6
|
6
|
5
|
7
|
6
|
0,269
|
Достоинство данного метода в том,
что он дает действительно случайные числа, так как таблица содержит проверенные
некоррелированные цифры. Недостатки метода: для хранения большого количества
цифр требуется много памяти; большие трудности порождения и проверки такого
рода таблиц, повторы при использовании таблицы уже не гарантируют случайности
числовой последовательности, а значит, и надежности результата.
Числа, генерируемые с помощью этих
ГСЧ, всегда являются псевдослучайными (или квазислучайными), то есть каждое
последующее сгенерированное число зависит от предыдущего:
+ 1 = f(ri).
Последовательности, составленные из
таких чисел, образуют петли, то есть обязательно существует цикл, повторяющийся
бесконечное число раз. Повторяющиеся циклы называются периодами.
Достоинством данных ГСЧ является
быстродействие; генераторы практически не требуют ресурсов памяти, компактны.
Недостатки: числа нельзя в полной мере назвать случайными, поскольку между ними
имеется зависимость, а также наличие периодов в последовательности
квазислучайных чисел.
Важными алгоритмическими методами
получения ГСЧ есть:
· метод серединных
квадратов;
· метод серединных
произведений;
· метод
перемешивания;
· линейный
конгруэнтный метод.
Проверка качества работы генератора.
От качества работы ГСЧ зависит
качество работы всей системы и точность результатов. Поэтому случайная
последовательность, порождаемая ГСЧ, должна удовлетворять целому ряду
критериев.
Осуществляемые проверки бывают двух
типов:
· проверки на
равномерность распределения;
· проверки на
статистическую независимость.
Проверки на равномерность
распределения.
) ГСЧ должен выдавать близкие к
следующим значения статистических параметров, характерных для равномерного
случайного закона:
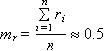 -
математическое ожидание;
-
математическое ожидание;
 -
дисперсия;
-
дисперсия;
 -
среднеквадратичное отклонение.
-
среднеквадратичное отклонение.
) Частотный тест.
Частотный тест позволяет выяснить, сколько чисел
попало в интервал (mr - σr; mr + σr),
то
есть(0,5 - 0,2887; 0,5 + 0,2887) или, в конечном итоге, (0,2113; 0,7887). Так как
0,7887 - 0,2113 = 0,5774, заключаем, что в хорошем ГСЧ в этот интервал должно
попадать около 57,7% из всех выпавших случайных чисел (рисунок 2.6).

Рисунок 2.6 - Частотная диаграмма
идеального ГСЧ в случае проверки его на частотный тест
Также необходимо учитывать, что
количество чисел, попавших в интервал (0; 0,5), должно быть примерно равно
количеству чисел, попавших в интервал (0,5; 1).
) Проверка по критерию «хи-квадрат».
Критерий «хи-квадрат» (χ2-критерий) - это один из
самых известных статистических критериев; он является основным методом,
используемым в сочетании с другими критериями. Критерий «хи-квадрат» был
предложен в 1900 году Карлом Пирсоном. Его замечательная работа рассматривается
как фундамент современной математической статистики.
Для нашего случая проверка по критерию
«хи-квадрат» позволит узнать, насколько созданный нами реальный ГСЧ близок к
эталону ГСЧ, то есть удовлетворяет ли он требованию равномерного распределения
или нет.
Проверки на статистическую независимость.
1) Проверка на частоту появления
цифры в последовательности.
Рассмотрим пример. Случайное число
0,2463389991 состоит из цифр 2463389991, а число 0,5467766618 состоит из цифр
5467766618. Соединяя последовательности цифр, имеем: 24633899915467766618.
Понятно, что теоретическая
вероятность pi выпадения i-ой цифры (от 0 до 9) равна 0,1.
Далее следует вычислить частоту
появления каждой цифры в выпавшей экспериментальной последовательности.
Например, цифра 1 выпала 2 раза из 20, а цифра 6 выпала 5 раз из 20.
Далее считают оценку и принимают
решение по критерию «хи-квадрат».
) Проверка появления серий из
одинаковых цифр.
Обозначим через nL число серий
одинаковых подряд цифр длины L. Проверять надо все L от 1 до m, где m - это
заданное пользователем число: максимально встречающееся число одинаковых цифр в
серии.
В примере «24633899915467766618»
обнаружены 2 серии длиной в 2 (33 и 77), то есть n2 = 2 и 2 серии длиной в 3
(999 и 666), то есть n3 = 2.
Вероятность появления серии длиной в
L равна: pL = 9 · 10-L (теоретическая). То есть вероятность появления серии
длиной в один символ равна: p1 = 0,9 (теоретическая). Вероятность появления
серии длиной в два символа равна: p2 = 0,09 (теоретическая). Вероятность
появления серии длиной в три символа равна: p3 = 0,009 (теоретическая).
Например, вероятность появления
серии длиной в один символ равна pL = 0,9, так как всего может встретиться один
символ из 10, а всего символов 9 (ноль не считается). А вероятность того, что
подряд встретится два одинаковых символа «XX» равна 0,1 · 0,1 · 9, то есть
вероятность 0,1 того, что в первой позиции появится символ «X», умножается на
вероятность 0,1 того, что во второй позиции появится такой же символ «X» и
умножается на количество таких комбинаций 9.
Частость появления серий
подсчитывается по ранее разобранной нами формуле «хи-квадрат» с использованием
значений pL.
Примечание: генератор может быть
проверен многократно, однако проверки не обладают свойством полноты и не
гарантируют, что генератор выдает случайные числа. Например, генератор,
выдающий последовательность 12345678912345…, при проверках будет считаться
идеальным, что, очевидно, не совсем так.
В заключение отметим, что третья
глава книги Дональда Э. Кнута «Искусство программирования» (том 2) полностью
посвящена изучению случайных чисел. В ней изучаются различные методы
генерирования случайных чисел, статистические критерии случайности, а также
преобразование равномерно распределенных случайных чисел в другие типы
случайных величин. Изложению этого материала уделено более двухсот страниц.
2.2 Моделирование случайной величины с заданным
законом распределения
Большей информативностью, по сравнению с такими
статистическими характеристиками как математическое ожидание, дисперсия, для
инженера обладает закон распределения вероятности случайной величины X.
Представим, что X принимает случайные значения из некоторого диапазона.
Например, X - диаметр вытачиваемой детали. Диаметр может отклоняться от
запланированного идеального значения под влиянием различных факторов, которые
нельзя учесть, поэтому он является случайной слабо предсказуемой величиной. Но
в результате длительного наблюдения за выпускаемыми деталями можно отметить,
сколько деталей из 1000 имели диаметр X1 (обозначим NX1), сколько деталей имели
диаметр X2 (обозначим NX2) и так далее. В итоге можно построить гистограмму
частости диаметров, откладывая для X1 величину NX1/1000, для X2 величину
NX2/1000 и так далее. (Обратим внимание, если быть точным, NX1 - это число
деталей, диаметр которых не просто равен X1, а находится в диапазоне от X1 - Δ/2
до X1 + Δ/2,
где
Δ
= X1 - X2). Важно, что сумма всех частостей будет равна 1 (суммарная площадь
гистограммы неизменна). Если X меняется непрерывно, опытов проведено очень
много, то в пределе N -> ∞ гистограмма превращается в график
распределения вероятности случайной величины. На рисунке 2.7, а показан пример
гистограммы дискретного распределения, а на рисунке 2.7, б показан вариант
непрерывного распределения случайной величины.

Рисунок 2.7 - Сравнение дискретного
и непрерывного законов распределения случайной величины
В нашем примере закон распределения
вероятности случайной величины показывает насколько вероятно то или иное
значение диаметра выпускаемых деталей. Случайной величиной является диаметр
детали.
В производстве и технике часто такие
законы распределения заданы по условию задачи. Наша задача сейчас состоит в
том, чтобы научиться имитировать появление конкретных случайных событий
согласно вероятностям такого распределения.
В числе наиболее значимых методов
можно назвать:
· метод ступенчатой
аппроксимации;
· метод усечения;
· метод взятия
обратной функции.
Каждый метод обладает своими
положительными и отрицательным сторонами. Среди их реализаций можно выделить
достаточно любопытный случай (в большей степени опирающийся на метод
ступенчатой аппроксимации).
За неимением места подробно его
излагать не будем, перечислим лишь его достоинства:
1. В качестве функции
распределения может быть задана произвольная зависимость f(x), от нее не требуется
аналитического задания, непрерывности, дифференцируемости, хорошей
интегрируемости (хотя требуется ограниченность на интересующем нас интервале).
2. Область распределения может
быть ограничена любым интервалом.
. Функция не требует
нормировки. Это особенно удобно на ограниченном (по тем или иным соображениям)
интервале.
Если же системно (применяя
достижения алгебры и численных методов, опирающиеся на твёрдую поверхность
кибернетики) подходить к каждому конкретному распределению, то на сегодняшний день
можно отметить работы Александра Самарина (The_Freeman) [19, 20], который
подвёл итоги применяющимся сегодня (в том числе в САПР вроде Matlab) методам
генерации случайных величин с заданным законом распределения. Для примера
коротко опишем наиболее часто используемое распределение - нормальное (рисунок
2.8).


Рисунок 2.8 - Функция
нормального распределения
Метод инверсии потребует вычисления
обратной функции ошибок. Если не использовать специальные аппроксимирующие
функции, сложно и невероятно долго. Для нормальной величины существует метод
Бокса-Мюллера. Он довольно прост и широко распространен. Его явный недостаток -
это вычисление трансцендентных функций. Существует также полярный метод,
помогающий избежать подсчета синуса и косинуса. Но мы все еще должны считать
логарифм и корень из него. Куда быстрее работает красиво названный метод
Ziggurat, придуманный Джорджем Марсалья, автором того же полярного метода.
Полярный метод - это пример выборки
с отклонением (acceptance-rejection sampling). Буквально, нужно сгенерировать
величину и принять ее, если она подходит, иначе - отклонить и сгенерировать еще
раз. Основной пример: генерирация случайной величины с плотностью f(x), однако
это слишком сложно сделать простым методом инверсии. Зато, вы можете
сгенерировать случайную величину с плотностью g(x), не очень сильно
отличающейся от f(x). В таком случае берём наименьшую константу M, такую что M
> 1 и почти всюду f(x) < Mg(x), и выполняете следующий алгоритм:
. Генерируем случайную
величину X из распределения g(x) и случайную величину U, равномерно
распределенную от 0 до 1.
. Если U < f(X) / Mg(X) -
возвращаем X, иначе - повторяем заново.
Общая проблема выборки с отклонением
заключается в подборе такой случайной величины с плотностью распределения g(x),
чтобы отклонений было как можно меньше. Для решения этой проблемы существует
множество расширений. Сам же метод является основой для почти все последующих
алгоритмов, включая Ziggurat. Суть последнего все та же: пытаемся покрыть
функцию плотности нормального распределения похожей и более простой функцией и
возвращаем величины, попавшие под кривую. Функция своеобразная и напоминает
многоступенчатое сооружение, откуда, собственно, и такое название у алгоритма
(рисунок 2.9).

Рисунок 2.9 - Схематическая
иллюстрация метода Ziggurat
Сам алгоритм можно ускорить
различными хитростями работы с 32-битными целыми, убирая ненужные перемножения.
Для большей информации можно
обратиться к статье George Marsaglia and Wai Wan Tsang «The Ziggurat Method for
Generating Random Variables».
Аналогично рассматриваются остальные
распределения - непрерывные и дискретные. Имея равномерное и нормальное
распределения, часто можно применить формулы преобразования их в требуемое, но,
как было отмечено выше, для каждого конкретного случая (в реалиях имеющихся
Тьюринг-полных императивных процедурных (наиболее подходящих для быстрых
вычислений) языков программирования на ПК с архитектурой фон Неймана) есть
свой, особый наиболее оптимальный сегодня алгоритм.
3. Создание программ моделирования случайных
последовательностей
.1 Векторная гауссовская марковская
последовательность
В отличие от детерминированных процессов,
течение которых определено однозначно, случайный процесс представляет изменения
во времени физической системы, которые заранее предсказать невозможно. Течение
случайного процесса может быть различным в зависимости от случая и определена
вероятность того или иного его течения.
Наиболее известным примером
случайного процесса являются флуктуационные (дробовые и тепловые) шумы в
радиотехнических устройствах. При наблюдении шумового напряжения на выходах
идентичных приборов обнаруживается, что функции, описывающие во времени эти напряжения,
различны. Задача теории случайных процессов заключается в отыскании
вероятностных закономерностей, которые связывают эти различные функции,
описывающие одно и то же физическое явление (например, флуктуационный шум).
Количественно случайный процесс описывается
случайной функцией времени ξ(t), которая в любой момент времени t может принимать различные
значения с заданным распределением вероятностей. Таким образом, для любого t =
ti и значение ξi = ξ(ti) является случайной величиной. Случайный процесс (случайная функция
времени) определяется совокупностью функций времени и законами,
характеризующими свойства совокупности.
Каждая из функций этой совокупности
называется реализацией случайного процесса. Реализация случайной функции ξ(t) обозначается через ξi(t), где параметр i может
быть любым действительным числом. Детерминированный процесс имеет одну
единственную реализацию, описываемую заданной функцией времени.
Таким образом, случайный процесс -
это не одна функция (в классическом понимании), а, в общем случае, бесконечное
множество реализаций (ансамбль реализаций). В этом смысле случайная функция
есть некая обобщенная функция. Нельзя изобразить случайный процесс одной
кривой, пусть даже очень замысловатой. Можно изобразить лишь отдельные его
реализации. На рисунке 3.1 в качестве примера изображены реализации случайного
процесса и сечение.
В зависимости от того, принадлежат
ли возможные значения времени t и реализации ξ(t)
дискретному множеству чисел или отрезку (а может быть и всей)
действительной оси, различают четыре типа случайных процессов:
. Случайный процесс общего
типа: t и ξ(t) могут
принимать любые значения на отрезке (или, быть может, на всей) действительной
оси.
. Дискретный случайный
процесс: t непрерывно, а величины ξ(t) дискретны.
. Случайная
последовательность общего типа: t дискретно, а
ξ(t) может принимать любые значения на
отрезке (или на всей) действительной оси.
. Дискретная случайная
последовательность: t и ξ(t) оба дискретны.

Рисунок 3.1 - Ансамбль реализаций и
сечение случайного процесса
Случайный процесс называется
гауссовским, если совместная плотность вероятности любой конечной совокупности
величин нормальная.
Модель гауссовского случайного
процесса широко используется в естествознании и технике. В радиотехнике и связи
гауссовский случайный процесс является адекватной математической моделью
активных и пассивных помех, атмосферных и космических шумов, каналов с
замиранием, с многолучевым распространением, групповых сигналов в
многоканальных системах. Флуктуационные шумы приемных устройств, обусловленные
дробовым эффектом и тепловым движением электронов, также подчиняются
нормальному закону распределения. Адекватность модели гауссовского случайного
процесса многим реальным помехам и сигналам и ее универсальность объясняются во
многих случаях действием центральной предельной теоремы теории вероятностей.
Ковариационная матрица (или матрица
ковариаций) в теории вероятностей - это матрица, составленная из попарных
ковариаций элементов одного или двух случайных векторов.
Ковариационная матрица случайного
вектора - квадратная симметрическая неотрицательно определенная матрица, на
диагонали которой располагаются дисперсии компонент вектора, а внедиагональные
элементы - ковариации между компонентами.
Ковариационная матрица случайного
вектора является многомерным аналогом дисперсии случайной величины для
случайных векторов. Матрица ковариаций двух случайных векторов - многомерный
аналог ковариации между двумя случайными величинами.
В случае нормально распределенного
случайного вектора, ковариационная матрица вместе с математическим ожиданием
этого вектора полностью определяют его распределение (по аналогии с тем, что
математическое ожидание и дисперсия нормально распределенной случайной величины
полностью определяют её распределение).
Взаимная ковариационная функция
случайных процессов - это функция двух переменных t и u, равная математическому
ожиданию произведения случайных процессов, взятых в любые моменты времени t и u
из областей определения этих случайных процессов.
Разведаем доступные средства новейшего IDE
Matlab 2016. Среди них для наших целей может быть использована в числе прочих
функция inv(), которая обращает матрицу. «Вокруг неё» и формул теории
вероятности и построим нашу программу.
Если ещё конкретнее, то последовательность
необходимых действий будет следующей:
1. Устанавливаются начальные
данные:
· интервал
дискретизации;
· длительность;
· функция корреляции
(произвольная);
· число отсчетов.
. Далее описывается
корреляционная матрица, с помощью которой будут генерироваться первые значения
последовательно на основе своих корреляционных матриц.
. После генерации четырех
первых значений генерируется матрица связи для генерации последующих.
. На основе сдвигов
предыдущих значений, вычисленного среднеквадратичного отклонения, матрицы связи
и случайного нормально распределенного числа генерируется следующий элемент
марковской последовательности.
. Осуществляется вывод в файл
очередного элемента и построение графика.
Содержимое файла
GaussVectorSequense.m
function
GaussVectorSequense(filename,a,b,N)
if nargin < 4 %по умолчанию
filename='gaussVector'
N=1000;
a=2;
b=4/2*pi;
end
del=1/2; % интервал дискретизации
T=2.5; % длительность реализаций
t=0:del:T;
r=2*exp(-t)-exp(-2*t); % функция
корреляции
n=length(t); % число отсчётов
for i=1:n
for j=1:n
b(i,j)=r(abs(i-j)+1);
end
end
BB=b ; % исходная корреляционная
матрица
D=inv(BB) ;% матрица точности
D(1,6)=0;
D(6,1)=0;
B=inv(D) ; % аппроксимирующая
корреляционная матрица
% корреляционные матрицы первых
значений
B3=[B(1,1) B(1,2)
B(2,1) B(2,2)];
B4=[B(1,1) B(1,2) B(1,3)
B(2,1) B(2,2) B(2,3)
B(3,1) B(3,2) B(3,3)];
B5=[B(1,1) B(1,2) B(1,3)
B(1,4)
B(2,1) B(2,2) B(2,3)
B(2,4)
B(3,1) B(3,2) B(3,3)
B(3,4)
B(4,1) B(4,2) B(4,3) B(4,4)];
x(1)=randn*sqrt(B(1,1)) ; % первое
значение последовательности
c=B(2,1)/B(1,1);
si=sqrt(B(2,2)-c*B(1,2));
x(2)=c*x(1)+randn*si ; % второе
значение последовательности
C=[B(3,1)
B(3,2)]*inv(B3);
si=sqrt(B(3,3)-C*[B(1,3);B(2,3)]);
x(3)=C(1)*x(1)+C(2)*x(2)+randn*si ;
% третье значение последовательности
C=[B(4,1) B(4,2)
B(4,3)]*inv(B4);
si=sqrt(B(4,4)-C*[B(1,4);B(2,4);B(3,4)]);
x(4)=C(1)*x(1)+C(2)*x(2)+C(3)*x(3)+randn*si;
% четвёртое значение
C=[B(5,1) B(5,2) B(5,3)
B(5,4)]*inv(B5) ;% матрица связи
s=sqrt(B(5,5)-C*[B(1,5);B(2,5);B(3,5);B(4,5)]);
% ср.квадр.отклон.
X=[x(1);x(2);x(3);x(4)];
fid = fopen(filename,
'w');
if fid == -1
error('File
'+filename+'is not opened');
end
fprintf(fid,'%f ',x(1));
fprintf(fid,'%f ',x(2));
fprintf(fid,'%f ',x(3));
fprintf(fid,'%f ',x(4));
sw = ['' sprintf('\n')];
for i=5:N
x(i)=C*X+s*randn; % следующее значение
fprintf(fid,'%f ',x(i));
if mod(i,10)==0
fprintf(fid,'%s ',sw);
end
for j=1:4
X(j)=x(i-4+j); % сдвиг предыдущих четырёх
end
end
plot(x); % марковская последовательность
Содержимое файла
GaussVectorSequense_caller.m
answer=GaussVectorSequense('GaussVector',2,4/2*pi,1000)
;(answer);
Результаты работы отобразим на рисунках 3.2 и
3.3.

Рисунок 3.2 - Текстовая часть результатов
работы программы
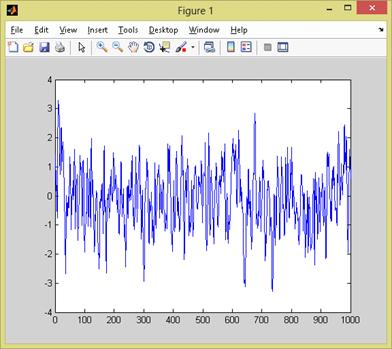
Рисунок 3.3 - Графическая часть результатов
работы программы
.2 Скалярная гауссовская последовательность
общего типа (с произвольной ковариационной функцией)
В радиофизике большую роль играют случайные
процессы, получившие название процессов Маркова или процессов без
последействия. Этот класс случайных процессов впервые систематически изучался
известным русским математиком А.А. Марковым.
Пример: броуновское движение.
Частицы (молекулы) газа или жидкости в отсутствие внешних влияний находятся в
постоянном, хаотическом движении, интенсивность которого зависит только от
температуры и плотности. Частица в случайные моменты времени сталкивается с
молекулами окружающей среды и меняет при этом свою скорость и направление.
Будем следить, как изменяется с
течением времени одна из координат избранной частицы, допустим горизонтальная
координата. При этом можно не учитывать силу тяжести; на частицу действуют
только систематическая сила трения об окружающую среду и случайная сила
толчков. Считая компоненту силы трения пропорциональной х-й компоненте скорости
и пренебрегая силой инерции, получим следующее уравнение движения частицы:
γ = n(t)
= n(t)
где γ - коэффициент трения; n(t) - сила случайных толчков вдоль оси х.
Поскольку толчки, испытываемые
данной частицей в результате столкновения с молекулами окружающей среды, в
разных направлениях равновероятны, то среднее значение n(t), очевидно, равно
нулю. Случайная сила n(t) представляет результирующий эффект, обусловленный
большим числом отдельных толчков. Время корреляции, грубо говоря, равно
среднему времени свободного пробега молекул; при большой концентрации молекул
оно очень мало. Поэтому согласно центральной предельной теореме случайную силу
n(t) можно приближенно рассматривать как нормальный белый шум.
Смещения частицы для двух не
перекрывающихся интервалов времени, значительно превышающих время свободного
пробега, независимы. Если взять три момента времени (рисунок 3.4).
> t’ > t1,
причем промежутки много больше
среднего времени свободного пробега, то поведение частицы на интервале (t’, t2)
не будет зависеть от того, что происходило с частицей до момента t’. Это
характерное свойство Марковских процессов. Такой случайный процесс можно
назвать процессом без последействия.

Рисунок 3.4 - Траектории броуновской
частицы
Допустим, что нам точно известна
координата х’ в момент t’. Вследствие случайного характера воздействующей силы
n(t), возможные значения координаты х2 в момент времени t2 различны и образуют
некоторый «ансамбль». Мы можем говорить об условной вероятности F(х2, t2 | х’,
t’) того, что если в момент времени t’ координата равна х’, то в момент времени
t2 частица будет иметь координату, заключенную в промежутке (х2, х2 + dx2).
Условная вероятность F(х2, t2 | х’,
t’) характеризует вероятность перехода частицы из состояния х’ в состояние х2
за время между t’ и t2 и называется вероятностью перехода. Если частица в
момент времени t’ может иметь различные значения координаты х’ с вероятностью
F(х’, t’), то двумерная плотность вероятности равна:
(х’, х2; t’, t2) = f(х’, t’) f(х2,
t2 | х’, t’).
Нормальные процессы и марковские процессы в
общем случае частично «перекрываются».
Воспользуемся встроенными возможностями
новейшего математического («матричного») САПР Matlab 2016. Среди них для наших
целей выделяется функция normrnd(), которая возвращает элементы нормального
распределения. «Вокруг неё» и построим программу.
Если ещё конкретнее, то последовательность
необходимых действий будет следующей:
1. Пользователь указывает имя
выходного файла, МО, дисперсию и число элементов для генерации
. С помощью функции randn()
генерируется нормально распределенная завтравка для генератора, и с помощью
классической формулы (плотности) для нормального распределения генерируются
выходные элементы, которые записываются в файл.
. Далее последовательно
отрисовывается на графике.
Содержимое файла
GaussScalarSequense.mGaussScalarSequense(filename,a,sigma,N)
fid = fopen(filename, 'w'); % открытие файла на запись
if fid == -1 % проверка
корректности открытия
error('File
'+filename+'is not opened');
end
if nargin < 4 %по
умолчанию
N=100;
a=0;
sigma=1;
end
% x=1:1:N;
arr=[0,0];%набор значений случайной величины
i=1;
sw = ['' sprintf('\n')];
while i < N+1
rng('shuffle');
rnd=randn;
arr(i)=((1/sqrt(2*pi*sigma2))*exp(-((rnd-a)2/(2*sigma2))));
fprintf(fid,'%f
',arr(i));
i=i+1;
if mod(i,10)==0
fprintf(fid,'%s ',sw);
end
end
fclose(fid);
i=1:1:N;
plot(i,arr(i))
end
Содержимое файла
GaussScalarSequense_caller.m
answer=GaussScalarSequense('Gauss1',0,1,100)
;(answer);
Результаты работы отобразим на рисунках 3.6 и
3.7.

Рисунок 3.6 - Текстовая часть
результатов работы программы

Рисунок 3.7 - Графическая часть
результатов работы программы
4. Создание программ оценивания моментных
функций стационарной случайной последовательности
4.1 Оценивание математического
ожидания
Математическое ожидание случайной
величины X (обозначается M(X) или реже E(X)) характеризует среднее значение
случайной величины (дискретной или непрерывной). Математическое ожидание - это
первый начальный момент заданной СВ.
Математическое ожидание относят к
так называемым характеристикам положения распределения (к которым также
принадлежат мода и медиана). Эта характеристика описывает некое усредненное
положение случайной величины на числовой оси. Скажем, если матожидание
случайной величины - срока службы лампы, равно 100 часов, то считается, что
значения срока службы сосредоточены (с обеих сторон) от этого значения (с тем
или иным разбросом, о котором уже говорит дисперсия).
Математическое ожидание дискретной
случайной величины Х вычисляется как сумма произведений значений xi, которые
принимает СВ Х, на соответствующие вероятности pi:

Для непрерывной случайной величины
(заданной плотностью вероятностей f(x)), формула вычисления математического
ожидания Х выглядит следующим образом:

Воспользуемся встроенными
возможностями мощного САПР Matlab 2016. Среди них для наших целей выделяется
функция sum(), которая возвращает сумму чисел. Сделаем её нашей отправной
точкой, и придём к успеху (путём деления суммы чисел на их количество
(подходящий тип оценки матожидания)).
Если ещё конкретнее, то
последовательность необходимых действий будет следующей:
. Для вычисления оценки
математического ожидания необходимо считать последовательность и число ее
элементов.
. Далее простым суммированием
элементов и делением суммы на число элементов вычислить оценку математического
ожидания.
Содержимое файла GetMiddleOfGauss.m
function a= GetMiddleOfGauss(fileName,N)
fid = fopen(fileName, 'r'); % открытие файла на запись
if fid == -1 % проверка
корректности открытия
error('File'+fileName+'
is not opened');
end
if nargin < 2 %по
умолчанию
N=100;
end
values
=fscanf(fid,'%f');
summ=sum(values);
fclose(fid);
a=summ/N;
Содержимое файла
GetMiddleOfGauss_caller.m('Gauss1',0,1,1000) ;=GetMiddleOfGauss('Gauss1',1000)
;('Middle of gausse sequense:');(answer);
Результаты работы отобразим на
рисунке 4.1.

Рисунок 4.1 - Результаты работы
программы
.2 Оценивание ковариационной функции
Автокорреляция - статистическая
взаимосвязь между последовательностями величин одного ряда, взятыми со сдвигом,
например, для случайного процесса - со сдвигом по времени.
Данное понятие широко используется в
эконометрике. Наличие автокорреляции случайных ошибок регрессионной модели
приводит к ухудшению качества МНК-оценок параметров регрессии, а также к
завышению тестовых статистик, по которым проверяется качество модели (то есть
создается искусственное улучшение качества модели относительно её действительного
уровня точности). Поэтому тестирование автокорреляции случайных ошибок является
необходимой процедурой построения регрессионной модели.
Коэффициенты автокорреляции также
имеют самостоятельное важное значение для моделей временных рядов ARMA.
Чаще всего тестируется наличие в
случайных ошибках авторегрессионного процесса первого порядка. Для тестирования
нулевой гипотезы, о равенстве коэффициента автокорреляции нулю чаще всего
применяют критерий Дарбина-Уотсона. При наличии лаговой зависимой переменной в
модели данный критерий неприменим, можно использовать асимптотический h-тест
Дарбина. Оба эти теста предназначены для проверки автокорреляции случайных
ошибок первого порядка. Для тестирования автокорреляции случайных ошибок
большего порядка можно использовать более универсальный асимптотический LM-тест
Бройша-Годфри. В данном тесте случайные ошибки не обязательно должны быть
нормально распределены. Тест применим также и в авторегрессионных моделях (в
отличие от критерия Дарбина-Уотсона).
Для тестирования совместной гипотезы
о равенстве нулю всех коэффициентов автокорреляции до некоторого порядка можно
использовать Q-тест Бокса-Пирса или Q-тест Льюнга-Бокса
Автокорреляционная функция
показывает зависимость автокорреляции от величины сдвига во времени. При этом
предполагается стационарность временного ряда, означающая в том числе
независимость автокорреляций от момента времени. Анализ автокорреляционной
функции (вместе с частной автокорреляционной функцией) позволяет проводить
идентификацию порядка ARMA-моделей.
Автоковариационная функция -
произведение автокорреляционной функции на дисперсию. Обычно используется
именно автокорреляционная функция, так как она безразмерна, то есть независима
от масштаба изменения временных рядов.
Воспользуемся встроенными возможностями
современного математического («матричного») САПР Matlab 2016. Среди них для
наших целей выделяется функция cov(), которая возвращает ковариационную функцию
двух распределений. Продвинемся вперёд, опираясь на неё.
Если ещё конкретнее, то последовательность
необходимых действий будет следующей:
. Для вычисления ковариации
двух последовательностей необходимо их считать из файла и подсчитать сумму
элементов для каждой последовательности.
. Затем подсчитать оценку МО
для каждой последовательности.
. После чего,
воспользовавшись формулой оценивания ковариации вычислить ее.
Содержимое файла
GetGaussCovariation.mcovar= GetGaussCovariation(fileName1,fileName2,N)
fid1 = fopen(fileName1, 'r'); % открытие файла на чтение
fid2 = fopen(fileName2, 'r');
if fid1 == -1 % проверка корректности открытия
error('File'+fileName1+'
is not opened');
end
if fid2 == -1 % проверка корректности открытия
error('File'+fileName2+'
is not opened');
end
if nargin < 3 %по
умолчанию
N=100;
end
values1
=fscanf(fid1,'%f');
values2
=fscanf(fid2,'%f');
fclose(fid1);
fclose(fid2);
summ1=sum(values1);
summ2=sum(values2);
a1=summ1/N;
a2=summ2/N;
i=1;
total=0;
while i<N+1
total=total+(values1(i)-a1)*(values2(i)-a2);
i=i+1;
end
covar=total/N;
Содержимое файла GetGaussCovariation_caller.m('Gauss1',0,1,100)
;('Gauss2',0,2,100) ;=GetGaussCovariation('Gauss1','Gauss2',100) ;('Covariation
of gausse sequenseS:');(answer);
Результаты работы отобразим на
рисунках 4.2 и 4.3.

Рисунок 4.2 - Текстовая часть
результатов работы программы

Рисунок 4.3 - Графическая часть
результатов работы программы
5. Создание программы прогнозирования случайной
последовательности общего типа
.1 Короткий теоретический базис
Функция правдоподобия в
математической статистике - это совместное распределение выборки из
параметрического распределения, рассматриваемое как функция параметра. При этом
используется совместная функция плотности (в случае выборки из непрерывного
распределения) либо совместная вероятность (в случае выборки из дискретного
распределения), вычисленные для данных выборочных значений.
Понятия вероятности и правдоподобия
тесно связаны. Сравните два предложения:
«Какова вероятность выпадения 12
очков в каждом из ста бросков двух костей?»
«Насколько правдоподобно, что кости
не шулерские, если из ста бросков в каждом выпало 12 очков?»
Если распределение вероятности
зависит от параметра, то с одной стороны можно рассматривать вероятность
некоторых событий при заданном параметре, а с другой стороны - вероятность
заданного события при различных значениях параметра. То есть в первом случае
имеем функцию, зависящую от события, а во втором - от параметра при
фиксированном событии. Последний вариант является функцией правдоподобия и
показывает, насколько правдоподобен выбранный параметр при заданном событии.
Неформально: если вероятность
позволяет нам предсказывать неизвестные результаты, основанные на известных
параметрах, то правдоподобие позволяет нам оценивать неизвестные параметры,
основанные на известных результатах.
Важно понимать, что по абсолютному
значению правдоподобия нельзя делать никаких вероятностных суждений.
Правдоподобие позволяет сравнить несколько вероятностных распределений с
разными параметрами и оценить в контексте какого из них наблюдаемые события
наиболее вероятны.
Метод максимального правдоподобия
или метод наибольшего правдоподобия (ММП, ML, MLE - англ. maximum likelihood
estimation) в математической статистике - это метод оценивания неизвестного
параметра путём максимизации функции правдоподобия. Основан на предположении о
том, что вся информация о статистической выборке содержится в функции
правдоподобия. Метод максимального правдоподобия был проанализирован,
рекомендован и значительно популяризирован Р. Фишером между 1912 и 1922 годами
(хотя ранее он был использован Гауссом, Лапласом и другими).
Оценка максимального правдоподобия
является популярным статистическим методом, который используется для создания
статистической модели на основе данных и обеспечения оценки параметров модели.
Метод максимального правдоподобия
соответствует многим известным методам оценки в области статистики. Например,
вы интересуетесь таким антропометрическим параметром, как рост жителей России.
Предположим, у вас имеются данные о росте некоторого количества людей, а не
всего населения. Кроме того, предполагается, что рост является нормально
распределённой величиной с неизвестной дисперсией и средним значением. Среднее
значение и дисперсия роста в выборке являются максимально правдоподобными к
среднему значению и дисперсии всего населения.
Для фиксированного набора данных и
базовой вероятностной модели, используя метод максимального правдоподобия, мы
получим значения параметров модели, которые делают данные «более близкими» к
реальным. Оценка максимального правдоподобия даёт уникальный и простой способ
определить решения в случае нормального распределения.
Метод оценки максимального
правдоподобия применяется для широкого круга статистических моделей, в том
числе:
· линейные модели и
обобщённые линейные модели;
· факторный анализ;
· моделирование
структурных уравнений;
· многие ситуации, в
рамках проверки гипотезы и доверительного интервала формирования;
· дискретные модели
выбора.
.2 Проектирование
Программа прогнозирования стоимости
на электричество, файл prices.mat содержит порядка 50000 значений:
дата-час-стоимость.
Прогнозируется на 24 шага вперед,
иными словами на сутки.
В прогнозировании используется метод
выборки максимального правдоподобия.
Модель схожа с моделью исторического
развития по спирали: исторические этапы повторяются, но свойства и
характеристики этапов изменяются.
Если рассматривать
последовательности временных отметок, то если значений последовательности достаточно
много, то практически всегда можно выделить некоторый интервал, который похож
на тот, что происходит накануне прогноза.
Модель построения прогнозов основана
на некотором предположении. В модели по выборке максимального подобия
полагается, что если события повторяются, то для каждой выборки, предшествующей
прогнозу, есть подобная выборка, содержащаяся в фактических значениях этого же
временного ряда.
Метод подобия выборок применимы в
краткосрочных прогнозах (финансы, энергетика, ...).
Исходные данные в файле prices.mat
(открывать в Matlab)
Задействуем средства мощного САПР
Matlab 2016. Из них для наших целей можно особо выделитть класс timeseries(),
который содержит данные - вектор чисел (часто через равные интервалы) и методы
- для идентификации и моделирования закономерностей, а также прогнозирования на
их основе данных. Сделаем его нашей отправной точкой, и получим результат.
.3 Разработка
Содержимое файла task5.m
clear; clc;
% <Date> -
<Hour> - <Value>prices PRICES_EUR; % Загрузка файла prices.mat=
PRICES_EUR;
% Задача
прогнозирования= datenum('01.09.2012 23:00:00', 'dd.mm.yyyy hh:MM:ss'); %
Момент прогноза = 24; % Горизонт
прогнозирования (Forecast)
% Параметры максимального подобия
M = 144;
Step = 24;
% Определяется выбока новой истории
Index =
find(TimeSeries(:,1) == datenum(year(T), month(T), day(T)) &
TimeSeries(:,2) == hour(T)); length(Index) > 1
fprintf(['Ошибка временного ряда: отметка времени T найдена во временном ряде более 1
раза \n']);
elseif isempty(Index)
fprintf(['Ошибка временного ряда: отметка времени T во временном ряде не найдена \n']);
else
HistNewData =
TimeSeries([Index-M+1:Index],:); % Выборка новой истории (HistNewData)
Index = Index - Step * 2;
end
%Определить значения подобия при
помощи перебора
k = 1;Index > 2 * M
HistOldData =
TimeSeries([Index-M+1 : Index],:);
Likeness(k,1)= Index;
CheckOld =
find(HistOldData(:,3) > 0);
CheckNew =
find(HistNewData(:,3) > 0);
if isempty(CheckOld) ||
isempty(CheckNew)
Likeness(k,2) = 0;
else
Likeness(k,2) =
abs(corr(HistOldData(:,3), HistNewData(:,3), 'type', 'Pearson'));
end
k = k + 1;
Index = Index - Step; % Возврат по времени назад на шаг Step
end
% 2.2.3. Определить максимум подобия
MaxLikeness
MaxLikeness = max(abs(Likeness(:,2)));
IndexLikeness =
find(Likeness(:,2) == MaxLikeness);= Likeness(IndexLikeness(1),1);
(['Максимальное подобие
= ', num2str(MaxLikeness),'\n'])
% Определить выборку максимального
подобия
MSPData = TimeSeries([MSP-M+1 : MSP],:); % Выборка максимального подобия
% Определить базовую выборку (BaseHistData)
HistBaseData = TimeSeries([MSP+1:MSP+P],:);% Базовая выборка
% Коэффициенты alpha1 и alpha0
% Делаем аппроксимацию HistNewData при помощи MSPData по методу наименьших
квадратов.
% В данном случае решение находится
через обратную матрицу.
X = MSPData(:,3);
X(:,length(X(1,:))+1) = 1; % Добавляем столбец с единичным вектором I
Y = HistNewData(:,3);=
X(:,2);= X'* X;= X'* Y;= inv(Xn); = invX * Yn; % Искомые коэффициенты
alpha1
и alpha0
являются значениями матрица A
% Собственно, прогнозирование
X = HistBaseData(:,3);
X(:,length(X(1,:))+1) = 1;
Forecast = X * A; % Выборка из 24 прогнозных значения
disp('Спрогнозированный результат:');
disp(Forecast)
5.4 Результаты
Результаты работы отобразим на
рисунке 5.1.

Рисунок 5.1 - Результаты работы
программы
6. Создание программы, реализующей фильтр
Калмана для векторной гауссовской марковской последовательности
6.1 Короткий теоретический базис
Фильтр Калмана - эффективный рекурсивный
фильтр, оценивающий вектор состояния динамической системы, используя ряд
неполных и зашумленных измерений. Назван в честь Рудольфа Калмана.
Фильтр Калмана широко используется в
инженерных и эконометрических приложениях: от радаров и систем технического
зрения до оценок параметров макроэкономических моделей. Калмановская фильтрация
является важной частью теории управления, играет большую роль в создании систем
управления. Совместно с линейно-квадратичным регулятором фильтр Калмана
позволяет решить задачу линейно-квадратичного гауссовского управления. Фильтр
Калмана и линейно-квадратичный регулятор - возможное решение большинства
фундаментальных задач в теории управления.
В большинстве приложений размерность
вектора состояния объекта превосходит размерность вектора данных наблюдения. И
при этом фильтр Калмана позволяет оценивать полное внутреннее состояние
объекта.
Фильтр Калмана предназначен для
рекурсивного дооценивания вектора состояния априорно известной динамической
системы, то есть для расчёта текущего состояния системы необходимо знать
текущее измерение, а также предыдущее состояние самого фильтра. Таким образом,
фильтр Калмана, подобно другим рекурсивным фильтрам, реализован во временно́м, а не в частотном
представлении, но в отличие от других подобных фильтров, фильтр Калмана
оперирует не только оценками состояния, а ещё и оценками неопределенности
(плотности распределения) вектора состояния, опираясь на формулу Байеса
условной вероятности.
Алгоритм работает в два этапа. На
этапе прогнозирования фильтр Калмана экстраполирует значения переменных
состояния, а также их неопределенности. На втором этапе, по данным измерения
(полученного с некоторой погрешностью), результат экстраполяции уточняется.
Благодаря пошаговой природе алгоритма, он может в реальном времени отслеживать
состояние объекта (без заглядывания вперед, используя только текущие замеры и
информацию о предыдущем состоянии и его неопределенности).
Бытует ошибочное мнение, что для
правильной работы фильтра Калмана якобы требуется гауссовское распределение
входных данных. В исходной работе Калмана результаты о минимуме ковариации
фильтра были получены на базе ортогональных проекций, без предположений о
гауссовости ошибок измерений. Затем просто было показано, что для специального
случая распределения ошибок по Гауссу фильтр дает точную оценку условной
вероятности распределения состояния системы.
Наглядный пример возможностей
фильтра - получение оптимальных, непрерывно обновляемых оценок положения и
скорости некоторого объекта по результатам временного ряда неточных измерений
его местоположения. Например, в радиолокации стоит задача сопровождения цели,
определения её местоположения, скорости и ускорения, при этом результаты
измерений поступают постепенно и сильно зашумлены. Фильтр Калмана использует
вероятностную модель динамики цели, задающую тип вероятного движения объекта,
что позволяет снизить воздействие шума и получить хорошие оценки положения
объекта в настоящий, будущий или прошедший момент времени.
Существует несколько разновидностей
фильтра Калмана, отличающихся приближениями и ухищрениями, которые приходится
применять для сведения фильтра к описанному виду и уменьшения его размерности:
· расширенный фильтр
Калмана (EKF, Extended Kalman filter). Сведение нелинейных моделей наблюдений и
формирующего процесса с помощью линеаризации посредством разложения в ряд
Тейлора;
· сигма-точечный
фильтр Калмана (UKF, Unscented Kalman filter). Используется в задачах, в
которых простая линеаризация приводит к уничтожению полезных связей между
компонентами вектора состояния. В этом случае «линеаризация» основана на
сигма-точечном преобразовании;
· Ensemble Kalman
filter (EnKF). Используется для уменьшения размерности задачи;
· возможны варианты с
нелинейным дополнительным фильтром, позволяющим привести негауссовые наблюдения
к нормальным;
· возможны варианты с
«обеляющим» фильтром, позволяющим работать с «цветными» шумами и т. д.
Кроме того, имеются аналоги фильтра
Калмана, использующие полностью или частично модель непрерывного времени:
· фильтр Калмана-Бьюси,
в котором и эволюция системы, и измерения имеют вид функций от непрерывного
времени;
· гибридный фильтр
Калмана, использующий непрерывное время при описании эволюции системы, и
дискретные моменты времени для измерений.
.2 Проектирование
Безусловно самый сложный алгоритм из
представленных. Для его реализации нужно:
. Задать входные данные.
· K - количество
реализаций процесса моделирования фильтра;
· m - размерность
вектора состояния;
· r - размерность
вектора возмущения;
· n - размерность
вектора наблюдений;
· ro - коэффициент
корреляции;
· dx - дисперсия
последовательности;
· Ft, Gt - системные
матрицы уравнения состояний;
· ht - матрицы связи
состояний и наблюдений;
· Qt - дисперсия шума
возмущения;
· Rt - дисперсия шума
наблюдения.
. После задания входных
данных начать цикл моделирования наблюдений.
. В процессе моделирования
наблюдений осуществить проведение оценки с помощью фильтра Калмана в пакетном
режиме.
. Полученные оценки записать
в файл.
У нас в распоряжении есть встроенные
возможности развитого САПР Matlab 2016. Среди них для наших целей нельзя особо
выделить ни одну функцию - для реализации поставленной задачи приходится все
формулы набирать вручную. Аналогично предыдущим примерам применим модульную
структуру программы, где KalmanFilter_caller.m её запускает, KalmanFilter.m
проводит основные операции, а kaldt.m реализует «внутреннюю логику» фильтра.
6.3 Разработка
Содержимое файла kaldt.m
function [xt,xt_,Pt,Pt_]= kaldt(zt,Ft,Gt,ht,Qt,Rt,x10,P10)
[n,t]=size(zt);
[m,mf]=size(Ft); [mg,r]=size(Gt); [rq1,rq2]=size(Qt);
[nh,mh]=size(ht);
[nr1,nr2]=size(Rt); mx=length(x10);
[mp1,mp2]=size(P10);
xt=zeros(m,t);Pt=zeros(m,m,t);xt_=zeros(m,t+1);
xt_(:,1)=x10;
Pt_(:,:,1)=P10;
for cnt=1:t
Vt=Pt_(:,:,cnt)*ht';Ut=ht*Vt+Rt;
Ut_=inv(Ut);Wt=Vt*Ut_;
Pt(:,:,cnt)=Pt(:,:,cnt)-Wt*Vt';
xpr=xt_(:,cnt)+Wt*(zt(:,cnt)-ht*xt(:,cnt));xt(:,cnt)=xpr;
xt_(:,cnt+1)=Ft*xpr;
Pt_(:,:,cnt+1)=Ft*Pt(:,:,cnt)*Ft'+Gt*Qt*Gt';
end;
end
Содержимое файла
KalmanFilter.m
function
KalmanFilter(filenameIn,filenameOut,N)
if nargin < 1 %по
умолчанию
filenameIn='gaussVector';
filenameOut='kalmanOut';
N=20;
end
fIn = fopen(filenameIn,
'r'); % открытие файла на запись
if fIn == -1 % проверка
корректности открытия
error('File'+filenameIn+'
is not opened');
end
values
=fscanf(fIn,'%f');
fclose(fIn);
K=length(values);
m=1;r=1;n=1;
%t=1:N;
ro=0.99;dx=1;
Ft=ro;
Gt=sqrt(dx*(1-ro2));
ht=1;
Qt=1;Rt=1;
%
Pte=zeros(m,m,N);Pt_e=zeros(m,m,N);
for k=1:K
x=zeros(m,N);values=zeros(n,N);
ut=randn(r,N);
vt=randn(n,N);
x(:,1)=sqrt(dx)*randn;
values(:,1)=ht*x(:,1)+vt(:,1);
for i=1:N-1
x(:,i+1)=Ft*x(:,i)+Gt*ut(:,i);
values(:,i+1)=ht*x(:,i+1)+vt(:,i+1);
end;
x10=0;P10=dx;
[xt,xt_,Pt,Pt_]=kaldt(values,Ft,Gt,ht,Qt,Rt,x10,P10);
end;
disp(xt);
fOut =
fopen(filenameOut, 'w');
if fOut == -1
error('File
'+filenameOut+'is not opened');
end
sw = ['' sprintf('\n')];
for i=1:length(xt)
fprintf(fOut,'%f
',xt(i));
if mod(i,10)==0
fprintf(fOut,'%s ',sw);
end
end
fclose(fOut);
end
Содержимое файла
KalmanFilter_caller.m
answer=KalmanFilter('gaussVector','kalmanFilter',100)
;('Гауссова последователность, подвергнутая фильтру Калмана:');
disp(answer);
%Параметры
%входной файл, выходной файл,
количество дискретных отсчетов
.4 Результаты
Результаты работы отобразим на рисунке 6.1.

Рисунок 6.1 - Результаты работы
программы
7 Применение разработанных программ в примере
прогнозирования случайной последовательности
.1 Проектирование
Применим разработанные программ в примере
прогнозирования случайной последовательности. Это несколько затруднительно
ввиду их разнородности, но наибольший смысл, как нам представляется, несёт в
себе следующая последовательность действий:
1. Определение выборки
максимального подобия MSPData.
. Определение базовой выборки
BaseHistData.
. Аппроксимация HistNewData
при помощи MSPData по методу наименьших квадратов.
. Вычисление среднего от
оригинальной последовательности и от спрогнозированной.
. Применение фильтра Калмана
к оригинальной последовательности и к спрогнозированной.
. Вычисление ковариации от
оригинальной последовательности и спрогнозированной.
7.2 Разработка
Содержимое файла task7_caller.m.m
clear; clc;
% <Date> -
<Hour> - <Value>prices PRICES_EUR; % Загрузка файла prices.mat= PRICES_EUR;
% Задача
прогнозирования= datenum('01.09.2012 23:00:00', 'dd.mm.yyyy hh:MM:ss'); %
Момент прогноза = 24; % Горизонт
прогнозирования (Forecast)
% Параметры максимального подобия
M = 144;
Step = 24;
% Определяется выбока новой истории
Index = find(TimeSeries(:,1)
== datenum(year(T), month(T), day(T)) & TimeSeries(:,2) == hour(T)); length(Index) > 1
fprintf(['Ошибка временного ряда: отметка времени T найдена во временном ряде более 1
раза \n']);
elseif isempty(Index)
fprintf(['Ошибка временного ряда: отметка времени T во временном ряде не найдена \n']);
else
HistNewData =
TimeSeries([Index-M+1:Index],:); % Выборка новой истории (HistNewData)
Index = Index - Step * 2;
end
%Определить значения подобия при
помощи перебора
k = 1;Index > 2 * M
HistOldData =
TimeSeries([Index-M+1 : Index],:);
Likeness(k,1)= Index;
CheckOld =
find(HistOldData(:,3) > 0);
CheckNew =
find(HistNewData(:,3) > 0);
if isempty(CheckOld) ||
isempty(CheckNew)
Likeness(k,2) = 0;
else
Likeness(k,2) =
abs(corr(HistOldData(:,3), HistNewData(:,3), 'type', 'Pearson'));
end
k = k + 1;
Index = Index - Step; % Возврат по времени назад на шаг Step
end
% 2.2.3. Определить максимум подобия
MaxLikeness
MaxLikeness = max(abs(Likeness(:,2)));
IndexLikeness =
find(Likeness(:,2) == MaxLikeness);= Likeness(IndexLikeness(1),1);
% Определить выборку максимального
подобия
MSPData = TimeSeries([MSP-M+1 : MSP],:); % Выборка максимального подобия
% Определить базовую выборку (BaseHistData)
HistBaseData = TimeSeries([MSP+1:MSP+P],:);% Базовая выборка
% Коэффициенты alpha1 и alpha0
% Делаем аппроксимацию HistNewData при помощи MSPData по методу наименьших
квадратов.
% В данном случае решение находится
через обратную матрицу.
X = MSPData(:,3);
X(:,length(X(1,:))+1) = 1; % Добавляем столбец с единичным вектором I
Y = HistNewData(:,3);=
X(:,2);= X'* X;= X'* Y;= inv(Xn); = invX * Yn; % Искомые коэффициенты
alpha1
и alpha0
являются значениями матрица A
% Собственно, прогнозирование
X = HistBaseData(:,3);
X(:,length(X(1,:))+1) = 1;
Forecast = X * A; % Выборка из 24 прогнозных значения
disp('Спрогнозированная последовательность:')
disp(Forecast)
% 1) Определяем
фактические значения= find(TimeSeries(:,1) == datenum(year(T), month(T),
day(T)) & TimeSeries(:,2) == hour(T));= TimeSeries([Index : Index+P-1],3);('Реальная последовательность:')
disp(Fact)
filename_origin='original_sequence';_predict='predict_sequence';_origin
= fopen(filename_origin, 'w'); _predict = fopen(filename_predict, 'w');
fid_origin == -1
error('File
'+filename_origin+'is not opened'); fid_predict == -1
error('File
'+filename_predict+'is not opened'); i=1:24
fprintf(fid_origin,'%f
',Fact(i));
fprintf(fid_predict,'%f
',Forecast(i));
end
%Вычисление среднего от оригинальной
последовательности и от
%спрогнозированной_origin=GetMiddleOfGauss(filename_origin,24)
;_predict=GetMiddleOfGauss(filename_predict,24) ;('МО
реальной последовательности:');
disp(a_origin);
disp('МО спрогнозированной последовательности:');
disp(a_predict);
%Применение фильтра Калмана к
оригинальной последовательности и к
%спрогнозированной
disp('ПРименение фильтра Калмана для ');
disp(filename_origin)(filename_origin,'kalmanFilter_origin',24)
;('Проверьте файл kalmanFilter_origin');('ПРименение
фильтра Калмана для ');
disp(filename_predict)(filename_predict,'kalmanFilter_predict',24)
;('Проверьте файл kalmanFilter_predict');
%Вычисление ковариации от
оригинальной последовательности и
%спрогнозированной=GetGaussCovariation(filename_origin,filename_predict,24)
;('Ковариация последовательностей:');
disp(cov);
7.3 Результаты
Результаты работы отобразим на рисунках 7.1 и
7.2.

Рисунок 7.1 - Первая часть результатов работы
программы

Рисунок 7.2 - Вторая часть
результатов работы программы
Заключение
Благодаря глубокому анализу всех
основных аспектов теории вероятности и математической статистики нам удалось
значительно продвинуться в понимании теоретической и прикладной составляющих
самых передовых на сегодняшний день методов и концепций. Применяя эти средства
как для научной, так и для промышленной разработки мы сможем достичь ещё более
значительных результатов в будущем.
Литература
1. Barker E., Kelsey J., Recommendation for Random Number
Generation Using Deterministic Random Bit Generators, NIST SP800-90A, January
2012.
. Brent R.P., "Some long-period random number
generators using shifts and xors", ANZIAM Journal, 2007; 48: C188-C202.
. Gentle J.E. (2003), Random Number Generation and Monte
Carlo Methods, Springer.
4. Hörmann W., Leydold J., Derflinger G. (2004, 2011), Automatic Nonuniform Random Variate Generation, Springer-Verlag.
. Knuth D.E.. The Art of Computer Programming, Volume 2:
Seminumerical Algorithms, Third Edition. Addison-Wesley, 1997. ISBN
0-201-89684-2. Chapter 3.
. Luby M., Pseudorandomness and Cryptographic Applications,
Princeton Univ Press, 1996.
. Matthews R., "Maximally Periodic Reciprocals",
Bulletin of the Institute of Mathematics and its Applications, 28: 147-148,
1992.
. von Neumann J., "Various techniques used in
connection with random digits," in A.S. Householder, G.E. Forsythe, and
H.H. Germond, eds., Monte Carlo Method, National Bureau of Standards Applied
Mathematics Series, 12 (Washington, D.C.: U.S. Government Printing Office,
1951): 36-38.
. Peterson, Ivars (1997). The Jungles of Randomness : a
mathematical safari. New York: John Wiley
& Sons. ISBN 0-471-16449-6.
10. Press W.H., Teukolsky S.A., Vetterling W.T., Flannery B.P.
(2007), Numerical Recipes (Cambridge University Press).
. Viega J., "Practical Random Number Generation in
Software", in Proc. 19th Annual Computer Security Applications Conference,
Dec. 2003.
12. Волков И.К., Зуев С.М., Цветкова Г.М. Случайные процессы:
Учеб. для вузов / Под ред. B.C. Зарубина, А.П. Крищенко. - М.: Изд-во МГТУ им.
Н.Э. Баумана, 1999. - 448с.
. ГОСТ 21878-76: Случайные процессы и динамические системы.
. Левин Б.Р. Теоретические основы статистической
радиотехники. - 3-е над.., перераб. и доп. - М.: Радио и связь, 1989. - 656с.
. Марков А.А. Элементы математической логики. - М.: Изд-во
МГУ, 1984.