Методы и алгоритмы семантического поиска информации в системах поддержки пользователей
Содержание
Введение
. Семантический поиск информации в интернет-ориентированных
системах поддержки пользователей
.1 Системы семантического поиска информации
.1.1 Система ABBY Compreno
.1.2 Система Exactus
.1.3 Поисковый алгоритм «Королёв»
.1.4 Система IBM Watson
.1.5 Система Inbenta
.2 Методы семантического поиска информации в области интернет
ресурсов
.3 Метод семантической обработки информации на основе
интенсиональной логики
.4 Постановка задач научно-квалификационной работы
. Расширение метода семантической обработки информации на
основе интенсиональной логики в предметной области систем поддержки
пользователей
.1 Формально-математические основания метода анализа
предложений на естественном языке
.2 Модернизация метода интенсиональной логики для систем поддержки
пользователей
.2.1 Построение дерева предложения для последующего
семантического анализа и выделения сущностей
.2.2 Перевод вопроса на естественном языке в формулу
формальной семантики
.2.3 Адаптация алгоритма поиска для текстов на русском языке
. Модели и алгоритмы семантического поиска в мультиагентной
системе поддержки пользователей
.1 Модель мультиагентной системы семантического поиска
информации в системе FAQ
.2 Алгоритм заполнения базы знаний ответов
.3 Алгоритм поиска наибольшего семантического веса ответа
. Экспериментальное исследование прототипа системы
технической поддержки пользователей на основе семантического поиска ответов на
вопросы
.1 Архитектура системы
.2 Программная реализация экспериментального прототипа
.3 Экспериментальные оценки релевантности и пертинентности
запросов
Список источников
Введение
В настоящее время все большую актуальность приобретает проблема обработки
и извлечения знаний из больших объемов информации. Несмотря на то, что в
глобальной сети Интернет содержится огромное количество данных, далеко не
всегда их можно использовать. Даже пользователь, приходящий на конкретный сайт,
часто не может найти нужную ему информацию. Тогда мы получаем парадоксальную
ситуацию, что нужная информация есть, но воспользоваться ей нельзя.
Попытки решить эту проблему предпринимались и предпринимаются уже
достаточно давно. Разные фирмы занимаются обработкой естественно-языковых
текстов с разной степенью успешности. Такие гиганты Интернета как Google или
Яндекс использую наработки в области обработки естественных языков для
обработки поисковых запросов. Но все еще, большую роль при поиске играют
алгоритмы, основанные на статистике и частоте употребления слов.
Есть две причины, по которым смысловое содержание текста редко участвует
в поиске. Первая - существующие алгоритмы поиска по смыслу несовершенны и
сложны в реализации. Вторая - поиск практически всегда должен вестись в рамках
какой-то предметной области, которая определяет смысловое содержание. Таким
образом, для того, чтобы сделать качественный поиск, требуется большое
количество дополнительных сведений о рассматриваемой области, которые сложно
получить по одному поисковому запросу, не зная дополнительных сведений. Но,
несмотря на это, попытки формализовать текст на естественном языке и определить
его смысловое содержание ведутся.
Один из подходов к формализации естественно-языковых текстов предложил
американский математик и философ Ричард Монтегю. Он сделал предположение о том,
что естественный язык можно описать с помощью стандартных средств
математической логики. В итоге ему удалось доказать , что данное предположение
применительно к английскому языку.
В представленном исследовании рассказывается о предложенной Монтегю
концепции формальной семантики и о том, как требуется её доработать для текстов
на русском языке. В качестве примера для практической реализации взята область
ответов на вопросы пользователей в системах поддержки клиентов.
1. Семантический поиск информации в интернет-ориентированных системах
поддержки пользователей
.1 Системы семантического поиска информации
.1.1 Система ABBYY Compreno
Система Compreno способна проводить достаточно
глубокий анализ текста. Она проводит полный лексический и семантический анализы
текста, что позволяет с достаточно высокой точностью искать и извлекать из
текста нужную информацию. Применяется для больших информационных систем и
внешних источников. Этапы работы представлены на рис.1.
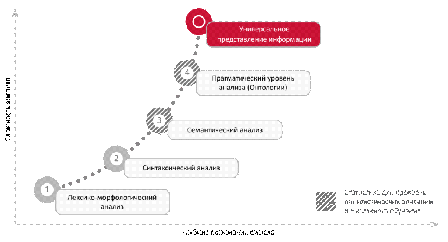
Рисунок 1 - Этапы работы ABBYY Compreno
Основным преимуществом системы является семантический анализ текста.
Система может извлекать из текста данные, отвечающие запросу. По большей части
разработка ABBYY направлена на работу с корпоративными хранилищами для анализа
хранящихся там документов, но она также может использоваться и для анализа
страниц в интернете.
.1.2 Система Exactus
Exactus
- это интеллектуальная поисковая система для поиска документов в сети Интернет.
Она работает на высокопроизводительной кластерной установке с операционной
системой Unix. Архитектура системы создана таким
образом, что её мощности можно постоянно наращивать путем добавления
дополнительных вычислительных модулей. При этом нагрузка будет балансироваться
менеджером распределенных вычислений, который использует виртуальную
параллельную машину (PVM).
Система реализована на языке C++ и
ее можно запускать на большом количестве Unix-подобных операционных систем.
Преимущества Exactus:
- Лингвистическая обработка текста (включает в себя
морфологический, синтаксический и семантический анализ)
- Обработка естественно-языковых текстовых запросов
- Расширение механизма поиска по ключевым словам
Работа с данными из самых разнообразных источников
- Автоматическое подключение этих источников
Использование параллельных вычислений
Схема обработки поисковых запросов в системе Exactus представлена на рис. 2.
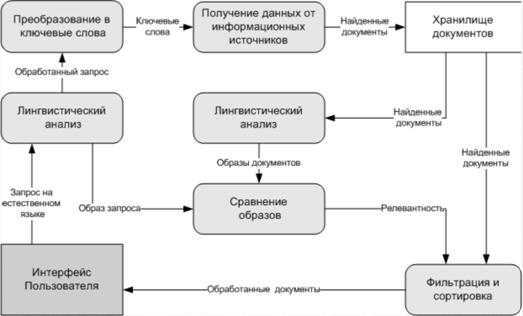
Рисунок 2 Схема обработки поисковых запросов в системе Exactus
Сильной стороной системы Exactus
является качественная интеллектуальная обработка текста. Документы проходят
многоуровневый лингвистический анализ и в структурированном виде сохраняются в
хранилище документов, что в будущем облегчает их поиск.
.1.3 Поисковый алгоритм «Королёв»
В 2017 году Yandex запустил
новый поисковый алгоритм «Королёв». Этот поисковый механизм основывается на
предыдущем алгоритме, который назывался «Палех»[1]. Особенность механизма
поиска состоит в том, что при поиске учитывает смысловое содержание фразы. В
основе алгоритма лежит нейронная сеть, которая сопоставляет смысл поискового
запроса и найденный документ. На рис. 3 представлен график частотного
распределения запросов в Яндексе в виде птицы, у которой есть клюв, туловище и
хвост. «Клюв» - это самые частые запросы, которые задают много, но их
разнообразие не так велико. «Туловище» - запросы средней частотности. «Хвост» -
разнообразные запросы, которые редко повторяются, но разнообразие которых
велико - за счет этого они набирают достаточно большой процент массы от
количества всех запросов.

Рисунок 3 - График частотного распределения запросов в «Яндексе»
В ходе работы поискового механизма берутся близкие по содержанию запрос
пользователя и найденный заголовок документа. После этого, производится их
скалярное произведение. Чем больше их скалярное произведение - тем релевантнее
результат поиска поисковому запросу. У «Яндекса» в распоряжении есть огромные
данные поисковых запросов, на основе которых они обучают нейронную сеть таким
образом, чтобы для тестов с похожими смыслами она генерировала похожие вектора,
а для текстов с разными смыслами - разные.
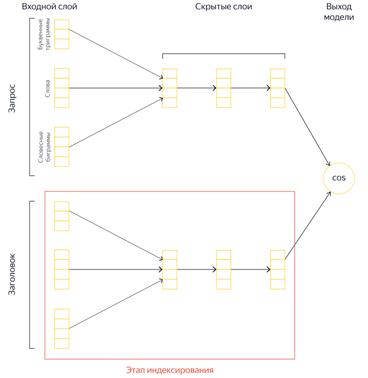
Рисунок 4 - Схема работы алгоритма «Королёв»
Безусловно, механизм поиска, разрабатываемый в «Яндексе» является
перспективным - и самое главное, что этот механизм может дорабатываться и
улучшаться на основе миллионов запросов, которые поступают к нему для
обработки.
.1.4 Система IBM Watson
Одной из систем, занимающихся поиском и анализом контента на естественном
языке, а также поиском ответов на вопросы, является IBM Watson. Это система,
которая разрабатывается компанией IBM уже на протяжении 15 лет, в которую
постоянно вносятся доработки.
Основой IBM Watson является технология DeepQA, которая основана на
статистическом подходе в компьютерной лингвистике. Общий алгоритм работы
системы представлен на рис. 5. Также одной из особенностей системы является -
то, что в качестве базы знаний в ней используется “Википедия”.
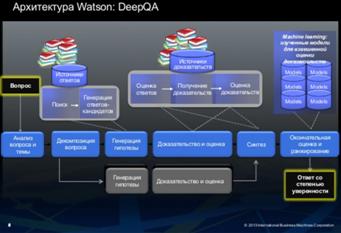
Рисунок 5 - Механизм DeepQA
К преимуществам системы можно отнести ее широкий охват знаний (благодаря
обширной базе знаний), возможность генерировать большое количество гипотез для
конкретного вопроса, опираясь на базу знаний.Watson имеет большую базу знаний и
поэтому она хороша для поиска ответов на самые разные вопросы, но для
узкоспециализированных областей требуются дополнительные и более детальные
сведения, поэтому применительно к ним, требуется ее доработка и адаптация.
Кроме того, система на данный момент работает только с английским языком, что
также сужает круг ее применения.
.1.5 Система Inbenta
Еще одна из подобных систем, которая занимается обработкой текста на
естественном языке - Inbenta. Inbenta представляет собой сервис, который
интегрируется с сайтом и улучшает поиск по сайту. Улучшение поиска получается
за счет предварительного анализа вопроса на естественном языке.
Основные этапы анализа следующие:
Исправление ошибок в введенной фразе
Находит родственные связи между словами(рис.2), удаление “шума”
Определение “семантического веса” каждого слова
Таким образом, Inbenta находит семантически наиболее важные слова и далее
ведет поиск ответа, исходя из этих слов.
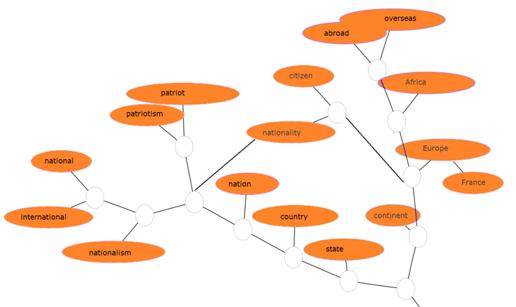
Рисунок 6 - Поиск родственных слов в Inbenta
Преимуществом Inbenta является отсутствие необходимости в базе знаний
предметной области - анализ ведется, опираясь исключительно на лингвистику. В
следствие этого, инструмент можно достаточно легко интегрировать в веб-сервисы,
так как требуется минимальный анализ контента сайта.
.2 Методы семантического поиска информации в области интернет ресурсов
1) Нейронные сети
Этот метод использует «Яндекс» в своем новом поисковом алгоритме
«Королёв»[2]. Это новый виток в развитии поисковых систем - после эпохи
машинного обучения и алгоритмов PageRank. Задача поиска по смыслу в данном контексте - найти ближайшее
соответствие запроса пользователя и заголовка страницы. Для нахождения близости
между заголовком документа и запросом пользователя, сначала эти параметры
представляются в форме векторов. Чем больше скалярное умножение этих векторов -
тем релевантнее документ запросу. К преимуществам метода можно отнести то, что
запрос становится устойчивым к переформулированию, к тому же становится
возможным найти близкие по содержанию документы, даже если точного совпадения
по фразе не было найдено, но смысловое содержание документов близко. Недостатки
- это сложность обучения нейронных сетей и требующиеся для этого огромные
массивы данных.
) Генетический алгоритм
Использование генетического алгоритма становится возможны при
семантическом поиске, так как сам порядок действий пользователя при поиске
напоминает эволюционный процесс, который включает в себя нахождение эффективных
наборов и сочетаний ключевых слов.
В результате работы генетического алгоритма формируется устойчивая и
эффективная популяция поисковых запросов, формируется семантическое ядро
документа. Для эффективной работы данного алгоритма также требуется большое
количество данных и документов для анализа.
) Построение семантического расширения поискового запроса
Основная идея данного подхода заключается в том, чтобы для каждого
поискового запроса строить его семантическое описание, и далее при поиске
опираться на него. Алгоритм семантического преобразования включает в себя
выделение основных аспектов в вопросе, после его идет построение модели вопроса
на основе концептуальных базисов.
) Концепция семантических сетей
В данном подходе говориться о модели поиска, когда каждый документ
содержит описание, понятное компьютеру. По этому описанию и ведется поиск. Для поиска строятся
RDF-схемы запросов от пользователей.
) Поиск на основе нечетких множеств
Данный подход к поиску включает в себя несколько моделей: основанные на
обобщении нечеткого отношения, основанные на максиминной близости между
нечеткими множествами и другие. Преимущества данных моделей заключается в том,
что текстовый запрос априори является нечеткой информацией, что не принимается
во внимание в большинстве существующих систем поиска.
.3 Метод семантической обработки информации на основе интенсиональной логики
Основоположником этого направления является Ричард Монтегю. Основную
мысль он выразил в одной из своих работ “English as a formal lanuage”[3], в
которой описывает формализацию английского языка. Цитата из книги: “I reject the contention that an important
theoretical difference exists between formal and natural languages. ... In the
present paper I shall accordingly present a precise treatment, culminating in a
theory of truth, of a formal language that I believe may reasonably be regarded
as a fragment of ordinary English. ... The treatment given here will be found
to resemble the usual syntax and model theory (or semantics) [due to Tarski] of
the predicate calculus, but leans rather heavily on the intuitive aspects of
certain recent developments in intensional logic [due to Montague himself]” . Перевод данного отрывка: “Я отвергаю тезис, что
формальные и естественные языки существенным образом различаются с
теоритической точки зрения.. В настоящей работе я представлю точное описание
формального логического языка, который, как я думаю, может с достаточными
основаниями рассматриваться как фрагмент обычного английского языка; это
описание завершается теорией истинности. Это описание аналогично обычному
синтаксису и теории моделей(или семантике) для исчисления предикатов
[построенные Тарским], но существенным образом опирается и на некоторые
последние результаты в интенсиональной логике [полученные самим Монтегю].”
В своей работе, Монтегю рассматривает формализацию текстов на английском
языке. Для решения поставленной задачи требуется формализация текста на русском
языке, который по своей структуре достаточно сильно отличается от английского.
Для формализации естественного языка, Монтегю в своих работах использовал
2 подхода:
) Прямой прямое описание синтаксиса естественного языка и
интерпретация его в моделях.
) Двухэтапный - использование промежуточного логического языка. В
данном методе используется промежуточный логический язык, который близок к
естественному. Далее происходит интерпретация с промежуточного языка на
естественный. Монтегю предлагает использовать в качестве промежуточного языка
язык интенсиональной логики.
В работе будет рассматриваться более подробно второй подход и
непосредственно преобразование фразы в язык интенсиональной логики. Одним из
ключевых этапов преобразования фразы на естественном языке в логическую формулу
является синтаксический анализ предложения. Центральный принцип формальной
семантики говорит о том, что отношение между синтаксисом и семантикой
композиционно. Соответственно, зная синтаксическую структуру предложения, можно
построить его логическую формулу.
1.4 Постановка задач научно-квалификационной работы
Целью научно-квалификационной работы является улучшение методов и
алгоритмов семантического поиска на запросы, полученные от пользователей, и
повышение качества возвращаемых ответов относительно конкретной предметной
области в системах поддержки пользователей.
Для достижения поставленной цели в работе были поставлены и решены
следующие задачи:
. Исследование принципов работы с запросами в существующих
системах поддержки пользователей.
. Разработка методов и алгоритмов поиска по естественно-языковым
запросам использующем логико-семантический подход. Адаптация методов и
алгоритмов для русского языка в системах поддержки пользователей.
. Разработка моделей и сценариев работы системы поддержки
пользователей
. Разработка экспериментального прототипа системы поддержки
пользователей
. Исследование эффективности полученных методов и алгоритмов на
примере разработанного прототипа системы поддержки пользователей для
веб-сервисов
В результате анализа инструментов, занимающихся анализом
естественно-языковых текстов, были сделаны следующие выводы:
) Основная часть инструментов работает на англоязычном рынке и
готовых решений для русского языка немного.
) Существующие системы анализа текстов недостаточно адаптированы
для задачи поиска ответов на вопросы.
) Большая часть существующих поисковых машин все еще отталкивается
от ключевых слов, что недостаточно для более точного поиска результата.
Чрезвычайно мало комплексных решений по анализу естественного русского
языка. Основные инструменты в первую очередь работают с английским языком.
Большая часть существующих инструментов с поддержкой русского языка
основывается на анализе морфологии и не предоставляют возможности извлекать
смысл из текста. Инструмента, подходящего для решения задачи консультанта, или
программы, помогающей найти ответ на вопрос для конкретной предметной области
не было найдено. Таким образом, существующие системы не удовлетворяют
поставленным задачам.
Учитывая вышеизложенные выводы, было принято решение разработать систему,
которая будет способна анализировать естественно-языковую фразу на русском
языке и помогать пользователю быстрее находить ответ на вопрос по заданной предметной
области (на конкретном сайте). Такая система будет полезна для больших
информационных порталов, где информация плохо структурирована, и посетитель,
приходящий на сайт, часто не может найти нужную информацию и вынужден
обращаться к службе поддержки, либо просто перейти на решение конкурента.
Было принято решение на начальном этапе сделать систему в форме бота,
который в живой форме может общаться с клиентом и предлагать ему ответы на
вопросы. Боты в последнее время становятся популярны, так как более привычны
человеку в обращении, чем простые каталоги с ответами на вопросы. В качестве
примера все возрастающей популярности ботов можно привести пример
кроссплатформенного мессенджера Telegram и магазин ботов для Telegram -
storebot.me.
2. Расширение метода семантической обработки информации на основе
интенсиональной логики в предметной области систем поддержки пользователей
.1 Формально-математические основания метода анализа предложений на
естественном языке
Изначально были попытки описать семантику естественного языка с помощью
исчисления предикатов. Но в ходе попыток преобразования фраз на естественном
языке в логические формулы, Монтегю столкнулся с рядом трудностей. Возникли
сложности с представлением союзов, имен прилагательных, глагольных времен и
т.д. Для преодоления такого рода трудностей Монтегю предложил использовать язык
интенсиональной логики. Основные отличия языка интенсиональной логики от
исчисления предикатов:
) Богатая структура типов выражений и частей моделей. Такие типы
есть и в исчислении предиактов, но в интенсиональной логике, они многообразнее.
Базовые типы интенсиональной логики будут рассмотрены ниже.
) Все выражения в языке интенсиональной логики представлены как
функции. Т.е. все типы, кроме основных e и t,
являются типами функций. Все выражения, кроме основных обозначают функции.
Также функции могут выступать в качестве аргументов или значений других
функций.
) Добавлена операция functional application (функциональное применение) - применение функции к ее аргументу
) Активно используются лямбда-выражения.
) Включение множества возможных миров
) Для интерпретации временных операторов используется структура
времени
В интенсиональной логике выделяется 2 базовых типа выражений: e-сущности и t-истинностные значения. Сам TYPE тип выражения определяется следующим образом [4]:
1) 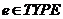
2) 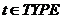
) Если 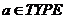 и
и 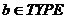 , то
, то 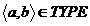
) Если 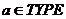 , то
, то 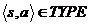
) Ничто другое, кроме перечисленного в п. 1-4, не относится к
множеству TYPE.
Таблица 1 - Типы и названия выражений интенсиональной логики
|
Тип выражения
|
Название
|
Множество семантических
значений
|
|
e
|
Индивид
|
D
|
|
<s, e>
|
Индивидный
|

|
|
t
|
Истинностное значение
|

|
|
<e, t>
|
Множества индивидов
|
|
<s,<e,
t>>
|
Свойства индивидов
|
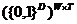
|
|
<<s,
e>, t>
|
Множества индивидных
концептов
|
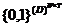
|
|
<<s,<e,
t>>, t>
|
Множества свойств индивидов
|
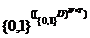
|
|
<s,t>
|
Пропозиции
|
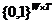
|
|
<<s,
t>, t>
|
Множества пропозиций
|
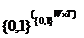
|
|
<e, <e,
t>>
|
Отношения между индивидами
|
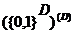
|
|
<s,<e,<e,t>>>
|
Отношения-в-интенсионале
между индивидами
|
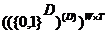
|
Для того, чтобы установить соответствие между синтаксическими категориями
и категориями интенсиональной логики, Монтегю ввел множество синтаксических
категорий формальной семантики (табл.2).
Таблица 2 - Основные категории формальной семантики
|
Категория
|
Определение
|
Грамматический эквивалент
|
Примеры
|
|
e
|
-
|
нет
|
-
|
|
t
|
-
|
Утвердительные предложения
|
Выводы сделаны верно. Ветер
усиливается.
|
|
IV (Intransitive
Verb phrase)
|
t/e
|
Глагольные фразы и
непереходные глаголы
|
Увеличиваться Помогать
|
|
T (Term phrase)
|
t/IV
|
Существительные фразы и
собственные имена
|
Леонид Вологда, Oн1,
он2…
|
|
TV (Transitive
Verb)
|
IV/T
|
Переходные глаголы
|
Определять Заимствовать
|
|
CN (Common Noun)
|
t//e
|
Нарицательные
существительные
|
Двигатель Семантика
|
|
IAV
(Intransitive adverb)
|
IV/IV
|
Наречия
|
Быстро Медленно
|
|
t/t (Sentence
Adverb)
|
|
Модальные определители
предложения
|
Необходимо-чтобы Непременно
|
|
IAV/T
|
|
Предлоги
|
В, на
|
|
DET
|
T/CN
|
Определители
|
Каждый, любой, всякий.
|
|
IV//
IV
|
|
Глаголы, образующие
инфинитивы
|
Пытаться Учиться
|
.2 Модернизация метода интенсиональной логики для русскоязычных систем
поддержки пользователей
.2.1 Построение дерева предложения для последующего семантического
анализа и выделения сущностей
Проанализировав данное предложение с помощью pymorphy2, получим следующие
характеристики слов:
) “Каждый” ('ADJF,Apro inan,masc,sing,accs') - Имя прилагательное
(полное), местоименное неодушевленное, мужской род, единственное число,
винительный падеж.
Принадлежит к категории DET.
) “охотник” ('NOUN,anim,masc sing,nomn') - Имя существительное,
одушевлённое, мужской род единственное число, именительный падеж.
Принадлежит к категории CN.
) “желает” ('VERB,impf,tran sing,3per,pres,indc') - Глагол (личная
форма), несовершенный вид, переходный, единственное число, 3 лицо, настоящее
время, изъявительное наклонение.
Принадлежит к категории TV.
) “знать” ('INFN,impf,tran') - Глагол (инфинитив), несовершенный
вид, переходный.
Принадлежит к категории TV.
) “где” ('ADVB,Ques') - Наречие, вопросительное.
Принадлежит к категории IAV.
) “сидит” ('VERB,impf,intr sing,3per,pres,indc') - Глагол (личная
форма), несовершенный вид, непереходный, единственное число, 3 лицо, настоящее
время, изъявительное наклонение.
Принадлежит к категории IV.
) “фазан” ('NOUN,anim,masc sing,nomn') - Имя существительное,
одушевлённое, мужской род единственное число, именительный падеж.
Принадлежит к категории CN.

Рисунок 7 - Древовидная структура предложения
Таким образом, можно сделать вывод, что с помощью формальной семантики
Монтегю возможно формализовать тексты на естественном русском языке.
Формализация текстов на русском языке будет отличаться от формализации текстов
на английском языке из-за их структурных различий. Для формализации текстов на
русском языке важное значение имеют как морфологический, так и синтаксический
анализ, в то время как в английском языке большую роль играет синтаксический
анализ текста. Имея достаточно большой корпус языка, такой как OpenCorpora, можно проводить качественный
морфологический анализ, который позволит с помощью категорий интенсиональной
логики формализовать естественно-языковой текст на русском языке.
.2.2 Перевод вопроса на естественном языке в формулу формальной семантики
Монтегю вводит понятие Правил трансформации, которые используются для
перевода фразы в формулу формальной семантики. Выделяется множество основных
выражений категории A - обозначенное
как ВА, а также множество фраз категории А, обозначенное как РА.
В множество РА входят все выражения и фразы, которые могут быть
составлены с помощью синтаксических правил. Приведем пример правила
трансформации для фрагмента естественного языка[5]:
1) Если 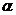 в области g, то
в области g, то 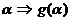 .
.
2) Если 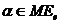 , то
, то 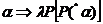 .
.
) Онn,
онаn, ониn переводятся в 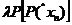 .
.
) Если  ,
, 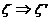 , то «любой (любая, любые)
, то «любой (любая, любые) 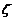 ».
».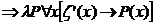
Правила применения функций
5) Если 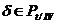 ,
, 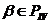 и
и  ,
, 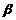 переводятся соответственно в
переводятся соответственно в  ,
, 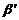 , то
, то  переводится в
переводится в 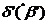 .
.
6) Если 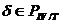 ,
, 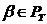 и , переводятся соответственно в , , то
и , переводятся соответственно в , , то 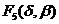 переводится в .
переводится в .
) Если 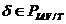 , и , переводятся соответственно в , , то переводится в .
, и , переводятся соответственно в , , то переводится в .
) Если 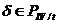 ,
, 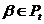 и , переводятся соответственно в , , то
и , переводятся соответственно в , , то 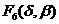 переводится в .
переводится в .
) Если 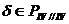 , и , переводятся соответственно в ,
, и , переводятся соответственно в , 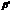 , то переводится в .
, то переводится в .
) Если 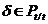 , и , переводятся соответственно в , , то переводится в .
, и , переводятся соответственно в , , то переводится в .
) Если 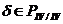 ,
, 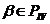 и , переводятся соответственно в , , то переводится в .
и , переводятся соответственно в , , то переводится в .
.2.3 Адаптация алгоритма поиска для текстов на русском языке
Существует 5 типов языков по морфологической типологии: аналитические,
изолирующие, синтетические, полисинтетические и олигосинтетические. Английский
язык относится к аналитическим языкам - т.е. языкам, в которых грамматические
отношения передаются в основном через синтаксис. То есть через служебные слова,
фиксированный порядок слов, контекст. В противоположность аналитическим языкам
существует тип синтетических языков. Особенностью синтетических языков является
то, что грамматические значения выражаются в пределах самого слова - то есть
формами самого слова.
Флективные языки относятся к категории синтетических и их особенностью
является то, что в языках этого типа словоизменение осуществляется с помощью
флексий. Русский язык как раз относится к категории флективных языков.
Основываясь на этом доводе, можно сделать вывод, что при определении
взаимосвязей между словами помимо синтаксиса, важную роль играет морфология и
морфологический анализ. Таким образом, требуется адаптация алгоритма Монтегю по
преобразованию фразы на естественном русском языке в формулу формальной семантики.
.2.4 Адаптация алгоритма для систем поддержки пользователей
Вследствие роста сложности ИС, возникает необходимость в создании
специальных механизмов для упрощения работы пользователя с ИС. Одним из таких
механизмов являются системы технической поддержки. Системы технической
поддержки (СТП) - это класс ИС, который обеспечивает помощь пользователю в
эффективном взаимодействии с технологическим продуктом либо услугой[7].
Системы технической поддержки выполняют следующие функции:
) Помогают пользователям максимально быстро находить ответы на
возникающие в ходе работы вопросы
) Помогают быстро находить и разрешать сбои в работе программного
обеспечения
) Производят корректировку развития продукта в соответствии с
отзывами пользователей
) Акцентируют внимание на слабых местах системы
) Позволяют определять дополнительные требования к системе
На рис. 8 представлена схема работы службы работы управления ошибками.
Первым этапом идет обнаружение инцидента - которое происходит благодаря
обращению пользователя, либо сигналу системы мониторинга. Вторым этапом
информация об ошибке логируется - записывается время обнаружения ошибки и
подробная техническая информация о том, в каких условиях произошла ошибка.
Следующий этап - возникшая ошибка определяется одной из существующих категорий,
и ей присваивается какой-то приоритет.
В текущей работе рассматривается этап работы, когда сообщение об ошибке
поступает от пользователя, и происходит поиск ответа на вопрос по текущей базе
знаний. Чаще всего ответ дается вручную специалистами по поддержке
пользователей, и СТП является только шлюзом, который передает информацию от
одного звена в цепочке - другому. Существуют различные системы по автоматизации
этого процесса. Один из примеров - helpdesk системы, в которых происходит сбор, категоризация и
отслеживание входящих запросов. Но, в конечном счете, ответ на вопрос дает
специалист.
Удобной формой взаимодействия с пользователем является чат, где
пользователь может задавать вопросы на естественном языке. Поэтому было принято
решение сделать поиск ответов на вопросы пользователя именно в форме чата.
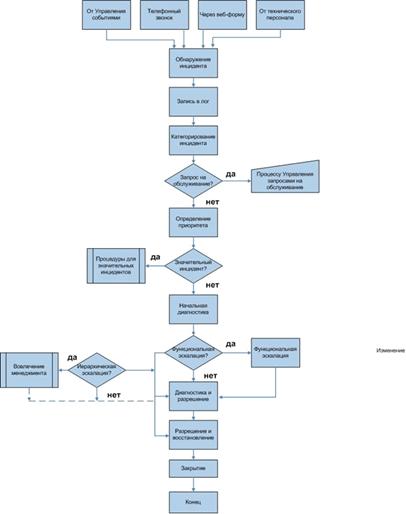
Рисунок 8 - схема управления обработкой ошибок
В текущем докладе рассказывается о возможности исключения специалиста из
цепочки ответа пользователю в тех случаях, когда ответ на вопрос уже известен и
сформулирован. Основной сложностью в данном вопросе является извлечение нужной
информации из запроса пользователя. Когда человек вводит запрос, то он
подразумевает некоторое смысловое содержание, и поиск должен происходить
непосредственно опираясь на него.
Таким образом, в данной главе была рассмотрена математическая
составляющая перевода фразы на естественном языке в формулу формальной
семантики. Было сказано о двухэтапном преобразовании и правилах логической трансформации.
Также было замечено, что для русского языка важную роль играет морфологический
анализ, на который можно опираться для определения грамматического значения
слова.
3. Модели и алгоритмы семантического поиска в мультиагентной системе
поддержки пользователей
.1 Модель мультиагентной системы семантического поиска информации в
системе FAQ (Frequently asked questions)
Для распределенных интернет-систем хорошо подходит мультиагентная
структура организации[6]. Основной особенностью мультиагентных систем является
то, что решение задач в такой системе происходит с помощью отдельных
самостоятельных программ - так называемых “агентов”. На рисунке 2 представлен
пример структуры системы технической поддержки пользователей на основе
нескольких групп «ВКонтакте», для каждой из которых поисковый запрос
формируется отдельно. Далее мы рассмотрим, что для семантического поиска с
помощью интенсиональной логики требуется предварительный анализ ответов на
вопросы с целью их обработки и представления в виде формул формальной
семантики.
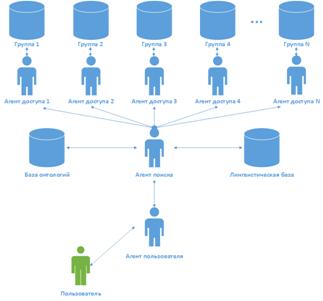
Рисунок 9 - Обобщенная структура агентно-ориентированной системы по
вопросам в социальных сетях.
В представленной схеме отображено, что центральным агентом является агент
поиска. Он взаимодействует с агентом пользователя и получает от него запрос.
Далее агент поиска взаимодействует с базой онтологий и лингвистической базой
для обработки и нахождения наиболее подходящего варианта ответа. Агенты доступа
к группам сканируют группы в социальной сети и ищут новые вопросы, которые
затем заносятся в базу отнологий.
.2 Алгоритм заполнения базы знаний
На начальном этапе работы требуется заполнение базы знаний определенной
предметной области. В базу знаний вносятся вопросы и ответы, по которым далее
будет осуществляться поиск. При заполнении каждый вопрос проходит обработку и
записывается в формализованном для поиска виде. Алгоритм заполнения представлен
на рис. 10.

Рисунок 10 - алгоритм заполнения Базы знаний
Первым этапом происходит ввод вопроса и ответа на него. Далее вопрос
проходит морфологическую обработку - определяются часть речь, начальная форма
слова и такие параметры, как падеж или склонений. На основании этих данных,
определяются главные члены предложения, которые и записываются в Базу знаний.
Поиск далее осуществляется непосредственно опираясь на главные члены
предложения, так как они содержат основную смысловую нагрузку предложения.
Часть данного алгоритма также задействована при поиске правильного и наиболее
подходящего ответа на вопрос.
.3 Алгоритм расчета и поиска наибольшего семантического веса ответа
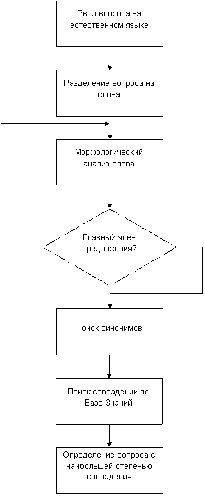
Рисунок 11 - Алгоритм поиска и расчета наибольшего семантического веса
ответа
После заполнения Базы знаний на основе наиболее общих вопросов, можно
приступать к поиску. Алгоритм работы поисковой системы представлен на рис. 11.
После того, как пользователь ввел вопрос, происходит разделение вопроса на
слова. Каждое из этих слов анализируется отдельно. Результатом анализа является
нахождение главных частей речи, по которым далее и идет поиск верного ответа.
Непосредственно вычисление семантического веса идет на основе сравнения главных
частей речи введенного пользователем вопроса и главных частей речи сохраненных
в базе знаний вопросов. При совпадении смысла какого-то из слов готового
варианта ответа и введенного вопроса, семантический вес увеличивается на
условную единицу. Чем большее значение совпадения, тем большим считается
значение семантического веса и вариант ответа является наиболее подходящим.
Таким образом, можно сделать вывод о том, что был реализован алгоритм
семантического поиска на основе формальной логики Монтегю, с учетом
особенностей русского языка. Большую роль при семантическом анализе в случае
русского языка играет морфологический анализ, так как русский язык относится к
категории флективных. При работе алгоритма большую роль играет насыщенность
базы знаний заранее подготовленными вопросами и ответами по предметной области.
Несомненно, поиск не должен строиться только на морфологическом анализе,
но в данной конкретной ситуации, морфологический анализ позволяет достаточно
дешевым способом проверить принадлежность слова той или иной категории
формальной семантики. В следующей главе рассматривается реализация алгоритма и
его тестирование.
4. Экспериментальное исследование прототипа системы поддержки
пользователей на основе семантического поиска ответов на вопросы
.1 Архитектура системы
. Система способна находить ответы находить ответы на вопросы,
заданные на естественном языке с достаточной степенью точности.
. Скорость поиска ответа на вопрос разработанной системы больше
чем у стандартного раздела с FAQ.
3. Удобство использования системы выше чем у простого раздела с FAQ.
Разработка в текущей версии представляет собой бота, который может
отвечать на вопросы по заранее известной предметной области. Знания о
предметной области загружаются в систему в виде специально организованной базы
знаний.
Для разработки приложения-бота была выбрана платформа Node.js. Эту
программную платформу можно использовать в качестве веб-сервера, и она удобна
тем, что в ее основе лежит асинхронное и событийно-ориентированное
программирование, которое позволяет писать веб-приложения для взаимодействия с
пользователем в реальном времени. Это как раз позволяет создавать
веб-приложения, которые обмениваются данными с большой частотой - как и в
случае с ботом.
В качестве базы данных используется MongoDB. MongoDB - это
документоориентированная система управления базами данных. К преимуществам этой
СУБД можно отнести скорость исполнения запросов, расширяемость и построение по
концепции документа. Построение по концепции документа очень удобно в данном
случае тем, что в будущем позволит изменять и добавлять новые поля в документы,
которые не были предусмотрены изначально.
мультиагентный интерфейс чат бот
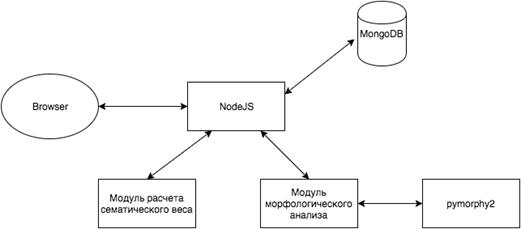
Рисунок 12 - Общая схема веб-приложения
Основная логика приложения находится на сервере под управлением nodejs.
Для морфологического анализа подключена библиотека pymorphy2, с помощью которой
можно определить базовые категории интенсиональной логики[8]. Первая версия
алгоритма сервиса опирается на морфологический анализ. В следствии того, что
русский язык относится к категории флективных языков, из данных, полученных
после морфологического анализа, можно сделать достаточное количество выводов.
Можно определить часть речи, род, число, склонение и т.п. В том числе, на
основе этих данных можно с высокой точностью, определить сказуемое и
подлежащее.
В основе первой версии алгоритма поиска как раз лежит определение главных
членов предложения. После определения главных членов предложения, происходит
поиск по совпадению в базе данных. Если оба большая часть главных членов
совпадает, то поиск считается успешным.
4.2 Программная реализация экспериментального прототипа

Рисунок 13 - Начальная форма диалога с ботом
На данный момент бот содержит информацию о веб-сервисе SmmBox и может
давать ответы на простейшие вопросы по работе сервиса. Таким образом,
уменьшается нагрузка на службу технической поддержки. Бот запущен на отдельном
сайте и на данный момент происходит тестирование, доработка и обучение бота
вопросам, поступающим по работе сервиса. Вопросы, поступающие по различным
каналам, классифицируются, обрабатываются и распределяются по категориям.

Рисунок 14 - Интерфейс чата с ботом
Основные программные решения, которые использовались при разработке:
"nodejs": "5.0.0",
"express": "4.10.2",
"semantics": "0.9.4",
"socket.io": "1.3.7"
Веб-сервис работает следующим образом:
Человек заходит на страницу поддержки SmmBox
Его встречает бот и предлагает задать вопрос
Человек вводит вопрос на естественном языке
Запрос отсылается на сервер, где обрабатывается и строится его
формализованное представление
Первая версия алгоритма сервиса опирается на морфологический анализ. В
следствии того, что русский язык относится к категории флективных языков, из
данных, полученных после морфологического анализа, можно сделать достаточное
количество выводов. Можно определить часть речи, род, число, склонение и т.п. В
том числе, на основе этих данных можно с высокой точностью, определить
сказуемое и подлежащее.
В основе первой версии алгоритма поиска как раз лежит определение главных
членов предложения. После определения главных членов предложения, происходит
поиск по совпадению в базе данных. Если оба большая часть главных членов
совпадает, то поиск считается успешным. Общая схема работы приложения
представлена на рис.15.
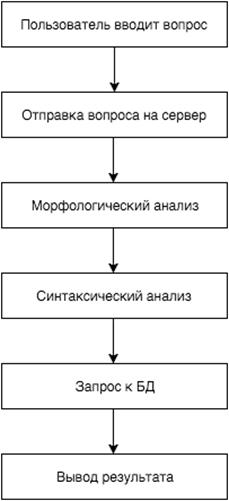
Рисунок 15 - Общий алгоритм работы приложения
Существует большое количество показателей, по которым можно оценивать
эффективность работы системы информационного поиска: это точность, полнота,
выпадение, релевантность и пертинентность. В данном случае нас интересует
последнее свойство - пертинентность. Пертинентность - это соответствие
полученной информации информационной потребности пользователя, т.е. по сути
показатель того, получил ли пользователь ответ на свой вопрос, или нет.
.3 Экспериментальные оценки релевантности и пертинентности запросов
Для тестирования были взяты по 25 вопросов из каждой категории: четко
сформулированные вопросы и вопросы без четкой формулировки.
Таблица 3 - Примеры естественно-языковых вопросов
|
Четко
сформулированный вопрос
|
Вопрос без
четкой формулировки
|
|
1
|
Как удалить мои фотографии?
|
Как возможно удалить старую
страницу, если ей уже не пользуются 4 года?
|
|
2
|
Как запретить другим людям
присылать мне сообщения?
|
Кому ни отправляю сообщения
в контакте мне пишет: пользователь запретил отправлять себе сообщение в
настройках приватности! Что это такое?
|
|
3
|
Как добавить пользователя в
черный список?
|
Здравствуйте, подскажите
можно восстановить страницу которую удалила и прошло больше 7 месяцев?
|
|
4
|
Как узнать общее количество
сообщений?
|
Каким образом мои друзья
видят мои лайки и комменты в группах, в которых не состоят и не заходят туда?
|
|
5
|
Как убрать из новостей все
репосты?
|
Не загружается изображения
в сообщениях и через приложение и через сайт
|
|
6
|
Как пригласить друга на
сайт?
|
Можете вернуть старый стиль
ВКонтакте либо оптимизировать работу нового?
|
|
7
|
Как пожаловаться
на новость?
|
Что делать если пропала
часть переписки с другом? Как её восстановить?
|
|
8
|
Как передать
голоса другу?
|
Как всё удалить то, что в
разделе "Закладки"?
|
|
9
|
Какие форматы видеозаписей
поддерживает сайт?
|
Здравствуйте, не могли бы
Вы пожалуйста заблокировать пользователя?
|
|
10
|
Как мне стать агентом
поддержки?
|
Не могу ввести с капчи
абракадабру, не разбираю символы, как убрать это при входе?
|
Сравнивались система поиска в социальной сети ВКонтакте и прототип
системы с реализованной интенсиональной логикой Монтегю. В результате теста на
четко сформулированные вопросы ответы нашлись в 100% случаев. Для вопросов без
четкой формулировки, результаты представлены в табл.2.
FAQ
«ВКонтакте» представляет собой вопросы, которые отсортированы по категориям:
доступ к странице, настройки приватности, друзья и подписчики и др. (рис.15).
Кроме того, есть система поиска ответов на вопросы. Вопросы для теста брались
из реальных источников - групп технической поддержки в этих социальных сетях.
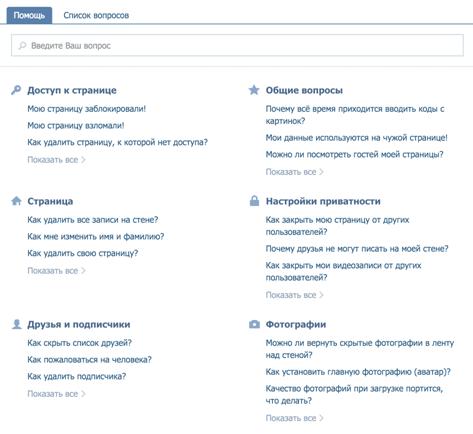
Рисунок 16 - Раздел помощи «ВКонтакте»
По результатам тестирования можно сделать вывод, что система помощи
ВКонтакте не предназначена для вопросов на естественном языке. Она хорошо ищет
по ключевым словам, но плохо работает с неструктурированными предложениями.
Прототип системы с интенсиональной логикой ищет ответы на вопросы на
естественном языке лучше, но также еще нуждается в доработке.
Таким образом, в ходе работы были исследованы подходы к анализу текста на
естественном языке. Были исследованы принципы работы в существующих системах
семантического поиска. Подробно рассматривался подход формальной семантики
Ричарда Монтегю, который был адаптирован для текстов на русском языке. На
основании теоретических исследований была спроектирована и реализована
информационная система, позволяющая проводить анализ текстов на естественном
языке.
В качестве основного применения системы рассматривается упрощение работы
системы технической поддержки и упрощение работы пользователя с FAQ (frequently
asked questions). Как правило, алгоритмы поиска, встроенные сейчас в подобные системы
опираются на совпадение слов и игнорируют смысловое содержание.
Основными причинами, почему в качестве применения были выбраны системы
поддержки являются следующие:
) Большой объем информации, содержащийся в таких системах,
затрудняет поиск ответа на нужный вопрос
) Область поиска ограничена рамками конкретной предметной области,
что делает возможным предварительный анализ и структуризацию информации.
В сравнении с подобными алгоритмами извлечения ключевых слов из текста,
адаптированных для русского языка, алгоритм показал свое преимущество
основываться не только на анализе и извлечении ключевых слов, но и на начальном
семантическом анализе. Семантический анализ оказался более структурным и
позволил более конкретно понимать смысл, содержащийся в предложении и на
основании этого смысла выполнить более точный поиск.
Несомненно, в более широких областях, где будут требоваться большие
объемы данных, такие продукты, как Inbenta или IBM Watson будут более
выигрышными, но для небольших сайтов, занимающихся конкретной специфической
деятельностью, использование бота-консультанта с семантическим анализом
входящего текста, видится более перспективным. Такой бот может быть
относительно легко построен для предметной области и сможет оказывать
необходимую помощь всем посетителям сайта.
Список источников
1. «Блог Яндекса» - Алгоритм «Палех»: как нейронные сети
помогают поиску Яндекса [Электронный ресурс] - Режим доступа:
https://yandex.ru/blog/company/algoritm-palekh-kak-neyronnye-seti-pomogayut-poisku-yandeksa
2. Хабрахабр. Блог компании Яндекс: Искусственный
интеллект в поиске. Как Яндекс научился применять электронные сети, чтобы
искать по смыслу, а не по словам. [Электронный ресурс] - Режим доступа:
https://habrahabr.ru/company/yandex/blog/314222/
3. Montague, R., «English as a formal language ,
in B. Visentini et al. (eds.), Linguaggi nella Societa et nella Technica,
Milan: Edizioni di Communita, 188-221. Reprinted in Thomason (ed.) 1974, pp.
188-221.
4. Швецов А. В. Летовальцев В. И. Программная
формализация естественного языка средствами формальной семантики // Программные
продукты и системы №3, 2010 г.
. Летовальцев В. И. Методы и алгоритмы семантической
обработки информации в корпоративных хранилищах// 2011, С. 1-235.
. Швецов А.Н., Горбунов Д.П. «Метод семантической
обработки информации в интернет-ресурсах на основе интенсиональной логики» //
Вузовская наука - региону, 111-113(2015)
. Интуит. Управление службой технической поддержки и
инцидентами [Электронный ресурс] - Режим доступа: http://www.intuit.ru/studies/courses/3704/946/lecture/15109
8. Korobov M.: Morphological Analyzer and
Generator for Russian and Ukrainian Languages // Analysis of Images, Social
Networks and Texts, pp 320-332 (2015).