Теория вероятностей и математическая статистика
Министерство
высшего и среднего специального образования Республики Узбекистан
Ташкенсткий
автомобильно-дорожный институт
Кафедра
"Высшая математика"
Тексты лекций
Теория
вероятностей и математическая статистика
М.У. Гафуров,
Р.Х. Кенджаев,
Ф.М. Закиров
Ташкент 2007
М.У. Гафуров, Р.Х. Кенджаев, Ф.М. Закиров
Теория вероятностей и математическая статистика. 2007 г. -124 стр.
В основу текстов лекций положен семестровый курс теории вероятностей и
математической статистики, читаемый авторами в течение ряда лет в Ташкенстком
автомобильно-дорожном институте. В сборнике основные понятия и факты теории
вероятностей и математической статистики первоначально вводятся для конечных
схем. Далее утверждения и формулы легко переводятся на общий случай. Приведенные
теоретические материалы проиллюстрированы большим числом примеров прикладного
содержания. вероятность выборка числовой корреляционный
В сборнике лекций содержатся следующие разделы: пространство случайных
событий, случайные величины и их числовые характеристики, предельные теоремы,
элементы выборочного пространства, точечное и интервальное статистическое
оценивание, элементы корреляционного и регрессионного анализа, а также проверка
статистических гипотез.
Настоящий сборник рассчитан для студентов экономических специальностей
высших экономических и технических учебных заведений, а также для всех
заинтересованных в освоении вероятностных методов решения практических задач.
Рецензенты: А.А. Абдушукуров - заведующий кафедрой "Теория вероятностей и математическая
статистика" Национального Университета Узбекистана, доктор
физико-математических наук,
Х. Валиджанов - доцент кафедры "Высшая математика" Ташкенсткого автомобильно-дорожного
института, кандидат физико-математических наук
Утверждено на заседании Научно-методического совета естественных и
инженерных наук ТАДИ (протокол №7 от 21 февраля 2007 года).
Оглавление
1. Предмет
теории вероятностей и ее значение для решения экономических, технических задач.
Вероятность и ее определение
. Операции
над событиями. Условная вероятность
. Теоремы
сложения и умножения вероятностей. Формулы полной вероятности и Байеса
.
Последовательность независимых испытаний. Локальная и интегральная теоремы
Лапласа
. Дискретные
случайные величины. Закон распределения. Виды дискретных распределений
. Числовые
характеристики дискретных случайных величин и их свойства
. Функции
распределения и плотности непрерывных случайных величин, их свойства
. Числовые
характеристики непрерывных случайных величин. Виды непрерывных распределений
. Закон
больших чисел и его практическое значение. Понятие о центральной предельной
теореме
. Предмет и
основные задачи математической статистики. Выборка
.
Статистическое распределение выборки. Эмпирическая функция распределения.
Полигон и гистограмма
.
Статистическая оценка. Требования, предъявляемые к статистической оценке.
Выборочное среднее и выборочная дисперсия
.
Интервальные оценки. Доверительный интервал. Доверительные интервалы для
неизвестных параметров нормального распределения
. Элементы корреляционного
и регрессионного анализа
. Выборочный
коэффициент корреляции и его свойства
.
Статистические гипотезы и их классификация. Статистический критерий
. Критерии
согласия
Список
литературы
1. Предмет теории вероятностей и ее значение для решения экономических,
технических задач. Вероятность и ее определение
На протяжении длительного времени человечество изучало и использовало для
своей деятельности лишь так называемые детерминистические закономерности.
Однако, поскольку случайные события врываются в нашу жизнь помимо нашего
желания и постоянно окружают нас, и более того, поскольку почти все явления
природы имеют случайный характер, необходимо научиться их изучать и разработать
для этой цели методы изучения.
По форме проявления причинных связей законы природы и общества делятся на
два класса: детерминированные (предопределенные) и статистические.
Например, на основании законов небесной механики по известному в
настоящем положению планет Солнечной системы может быть практически однозначно
предсказано их положение в любой наперед заданный момент времени, в том числе
очень точно могут быть предсказаны солнечные и лунные затмения. Это пример
детерминированных законов.
Вместе с тем не все явления поддаются точному предсказанию. Так,
долговременные изменения климата, кратковременные изменения погоды не являются
объектами для успешного прогнозирования, т.е. многие законы и закономерности
гораздо менее вписываются в детерминированные рамки. Такого рода законы
называются статистическими. Согласно этим законам, будущее состояние системы
определяется не однозначно, а лишь с некоторой вероятностью.
Теория вероятностей, как и другие математические науки, возродилась и
развилась из потребностей практики. Она занимается изучением закономерностей,
присущих массовым случайным событиям.
Теория вероятностей изучает свойства массовых случайных событий,
способных многократно повторяться при воспроизведении определенного комплекса
условий. Основное свойство любого случайного события, независимо от его
природы, - мера, или вероятность его осуществления.
Наблюдаемые нами события (явления) можно подразделить на три вида:
достоверные, невозможные и случайные.
Достоверным называют событие, которое обязательно произойдет. Невозможным
называют событие, которое заведомо не произойдет. Случайным называют событие,
которое может либо произойти, либо не произойти.
Теория вероятностей не ставит перед собой задачу предсказать, произойдет
единичное событие или нет, так как невозможно учесть влияние на случайное
событие всех причин. С другой стороны, оказывается, что достаточно большое
число однородных случайных событий, независимо от их конкретной природы,
подчиняется определенным закономерностям, а именно - вероятностным
закономерностям.
Итак, предметом теории вероятностей является изучение вероятностных
закономерностей массовых однородных случайных событий.
Некоторые задачи, относящиеся к массовым случайным явлениям, пытались
решать, используя соответствующий математический аппарат, еще в начале ХVII в.
Изучая ход и результаты различных азартных игр, Б. Паскаль, П. Ферма и Х.
Гюйгенс в середине XVII века заложили основы классической теории вероятностей.
В своих работах они неявно использовали понятия вероятности и математического
ожидания случайной величины. Только в начале XVIII в. Я. Бернулли формулирует
понятие вероятности.
Дальнейшими успехами теория вероятностей обязана Муавру, Лапласу, Гауссу,
Пуассону и др.
В развитие теории вероятностей огромный вклад внесли русские и советские
математики, такие как П.Л. Чебышев, А.А. Марков, А.М. Ляпунов, С.Н. Бернштейн,
А.Н. Колмогоров, А.Я. Хинчин, А. Прохоров и др.
Особое место в развитии теории вероятностей принадлежит и узбекистанской
школе, яркими представителями которой являются академики В.И. Романовский, С.Х.
Сираждинов, Т.А. Сарымсаков, Т.А. Азларов, Ш.К. Фарманов, профессора И.С.
Бадалбаев, М.У. Гафуров, Ш.А. Хашимов и др.
Как уже было отмечено, потребности практики, способствовав зарождению
теории вероятностей, питали ее развитие как науки, приводя к появлению все
новых ее ветвей и разделов. На теорию вероятностей опирается математическая
статистика, задача которой состоит в том, чтобы по выборке восстановить с
определенной степенью достоверности характеристики, присущие генеральной
совокупности. От теории вероятностей отделились такие отрасли науки, как теория
случайных процессов, теория массового обслуживания, теория информации, теория
надежности, эконометрическое моделирование и др.
В качестве важнейших сфер приложения теории вероятностей можно указать
экономические, технические науки. В настоящее время трудно себе представить
исследование экономико-технических явлений без моделирований, опирающихся на
теорию вероятностей, без моделей корреляционного и регрессионного анализа,
адекватности и "чувствительных" адаптивных моделей.
События, происходящие в автомобильных потоках, степень надежности
составных частей машин, автокатастрофы на дорогах, различные ситуации в
процессе проектирования дорог ввиду их недетерминированности входят в круг
проблем, исследуемых посредством методов теории вероятностей.
Основные понятия теории вероятностей - это опыт или эксперимент и
события. Действия, которые осуществляются при определенных условиях и
обстоятельствах, мы назовем экспериментом. Каждое конкретное осуществление
эксперимента называется испытанием.
Всякий
мыслимый результат эксперимента называется элементарным событием и обозначается
через 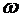 . Случайные события состоят из некоторого числа
элементарных событий и обозначаются через A, B, C, D,...
. Случайные события состоят из некоторого числа
элементарных событий и обозначаются через A, B, C, D,...
Множество
элементарных событий таких, что
)
в результате проведения эксперимента всегда происходит одно из
элементарных событий ;
)
при одном испытании произойдет только одно элементарное событие называется пространством элементарных событий и
обозначается через 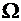 .
.
Таким
образом, любое случайное событие является подмножеством пространства
элементарных событий. По определению пространства элементарных событий
достоверное событие можно обозначить через .
Невозможное событие обозначается через  .
.
Пример 1. Бросается игральная кость. Пространство элементарных событий,
отвечающее данному эксперименту, имеет следующий вид:
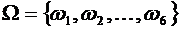 .
.
Пример
2. Пусть в урне содержатся 2 красных, 3 синих и 1 белый, всего 6 шаров.
Эксперимент состоит в том, что из урны вынимаются наудачу шары. Пространство
элементарных событий, отвечающее данному эксперименту, имеет следующий вид:
,
где
элементарные события имеют следующие значения: 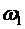 -
появился белый шар;
-
появился белый шар; 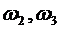 - появился красный шар;
- появился красный шар; 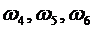 - появился синий шар. Рассмотрим следующие события:
- появился синий шар. Рассмотрим следующие события:
А
- появление белого шара;
В
- появление красного шара;
С
- появление синего шара;- появление цветного (небелого) шара.
Здесь мы
видим, что каждое из этих событий обладает той или иной степенью возможности:
одни - большей, другие - меньшей. Очевидно, что степень возможности события В
больше, чем события А; события С - чем события В; события D - чем события С.
Чтобы количественно сравнивать между собой события по степени их возможности,
очевидно, нужно с каждым событием связать определенное число, которое тем
больше, чем более возможно событие.
Это
число обозначим через 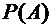 и назовем вероятностью события А. Дадим теперь
определение вероятности.
и назовем вероятностью события А. Дадим теперь
определение вероятности.
Пусть
пространство элементарных событий является
конечным множеством и элементы его суть 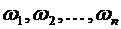 . Будем
считать, что они являются равновозможными элементарными событиями, т.е. каждое
элементарное событие не имеет больше шансов появления, чем другие. Как
известно, каждое случайное событие А состоит из элементарных событий как
подмножество . Эти элементарные события называются
благоприятствующими для А.
. Будем
считать, что они являются равновозможными элементарными событиями, т.е. каждое
элементарное событие не имеет больше шансов появления, чем другие. Как
известно, каждое случайное событие А состоит из элементарных событий как
подмножество . Эти элементарные события называются
благоприятствующими для А.
Вероятность
события А определяется формулой
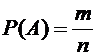 , (1.1)
, (1.1)
где
m - число благоприятствующих элементарных событий для А, n - число всех
элементарных событий, входящих в .
Если в примере 1 через А обозначить событие, состоящее в том, что выпадет
четное число очков, то
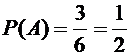 .
.
В
примере 2 вероятности событий имеют следующие значения:
 ;
; 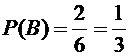 ;
; 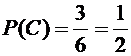 ;
; 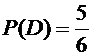 .
.
Из определения вероятности вытекают следующие ее свойства:
. Вероятность достоверного события равна единице.
Действительно, если событие достоверно, то все элементарные события
благоприятствуют ему. В этом случае m=n и, следовательно,
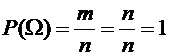 .
.
.
Вероятность невозможного события равна нулю.
Действительно,
если событие невозможно, то ни одно элементарное событие не благоприятствует
ему. В этом случае m=0 и, следовательно,
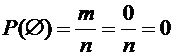 .
.
.
Вероятность случайного события есть положительное число, заключенное между
нулем и единицей.
Действительно,
случайному событию благоприятствует лишь часть из общего числа элементарных
событий. В этом случае 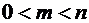 , а значит,
, а значит, 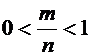 и,
следовательно,
и,
следовательно,
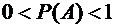 .
.
Итак,
вероятность любого события удовлетворяет неравенствам
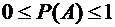 . (1.2)
. (1.2)
Относительной
частотой события называют отношение числа испытаний, в которых событие
появилось, к общему числу фактически произведенных испытаний.
Таким
образом, относительная частота события А определяется формулой
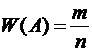 , (1.3)
, (1.3)
где
т - число появлений события, п - общее число испытаний.
Сопоставляя
определения вероятности и относительной частоты, заключаем: определение
вероятности не требует, чтобы испытания производились в действительности;
определение же относительной частоты предполагает, что испытания были
произведены фактически.
Пример
3. Из 80 случайно отобранных одинаковых деталей выявлено 3 бракованных.
Относительная частота бракованных деталей равна
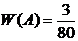 .
.
Пример
4. В течение года на одном из объектов было проведено 24 проверки, причем было
зарегистрировано 19 нарушений законодательства. Относительная частота нарушений
законодательства равна
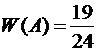 .
.
Длительные
наблюдения показали, что если в одинаковых условиях производятся опыты, в
каждом из которых число испытаний достаточно велико, то относительная частота
изменяется мало (тем меньше, чем больше произведено испытаний), колеблясь около
некоторого постоянного числа. Оказалось, что это постоянное число есть
вероятность появления события.
Таким
образом, если опытным путем установлена относительная частота, то полученное
число можно принять за приближенное значение вероятности. Это есть
статистическое определение вероятности.
В
заключении рассмотрим геометрическое определение вероятности.
Если
пространство элементарных событий рассматривать
как некоторую область на плоскости или в пространстве, а А как ее подмножество,
то вероятность события А будет рассматриваться как отношение площадей или
объемов А и , и находиться по следующим формулам:
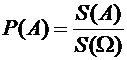 , (1.4)
, (1.4)
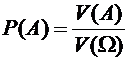 . (1.5)
. (1.5)
Вопросы для повторения и контроля:
1. На какие классы делятся законы природы и общества по форме
проявления причинных связей?
2. На какие виды можно подразделить события?
. Что является предметом теории вероятностей?
. Что вы знаете об истории развития теории вероятностей?
. Каково значение теории вероятностей для экономических,
технических задач?
. Что такое эксперимент, испытание, элементарное событие и
событие, как они обозначаются?
. Что называется пространством элементарных событий?
. Как определяется вероятность события?
. Какие свойства вероятности вы знаете?
10. Что вы знаете об относительной частоте события?
11. В чем сущность статистического определения вероятности?
12. Каково геометрическое определение вероятности?
. Операции над событиями. Условная вероятность
Часто возникает вопрос: насколько связаны два случайных события А и В
друг с другом, в какой мере наступление одного из них влияет на возможность
наступления другого?
В качестве примера связи между двумя событиями можно привести случаи,
когда наступление одного из событий ведет к обязательному осуществлению другого
или же, наоборот, когда наступление одного события исключает шансы другого.
Если в результате эксперимента события А и В не могут наступить
одновременно, то они называются несовместными событиями, в противном случае
совместными.
Пример 1. Из ящика с деталями наудачу извлечена деталь. То, что она
стандартна, исключает ее нестандартность. События "Наудачу извлеченная
деталь стандартна" и "Наудачу извлеченная деталь нестандартна" -
несовместные.
Если события рассматривать как подмножества пространства элементарных
событий, то отношения между событиями можно интерпретировать как соотношения
между множествами. Несовместные события - это такие события, которые не
содержат общих элементарных событий.
Говорят,
что событие А влечет за собой событие В, если в результате эксперимента из
наступления события А обязательно следует наступление события В, и обозначают это
через 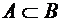 . Если и
. Если и 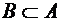 , то
, то 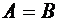 .
.
Пример
2. Бросается игральная кость. Событие "выпало 4" влечет за собой
событие "выпало четное число очков".
Суммой
двух событий А и В называют событие, состоящее в наступлении события А или
события В, или обоих этих событий. Оно обозначается через А+В или 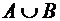 . Суммой нескольких событий называют событие, которое
состоит в наступлении хотя бы одного из этих событий.
. Суммой нескольких событий называют событие, которое
состоит в наступлении хотя бы одного из этих событий.
Пример
3. Из орудия производится два выстрела. Если А - попадание при первом выстреле,
а В - попадание при втором выстреле, то А+В - попадание при первом выстреле,
или при втором, или в обоих выстрелах.
Произведением
двух событий А и В называют событие, состоящее в совместном наступлении событий
А и В. Оно обозначается через АВ или 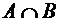 .
Произведением нескольких событий называют событие, состоящее в совместном
наступлении всех этих событий.
.
Произведением нескольких событий называют событие, состоящее в совместном
наступлении всех этих событий.
Пример
4. В ящике содержатся детали, изготовленные заводами №1 и №2. Если А -
появление стандартной детали, а В - деталь изготовлена заводом №1, то АВ -
появление стандартной детали завода №1.
Противоположное
событие для события А обозначается через 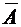 . Оно
считается наступившим тогда и только тогда, когда А не наступает. Иными
словами, А и - это такие несовместные события, которые вместе
образуют достоверное событие, т.е.
. Оно
считается наступившим тогда и только тогда, когда А не наступает. Иными
словами, А и - это такие несовместные события, которые вместе
образуют достоверное событие, т.е.
 .
.
Пример
5. Попадание и промах при выстреле по цели - противоположные события. Если А -
попадание, то - промах.
Событие,
которое представляет собой наступление события А и не наступление события В,
называется разностью событий А и В, и обозначается через A\В.
Два
события называют независимыми, если вероятность одного из них не зависит от
наступления или ненаступления другого. В противном случае эти события
называются зависимыми.
Пример
6. Монета брошена 2 раза. Вероятность появления герба при первом бросании
(событие А) не зависит от появления герба при втором бросании (событие В). В
свою очередь, вероятность выпадения герба при втором бросании не зависит от
результата первого бросания. Таким образом, события А и В - независимы.
Несколько
событий называют попарно независимыми, если любые два из них взаимно
независимы.
Пусть
А и В - два случайных события, причем 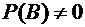 . Из
определения зависимых событий следует, что вероятность одного из событий
зависит от наступления или ненаступления другого. Поэтому, если нас интересует
вероятность события А, то важно знать, наступило ли событие В.
. Из
определения зависимых событий следует, что вероятность одного из событий
зависит от наступления или ненаступления другого. Поэтому, если нас интересует
вероятность события А, то важно знать, наступило ли событие В.
Вероятность
события А при условии, что произошло событие В, называется условной
вероятностью и обозначается через 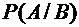 .
.
Пример
7. В урне содержится 3 белых и 3 черных шара. Из урны дважды вынимают наудачу
по одному шару, не возвращая их в урну. Найти вероятность появления белого шара
при втором испытании (событие А), если при первом испытании был извлечен черный
шар (событие В).
Решение.
После первого испытания в урне осталось всего 5 шаров, из них 3 белых. Искомая
условная вероятность равна
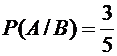 .
.
Выведем
теперь формулу условной вероятности. Пусть событиям А и В благоприятствуют
соответственно m и k элементарных событий из n; тогда, согласно (1.1), их
безусловные вероятности равны 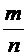 и
и 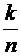 соответственно. Пусть событию А при условии, что
событие В произошло, благоприятствуют r элементарных событий, тогда, согласно
(1.1), условная вероятность события А равна
соответственно. Пусть событию А при условии, что
событие В произошло, благоприятствуют r элементарных событий, тогда, согласно
(1.1), условная вероятность события А равна
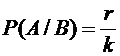 .
.
Разделив
и числитель, и знаменатель на n, получим формулу условной вероятности

Или
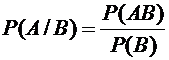 . (2.1)
. (2.1)
поскольку
событию АВ соответствуют r элементарных событий и, следовательно, 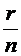 - его безусловная вероятность.
- его безусловная вероятность.
Вопросы для повторения и контроля:
1. Какие события называются несовместными, а какие совместными?
2. Что означает выражение "событие А влечет за собой событие
В" и как оно обозначается?
. Что называется суммой событий и как оно обозначается?
. Что называется произведением событий и как оно обозначается?
. Что такое противоположное событие и как оно обозначается?
. Что называется разностью событий и как оно обозначается?
. Какие события называются независимыми, а какие зависимыми?
. Что такое условная вероятность и какова ее формула?
. Теоремы сложения и умножения вероятностей. Формулы полной вероятности и
Байеса
Пусть события А и В - несовместные, причем вероятности этих событий даны.
Как найти вероятность того, что наступит либо событие А, либо событие В, т.е.
вероятность суммы этих событий А+В? Ответ на этот вопрос дает следующая
теорема.
Теорема 3.1 (сложения вероятностей несовместных событий). Вероятность
суммы двух несовместных событий равна сумме вероятностей этих событий:
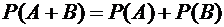 . (3.1)
. (3.1)
Доказательство.
Введем обозначения:
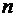 - общее
число элементарных событий;
- общее
число элементарных событий;
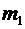 - число
элементарных событий, благоприятствующих событию А;
- число
элементарных событий, благоприятствующих событию А;
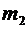 - число
элементарных событий, благоприятствующих событию В.
- число
элементарных событий, благоприятствующих событию В.
Число
элементарных событий, благоприятствующих наступлению либо события А, либо
события В, равно 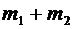 . Следовательно,
. Следовательно,
 .
.
Приняв
во внимание, что 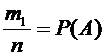 и
и 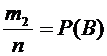 ,
окончательно получим
,
окончательно получим
.
Следствие
3.1. Вероятность суммы нескольких несовместных событий равна сумме вероятностей
этих событий:
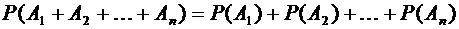 . (3.2)
. (3.2)
Пример
1. В урне 30 шаров: 10 красных, 5 синих и 15 белых. Найти вероятность появления
цветного шара.
Решение.
Появление цветного шара означает появление либо красного, либо синего шара.
Вероятность
появления красного шара (событие А)
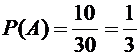 .
.
Вероятность
появления синего шара (событие В)
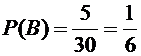 .
.
События
А и В несовместны (появление шара одного цвета исключает появление шара другого
цвета), поэтому искомая вероятность равна
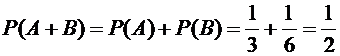 .
.
Так
как противоположные события вместе образуют достоверное событие, то из теоремы
3.1 вытекает, что
 ,
,
поэтому
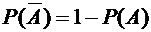 . (3.3)
. (3.3)
Пример
2. Вероятность того, что день будет дождливым, равна 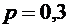 . Найти вероятность того, что день будет ясным.
. Найти вероятность того, что день будет ясным.
Решение.
События "день дождливый" и "день ясный" - противоположные,
поэтому искомая вероятность равна
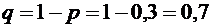 .
.
Из
формулы (2.1) получаем следующую теорему.
Теорема
3.2 (умножения вероятностей зависимых событий). Вероятность произведения двух
зависимых событий равна произведению вероятности одного из них на условную
вероятность другого, вычисленную в предположении, что первое событие уже
наступило:
 . (3.4)
. (3.4)
Пример
3. У сборщика имеется 3 конусных и 7 эллиптических валиков. Сборщик наудачу
взял один валик, а затем второй. Найти вероятность того, что первый из взятых
валиков - конусный, а второй - эллиптический.
Решение.
Вероятность
того, что первый из взятых валиков окажется конусным (событие В), равна
 .
.
Условная
вероятность того, что второй из валиков окажется эллиптическим (событие А),
вычисленная в предположении, что первый валик - конусный, равна
 .
.
Тогда
по формуле (3.4) искомая вероятность равна
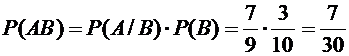 .
.
Теперь
перейдем к случаю, когда события А и В - независимые, и найдем вероятность
произведения этих событий.
Так
как событие А не зависит от события В, то его условная вероятность равна его безусловной вероятности , т.е.
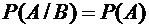 .
.
Отсюда
вытекает следующая теорема.
Теорема
3.3 (умножения вероятностей независимых событий). Вероятность произведения двух
независимых событий равна произведению вероятностей этих событий:
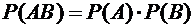 . (3.5)
. (3.5)
Следствие
3.2. Вероятность произведения нескольких независимых событий равна произведению
вероятностей этих событий:
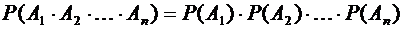 .
.
Пример
4. Имеется 3 ящика, содержащих по 10 деталей. В первом ящике 8, во втором 7 и в
третьем 9 стандартных деталей. Из каждого ящика наудачу вынимают по одной
детали. Найти вероятность того, что все три вынутые детали окажутся
стандартными.
Решение.
Вероятность того, что из первого ящика вынута стандартная деталь (событие А),
равна
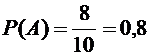 .
.
Вероятность
того, что из второго ящика вынута стандартная деталь (событие В), равна
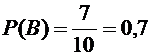 .
.
Вероятность
того, что из третьего ящика вынута стандартная деталь (событие С), равна
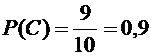 .
.
Так
как события А, В и С - независимые, то искомая вероятность по теореме умножения
вероятностей независимых событий равна
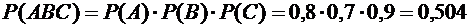 .
.
Теперь
перейдем к случаю, когда события А и В - совместные, и найдем вероятность суммы
этих событий.
Теорема
3.4 (сложения вероятностей совместных событий). Вероятность суммы двух
совместных событий равна сумме вероятностей этих событий с вычетом вероятности
их произведения:
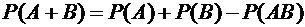 . (3.6)
. (3.6)
Пример
5. Вероятности попадания в цель при стрельбе первого и второго орудий
соответственно равны: 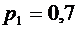 ;
; 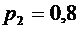 . Найти
вероятность попадания при одном залпе (из обоих орудий) хотя бы одним из
орудий.
. Найти
вероятность попадания при одном залпе (из обоих орудий) хотя бы одним из
орудий.
Решение.
Вероятность попадания в цель каждым из орудий не зависит от результата стрельбы
из другого орудия, поэтому события А (попадание первого орудия) и В (попадание
второго орудия) независимы.
Вероятность
события АВ (оба орудия дали попадание), равна
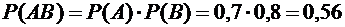 .
.
Искомая
вероятность равна
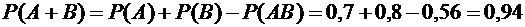 .
.
Если
независимые события 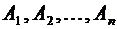 вместе образуют достоверное событие, то вероятность
появления хотя бы одного из этих событий можно найти по формуле
вместе образуют достоверное событие, то вероятность
появления хотя бы одного из этих событий можно найти по формуле
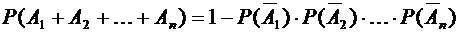 (3.7)
(3.7)
Пример
6. В типографии имеются 4 машины. Для каждой машины вероятность того, что она
работает в данный момент, равна 0,9. Найти вероятность того, что в данный
момент работает хотя бы одна машина (событие А).
Решение.
Вероятность того, что машина в данный момент не работает, равна
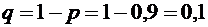 .
.
Тогда
искомая вероятность равна
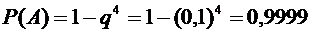 .
.
Говорят,
что события образуют полную группу событий, если они несовместны
и вместе образуют достоверное событие, т.е. 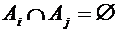 ,
, 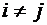 ;
; 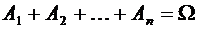 .
.
Предположим,
что событие А может наступить только при условии появления одного из событий 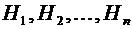 , образующих полную группу, которые назовем
гипотезами. Пусть известны вероятности этих событий и условные вероятности
, образующих полную группу, которые назовем
гипотезами. Пусть известны вероятности этих событий и условные вероятности 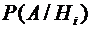 ,
, 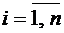 .
.
Так
как 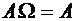 , то
, то
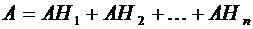 .
.
Из
несовместности вытекает несовместность событий 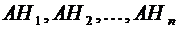 .
.
Применяя
формулу (3.1), имеем
 .
.
Согласно
формуле (3.4) (так как события могут
быть и зависимыми), заменив каждое слагаемое 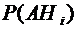 в правой
части последнего выражения произведением
в правой
части последнего выражения произведением 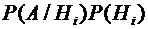 , получим
формулу полной вероятности
, получим
формулу полной вероятности
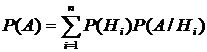 . (3.8)
. (3.8)
Пример
7. Имеется два набора деталей. Вероятность того, что деталь первого набора
стандартна, равна 0,8, а второго - 0,9. Найти вероятность того, что взятая
наудачу деталь из наудачу взятого набора - стандартная.
Решение.
Обозначим через А событие "извлеченная деталь стандартна". Деталь
может быть извлечена либо из первого набора (событие 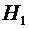 ), либо из второго набора (событие
), либо из второго набора (событие  ).
).
Вероятность
того, что деталь будет вынута из первого набора, равна
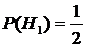 .
.
Вероятность
того, что деталь будет вынута из второго набора, равна
 .
.
По
условиям задачи 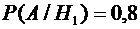 и
и 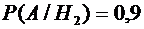 .
.
Тогда
искомая вероятность находится по формуле полной вероятности и равна
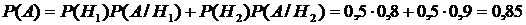 .
.
Пусть
теперь для тех же событий, что и при выводе формулы полной вероятности,
появилось событие А, и ставится задача отыскать условные вероятности гипотез 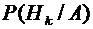 ,
,  .
.
Из
формулы (2.1) имеем
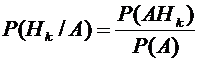 .
.
Далее,
из формулы (3.4) получаем
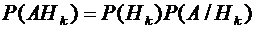 .
.
Отсюда
и из предыдущего соотношения, применяя формулу полной вероятности, выводим
формулу Байеса:
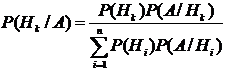 (3.9)
(3.9)
Пример
8. Детали, изготовляемые цехом завода, попадают для проверки их на
стандартность к одному из двух контролеров. Вероятность того, что деталь
попадет к первому контролеру, равна 0,6, а ко второму - 0,4. Вероятность того,
что годная деталь будет признана стандартной первым контролером, равна 0,94, а
вторым - 0,98. Годная деталь при проверке была признана стандартной. Найти
вероятность того, что эту деталь проверил первый контролер.
Решение.
Обозначим через А событие, состоящее в том, что годная деталь признана
стандартной. Можно сделать два предположения:
) деталь
проверил первый контролер (гипотеза );
) деталь
проверил второй контролер (гипотеза ).
По условиям задачи имеем:
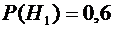 (вероятность
того, что деталь попадет к первому контролеру);
(вероятность
того, что деталь попадет к первому контролеру);
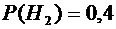 (вероятность
того, что деталь попадет ко второму контролеру);
(вероятность
того, что деталь попадет ко второму контролеру);
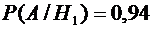 (вероятность
того, что годная деталь будет признана стандартной первым контролером);
(вероятность
того, что годная деталь будет признана стандартной первым контролером);
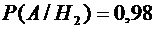 (вероятность
того, что годная деталь будет признана стандартной вторым контролером).
(вероятность
того, что годная деталь будет признана стандартной вторым контролером).
Искомую
вероятность найдем по формуле Байеса
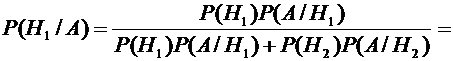
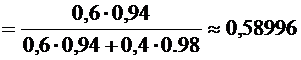 .
.
Вопросы для повторения и контроля:
1. О чем теорема сложения вероятностей несовместных событий и
каково ее доказательство?
2. Чему равна вероятность противоположного события?
. О чем идет речь в теоремах умножения вероятностей зависимых и
независимых событий?
. О чем теорема сложения вероятностей совместных событий?
. Как можно найти вероятность появления хотя бы одного события?
. Какие события образуют полную группу событий?
. Что такое формула полной вероятности и как она выводится?
. Что такое формула Байеса и как она выводится?
Опорные слова:
Вероятность суммы несовместных событий, вероятность противоположного
события, вероятность произведения зависимых событий, вероятность произведения
независимых событий, вероятность суммы несовместных событий, вероятность появления хотя бы одного
события, полная группа событий, гипотезы, формула полной вероятности, формула
Байеса.
. Последовательность независимых испытаний. Локальная и интегральная
теоремы Лапласа
Пусть производится n независимых испытаний, в каждом из которых событие А
может либо произойти (успех), либо не произойти (неудача). Будем считать, что
вероятность события А в каждом испытании одна и та же, а именно равна р.
Следовательно, вероятность ненаступления события А в каждом испытании
также постоянна и равна q=1-p. Такая последовательность испытаний называется
схемой Бернулли.
В качестве таких испытаний можно рассматривать, например, производство
изделий на определенном оборудовании при постоянстве технологических и
организационных условий, в этом случае изготовление годного изделия - успех,
бракованного - неудача.
Эта ситуация соответствует схеме Бернулли, если считать, что процесс
изготовления одного изделия не зависит от того, были годными или бракованными
предыдущие изделия.
Другим примером является стрельба по мишени.
Здесь попадание - успех, промах - неудача.
Поставим своей задачей вычислить вероятность того, что при n испытаниях
событие А осуществится ровно k раз и, следовательно, не осуществится n-k раз,
т.е. будет k успехов и n-k неудач.
Искомую
вероятность обозначим 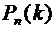 . Например, символ
. Например, символ 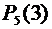 означает
вероятность того, что в пяти испытаниях событие появится ровно 3 раза и,
следовательно, не наступит 2 раза.
означает
вероятность того, что в пяти испытаниях событие появится ровно 3 раза и,
следовательно, не наступит 2 раза.
Последовательность
п независимых испытаний можно рассматривать как сложное событие, являющееся
произведением п независимых событий. Следовательно, вероятность того, что в п
испытаниях событие А наступит k раз и не наступит n-k раз, по теореме 3.3
умножения вероятностей независимых событий, равна
 .
.
Таких
сложных событий может быть столько, сколько можно составить сочетаний из п
элементов по k элементов, т.е. 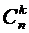 .
.
Так как эти сложные события несовместны, то по теореме 3.1 сложения
вероятностей несовместных событий, искомая вероятность равна сумме вероятностей
всех возможных сложных событий.
Поскольку же вероятности всех этих сложных событий одинаковы, то искомая
вероятность (появление k раз события А в п испытаниях) равна вероятности одного
сложного события, умноженной на их число
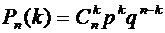
Или
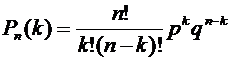 (4.1)
(4.1)
Полученную
формулу называют формулой Бернулли.
Пример
1. Вероятность того, что расход электроэнергии на продолжении одних суток не
превысит установленной нормы, равна 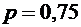 . Найти
вероятность того, что в течение 4 суток из ближайших 6 суток расход
электроэнергии не превысит нормы.
. Найти
вероятность того, что в течение 4 суток из ближайших 6 суток расход
электроэнергии не превысит нормы.
Решение.
Вероятность нормального расхода электроэнергии на продолжении каждых из 6 суток
постоянна и равна . Следовательно, вероятность перерасхода
электроэнергии в каждые сутки также постоянна и равна
 .
.
Искомая
вероятность по формуле Бернулли равна
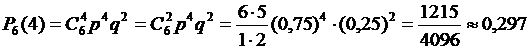 .
.
В
ряде задач представляет интерес наивероятнейшее число успехов, т.е. такое число
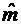 успехов, вероятность которого самая большая среди
вероятностей (4.1). Так как при увеличении k вероятности (4.1) сначала
возрастают, а затем, с определенного момента, начинают убывать, то для должны иметь место соотношения
успехов, вероятность которого самая большая среди
вероятностей (4.1). Так как при увеличении k вероятности (4.1) сначала
возрастают, а затем, с определенного момента, начинают убывать, то для должны иметь место соотношения
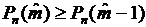 (4.2)
(4.2)
И
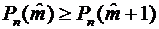 . (4.3)
. (4.3)
Используя
формулу (4.1) и соотношение 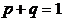 , из
(4.2) и (4.3) получаем соответственно неравенства
, из
(4.2) и (4.3) получаем соответственно неравенства
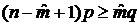 (4.4)
(4.4)
И
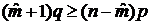 . (4.5)
. (4.5)
Окончательно
получаем, что лежит в интервале единичной длины:
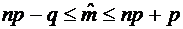 . (4.6)
. (4.6)
Однако,
стоит заметить, что использование формулы Бернулли при больших значениях п
достаточно трудно, так как формула требует выполнения действий над громадными
числами.
Например,
если 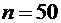 ,
, 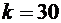 ,
, 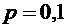 , то для отыскания вероятности
, то для отыскания вероятности  надо вычислить выражение
надо вычислить выражение
 , где
, где 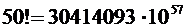 ,
, 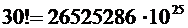 ,
,  .
.
Естественно
возникает вопрос: нельзя ли вычислить интересующую нас вероятность, не прибегая
к формуле Бернулли? Оказывается можно. Локальная теорема Лапласа и дает
асимптотическую формулу, которая позволяет приближенно найти вероятность
появления события ровно k раз в n испытаниях, если число испытаний достаточно
велико.
Локальная
теорема Лапласа. Если вероятность р появления события А в каждом испытании
постоянна и отлична от нуля и единицы, то вероятность того, что событие А появится в п испытаниях ровно k
раз, приближенно равна (тем точнее, чем больше п) значению функции
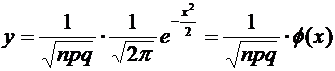
при
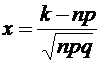 .
.
Имеются
таблицы, в которых помещены значения функции 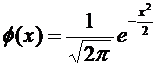 .
При этом следует учитывать, что
.
При этом следует учитывать, что 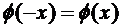 , так как
функция
, так как
функция 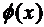 четна.
четна.
Итак,
вероятность того, что событие А появится в п независимых испытаниях ровно k
раз, приближенно равна
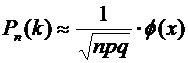 , (4.7)
, (4.7)
где
.
Пример
2. Найти вероятность того, что событие А наступит ровно 80 раз в 400
испытаниях, если вероятность появления этого события в каждом испытании равна
0,2.
Решение.
По условию 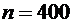 ;
; 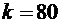 ;
; 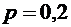 ;
; 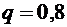 .
Воспользуемся формулой (4.7):
.
Воспользуемся формулой (4.7):
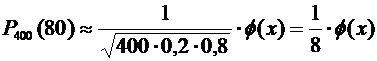 .
.
Вычислим
определяемое данными задачи значение х:
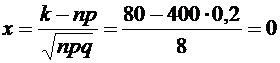 .
.
По
таблице находим  .
.
Искомая
вероятность равна
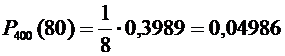 .
.
Формула
Бернулли приводит примерно к такому же результату (выкладки, ввиду их
громоздкости, опущены):
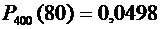 .
.
Пусть
теперь требуется вычислить вероятность 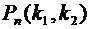 того,
что событие А появится в п испытаниях не менее
того,
что событие А появится в п испытаниях не менее 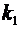 и не
более
и не
более 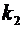 раз (для краткости будем говорить "от до раз").
Эта задача решается с помощью следующей теоремы.
раз (для краткости будем говорить "от до раз").
Эта задача решается с помощью следующей теоремы.
Интегральная
теорема Лапласа. Если вероятность р наступления события А в каждом испытании
постоянна и отлична от нуля и единицы, то вероятность того, что событие А появится в п испытаниях от до раз,
приближенно равна определенному интегралу
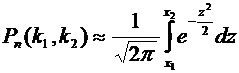 , (4.8)
, (4.8)
где
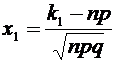 и
и 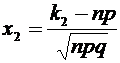 .
.
При
решении задач, требующих применения интегральной теоремы Лапласа, пользуются
специальной таблицей для интеграла 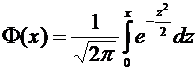 . В
таблице даны значения функции
. В
таблице даны значения функции 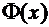 для
для 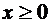 , а для
, а для  воспользуемся
нечетностью функции , т.е.
воспользуемся
нечетностью функции , т.е. 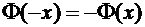 . Функцию
часто называют функцией Лапласа.
. Функцию
часто называют функцией Лапласа.
Итак,
вероятность того, что событие А появится в п независимых испытаниях от до раз,
равна
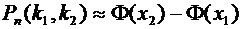 , (4.9)
, (4.9)
где
и .
Пример
3. Вероятность того, что организация не прошла проверку налоговой инспекции,
равна . Найти вероятность того, что среди 400 случайно
отобранных организаций не прошедших проверку окажется от 70 до 100 организаций.
Решение.
По условию ; 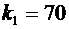 ;
; 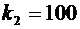 ; ; . Воспользуемся формулой (4.9):
; ; . Воспользуемся формулой (4.9):
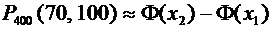 .
.
Вычислим
нижний и верхний пределы интегрирования:
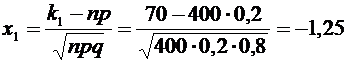 ;
;
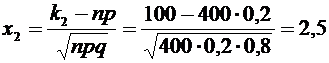 .
.
Таким
образом, имеем
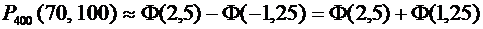 .
.
По
таблице значений функции находим
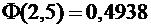 ;
; 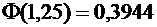 .
.
 .
.
В
теме №1 было отмечено, что по статистическому определению вероятности в
качестве вероятности можно взять относительную частоту, поэтому представляет
интерес оценка разности между ними. Вероятность того, что отклонение
относительной частоты от постоянной вероятности р по абсолютной величине не
превышает заданного числа 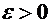 , равна
, равна
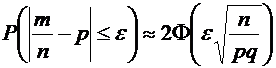 . (4.10)
. (4.10)
Пример
4. Вероятность того, что деталь не стандартна, равна . Найти вероятность того, что среди случайно
отобранных 400 деталей относительная частота появления нестандартных деталей
отклонится от вероятности по абсолютной величине не более, чем на 0,03.
Решение.
По условию ; ; 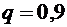 ;
; 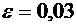 .
.
Требуется
найти вероятность 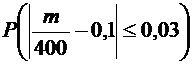 .
.
Пользуясь
формулой (4.10), имеем
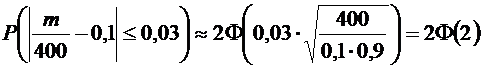 .
.
По
таблице находим  . Следовательно,
. Следовательно, 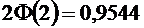 .
.
Итак,
искомая вероятность приближенно равна 0,9544.
Смысл
полученного результата таков: если взять достаточно большое число проб по 400
деталей в каждой, то примерно в 95,44% этих проб отклонение относительной
частоты от постоянной вероятности по
абсолютной величине не превысит 0,03.
Вопросы для повторения и контроля:
1. Что называется схемой Бернулли?
2. Как выводится формула Бернулли?
. Как находится наивероятнейшее число успехов?
. О чем идет речь в локальной теореме Лапласа?
. О чем идет речь в интегральной теореме Лапласа?
. Как находится вероятность отклонения относительной частоты от
постоянной вероятности?
Опорные слова:
Последовательность
независимых испытаний, схема Бернулли, формула Бернулли, наивероятнейшее число успехов, локальная теорема
Лапласа, вероятность того, что событие А появится в п независимых испытаниях ровно
k раз, интегральная теорема Лапласа, вероятность того, что событие А появится в
п независимых испытаниях от до раз, функция Лапласа, вероятность отклонения
относительной частоты от постоянной вероятности.
.
Дискретные случайные величины. Закон распределения. Виды дискретных
распределений
В предыдущих темах неоднократно приводились события, состоящие в
появлении того или иного числа. Например, при бросании игральной кости могли появиться
числа 1, 2, 3, 4, 5 и 6. Наперед определить число выпавших очков невозможно,
поскольку оно зависит от многих случайных причин, которые полностью не могут
быть учтены. В этом смысле число очков есть величина случайная; числа 1, 2, 3,
4, 5 и 6 есть возможные значения этой величины.
Случайной величиной называют величину, которая в результате испытания
примет одно и только одно возможное значение, наперед не известное и зависящее
от случайных причин, которые заранее не могут быть учтены.
Пример 1. Число родившихся мальчиков среди ста новорожденных есть
случайная величина, которая имеет следующие возможные значения: 0, 1, 2, ... ,
100.
Пример
2. Расстояние, которое пролетит снаряд при выстреле из орудия, есть случайная
величина. Возможные значения этой величины принадлежат некоторому промежутку  .
.
Так
как в результате испытаний происходят элементарные события, то можно связать
понятия случайной величины и элементарных событий и дать другое определение
случайной величины.
Случайной
величиной называется функция 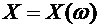 ,
определенная на пространстве элементарных событий ,
,
определенная на пространстве элементарных событий , 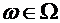 .
.
Пример
3. При подбрасывании двух монет число выпавших гербов Х есть случайная
величина, которая может принимать значения 0, 1 и 2. Пространство элементарных
событий состоит из следующих элементарных событий:
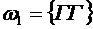 ,
,  ,
, 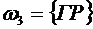 ,
, 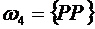 .
.
Тогда
Х принимает следующие значения:
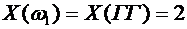 ,
, 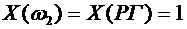 ,
,
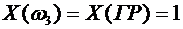 ,
, 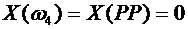 .
.
Случайные
величины обозначаются прописными латинскими буквами 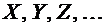 , а их возможные значения - соответствующими строчными
буквами
, а их возможные значения - соответствующими строчными
буквами 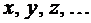 . Например, если случайная величина Х имеет три
возможных значения, то они обозначаются через
. Например, если случайная величина Х имеет три
возможных значения, то они обозначаются через 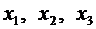 .
.
Дискретной
(прерывной) называют случайную величину, которая принимает отдельные,
изолированные возможные значения с определенными вероятностями. Число возможных
значений дискретной случайной величины может быть конечным или бесконечным. В
качестве примера таковой можно привести случайную величину из примера 1.
Непрерывной
называют случайную величину, которая может принимать все значения из некоторого
конечного или бесконечного промежутка. Число возможных значений непрерывной
случайной величины бесконечно. В качестве примера такой величиныможно привести
случайную величину из примера 2.
Для
задания дискретной случайной величины недостаточно перечислить все возможные ее
значения, нужно еще указать их вероятности. С другой стороны, во многих задачах
нет необходимости рассматривать случайные величины как функции от элементарного
события, а достаточно знать лишь вероятности возможных значений случайной
величины, т.е. закон распределения случайной величины.
Законом
распределения вероятностей или просто законом распределения дискретной
случайной величины называют соответствие между возможными значениями и их
вероятностями; его можно задать в виде таблицы, графика и формулы.
Рассмотрим различные способы задания закона распределения вероятностей на
примерах.
При табличном задании закона распределения дискретной случайной величины
первая строка таблицы содержит возможные значения, а вторая - их вероятности.
Сумма вероятностей во второй строке таблицы должна быть равна 1. В таблице 5.1
задан закон распределения дискретной случайной величины из примера 3.
Таблица 5.1
|
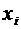 012 012
|
|
|
|
|
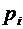 1 / 41 / 21 / 4 1 / 41 / 21 / 4
|
|
|
|
Пример 4. В денежной лотерее выпущено 100 билетов. Разыгрывается один
выигрыш в 5000 сум, пять выигрышей по 1000 сум и десять выигрышей по 500 сум.
Найти закон распределения случайной величины Х - стоимости возможного выигрыша
для владельца одного лотерейного билета.
Решение.
Напишем возможные значения Х: 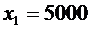 ,
, 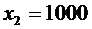 ,
, 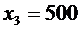 ,
, 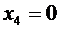 . Вероятности этих возможных значений таковы:
. Вероятности этих возможных значений таковы: 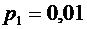 ,
, 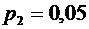 ,
, 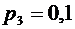 ,
, 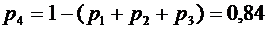 .
.
Тогда
искомый закон распределения имеет вид
Таблица 5.2
|
050010005000
|
|
|
|
|
|
0,840,10,050,01
|
|
|
|
|
Для
наглядности закон распределения дискретной случайной величины можно изобразить
и графически, для чего в прямоугольной системе координат строят точки 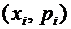 , а затем соединяют их отрезками прямых. Полученную
фигуру называют многоугольником распределения. На рисунке 5.1 приведен
многоугольник распределения случайной величины Х из примера 3.
, а затем соединяют их отрезками прямых. Полученную
фигуру называют многоугольником распределения. На рисунке 5.1 приведен
многоугольник распределения случайной величины Х из примера 3.
Теперь
рассмотрим некоторые дискретные распределения, заданные посредством формул:
биномиальное, геометрическое и Пуассона.
Пусть
производится n независимых испытаний, в каждом из которых вероятность
наступления события А (успеха) постоянна и равна p (следовательно, вероятность
непоявления (неудачи) равна q=1-p). Рассмотрим в качестве дискретной случайной
величины Х число появлений события А в этих испытаниях. Возможные значения Х
таковы: 0, 1, 2, ..., n. Вероятности этих возможных значений находятся по
формуле Бернулли (4.1):
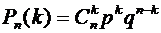 ,
,
где
k= 0, 1, 2, ..., n.
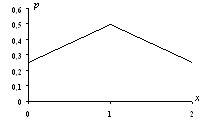
Рис.
5.1.
Биномиальным
называют распределение вероятностей, определяемое формулой Бернулли. Закон
назван "биномиальным" потому, что правую часть формулы Бернулли можно
рассматривать как общий член разложения бинома Ньютона:
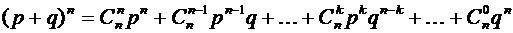 .
.
Так
как p + q = 1, то сумма вероятностей возможных значений случайной величины
равна 1.
Таким
образом, биномиальный закон распределения имеет вид
Таблица 5.3
В качестве примера биномиального распределения можно привести
распределение случайной величины из примера 3.
Пусть
производятся независимые испытания, в каждом из которых вероятность появления
события А (успеха) равна р (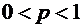 ) и,
следовательно, вероятность его непоявления (неудачи) равна q=1-p. Испытания
продолжаются до первого успеха. Таким образом, если событие А появилось в k-м
испытании, то в предшествующих k - 1 испытаниях оно не появлялось.
) и,
следовательно, вероятность его непоявления (неудачи) равна q=1-p. Испытания
продолжаются до первого успеха. Таким образом, если событие А появилось в k-м
испытании, то в предшествующих k - 1 испытаниях оно не появлялось.
Если
через Х обозначить дискретную случайную величину, равную числу испытаний до
первого успеха, то ее возможными значениями будут натуральные числа 1, 2, 3,
...
Пусть
в первых k - 1 испытаниях событие А не наступило, а в k-м испытании появилось.
Вероятность этого "сложного события", по теореме 3.3 умножения
вероятностей независимых событий, равна
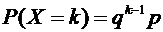 . (5.1)
. (5.1)
Геометрическим
называют распределение вероятностей, определяемое формулой (5.1), так как
полагая в этой формуле k = 1, 2, ..., получим геометрическую прогрессию с
первым членом р и знаменателем q (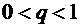 ):
):
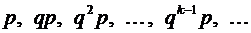
Просуммировав
бесконечно убывающую геометрическую прогрессию, легко убедиться, что сумма
вероятностей возможных значений случайной величины равна 1:
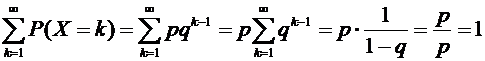 .
.
Таким
образом, геометрический закон распределения имеет вид
Таблица 5.4
Пример
5. Из орудия производится стрельба по цели до первого попадания. Вероятность
попадания в цель 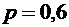 . Найти вероятность того, что попадание произойдет при
третьем выстреле.
. Найти вероятность того, что попадание произойдет при
третьем выстреле.
Решение.
По условию , 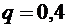 ,
, 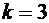 . Искомая вероятность по формуле (5.1) равна:
. Искомая вероятность по формуле (5.1) равна:
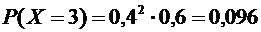 .
.
Пусть
производится n независимых испытаний, в каждом из которых вероятность появления
события А равна р. Для определения вероятности k появлений события в этих
испытаниях используют формулу Бернулли. Если же п велико, то пользуются
локальной теоремой Лапласа. Однако она дает большую погрешность, если
вероятность события мала (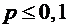 ).
).
Если
сделать допущение, что произведение 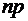 при
при 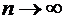 сохраняет постоянное значение, а именно
сохраняет постоянное значение, а именно 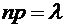 , то вероятность того, что при очень большом числе испытаний,
в каждом из которых вероятность события очень мала, событие наступит ровно k
раз, находится по следующей формуле
, то вероятность того, что при очень большом числе испытаний,
в каждом из которых вероятность события очень мала, событие наступит ровно k
раз, находится по следующей формуле
 . (5.2)
. (5.2)
Эта
формула выражает закон распределения Пуассона вероятностей массовых (п велико)
и маловероятных (р мало) событий. Имеются специальные таблицы для распределения
Пуассона.
Пример
6. Завод отправил на базу 5000 доброкачественных изделий. Вероятность того, что
в пути изделие повредится, равно 0,0002. Найти вероятность того, что на базу
прибудут 3 негодных изделия.
Решение.
По условию 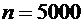 ,
, 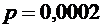 , . Найдем
, . Найдем 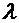 :
:
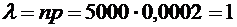 .
.
Искомая
вероятность по формуле (5.2) равна:
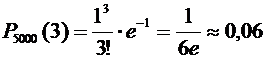 .
.
Вопросы для повторения и контроля:
1. Как определяется случайная величина в общем случае и на языке
функций?
2. Что такое дискретная случайная величина?
. Что такое непрерывная случайная величина?
. Что вы знаете о законе распределения дискретной случайной
величины?
. Что вы знаете о биномиальном законе распределения?
. Каковы особенности геометрического закона распределения?
7. В каких случаях используют распределение Пуассона?
Опорные слова:
Случайная величина, дискретная случайная величина, непрерывная случайная величина, закон
распределения дискретной случайной величины, многоугольник распределения,
биномиальное распределение, геометрическое распределение, распределение
Пуассона.
. Числовые характеристики дискретных случайных величин и их свойства
Как мы видели выше, закон распределения полностью характеризует
дискретную случайную величину. Однако часто закон распределения неизвестен и
приходится ограничиваться числами, которые описывают случайную величину
суммарно; такие числа называют числовыми характеристиками случайной величины.
К числу важных числовых характеристик относится математическое ожидание.
Математическое ожидание приближенно равно среднему значению случайной величины.
Для решения многих задач достаточно знать математическое ожидание. Например,
если известно, что математическое ожидание числа выбиваемых очков у первого
стрелка больше, чем у второго, то первый стрелок в среднем выбивает больше
очков, чем второй, и, следовательно, стреляет лучше второго.
Математическим ожиданием дискретной случайной величины Х называется сумма
произведений всех ее возможных значений на их вероятности и обозначается через
М(Х).
Пусть
случайная величина Х принимает значения 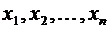 с
соответствующими вероятностями
с
соответствующими вероятностями  . Тогда
математическое ожидание М(Х) случайной величины Х определяется равенством
. Тогда
математическое ожидание М(Х) случайной величины Х определяется равенством
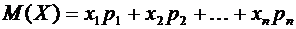 . (6.1)
. (6.1)
Если
дискретная случайная величина Х принимает бесконечное множество возможных
значений, то
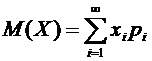 . (6.2)
. (6.2)
Пример
1. Найти математическое ожидание случайной величины Х, зная закон ее
распределения
Таблица 6.1
|
352
|
|
|
|
|
0,10,60,3
|
|
|
|
Решение. Искомое математическое ожидание по формуле (6.1) равно
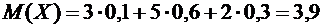 .
.
Пример
2. Найти математическое ожидание числа появлений события А в одном испытании,
если вероятность события А равна р.
Решение.
Случайная величина Х - число появлений события А в одном испытании - может
принимать только два значения: 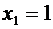 (событие
А наступило) с вероятностью р и
(событие
А наступило) с вероятностью р и 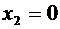 (событие
А не наступило) с вероятностью q = 1 - р.
Искомое математическое ожидание по формуле (6.1) равно
(событие
А не наступило) с вероятностью q = 1 - р.
Искомое математическое ожидание по формуле (6.1) равно
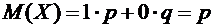 .
.
Итак,
математическое ожидание числа появлений события в одном испытании равно
вероятности этого события.
Теперь приведем свойства математического ожидания.
Свойство 6.1. Математическое ожидание постоянной величины равно самой
постоянной:
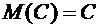 .
.
Доказательство.
Будем рассматривать постоянную С как дискретную случайную величину, которая
имеет одно возможное значение С и принимает его с вероятностью 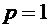 . Следовательно,
. Следовательно,
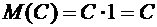 .
.
Свойство
6.2.
Постоянный
множитель можно выносить за знак математического ожидания:
 .
.
Две
случайные величины называются независимыми, если закон распределения одной из
них не зависит от того, какие возможные значения приняла другая величина.
Произведением
независимых случайных величин Х и Y называется случайная величина ХY, возможные
значения которой равны произведениям каждого возможного значения Х на каждое
возможное значение Y; вероятности возможных значений произведения ХY равны
произведениям вероятностей возможных значений сомножителей.
Свойство 6.3.
Математическое ожидание произведения двух независимых случайных величин
равно произведению их математических ожиданий:
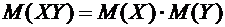 .
.
Следствие
6.1. Математическое ожидание произведения нескольких независимых случайных
величин равно произведению их математических ожиданий.
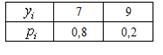
Пример
3. Независимые случайные величины Х и Y заданы следующими законами
распределения:
Таблица
6.2
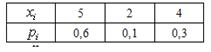
Таблица
6.3
Найти
математическое ожидание случайной величины ХY.
Решение.
Найдем математические ожидания каждой из данных величин:
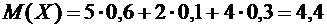 ;
;
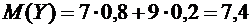 .
.
Случайные величины Х и Y независимые, поэтому искомое математическое
ожидание равно
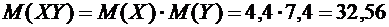 .
.
Суммой
случайных величин Х и Y называется случайная величина Х+Y, возможные значения
которой равны суммам каждого возможного значения Х с каждым возможным значением
Y; вероятности возможных значений Х+Y для независимых величин Х и Y равны
произведениям вероятностей слагаемых; для зависимых величин - произведениям
вероятности одного слагаемого на условную вероятность второго.
Свойство 6.4. Математическое ожидание суммы двух случайных величин равно
сумме математических ожиданий слагаемых:
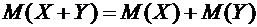 .
.
Следствие
6.2. Математическое ожидание суммы нескольких случайных величин равно сумме
математических ожиданий слагаемых.
Пример
4. Найти математическое ожидание суммы числа очков, которые могут выпасть при
бросании двух игральных костей.
Решение.
Обозначим число очков, которое может выпасть на первой кости, через Х и на
второй - через Y. Возможные значения этих
величин одинаковы и равны 1, 2, 3, 4, 5 и 6, причем вероятность каждого из этих
значений равна 1/6.
Найдем
математическое ожидание числа очков, которые могут выпасть на первой кости:
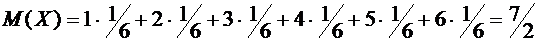 .
.
Очевидно,
что и 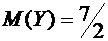 .
.
Искомое
математическое ожидание равно
 .
.
Свойство
6.5. Математическое ожидание числа появлений события А в n независимых
испытаниях, в каждом из которых вероятность р появления события постоянна,
равно произведению числа испытаний на вероятность появления события в одном
испытании:
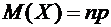 .
.
Пример
5. Вероятность выявления ошибок в документации при проверке предприятия равна . Найти математическое ожидание общего числа выявлений
ошибок, если будет проведено 10 проверок предприятий.
Решение.
Выявление ошибок при каждой проверке не
зависит от исходов других проверок, поэтому рассматриваемые события независимы
и, следовательно, искомое математическое ожидание равно
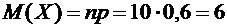 (выявлений ошибок).
(выявлений ошибок).
Некоторые
случайные величины имеют одинаковые математические ожидания, но различные
возможные значения. Рассмотрим, например, дискретные случайные величины Х и Y, заданные следующими законами распределения:
Таблица
6.4
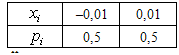
Таблица
6.5

Найдем
математические ожидания этих величин:
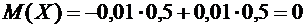 ;
;
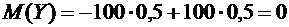 .
.
Здесь
математические ожидания обеих величин одинаковы, а возможные значения различны,
причем Х имеет возможные значения, близкие к математическому ожиданию, а Y - далекие от своего математического ожидания. Таким
образом, зная лишь математическое ожидание случайной величины, еще нельзя
судить ни о том, какие возможные значения она может принимать, ни о том, как
они рассеяны вокруг математического ожидания.
Другими
словами, математическое ожидание полностью случайную величину не характеризует.
По этой причине наряду с математическим ожиданием рассматриваются и другие
числовые характеристики.
Пусть
Х - случайная величина и М(Х) - ее математическое ожидание. Отклонением
случайной величины называется разность  .
.
На
практике часто требуется оценить рассеяние возможных значений случайной
величины вокруг ее среднего значения. Например, в артиллерии важно знать,
насколько кучно лягут снаряды вблизи цели, которая должна быть поражена.
Дисперсией
(рассеянием) дискретной случайной величины называют математическое ожидание
квадрата отклонения случайной величины от ее математического ожидания:
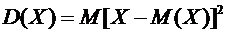 . (6.3)
. (6.3)
Для
вычисления дисперсии часто бывает удобно воспользоваться следующей формулой:
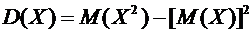 . (6.4)
. (6.4)
Пример
6. Найти дисперсию случайной величины Х, которая задана следующим законом
распределения:
Таблица 6.6
|
235
|
|
|
|
|
0,10,60,3
|
|
|
|
Решение. Математическое ожидание М(Х) равно:
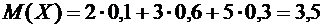 .
.
Закон
распределения случайной величины 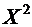 имеет
вид:
имеет
вид:
Таблица 6.7
|
 4925 4925
|
|
|
|
|
0,10,60,3
|
|
|
|
Математическое
ожидание 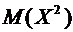 равно:
равно:
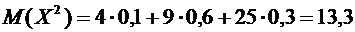 .
.
Искомая
дисперсия равна
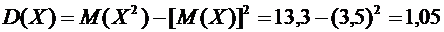 .
.
Дисперсия,
как и математическое ожидание, имеет несколько свойств.
Свойство
6.6. Дисперсия постоянной величины равна нулю:
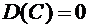 .
.
Доказательство.
По определению дисперсии,
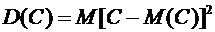 .
.
Пользуясь свойством 6.1, получим
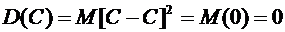 .
.
Итак,
.
Свойство
становится ясным, если учесть, что постоянная величина сохраняет одно и то же
значение и рассеяния не имеет.
Свойство
6.7. Постоянный множитель можно выносить за знак дисперсии, возводя его в
квадрат:
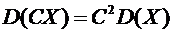 .
.
Свойство
6.8. Дисперсия суммы двух независимых случайных величин равна сумме дисперсий
этих величин:
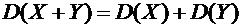 .
.
Следствие
6.3. Дисперсия суммы нескольких независимых случайных величин равна сумме
дисперсий этих величин.
Следствие
6.4. Дисперсия суммы постоянной величины и случайной величины равна дисперсии
случайной величины:
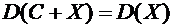 .
.
Доказательство.
Величины С и Х независимы, поэтому по свойству 6.8 имеем
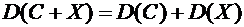 .
.
В
силу свойства 6.6 . Следовательно,
.
Свойство
становится ясным, если учесть, что величины Х и Х + С отличаются лишь началом
отсчета и, значит, рассеяны вокруг своих математических ожиданий одинаково.
Свойство
6.9. Дисперсия разности двух независимых случайных величин равна сумме их
дисперсий:
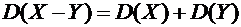 .
.
Доказательство.
В силу свойства 6.8 имеем
 .
.
По свойству 6.7,
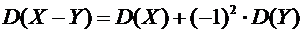 .
.
или
.
Свойство
6.10. Дисперсия числа появлений события А в n независимых испытаниях, в каждом
из которых вероятность р появления события постоянна, равна произведению числа
испытаний на вероятности появления и непоявления события в одном испытании:
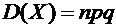 .
.
Пример
7. ГНИ проводит 10 независимых проверок предприятий, в каждой из которых
вероятность выявления ошибок в документации равна . Найти дисперсию случайной величины Х - числа выявлений
ошибок в документации в этих проверках.
Решение.
По условию, 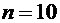 , .
Вероятность невыявления ошибок в
документации равна
, .
Вероятность невыявления ошибок в
документации равна
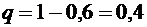 .
.
Искомая
дисперсия равна
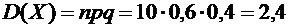 .
.
Для
оценки рассеяния возможных значений случайной величины вокруг ее среднего
значения служит также среднее квадратическое отклонение.
Средним
квадратическим отклонением случайной величины Х называется квадратный корень из
дисперсии:
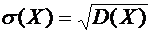 . (6.5)
. (6.5)
Пример
8. Cлучайная величина Х задана следующим законом распределения:
Таблица 6.8
|
2310
|
|
|
|
|
0,10,40,5
|
|
|
|
Найти
среднее квадратическое отклонение 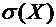 .
.
Решение. Математическое ожидание М(Х) равно:
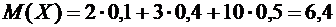 .
.
Математическое
ожидание равно:
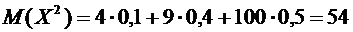 .
.
Найдем
дисперсию:
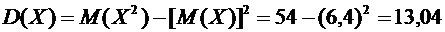 .
.
Искомое среднее квадратическое отклонение равно:
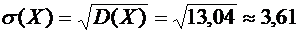 .
.
Вопросы для повторения и контроля:
1. Что называется числовыми характеристиками случайной величины и
какие их виды вы знаете?
2. Что такое математическое ожидание и как оно определяется?
. Чему равно математическое ожидание числа появлений события в
одном испытании и как оно находится?
. Что вы знаете о 1- и 2-свойствах математического ожидания
(свойства 6.1 и 6.2)?
. Какие случайные величины называются независимыми и что является
произведением
независимых случайных величин?
. Как определяется сумма случайных величин?
7. Что вы знаете о 3- и 4-свойствах математического ожидания, а
также об их следствиях (свойства 6.3 и 6.4, следствия 6.1 и 6.2)?
. В чем целесообразность введения других числовых характеристик
случайной величины, кроме математического ожидания, и что такое отклонение
случайной величины?
. Что такое дисперсия и как она находится?
. Что вы знаете о 1- и 2-свойствах дисперсии (свойства 6.6 и
6.7)?
. Что вы знаете о 3-свойстве дисперсии и его следствиях (свойство
6.8, следствия 6.3 и 6.4)?
. Что вы знаете о 4-свойстве дисперсии (свойство 6.9)?
. Чему равны математическое ожидание и дисперсия числа появлений
события А в n независимых испытаниях (свойства 6.5 и 6.10)?
14. Что такое среднее квадратическое отклонение и как оно
определяется?
Опорные слова:
Числовые характеристики случайной величины, математическое ожидание, независимые
случайные величины, произведение независимых случайных величин, сумма случайных
величин, отклонение случайной величины, дисперсия, среднее квадратическое
отклонение.
. Функции распределения и плотности непрерывных случайных величин, их
свойства
Дискретная случайная величина может быть задана перечнем всех ее
возможных значений и их вероятностей. Однако такой способ задания неприменим
для непрерывных случайных величин.
Например,
рассмотрим случайную величину Х, возможные значения которой сплошь заполняют
интервал 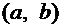 . Очевидно, что невозможно составить перечень всех
возможных значений Х. Поэтому целесообразно дать общий способ задания любых
типов случайных величин, для чего вводятся функции распределения вероятностей
случайной величины.
. Очевидно, что невозможно составить перечень всех
возможных значений Х. Поэтому целесообразно дать общий способ задания любых
типов случайных величин, для чего вводятся функции распределения вероятностей
случайной величины.
Пусть
х - действительное число. Вероятность события, состоящего в том, что Х примет
значение, меньшее х, т.е. вероятность события 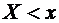 ,
обозначим через
,
обозначим через 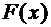 . Если х изменяется, то изменяется и , т.е. -
функция от х.
. Если х изменяется, то изменяется и , т.е. -
функция от х.
Функцией
распределения случайной величины Х называется функция , определяющая вероятность того, что случайная
величина Х в результате испытания примет значение, меньшее х, т.е.
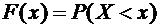 . (7.1)
. (7.1)
Геометрически
это равенство можно истолковать так: есть
вероятность того, что случайная величина примет значение, которое изображается
на числовой оси точкой, лежащей левее точки х.
Теперь
рассмотрим свойства функции распределения.
Свойство
7.1. Значения функции распределения принадлежат отрезку 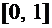 :
:
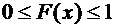 . (7.2)
. (7.2)
Доказательство.
Свойство вытекает из определения функции распределения как вероятности:
вероятность всегда есть неотрицательное число, не превышающее единицы.
Свойство
7.2. - неубывающая функция, т.е.:
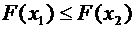 , если
, если 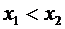 . (7.3)
. (7.3)
Следствие
7.1. Вероятность того, что случайная величина примет значение, заключенное в
интервале , равна приращению функции распределения на этом
интервале:
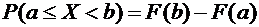 . (7.4)
. (7.4)
Пример
1. Cлучайная величина Х задана следующей функцией распределения:
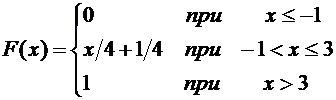 .
.
Найти
вероятность того, что в результате испытания Х примет значение, принадлежащее
интервалу 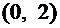 :
:
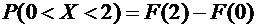 .
.
Решение.
Так как на интервале , по условию,
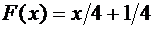 ,
,
то
 .
.
Итак,
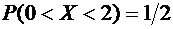 .
.
Следствие
7.2. Вероятность того, что непрерывная случайная величина Х примет одно
определенное значение, равна нулю.
Свойство
7.3. Если возможные значения случайной величины принадлежат интервалу , то: 1) 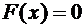 при
при 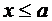 ; 2)
; 2) 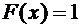 при
при 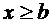 .
.
Доказательство.
1) Пусть  . Тогда событие
. Тогда событие 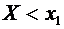 невозможно
(так как значений, меньших
невозможно
(так как значений, меньших 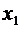 ,
величина Х по условию не принимает) и, следовательно, вероятность его равна
нулю.
,
величина Х по условию не принимает) и, следовательно, вероятность его равна
нулю.
)
Пусть  . Тогда событие
. Тогда событие 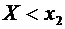 достоверно (так как все возможные значения Х меньше
достоверно (так как все возможные значения Х меньше 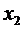 ) и, следовательно, вероятность его равна единице.
) и, следовательно, вероятность его равна единице.
Следствие
7.3. Если возможные значения непрерывной случайной величины расположены на всей
числовой оси х, то справедливы следующие предельные соотношения:
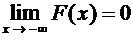 ;
; 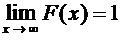 . (7.5)
. (7.5)
График
функции распределения непрерывной случайной величины в силу свойства 7.1
расположен в полосе, ограниченной прямыми  ,
,  .
.
Из
свойства 7.2 вытекает, что при возрастании х в интервале , в котором заключены все возможные значения случайной
величины, график имеет вид либо наклона вверх, либо горизонтальный.
В
силу свойства 7.3 при ординаты графика равны нулю; при ординаты графика равны единице.
График
функции распределения непрерывной случайной величины изображен на рис. 7.1.
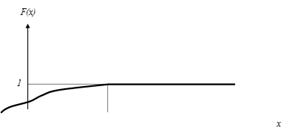
Рис.
7.1.
График
функции распределения дискретной случайной величины имеет ступенчатый вид.
Пример
2. Дискретная случайная величина Х задана следующим законом распределения:
Таблица 7.1
|
148
|
|
|
|
|
0,30,10,6
|
|
|
|
Найти функцию
распределения и вычертить ее график.
Решение.
Если 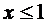 , то по свойству 7.3 .
, то по свойству 7.3 .
Если
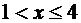 , то
, то 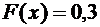 .
Действительно, Х может принять значение 1 с вероятностью 0,3.
.
Действительно, Х может принять значение 1 с вероятностью 0,3.
Если
 , то
, то 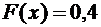 .
Действительно, если удовлетворяет неравенству
.
Действительно, если удовлетворяет неравенству 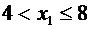 , то
, то 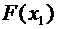 равно
вероятности события , которое может быть осуществлено, когда Х примет
значение 1 с вероятностью 0,3 или значение 4 с вероятностью 0,1. Поскольку эти
два события несовместны, то по теореме 3.1 вероятность события равна сумме вероятностей 0,3 + 0,1 = 0,4.
равно
вероятности события , которое может быть осуществлено, когда Х примет
значение 1 с вероятностью 0,3 или значение 4 с вероятностью 0,1. Поскольку эти
два события несовместны, то по теореме 3.1 вероятность события равна сумме вероятностей 0,3 + 0,1 = 0,4.
Если
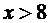 , то по свойству 7.3 .
, то по свойству 7.3 .
Итак,
функция распределения аналитически может быть записана так:
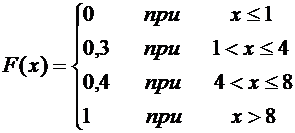 .
.
График
этой функции приведен на рис. 7.2.
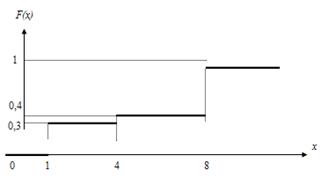
Рис.
7.2.
Непрерывную случайную величину можно также задать, используя другую
функцию, которая называется функцией плотности.
Функцией
плотности непрерывной случайной величины Х называется функция 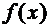 - первая производная от функции распределения :
- первая производная от функции распределения :
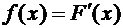 . (7.6)
. (7.6)
Отсюда
следует, что функция распределения является первообразной для функции
плотности. Для описания распределения вероятностей дискретной случайной
величины функция плотности неприменима.
Зная
функцию плотности, можно вычислить вероятность того, что непрерывная случайная
величина примет значение, принадлежащее заданному интервалу.
Теорема
7.1. Вероятность того, что непрерывная случайная величина Х примет значение,
принадлежащее интервалу , равна определенному интегралу от функции плотности,
взятому в пределах от а до b:
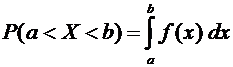 . (7.7)
. (7.7)
Доказательство.
Из формулы (7.4) получаем
.
По
формуле Ньютона-Лейбница
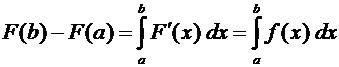 .
.
Таким
образом,
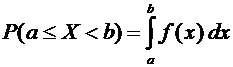 .
.
Так
как 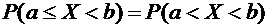 , то получаем
, то получаем
.
Пример
3. Задана функция плотности случайной величины Х:
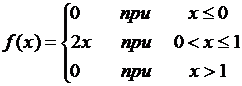 .
.
Найти
вероятность того, что в результате испытания Х примет значение, принадлежащее
интервалу 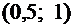 .
.
Решение. Искомая вероятность по формуле (7.7) равна
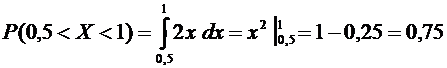 .
.
Зная
функцию плотности распределения , можно
найти функцию распределения по
формуле
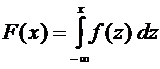 . (7.8)
. (7.8)
Пример
4. Найти функцию распределения по данной функции плотности:
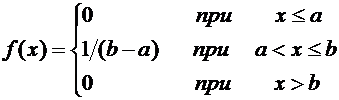 .
.
Построить
график найденной функции.
Решение.
Воспользуемся формулой (7.8). Если , то 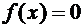 , следовательно, . Если
, следовательно, . Если 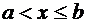 , то
, то 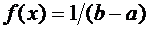 ,
следовательно,
,
следовательно,
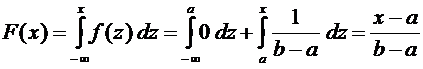 .
.
Если
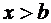 , то
, то
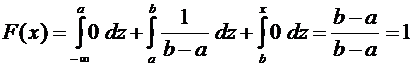 .
.
Итак,
искомая функция распределения имеет вид
 .
.
График
этой функции изображен на рис. 7.3.
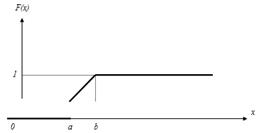
Рис.
7.3.
Приведем
два свойства функции плотности.
Свойство
7.4. Функция плотности - неотрицательная функция:
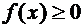 . (7.9)
. (7.9)
Доказательство.
Функция распределения - неубывающая функция, следовательно, ее производная 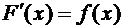 - функция неотрицательная.
- функция неотрицательная.
Свойство
7.5. Несобственный интеграл от функции плотности распределения в пределах от  до
до  равен
единице:
равен
единице:
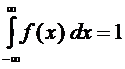 . (7.10)
. (7.10)
Вопросы для повторения и контроля:
1. Почему целесообразно дать общий способ задания любых типов случайных
величин?
. Что называется функцией распределения случайной величины?
. Что вы знаете о 1-свойстве функции распределения (свойство 7.1)?
4. Что вы знаете о 2-свойстве функции распределения и его следствиях (свойство 7.2,
следствия 7.1 и 7.2)?
. Какими свойствами обладают графики функций распределения
непрерывной и дискретной случайной величин?
. Что называется функцией плотности непрерывной случайной величины и что вы знаете о
теореме 7.1?
. Как можно найти функцию распределения, зная функцию плотности
распределения и что вы знаете о свойствах функции плотности (свойства 7.4 и
7.5)?
Опорные слова:
Функция распределения случайной величины, график функции распределения непрерывной
случайной величины, график функции распределения дискретной случайной величины,
функция плотности непрерывной случайной величины
. Числовые характеристики непрерывных случайных величин. Виды непрерывных
распределений
Как и дискретные случайные величины, непрерывные случайные величины также
имеют числовые характеристики. Рассмотрим математическое ожидание и дисперсию
непрерывной случайной величины.
Пусть
непрерывная случайная величина Х задана функцией плотности и возможные значения этой случайной величины
принадлежат отрезку 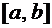 .
.
Математическим
ожиданием непрерывной случайной величины Х, возможные значения которой
принадлежат отрезку , называется следующий определенный интеграл
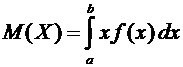 . (8.1)
. (8.1)
Если
возможные значения принадлежат всей числовой оси Ох, то математическое ожидание
имеет следующий вид
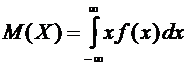 . (8.2)
. (8.2)
Дисперсией
непрерывной случайной величины Х, возможные значения которой принадлежат
отрезку , называется следующий определенный интеграл
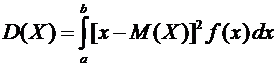 . (8.3)
. (8.3)
Если
возможные значения принадлежат всей числовой оси Ох, то дисперсия имеет
следующий вид
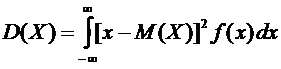 . (8.4)
. (8.4)
Для вычисления дисперсии более удобны соответственно следующие формулы
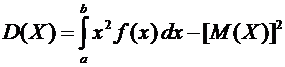 (8.5)
(8.5)
И
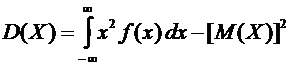 . (8.6)
. (8.6)
Свойства математического ожидания и дисперсии дискретных случайных
величин сохраняются и для непрерывных случайных величин.
Среднее
квадратическое отклонение непрерывной случайной величины определяется, как и
для дискретной случайной величины, следующим равенством
. (8.7)
Пример
1. Найти математическое ожидание, дисперсию и среднее квадратическое отклонение
случайной величины Х, заданной следующей функцией распределения:
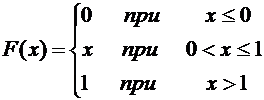 .
.
Решение. Найдем функцию плотности:
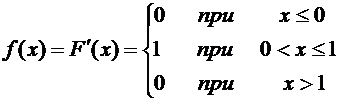 .
.
Найдем математическое ожидание по формуле (8.1):
 .
.
Найдем
дисперсию по формуле (8.5):
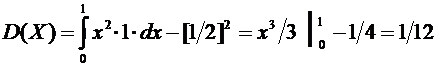 .
.
Найдем
среднее квадратическое отклонение по формуле (8.7):
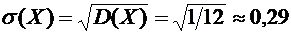 .
.
При
решении задач, которые выдвигает практика, приходится сталкиваться с различными
распределениями непрерывных случайных величин. Функции плотности непрерывных
случайных величин называются также законами распределений. Наиболее часто
встречаются законы нормального, равномерного и показательного распределений.
Нормальным
распределением с параметрами 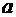 и
и 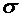 (
(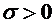 )
называется распределение вероятностей непрерывной случайной величины, которое
описывается следующей функцией плотности
)
называется распределение вероятностей непрерывной случайной величины, которое
описывается следующей функцией плотности
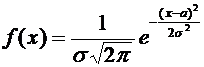 . (8.8)
. (8.8)
Отсюда
видно, что нормальное распределение определяется двумя параметрами: и .
Достаточно знать эти параметры, чтобы задать нормальное распределение.
Отметим
вероятностный смысл этих параметров. Итак, 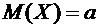 , т.е.
математическое ожидание нормального распределения равно параметру , и
, т.е.
математическое ожидание нормального распределения равно параметру , и 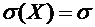 , т.е.
среднее квадратическое отклонение нормального распределения равно параметру .
, т.е.
среднее квадратическое отклонение нормального распределения равно параметру .
Функция
распределения нормальной случайной величины имеет вид
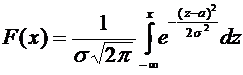 . (8.9)
. (8.9)
Общим
называется нормальное распределение с произвольными параметрами и (). Стандартным называется нормальное распределение с
параметрами  и
и  .
.
Легко
заметить, что функция плотности стандартного нормального распределения имеет
следующий вид
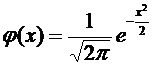 . (8.10)
. (8.10)
Эта
функция уже встречалась нам в теме № 4. Ее значения приведены в специальных
таблицах в различной литературе по теории вероятностей и математической
статистике.
Вероятность
попадания нормальной случайной величины с произвольными параметрами и в
интервал 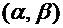 можно найти, пользуясь функцией Лапласа
можно найти, пользуясь функцией Лапласа 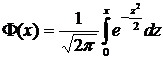 . Действительно, по теореме 7.1 имеем
. Действительно, по теореме 7.1 имеем
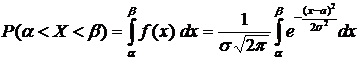 .
.
Введем
новую переменную 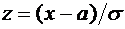 . Отсюда
. Отсюда 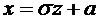 ,
, 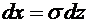 . Найдем новые пределы интегрирования. Если
. Найдем новые пределы интегрирования. Если 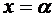 , то
, то  ; если
; если 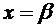 , то
, то 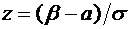 .
.
Таким
образом, имеем
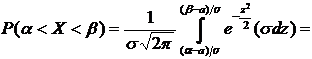
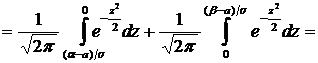
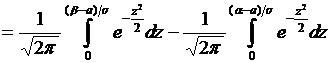 .
.
Используя
функцию 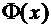 , окончательно получим
, окончательно получим
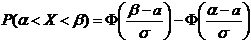 . (8.11)
. (8.11)
В
частности, вероятность попадания стандартной нормальной случайной величины Х в
интервал  равна
равна
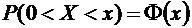 , (8.12)
, (8.12)
так
как в этом случае и .
Пример
2. Случайная величина Х распределена по нормальному закону. Математическое
ожидание и среднее квадратическое отклонение этой величины соответственно равны
30 и 10. Найти вероятность того, что Х примет значение, принадлежащее интервалу
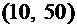 .
.
Решение.
Воспользуемся формулой (8.11). По условию, 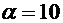 ,
, 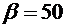 ,
, 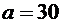 ,
, 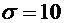 , следовательно,
, следовательно,
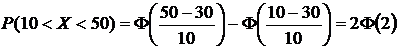 .
.
По
таблице находим 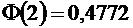 . Отсюда искомая вероятность равна
. Отсюда искомая вероятность равна
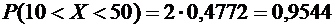 .
.
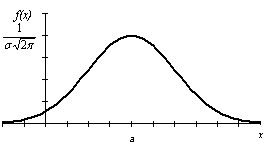
Рис.
8.1.
График
функции плотности нормального распределения называется нормальной кривой
(кривой Гаусса). Этот график изображен на рис. 8.1.
Равномерным
распределением на отрезке называется распределение вероятностей случайной
величины Х, все возможные значения которой принадлежат этому отрезку, если ее
функция плотности имеет вид
. (8.13)
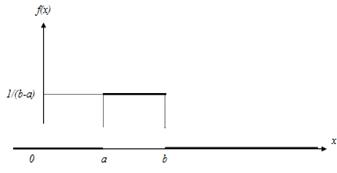
Рис. 8.2.
Функция
распределения равномерно распределенной на случайной
величины имеет вид
. (8.14)
График
функции плотности равномерного распределения приведен на рис. 8.2, а график
функции распределения - на рис. 7.3.
Вычислим
математическое ожидание и дисперсию равномерной случайной величины.
По
формуле (8.1) имеем
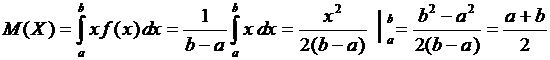 .
.
Далее,
по формуле (8.5) имеем
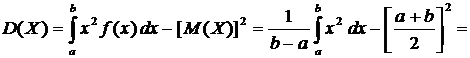
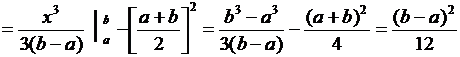 .
.
Теперь
найдем вероятность попадания непрерывной случайной величины Х, распределенной
равномерно на , в интервал 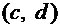 ,
принадлежащий .
,
принадлежащий .
Используя
теорему 7.1 и формулу (8.13), имеем

Или
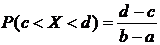 . (8.15)
. (8.15)
Показательным
(экспоненциальным) распределением называется распределение вероятностей
непрерывной случайной величины Х, которое описывается функцией плотности
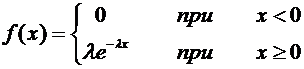 , (8.16)
, (8.16)
где
- постоянная положительная величина.
Из
определения видно, что показательное распределение определяется одним
параметром . Найдем функцию распределения показательного закона:
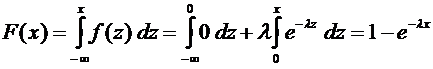 .
.
Итак,
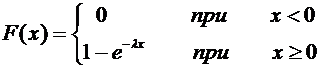 . (8.17)
. (8.17)
Графики функций плотности и распределения показательного закона
изображены на рис. 8.3.
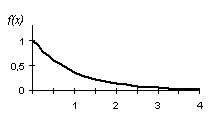
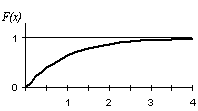
Рис. 8.3.
Найдем
вероятность попадания в интервал 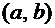 непрерывной
случайной величины Х, которая распределена по показательному закону из формулы
(8.17). Используя формулу (7.4), имеем
непрерывной
случайной величины Х, которая распределена по показательному закону из формулы
(8.17). Используя формулу (7.4), имеем
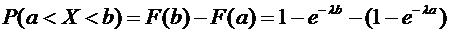
Или
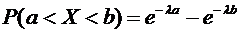 . (8.18)
. (8.18)
Пример
3. Непрерывная случайная величина Х распределена по показательному закону
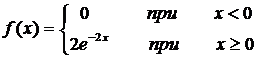 .
.
Найти
вероятность того, что в результате испытания Х попадает в интервал 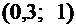 .
.
Решение.
По условию, 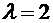 . Воспользуемся формулой (8.18):
. Воспользуемся формулой (8.18):

Отметим
вероятностный смысл параметра показательного распределения. Математическое
ожидание и среднее квадратическое отклонение показательного распределения равны
обратной величине параметра , т.е. 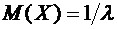 и
и 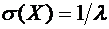 .
.
Пример
4. Непрерывная случайная величина Х распределена по показательному закону
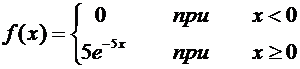 .
.
Найти
математическое ожидание, среднее квадратическое отклонение и дисперсию
случайной величины Х.
Решение.
По условию,  . Следовательно,
. Следовательно,
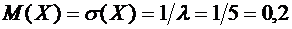 ;
;
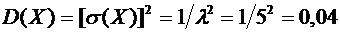 .
.
Вопросы для повторения и контроля:
1. Что является математическим ожиданием непрерывной случайной
величины?
2. Что является дисперсией непрерывной случайной величины и как она
вычисляется?
. Что называется нормальным распределением?
. Каков вероятностный смысл параметров нормального распределения?
. Что такое общее и стандартное нормальные распределения, каковы
их функции плотности и распределения?
. Как находится вероятность попадания нормальной случайной
величины в заданный интервал?
. Что называется равномерным распределением?
. Как вычисляется математическое ожидание и дисперсия равномерной
случайной величины?
. Как находится вероятность попадания равномерной случайной
величины в заданный интервал?
. Что называется показательным распределением?
. Как находится вероятность попадания показательной случайной
величины в заданный интервал?
. Каков вероятностный смысл параметра показательного
распределения?
Опорные слова:
Математическое ожидание непрерывной случайной величины, дисперсия
непрерывной случайной величины, закон распределения, нормальное распределение,
общее нормальное распределение, стандартное нормальное распределение, вероятность
попадания нормальной случайной величины в заданный интервал, нормальная кривая
(кривая Гаусса), равномерное распределение, вероятность попадания равномерной
случайной величины в заданный интервал, показательное распределение, вероятность
попадания показательной случайной величины в заданный интервал.
. Закон больших чисел и его практическое значение. Понятие о центральной
предельной теореме
Как мы видели в предыдущих темах, нельзя заранее уверенно предвидеть,
какое из возможных значений примет случайная величина в итоге испытания, потому
что это зависит от многих случайных причин, учесть которые невозможно. Однако
при некоторых сравнительно широких условиях суммарное поведение достаточно
большого числа случайных величин почти утрачивает случайный характер и
становится закономерным.
Для практики очень важно знание условий, при выполнении которых
совокупное действие очень многих случайных причин приводит к результату, почти
не зависящему от случая, так как позволяет предвидеть ход явлений. Эти условия
и указываются в теоремах, носящих общее название закона больших чисел. К ним
относятся теоремы Чебышева и Бернулли.
Теоремы, относящиеся к закону больших чисел, устанавливают условия
сходимости среднего арифметического п случайных величин к среднему
арифметическому их математических ожиданий.
Вначале приведем неравенство Чебышева, на которое опираются
доказательства вышеназванных теорем.
Если известна дисперсия случайной величины, то с ее помощью можно оценить
вероятность отклонения этой величины на заданное значение от своего
математического ожидания, причем оценка вероятности отклонения зависит лишь от
дисперсии. Соответствующую оценку вероятности дает неравенство П.Л.Чебышева:
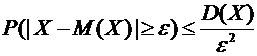 ,
,  . (9.1)
. (9.1)
Из
этого неравенства в качестве следствия можно получить следующее неравенство
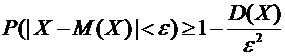 , . (9.2)
, . (9.2)
Пример
1. Оценить вероятность отклонения случайной величины Х от своего
математического ожидания на величину, превышающую утроенное
среднеквадратическое отклонение случайной величины.
Решение.
По условию, 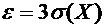 . Учитывая, что
. Учитывая, что 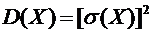 , из
формулы (9.1) получаем
, из
формулы (9.1) получаем
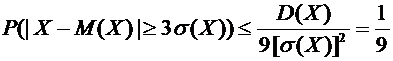 .
.
Теорема
9.1 (закон больших чисел в форме
Чебышева). Пусть  - последовательность независимых случайных величин,
дисперсии которых ограничены сверху одним и тем же числом с:
- последовательность независимых случайных величин,
дисперсии которых ограничены сверху одним и тем же числом с: 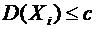 ,
,  .
.
Тогда
для любого имеет место:
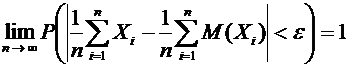 . (9.3)
. (9.3)
Из
этой теоремы вытекает справедливость закона больших чисел для среднего
арифметического независимых случайных величин, имеющих одинаковое распределение
вероятностей.
Следствие
9.1. Пусть - последовательность независимых случайных величин,
имеющих одно и то же математическое ожидание а, и дисперсии которых ограничены
сверху одним и тем же числом с: , . Тогда для любого имеет
место:
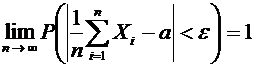 . (9.4)
. (9.4)
Закон
больших чисел для независимых случайных величин с одинаковым математическим
ожиданием отражает сходимость среднего арифметического случайных величин в
сериях независимых испытаний к общему математическому ожиданию этих случайных
величин.
Таким
образом, среднее арифметическое достаточно большого числа независимых случайных
величин (дисперсии которых равномерно ограничены) утрачивает характер случайной
величины. Объясняется это тем, что отклонения каждой из этих величин от своих
математических ожиданий могут быть как положительными, так и отрицательными, а
в среднем арифметическом они погашаются.
Закон
больших чисел имеет многочисленные практические приложения. Пусть, например,
производится п независимых измерений некоторой величины, истинное значение
которой равно а. Результат каждого измерения является случайной величиной 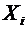 . Если измерения выполняются без систематической
погрешности, то математическое ожидание случайных величин можно считать равным истинному значению измеряемой
величины,
. Если измерения выполняются без систематической
погрешности, то математическое ожидание случайных величин можно считать равным истинному значению измеряемой
величины, 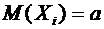 ,
,  .
Дисперсию результатов измерений часто можно считать ограниченной некоторым числом
с.
.
Дисперсию результатов измерений часто можно считать ограниченной некоторым числом
с.
Тогда
случайные результаты измерений удовлетворяют условиям теоремы 9.1 и,
следовательно, среднее арифметическое п измерений при большом числе измерений
практически не может сильно отличаться от истинного значения измеряемой
величины а. Этим обосновывается выбор среднего арифметического измерений в
качестве истинного значения измеряемой величины.
Для
относительной частоты успехов в независимых испытаниях справедлива следующая
теорема.
Теорема
9.2 (закон больших чисел в форме
Бернулли). Если в каждом из п независимых испытаний вероятность р появления
события А постоянна, то для числа успехов т в этих испытаниях при любом имеет место:
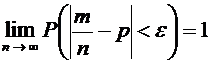 . (9.5)
. (9.5)
Рассмотрим
последовательность независимых, одинаково распределенных случайных величин . Пусть , 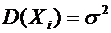 , .
Образуем последовательность
, .
Образуем последовательность 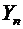 ,
, 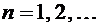 , центрированных и нормированных сумм случайных
величин:
, центрированных и нормированных сумм случайных
величин:
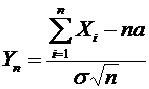 . (9.6)
. (9.6)
Согласно
центральной предельной теореме, при достаточно общих предположениях о законах
распределения случайных величин последовательность
функций распределения центрированных и нормированных сумм случайных величин при сходится
для любых х к функции распределения стандартной нормальной случайной величины.
Теорема
9.3 (центральная предельная теорема).
Пусть - последовательность независимых, одинаково
распределенных случайных величин, имеющих конечную дисперсию , и пусть , . Тогда для любого 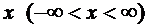 имеет
место:
имеет
место:
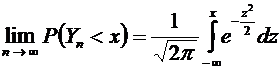 . (9.7)
. (9.7)
Вопросы для повторения и контроля:
1. О чем идет речь в теоремах, носящих общее название закона
больших чисел?
2. Что вы знаете о неравенстве Чебышева?
3. Что
утверждает закон больших чисел в форме Чебышева?
4. В чем сущность закона больших чисел и каково его практическое
значение?
5. Что
утверждает закон больших чисел в форме Бернулли?
6. О чем идет речь в центральной предельной теореме?
Опорные слова:
Закон больших чисел, неравенство Чебышева, последовательность независимых
случайных величин, центрированная и нормированная сумма случайных величин,
центральная предельная теорема.
. Предмет и основные задачи математической статистики. Выборка
Основная цель при применении математической статистики состоит в
получении выводов о массовых явлениях и процессах по данным наблюдений над ними
или экспериментов. Эти статистические выводы относятся не к отдельным
испытаниям, а представляют собой утверждения об общих характеристиках этого
явления (вероятностях, законах распределения и их параметрах, математических
ожиданиях и т.п.) в предположении постоянства условий, порождающих исследуемое
явление.
Установление закономерностей, которым подчинены массовые случайные
явления, основано на изучении методами теории вероятностей статистических
данных - результатов наблюдений.
Первая задача математической статистики - указать способы сбора и
группировки статистических сведений, полученных в результате наблюдений или в
результате специально поставленных экспериментов.
Вторая задача математической статистики - разработать методы анализа
статистических данных в зависимости от целей исследования, таких, как:
а) оценка неизвестной вероятности события; оценка неизвестной функции
распределения; оценка параметров распределения, вид которого известен; оценка
зависимости случайной величины от одной или нескольких случайных величин и др.;
б) проверка статистических гипотез о виде неизвестного распределения или
о величине параметров распределения, вид которого известен.
Итак, предметом математической статистики является создание методов сбора
и обработки статистических данных для получения научных и практических выводов.
Математическая статистика опирается на теорию вероятностей, и ее цель -
оценить характеристики генеральной совокупности по выборочным данным.
Если требуется изучить совокупность однородных объектов относительно
некоторого признака, характеризующего эти объекты, то естественным является
проведение сплошного обследования, т.е. обследование каждого из объектов
совокупности относительно этого признака. На практике, однако, проведение
сплошного обследования по тем или иным причинам часто бывает невозможным. В
таких случаях случайно отбирают из всей совокупности ограниченное число объектов
и подвергают их изучению.
Выборочной совокупностью или просто выборкой называется совокупность
случайно отобранных объектов. Генеральной совокупностью называется совокупность
объектов, из которых производится выборка. Например, если все студенты
Налоговой академии - это генеральная совокупность, то студенты какой-либо
группы являются выборкой.
Объемом
совокупности (выборочной или генеральной) называется число объектов этой
совокупности. Например, если из 1000 деталей отобрано для обследования 100
деталей, то объем генеральной совокупности 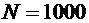 , а объем
выборки
, а объем
выборки 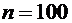 .
.
При
составлении выборки можно поступать двумя способами: после того, как объект
отобран и над ним произведено наблюдение, он может быть возвращен либо не
возвращен в генеральную совокупность. В зависимости от этого выборки
подразделяются на повторные и бесповторные.
Повторной
называют выборку, при которой отобранный объект (перед отбором следующего)
возвращается в генеральную совокупность. Бесповторной называют выборку, при
которой отобранный объект в генеральную совокупность не возвращается.
Для
того, чтобы по данным выборки можно было достаточно уверенно судить об
интересующем признаке генеральной совокупности, необходимо, чтобы объекты
выборки правильно его представляли. Другими словами, выборка должна правильно
представлять пропорции генеральной совокупности, т.е. выборка должна быть
репрезентативной (представительной).
В
силу закона больших чисел можно утверждать, что выборка будет репрезентативной,
если каждый объект выборки отобран случайно из генеральной совокупности в
предположении, что все объекты имеют одинаковую вероятность попасть в выборку.
Если
объем генеральной совокупности достаточно велик, а выборка составляет лишь незначительную
часть этой совокупности, то различие между повторной и бесповторной выборками
стирается; в предельном случае, когда рассматривается бесконечная генеральная
совокупность, а выборка имеет конечный объем, это различие исчезает.
На
практике применяются различные способы отбора. Существует отбор, не требующий
расчленения генеральной совокупности на части, например, простой случайный
бесповторный отбор и простой случайный повторный отбор, а также применяется
отбор, при котором генеральная совокупность разбивается на части (типический
отбор, механический отбор, серийный отбор).
Простым
случайным называется такой отбор, при котором объекты извлекаются по одному из
всей генеральной совокупности. Если извлеченные объекты возвращаются в
генеральную совокупность для участия в последующем отборе, то такой отбор будет
простым случайным повторным, в противном случае - простым случайным
бесповторным. Например, если требуется определить среднемесячную зарплату по
региону, то применяется простой случайный бесповторный отбор, так как зарплата
одного и того же человека учитывается только один раз. Если же требуется
определить половозрастной, социальный, образовательный состав различных
комиссий в каком-либо районе, то отбор является простым случайным повторным,
так как один и тот же работник может участвовать в различных комиссиях, и,
следовательно, попасть в выборку несколько раз.
Типическим
называется отбор, при котором объекты отбираются не из всей генеральной
совокупности, а из каждой ее "типической" части. Например, если
детали изготовляются на нескольких станках, то отбор производится не из всей
совокупности деталей, произведенных всеми станками, а из продукции каждого
станка в отдельности. Типическим отбором пользуются тогда, когда обследуемый
признак заметно колеблется в различных типических частях генеральной
совокупности.
Механическим
называется отбор, при котором генеральная совкупность механически делится на
столько примерно одинаковых по размеру групп, сколько объектов должно войти в
выборку, а из каждой группы отбирается объект с одним и тем же номером.
Например, если нужно отобрать 20% изготовленных станком деталей, то отбирается
каждая пятая деталь; если требуется отобрать 5% деталей, то отбирается каждая
двадцатая деталь и т.д. Иногда механический отбор может не обеспечить
репрезентативности выборки.
Серийным
называется отбор, при котором объекты отбираются из генеральной совокупности не
по одному, а "сериями", которые подвергаются сплошному обследованию.
Например, если изделия изготовляются большой группой станков-автоматов, то
подвергается сплошному обследованию продукция только нескольких станков.
Серийным отбором пользуются тогда, когда обследуемый признак колеблется в
различных сериях незначительно.
На
практике часто применяется комбинированный отбор, при котором сочетаются
указанные выше способы.
Вопросы для повторения и контроля:
1. Какие задачи стоят перед математической статистикой?
2. Какова цель применения математической статистики и в чем ее
предмет?
. Что такое выборочная совокупность (выборка), генеральная
совокупность, объем совокупности?
. Что называется повторной выборкой, бесповторной выборкой и
репрезентативной выборкой?
. Что представляет собой простой случайный отбор и типический
отбор?
. Что представляет собой механический отбор и серийный отбор?
Опорные слова:
Математическая статистика, оценка, проверка статистических гипотез, сбор
и обработка статистических данных, выборочная совокупность, выборка,
генеральная совокупность, объем совокупности, повторная выборка, бесповторная
выборка, репрезентативная выборка, простой случайный бесповторный отбор,
простой случайный повторный отбор, типический отбор, механический отбор,
серийный отбор, комбинированный отбор.
. Статистическое распределение выборки. Эмпирическая функция
распределения. Полигон и гистограмма
Пусть
из генеральной совокупности извлечена выборка. При этом пусть значение наблюдалось 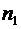 раз, -
раз, - 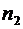 раз, ...
,
раз, ...
, 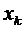 -
- 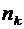 раз и
т.д.;
раз и
т.д.;  является объемом выборки.
является объемом выборки.
Наблюдаемые
значения называются вариантами, а последовательность вариант,
записанных в возрастающем порядке, - вариационным рядом. Числа наблюдений  называются частотами, а их отношения к объему выборки
называются частотами, а их отношения к объему выборки
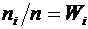 - относительными частотами.
- относительными частотами.
Статистическим
распределением выборки называется перечень вариант и соответствующих им частот
или относительных частот. Статистическое распределение можно задать также в
виде последовательности интервалов и соответствующих им частот. В этом случае в
качестве частоты, соответствующей интервалу, принимают сумму частот, попавших в
этот интервал. При этом сумма частот должна быть равна объему выборки, а сумма
относительных частот - единице.
В теории вероятностей под распределением понимается соответствие между
возможными значениями случайной величины и их вероятностями, а в математической
статистике - соответствие между наблюдаемыми вариантами и их частотами
(относительными частотами).
Пример
1. Задано распределение частот выборки объема 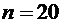 :
:
Таблица 11.1
|
3510
|
|
|
|
|
785
|
|
|
|
Написать
распределение относительных частот.
Решение. Найдем относительные частоты, для чего разделим частоты на объем
выборки:
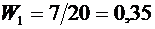 ,
, 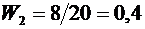 ,
, 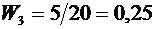 .
.
Напишем
распределение относительных частот:
Таблица 11.2
|
3510
|
|
|
|
|
 0,350,40,25 0,350,40,25
|
|
|
|
Контроль:
,35 + 0,4 + 0,25 = 1.
Пусть
известно статистическое распределение частот количественного признака Х.
Обозначим через 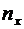 число наблюдений, при которых наблюдались значения
признака, меньшие х, а через - общее
число наблюдений (объем выборки). Относительная частота события равна
число наблюдений, при которых наблюдались значения
признака, меньшие х, а через - общее
число наблюдений (объем выборки). Относительная частота события равна 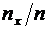 . При
изменении x изменяется и относительная частота, т.е. относительная частота есть функция от х.
. При
изменении x изменяется и относительная частота, т.е. относительная частота есть функция от х.
Эмпирической
функцией распределения (функцией распределения выборки) называется функция  , определяющая для каждого значения х относительную
частоту события , т.е.
, определяющая для каждого значения х относительную
частоту события , т.е.
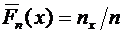 , (11.1)
, (11.1)
где
- число вариант, меньших х; - объем выборки.
Функция
называется эмпирической, потому что она находится
эмпирическим (опытным) путем.
В
отличие от эмпирической функции распределения выборки функция распределения генеральной совокупности называется теоретической
функцией распределения. Различие между эмпирической и теоретической функциями
состоит в том, что теоретическая функция определяет
вероятность события , а эмпирическая функция определяет относительную частоту этого же события.
Из
закона больших чисел в форме Бернулли (теорема 9.2) следует, что при больших относительная частота события , т.е. и
вероятность этого же события мало
отличаются одно от другого в том смысле, что
 при
любом . (11.2)
при
любом . (11.2)
С
другой стороны, из определения функции вытекает,
что она обладает всеми свойствами :
) значения
эмпирической функции принадлежат отрезку ;
) - неубывающая функция;
3) если
- наименьшая варианта, то  при
при 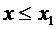 ; если - наибольшая варианта, то
; если - наибольшая варианта, то 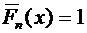 при
при 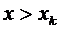 .
.
Отсюда следует целесообразность использования эмпирической функции
распределения выборки для приближенного представления теоретической функции
распределения генеральной совокупности. Другими словами, эмпирическая функция
распределения выборки служит для оценки теоретической функции распределения
генеральной совокупности.
Пример 2. Построить эмпирическую функцию по данному распределению
выборки:
Таблица 11.3
|
148
|
|
|
|
|
9318
|
|
|
|
Решение.
Найдем объем выборки:  . Наименьшая варианта равна 1, следовательно,
. Наименьшая варианта равна 1, следовательно,
при .
Значение
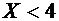 , а именно
, а именно 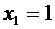 , наблюдалось
9 раз, следовательно,
, наблюдалось
9 раз, следовательно,
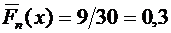 при .
при .
Значения
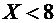 , а именно и
, а именно и  , наблюдались
, наблюдались 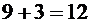 раз,
следовательно,
раз,
следовательно,
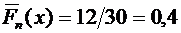 при .
при .
Так
как наибольшая варианта равна 8, то
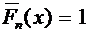 при .
при .
Искомая эмпирическая функция имеет вид
 .
.
График
этой функции изображен на рис. 11.1.
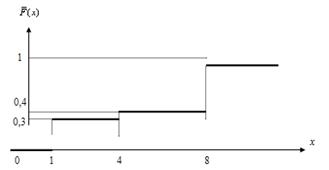
Рис.
11.1.
Статистическое распределение графически можно изобразить различными
способами, в частности, в виде полигона и гистограммы.
Полигоном
частот называется ломаная, отрезки которой соединяют точки 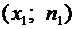 ,
, 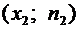 , ... ,
, ... ,  . Для построения полигона частот на оси абсцисс
откладывают варианты , а на оси ординат - соответствующие им частоты . Точки
. Для построения полигона частот на оси абсцисс
откладывают варианты , а на оси ординат - соответствующие им частоты . Точки 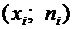 соединяют
отрезками прямых и получают полигон частот.
соединяют
отрезками прямых и получают полигон частот.
Полигоном
относительных частот называется ломаная, отрезки которой соединяют точки 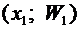 ,
,  , ...,
, ...,  . Полигон относительных частот строится аналогичным
полигону частот образом. На рис. 11.2 изображен полигон относительных частот
следующего распределения:
. Полигон относительных частот строится аналогичным
полигону частот образом. На рис. 11.2 изображен полигон относительных частот
следующего распределения:
Таблица 11.4
|
2468
|
|
|
|
|
|
0,10,50,250,15
|
|
|
|
|
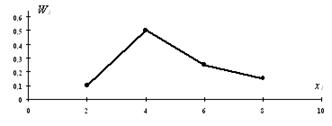
Рис. 11.2.
В
случае непрерывного признака целесообразно строить гистограмму, для чего
интервал, в котором заключены все наблюдаемые значения признака, разбивается на
несколько частичных интервалов длиной  и для
каждого частичного интервала находится - сумма
частот вариант, попавших в i-й интервал.
и для
каждого частичного интервала находится - сумма
частот вариант, попавших в i-й интервал.
Гистограммой
частот называется ступенчатая фигура, состоящая из прямоугольников, основаниями
которых служат частичные интервалы длиною , а
высоты равны отношению  . Для построения гистограммы частот на оси абсцисс
следует отложить частичные интервалы, а над ними провести отрезки, параллельные
оси абсцисс на расстоянии .
. Для построения гистограммы частот на оси абсцисс
следует отложить частичные интервалы, а над ними провести отрезки, параллельные
оси абсцисс на расстоянии .
Площадь
i-го частичного прямоугольника равна 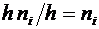 - сумме
частот вариант i-го интервала; следовательно, площадь гистограммы частот равна
сумме всех частот, т.е. объему выборки.
- сумме
частот вариант i-го интервала; следовательно, площадь гистограммы частот равна
сумме всех частот, т.е. объему выборки.
Таблица 11.5
|
Частичный интервал длиною h
= 5
|
Сумма частот вариант
частичного интервала Плотность частоты
|
|
|
5 - 10
|
4
|
0,8
|
|
10 - 15
|
6
|
1,2
|
|
15 - 20
|
16
|
3,2
|
|
20 - 25
|
36
|
7,2
|
|
25 - 30
|
24
|
4,8
|
|
30 - 35
|
10
|
2,0
|
|
35 - 40
|
4
|
0,8
|
На рис. 11.3 изображена гистограмма частот распределения, заданного в
табл. 11.5.
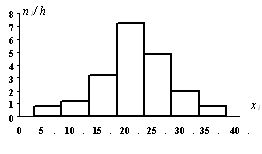
Рис. 11.3.
Гистограммой
относительных частот называется ступенчатая фигура, состоящая из
прямоугольников, основаниями которых служат частичные интервалы длиною , а высоты равны отношению 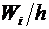 . Гистограмма относительных частот строится
аналогичным гистограмме частот образом.
. Гистограмма относительных частот строится
аналогичным гистограмме частот образом.
Площадь
i-го частичного прямоугольника равна  - сумме
относительных частот вариант i-го интервала; следовательно, площадь гистограммы
относительных частот равна сумме всех относительных частот, т.е. единице.
- сумме
относительных частот вариант i-го интервала; следовательно, площадь гистограммы
относительных частот равна сумме всех относительных частот, т.е. единице.
Вопросы для повторения и контроля:
1. Что называется вариантами, вариационным рядом, частотами и
относительными частотами?
2. Что такое статистическое распределение выборки и как оно
задается, какова разница между распределением в теории вероятностей и
распределением в математической статистике?
3. Что такое эмпирическая функция распределения и теоретическая
функция распределения?
. Какими свойствами обладает эмпирическая функция распределения?
5. В чем целесообразность использования эмпирической функции
распределения выборки для оценки теоретической функции распределения
генеральной совокупности?
6. Что называется полигоном частот и полигоном относительных
частот, как они строятся?
7. Что такое гистограмма частот, как она строится и чему равна
площадь гистограммы частот?
8. Что такое гистограмма относительных частот, как она строится и
чему равна площадь гистограммы относительных частот?
Опорные слова:
Варианта, вариационный ряд, частота, относительная частота,
статистическое распределение выборки, эмпирическая функция распределения,
теоретическая функция распределения, полигон частот, полигон относительных
частот, гистограмма частот, площадь гистограммы частот, гистограмма
относительных частот, площадь гистограммы относительных частот.
. Статистическая оценка. Требования, предъявляемые к статистической
оценке. Выборочное среднее и выборочная дисперсия
Теория статистического оценивания с точки зрения постановки задачи
подразделяется на параметрические и непараметрические случаи.
Если требуется изучить количественный признак генеральной совокупности,
то возникает задача оценки параметров, которыми определяется распределение
этого признака. Например, если наперед известно, что изучаемый признак
распределен в генеральной совокупности нормально, то необходимо оценить
(приближенно найти) математическое ожидание и среднее квадратическое
отклонение, так как эти два параметра полностью определяют нормальное
распределение.
Обычно
имеются лишь данные выборки, например, значения количественного признака , , ..., 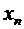 , полученные в результате наблюдений, причем эти наблюдения предполагаются
независимыми. Через эти данные и выражается оцениваемый параметр. Рассматривая , , ..., как независимые случайные величины
, полученные в результате наблюдений, причем эти наблюдения предполагаются
независимыми. Через эти данные и выражается оцениваемый параметр. Рассматривая , , ..., как независимые случайные величины  ,
, 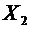 , ... ,
, ... , 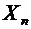 , можно сказать, что нахождение статистической оценки
неизвестного параметра теоретического распределения равносильно нахождению
функции от наблюдаемых случайных величин, которая и дает приближенное значение
оцениваемого параметра. Например, для оценки математического ожидания
нормального распределения служит функция
, можно сказать, что нахождение статистической оценки
неизвестного параметра теоретического распределения равносильно нахождению
функции от наблюдаемых случайных величин, которая и дает приближенное значение
оцениваемого параметра. Например, для оценки математического ожидания
нормального распределения служит функция 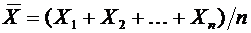 , которая
является средним арифметическим наблюдаемых значений признака.
, которая
является средним арифметическим наблюдаемых значений признака.
Таким
образом, статистической оценкой неизвестного параметра 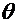 теоретического распределения называется функция
теоретического распределения называется функция  от наблюдаемых случайных величин, которая в
определенном статистическом смысле близка к истинному значению этого параметра.
от наблюдаемых случайных величин, которая в
определенном статистическом смысле близка к истинному значению этого параметра.
Важнейшими
свойствами статистической оценки, определяющими ее близость к истинному
значению оцениваемого параметра, являются свойства несмещенности,
состоятельности и эффективности.
Пусть
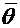 - статистическая оценка неизвестного параметра теоретического распределения. Многократно извлекая из
генеральной совокупности выборки объема , можно
получить оценки
- статистическая оценка неизвестного параметра теоретического распределения. Многократно извлекая из
генеральной совокупности выборки объема , можно
получить оценки 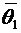 ,
, 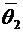 , ... ,
, ... , 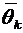 , которые, вообще говоря, различны между собой. Таким
образом, оценку можно рассматривать как случайную величину, а числа , , ... , - как ее возможные значения.
, которые, вообще говоря, различны между собой. Таким
образом, оценку можно рассматривать как случайную величину, а числа , , ... , - как ее возможные значения.
Если
оценка дает приближенное значение с избытком, то каждое найденное по данным выборок
число  (
( ) больше
истинного значения . Ясно, что в этом случае и математическое ожидание
(среднее значение) случайной величины больше,
чем , т.е.
) больше
истинного значения . Ясно, что в этом случае и математическое ожидание
(среднее значение) случайной величины больше,
чем , т.е.  .
Очевидно, что если дает оценку с недостатком, то
.
Очевидно, что если дает оценку с недостатком, то 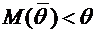 .
.
Отсюда
видно, что использование статистической оценки, математическое ожидание которой
не равно оцениваемому параметру, приведет к систематическим ошибкам, которые
являются неслучайными ошибками, искажающими результаты измерений в одну
определенную сторону. По этой причине равенство математического ожидания оценки
оцениваемому параметру хотя и не устраняет ошибок
ввиду того, что одни значения больше,
а другие меньше , однако гарантирует от получения систематических
ошибок, так как ошибки разных знаков будут встречаться одинаково часто.
Статистическая
оценка называется несмещенной, если ее математическое
ожидание равно оцениваемому параметру при
любом объеме выборки, т.е.
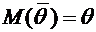 . (12.1)
. (12.1)
Смещенной
называется оценка, математическое ожидание которой не равно оцениваемому
параметру.
Однако
несмещенная оценка необязательно каждый раз дает хорошее приближение
оцениваемого параметра. Действительно, возможные значения могут быть сильно рассеяны вокруг своего среднего
значения, т.е. дисперсия 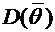 может быть значительной. В этом случае найденная по
данным одной выборки оценка может оказаться весьма удаленной от среднего
значения , а значит, и от самого оцениваемого параметра . Если же потребовать, чтобы дисперсия была малой, то возможность допустить большую ошибку
будет исключена.
может быть значительной. В этом случае найденная по
данным одной выборки оценка может оказаться весьма удаленной от среднего
значения , а значит, и от самого оцениваемого параметра . Если же потребовать, чтобы дисперсия была малой, то возможность допустить большую ошибку
будет исключена.
Статистическая
оценка называется эффективной, если при заданном объеме выборки она имеет наименьшую возможную дисперсию.
Статистическая
оценка называется состоятельной, если она сходится по
вероятности к оцениваемому параметру , т.е.
для любого
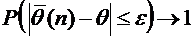 при . (12.2)
при . (12.2)
Например,
если дисперсия несмещенной оценки при стремится
к нулю, то такая оценка оказывается и состоятельной.
Пусть
генеральная совокупность изучается относительно количественного признака Х.
Генеральной
средней  называется среднее арифметическое значений признака
генеральной совокупности.
называется среднее арифметическое значений признака
генеральной совокупности.
Если
все значения , , ... ,  признака генеральной совокупности объема
признака генеральной совокупности объема 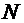 различны, то генеральная средняя равна
различны, то генеральная средняя равна
 . (12.3)
. (12.3)
Если
же значения признака , , ... , имеют соответственно частоты 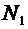 ,
, 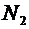 , ... ,
, ... , 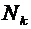 , причем
, причем 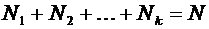 , то в
этом случае генеральная средняя равна
, то в
этом случае генеральная средняя равна
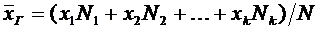 . (12.4)
. (12.4)
Если
рассматривать обследуемый признак Х генеральной совокупности как случайную
величину и сопоставлять формулы (12.3) и (12.4) с формулами (6.1) и (6.2), то
можно сделать вывод, что математическое ожидание признака равно генеральной
средней этого признака:
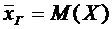 . (12.5)
. (12.5)
Пусть
теперь для изучения генеральной совокупности относительно количественного
признака Х извлечена выборка объема .
Выборочной
средней  называется среднее арифметическое наблюдаемых
значений признака выборочной совокупности.
называется среднее арифметическое наблюдаемых
значений признака выборочной совокупности.
Если
все значения , , ... , признака выборки объема различны, то выборочная средняя равна
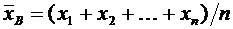 . (12.6)
. (12.6)
Если
же значения признака , , ... , имеют соответственно частоты , , ... , , причем 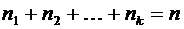 , то в
этом случае выборочная средняя равна
, то в
этом случае выборочная средняя равна
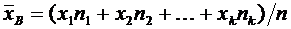 (12.7)
(12.7)
или
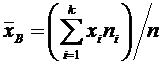 . (12.8)
. (12.8)
Убедимся,
что выборочная средняя является несмещенной оценкой генеральной средней, т.е.
покажем, что математическое ожидание равно . Будем рассматривать как
случайную величину и , , ... , как независимые, одинаково распределенные случайные
величины. Поскольку эти величины одинаково распределены, то они имеют
одинаковые числовые характеристики, в частности одинаковое математическое
ожидание, которое равно математическому ожиданию признака Х генеральной совокупности.
На
основании этого, используя свойство 6.2, следствие 6.2, а также формулы (12.5)
и (12.6), получаем
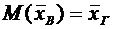 . (12.9)
. (12.9)
Используя
следствие 9.1, легко показать, что выборочная средняя является и состоятельной
оценкой генеральной средней.
Для
того, чтобы охарактеризовать рассеяния значений количественных признаков
генеральной и выборочной совокупностей вокруг своих средних значений, вводятся
сводные характеристики - соответственно генеральная и выборочная дисперсии, а
также средние квадратические отклонения.
Генеральной
дисперсией 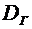 называется среднее арифметическое квадратов
отклонений значений признака генеральной совокупности от их среднего значения .
называется среднее арифметическое квадратов
отклонений значений признака генеральной совокупности от их среднего значения .
Если
все значения , , ... , признака генеральной совокупности объема различны, то генеральная дисперсия равна
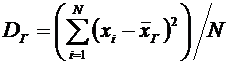 . (12.10)
. (12.10)
Если
же значения признака , , ... , имеют соответственно частоты , , ... , , причем , то в
этом случае генеральная дисперсия равна
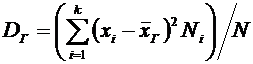 . (12.11)
. (12.11)
Генеральным
средним квадратическим отклонением называется квадратный корень из генеральной
дисперсии:
 . (12.12)
. (12.12)
Пример
1. Генеральная совокупность задана следующей таблицей распределения:
Таблица 12.1
|
2456
|
|
|
|
|
|
 89103 89103
|
|
|
|
|
Найти
генеральную дисперсию и генеральное среднее квадратическое отклонение.
Решение. Найдем генеральную среднюю:
 .
.
Найдем
генеральную дисперсию:
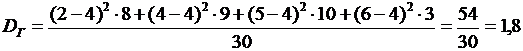 .
.
Найдем
генеральное среднее квадратическое отклонение:
 .
.
Выборочной
дисперсией  называется среднее арифметическое квадратов
отклонений наблюдаемых значений признака выборочной совокупности от их среднего
значения .
называется среднее арифметическое квадратов
отклонений наблюдаемых значений признака выборочной совокупности от их среднего
значения .
Если
все значения , , ... , признака выборки объема различны, то выборочная дисперсия равна
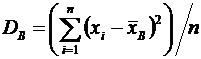 . (12.13)
. (12.13)
Если
же значения признака , , ... , имеют соответственно частоты , , ... , , причем , то в
этом случае выборочная дисперсия равна
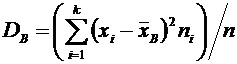 . (12.14)
. (12.14)
Выборочным
средним квадратическим отклонением называется квадратный корень из генеральной
дисперсии:
Пример
2. Выборочная совокупность задана следующей таблицей распределения:
Таблица 12.2
|
1234
|
|
|
|
|
|
2015105
|
|
|
|
|
Найти
выборочную дисперсию и выборочное среднее квадратическое отклонение.
Решение. Найдем выборочную
среднюю:
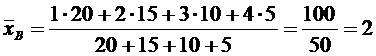 .
.
Найдем
выборочную дисперсию:
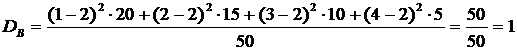 .
.
Найдем
выборочное среднее квадратическое отклонение:
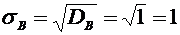 .
.
Дисперсии
удобнее вычислять, используя следующие формулы:
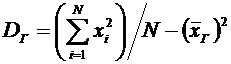 , (12.16)
, (12.16)
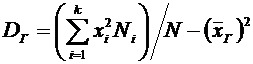 , (12.17)
, (12.17)
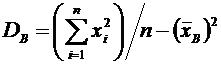 (12.18)
(12.18)
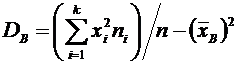 . (12.19)
. (12.19)
Теперь
пусть требуется по данным выборки оценить неизвестную генеральную дисперсию . Выборочная дисперсия является
смещенной оценкой , так как
 . (12.20)
. (12.20)
Если
же в качестве оценки генеральной дисперсии принять исправленную дисперсию 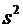 , которая получается путем умножения на дробь
, которая получается путем умножения на дробь  , то она
будет несмещенной оценкой генеральной дисперсии. Действительно, учитывая
(12.20), имеем
, то она
будет несмещенной оценкой генеральной дисперсии. Действительно, учитывая
(12.20), имеем
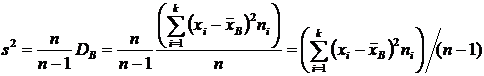 (12.21)
(12.21)
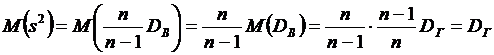 . (12.22)
. (12.22)
Вопросы для повторения и контроля:
1. Что называется статистической оценкой неизвестного параметра и
какими важнейшими свойствами она может обладать?
2. Что такое несмещенная оценка и чем обосновывается ее введение?
3. Что такое эффективная оценка и в чем необходимость ее ввода?
4. Что называется смещенной оценкой и состоятельной оценкой?
5. Что такое генеральная средняя и по каким формулам она
вычисляется?
6. Что называется выборочной средней и по каким формулам она
вычисляется?
7. Какой оценкой генеральной средней является выборочная средняя?
8. Что такое генеральная дисперсия и по каким формулам она
вычисляется?
9. Что называется выборочной дисперсией и по каким формулам она
вычисляется?
10. Что такое генеральное среднее квадратическое отклонение и
выборочное среднее квадратическое отклонение, для чего они, а также генеральная
и выборочная дисперсии вводятся?
. По каким формулам удобнее вычислять дисперсии?
. Что является несмещенной оценкой генеральной дисперсии?
Опорные слова:
Статистическая оценка неизвестного параметра, несмещенная оценка,
смещенная оценка, эффективная оценка, состоятельная оценка, генеральная
средняя, выборочная средняя, генеральная дисперсия, генеральное среднее
квадратическое отклонение, выборочная дисперсия, выборочное среднее
квадратическое отклонение, исправленная дисперсия.
. Интервальные оценки. Доверительный интервал. Доверительные интервалы
для неизвестных параметров нормального распределения
Имеется два способа оценки параметров: точечный и интервальный. Точечные
методы указывают лишь точку, около которой находится неизвестный оцениваемый
параметр. С помощью интервальных способов можно найти интервал, в котором с
некоторой вероятностью находится неизвестное значение параметра.
Точечной называется оценка, которая определяется одним числом. При
выборке малого объема точечная оценка может значительно отличаться от
оцениваемого параметра, т.е. приводить к грубым ошибкам. По этой причине при небольшом
объеме выборки следует пользоваться интервальными оценками.
Интервальной называется оценка, которая определяется двумя числами -
концами интервала. Интервальные оценки позволяют установить точность и
надежность оценок.
Пусть
найденная по данным выборки статистическая характеристика служит оценкой неизвестного параметра . Если 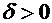 и
и 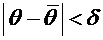 , то оценка тем
точнее определяет параметр , чем
меньше
, то оценка тем
точнее определяет параметр , чем
меньше  . Точность оценки характеризуется положительным числом
.
. Точность оценки характеризуется положительным числом
.
Однако
нельзя категорически утверждать, что оценка удовлетворяет
неравенству . Статистические методы позволяют лишь говорить о
вероятности, с которой это неравенство осуществляется.
Надежностью
(доверительной вероятностью) оценки по называется вероятность  , с
которой осуществляется неравенство , т.е.
, с
которой осуществляется неравенство , т.е.
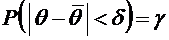 . (13.1)
. (13.1)
В
качестве берется число, близкое к единице.
Из
неравенства легко можно получить двойное неравенство
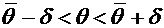 . (13.2)
. (13.2)
Тогда
соотношение (13.1) принимает следующий вид
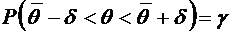 . (13.3)
. (13.3)
Это
соотношение означает следующее: вероятность того, что интервал 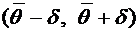 заключает в себе (покрывает) неизвестный параметр , равна .
заключает в себе (покрывает) неизвестный параметр , равна .
Интервал
называется доверительным интервалом, который
покрывает неизвестный параметр с
заданной надежностью .
Пусть
количественный признак Х генеральной совокупности распределен нормально, причем
среднее квадратическое отклонение  этого
распределения известно. Требуется оценить неизвестное математическое ожидание
этого
распределения известно. Требуется оценить неизвестное математическое ожидание 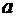 по выборочной средней
по выборочной средней 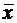 .
Поставим своей задачей найти доверительные интервалы, покрывающие параметр с надежностью .
.
Поставим своей задачей найти доверительные интервалы, покрывающие параметр с надежностью .
Будем
рассматривать выборочную среднюю как
случайную величину 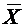 (
изменяется от выборки к выборке) и выборочные значения признака , , ... , - как одинаково распределенные случайные величины , , ... , (эти числа также изменяются от выборки к выборке).
Математическое ожидание каждой из этих величин равно и среднее квадратическое отклонение - .
(
изменяется от выборки к выборке) и выборочные значения признака , , ... , - как одинаково распределенные случайные величины , , ... , (эти числа также изменяются от выборки к выборке).
Математическое ожидание каждой из этих величин равно и среднее квадратическое отклонение - .
Тогда,
используя свойство 6.2, следствие 6.2, а также формулу (12.6), получаем, что
параметры распределения следующие:
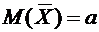 ,
, 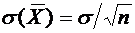 . (13.4)
. (13.4)
Потребуем,
чтобы выполнялось соотношение
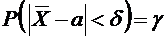 , (13.5)
, (13.5)
где
- заданная надежность.
Используя
формулу (8.11) с заменой  на и на ,
нетрудно получить соотношение
на и на ,
нетрудно получить соотношение
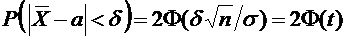 , (13.6)
, (13.6)
где
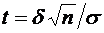 .
.
Найдя
из последнего равенства  , можно написать
, можно написать
 . (13.7)
. (13.7)
Обозначая
для общности выборочную среднюю вновь через , из
соотношений (13.5) - (13.7) получаем соотношения
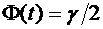 (13.8)
(13.8)
И
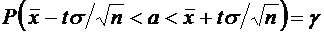 . (13.9)
. (13.9)
Значит,
с надежностью можно утверждать, что доверительный интервал  покрывает неизвестный параметр , при этом точность оценки равна , а число
покрывает неизвестный параметр , при этом точность оценки равна , а число 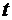 определяется
из равенства (13.8) по таблице функции Лапласа.
определяется
из равенства (13.8) по таблице функции Лапласа.
Пример
1. Случайная величина Х имеет нормальное распределение с известным средним
квадратическим отклонением  . Найти
доверительный интервал для оценки неизвестного математического ожидания по выборочной средней , если
объем выборки
. Найти
доверительный интервал для оценки неизвестного математического ожидания по выборочной средней , если
объем выборки  и задана надежность оценки
и задана надежность оценки  .
.
Решение.
Найдем . Из соотношения (13.8) получаем 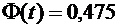 и по таблице функции Лапласа находим
и по таблице функции Лапласа находим 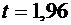 .
.
Найдем
точность оценки:
 .
.
Доверительный
интервал таков: 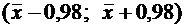 . Например, если
. Например, если 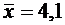 , то
доверительный интервал имеет следующие доверительные границы:
, то
доверительный интервал имеет следующие доверительные границы:
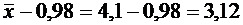 ;
; 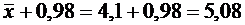 .
.
Далее
нам потребуются распределения "хи квадрат" и Стьюдента.
Пусть
(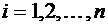 ) -
нормальные независимые случайные величины, причем математическое ожидание
каждой из них равно нулю, а среднее квадратическое отклонение - единице. Тогда
сумма квадратов этих величин
) -
нормальные независимые случайные величины, причем математическое ожидание
каждой из них равно нулю, а среднее квадратическое отклонение - единице. Тогда
сумма квадратов этих величин  распределена
по закону
распределена
по закону 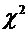 ("хи квадрат") с
("хи квадрат") с 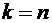 степенями свободы.
степенями свободы.
Функция
плотности этого распределения имеет вид
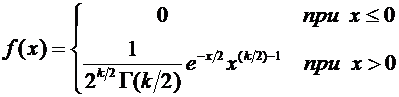 , (13.10)
, (13.10)
где
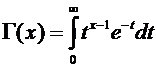 - гамма-функция.
- гамма-функция.
Отсюда
видно, что распределение "хи квадрат" определяется одним параметром -
числом степеней свободы  .
.
Далее,
пусть  - нормальная случайная величина, причем
- нормальная случайная величина, причем 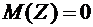 ,
, 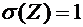 , а
, а  - независимая от случайная
величина, которая распределена по закону с степенями свободы. Тогда случайная величина
- независимая от случайная
величина, которая распределена по закону с степенями свободы. Тогда случайная величина
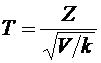 (13.11)
(13.11)
имеет
распределение, которое называется -распределением
или распределением Стьюдента с степенями
свободы.
Пусть
теперь требуется оценить неизвестное математическое ожидание количественного признака Х генеральной совокупности,
который распределен нормально, по выборочной средней , когда среднее квадратическое отклонение этого распределения н е и з в е с т н о. Поставим
своей задачей найти доверительные интервалы, покрывающие параметр с надежностью .
Рассмотрим
случайную величину
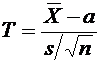 , (13.12)
, (13.12)
которая
имеет распределение Стьюдента с 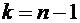 степенями
свободы. Здесь - выборочная средняя,
степенями
свободы. Здесь - выборочная средняя, 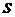 -
"исправленное" среднее квадратическое отклонение, - объем выборки.
-
"исправленное" среднее квадратическое отклонение, - объем выборки.
Функция
плотности распределения этой случайной величины равна
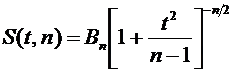 , (13.13)
, (13.13)
где
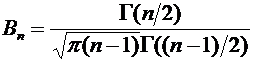 .
.
Отсюда
видно, что распределение случайной величины (13.12) определяется параметром - объемом выборки и не зависит от неизвестных
параметров и .
Поскольку
 - четная функция от , то
вероятность осуществления неравенства
- четная функция от , то
вероятность осуществления неравенства
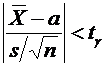 (13.14)
(13.14)
определяется
на основании теоремы 7.1 из следующей формулы
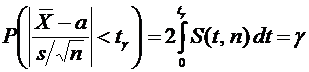 . (13.15)
. (13.15)
Заменив
неравенство (13.14) равносильным ему двойным неравенством, получаем соотношение
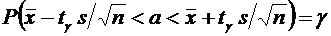 . (13.16)
. (13.16)
Итак,
пользуясь распределением Стьюдента, мы нашли доверительный интервал 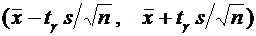 , покрывающий неизвестный параметр с надежностью . Из
специальной таблицы по заданным и можно найти
, покрывающий неизвестный параметр с надежностью . Из
специальной таблицы по заданным и можно найти 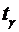 .
.
Пример
2. Количественный признак Х генеральной совокупности распределен нормально. По
выборке объема 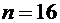 найдены выборочная средняя
найдены выборочная средняя 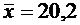 и "исправленное" среднее квадратическое
отклонение
и "исправленное" среднее квадратическое
отклонение 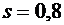 . Оценить неизвестное математическое ожидание при помощи доверительного интервала с надежностью .
. Оценить неизвестное математическое ожидание при помощи доверительного интервала с надежностью .
Решение.
Найдем . Пользуясь таблицей, по и находим 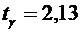 .
.
Найдем
доверительные границы:
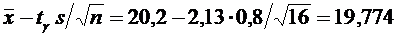 ,
,
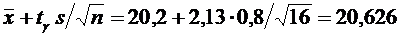 .
.
Итак,
с надежностью 0,95 неизвестный параметр заключен в доверительном интервале 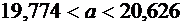 .
.
Пусть
количественный признак Х генеральной совокупности распределен нормально.
Требуется оценить неизвестное генеральное среднее квадратическое отклонение по "исправленному" среднему квадратическому
отклонению . Поставим перед собой задачу найти доверительные
интервалы, покрывающие параметр с
заданной надежностью .
Потребуем,
чтобы выполнялось соотношение
 (13.17)
(13.17)
или
равносильное ему соотношение
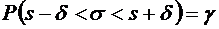 , (13.18)
, (13.18)
где
- заданная надежность.
Положив
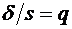 , из двойного неравенства
, из двойного неравенства
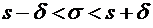 (13.19)
(13.19)
получаем
неравенство
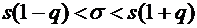 . (13.20)
. (13.20)
Для
нахождения доверительного интервала, покрывающего параметр , остается только найти  . С этой
целью рассмотрим случайную величину
. С этой
целью рассмотрим случайную величину
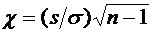 , (13.21)
, (13.21)
где
- объем выборки (эта случайная величина обозначена
через 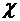 ввиду того, что случайная величина
ввиду того, что случайная величина 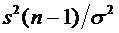 распределена по закону с
распределена по закону с 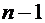 степенями свободы).
степенями свободы).
Функция
плотности распределения случайной величины имеет
следующий вид
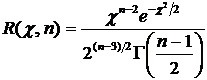 . (13.22)
. (13.22)
Это
распределение не зависит от оцениваемого параметра , а зависит лишь от объема выборки .
Из
неравенства (13.20) можно получить неравенство
 . (13.23)
. (13.23)
Умножив
все члены этого неравенства на 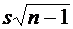 ,
получаем
,
получаем
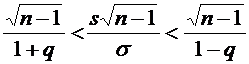
Или
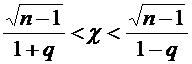 . (13.24)
. (13.24)
Воспользовавшись
теоремой 7.1, находим, что вероятность осуществления этого неравенства и,
следовательно, равносильного ему неравенства (13.20), равна
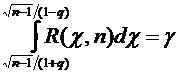 . (13.25)
. (13.25)
Из
этого уравнения можно по заданным и найти . Однако
на практике находится из специальной таблицы.
Вычислив
по выборке и найдя по таблице , получим
искомый доверительный интервал  ,
покрывающий неизвестный параметр с
заданной надежностью .
,
покрывающий неизвестный параметр с
заданной надежностью .
Пример
3. Количественный признак Х генеральной совокупности распределен нормально. По
выборке объема 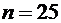 найдено "исправленное" среднее
квадратическое отклонение . Найти доверительный интервал, покрывающий генеральное
среднее квадратическое отклонение с надежностью .
найдено "исправленное" среднее
квадратическое отклонение . Найти доверительный интервал, покрывающий генеральное
среднее квадратическое отклонение с надежностью .
Решение.
По специальной таблице по данным и найдем 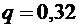 .
.
Найдем
искомый доверительный интервал:
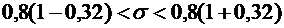
Или
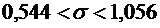 .
.
Вопросы для повторения и контроля:
1. Какие способы оценки параметров и связанные с ними оценки вы
знаете?
2. Что
такое точность оценки и надежность (доверительная вероятность)?
3. Что называется доверительным интервалом?
4. Как находится доверительный интервал для оценки математического
ожидания нормального распределения при известном среднем квадратическом
отклонении?
. Что вы знаете о распределениях "хи квадрат" и
Стьюдента?
. Как находится доверительный интервал для оценки математического
ожидания нормального распределения при неизвестном среднем квадратическом
отклонении?
. Как находится доверительный интервал для оценки среднего
квадратического отклонения нормального распределения?
Опорные слова:
Точечная оценка, интервальная оценка, точность оценки, надежность
(доверительная вероятность), доверительный интервал, доверительный интервал для
оценки математического ожидания нормального распределения при известном среднем
квадратическом отклонении, распределение "хи квадрат", распределение
Стьюдента, доверительный интервал для оценки математического ожидания
нормального распределения при неизвестном среднем квадратическом отклонении,
доверительный интервал для оценки среднего квадратического отклонения
нормального распределения.
. Элементы корреляционного и регрессионного анализа
Корреляционный анализ и регрессионный анализ являются смежными разделами
математической статистики и предназначены для изучения по выборочным данным статистической
зависимости случайных величин. Две случайные величины могут быть связаны либо
функциональной зависимостью, либо статистической зависимостью, либо быть
независимыми.
Если
каждому возможному значению случайной величины соответствует
одно возможное значение случайной величины  , то называется функцией случайного аргумента :
, то называется функцией случайного аргумента :
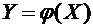 ,
,
а
зависимость между случайными величинами и называется функциональной зависимостью.
Строгая
функциональная зависимость реализуется редко, так как обе величины или одна из
них подвержены еще действию случайных факторов, причем среди них могут быть и
общие для обеих величин, т.е. такие факторы, которые воздействуют как на , так и на . В этом
случае возникает статистическая зависимость. Статистической называется
зависимость, при которой изменение одной из величин влечет изменение
распределения другой. Частным случаем статистической зависимости является
корреляционная зависимость.
Если
статистическая зависимость проявляется в том, что при изменении одной из
рассматриваемых случайных величин изменяется среднее значение другой случайной
величины, то такая статистическая зависимость называется корреляционной.
Приведем
пример случайной величины , которая не связана с величиной функционально, а связана корреляционно. Пусть - урожай зерна, -
количество удобрений. С одинаковых по площади участков земли при равных
количествах внесенных удобрений снимают различный урожай, т.е. не является функцией от . Это объясняется влиянием случайных факторов, таких,
как осадки, температура воздуха и др. С другой стороны, средний урожай является
функцией от количества удобрений, т.е. связан с
корреляционной зависимостью.
Условным
средним 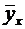 называется среднее арифметическое наблюдавшихся
значений , соответствующих
называется среднее арифметическое наблюдавшихся
значений , соответствующих 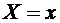 .
Например, если при
.
Например, если при 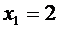 величина приняла
значения
величина приняла
значения 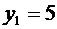 ,
, 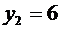 ,
,  , то условное среднее равно
, то условное среднее равно
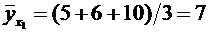 .
.
Условным
средним 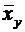 называется среднее арифметическое наблюдавшихся
значений , соответствующих
называется среднее арифметическое наблюдавшихся
значений , соответствующих 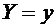 .
.
Как
видно из определения, условное среднее является
функцией от 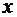 ; обозначив эту функцию через
; обозначив эту функцию через 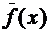 , получим уравнение
, получим уравнение
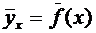 . (14.1)
. (14.1)
Это
уравнение называется выборочным уравнением регрессии на ; функция
называется выборочной регрессией на , а ее
график - выборочной линией регрессии на .
Аналогично
уравнение
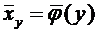 (14.2)
(14.2)
называется
выборочным уравнением регрессии на ; функция 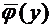 называется
выборочной регрессией на , а ее
график - выборочной линией регрессии на .
называется
выборочной регрессией на , а ее
график - выборочной линией регрессии на .
В
связи с вышеизложенным возникают две задачи
теории корреляции. Первая - нахождение по данным наблюдений параметров функций и при
условии, что известен их вид. Вторая - оценка силы (тесноты) связи между
случайными величинами и и
установление наличия корреляционной зависимости между этими величинами.
Пусть
изучается система количественных признаков  . В
результате независимых опытов получены пар чисел
. В
результате независимых опытов получены пар чисел  ,
, 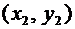 , ... ,
, ... , 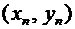 .
.
Найдем
по данным наблюдений выборочное уравнение прямой линии регрессии. Для
определенности будем искать уравнение
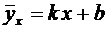 (14.3)
(14.3)
регрессии
на .
Поскольку
различные значения признака и
соответствующие им значения 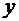 признака
наблюдались по одному разу, то группировать данные
нет необходимости. Также нет надобности использовать понятие условной средней,
поэтому уравнение (14.3) можно записать следующим образом:
признака
наблюдались по одному разу, то группировать данные
нет необходимости. Также нет надобности использовать понятие условной средней,
поэтому уравнение (14.3) можно записать следующим образом:
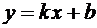 . (14.4)
. (14.4)
Угловой
коэффициент прямой линии регрессии на называется выборочным коэффициентом регрессии на и
обозначается через 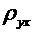 . Следовательно, искомое выборочное уравнение (14.4)
прямой линии регрессии на следует
искать в виде
. Следовательно, искомое выборочное уравнение (14.4)
прямой линии регрессии на следует
искать в виде
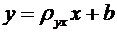 . (14.5)
. (14.5)
Нужно
найти такие параметры и 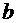 , при
которых точки , , ... , , построенные по данным наблюдений, на плоскости
, при
которых точки , , ... , , построенные по данным наблюдений, на плоскости 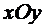 лежали как можно ближе к прямой (14.5).
лежали как можно ближе к прямой (14.5).
Для
осуществления этого воспользуемся методом наименьших квадратов. При
использовании этого метода сумма квадратов отклонений 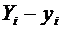 (), где
(), где 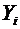 - вычисленная по уравнению (14.5) ордината,
соответствующая наблюдаемому значению , а
- вычисленная по уравнению (14.5) ордината,
соответствующая наблюдаемому значению , а 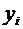 - наблюдаемая ордината, соответствующая , должна быть минимальной. Так как каждое отклонение
зависит от отыскиваемых параметров, то и сумма квадратов отклонений есть
функция этих параметров:
- наблюдаемая ордината, соответствующая , должна быть минимальной. Так как каждое отклонение
зависит от отыскиваемых параметров, то и сумма квадратов отклонений есть
функция этих параметров:
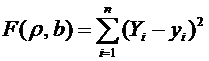 (14.6)
(14.6)
или
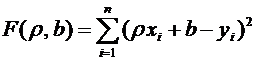 . (14.7)
. (14.7)
Для
отыскания минимума приравняем нулю соответствующие частные производные:
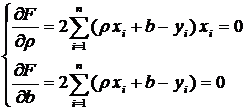 . (14.8)
. (14.8)
Решив
эту систему двух линейных уравнений относительно 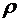 и , найдем искомые параметры:
и , найдем искомые параметры:
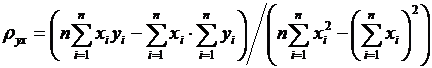 ; (14.9)
; (14.9)
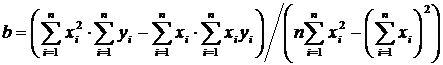 . (14.10)
. (14.10)
Аналогично
можно найти выборочное уравнение прямой линии регрессии на :
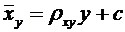 , (14.11)
, (14.11)
где
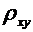 - выборочный коэффициент регрессии на .
- выборочный коэффициент регрессии на .
Пример
1. Найти выборочное уравнение прямой линии регрессии на по
данным 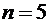 наблюдений:
наблюдений:
Таблица 14.1
|
1,001,503,004,505,00
|
|
|
|
|
|
|
1,251,401,501,752,25
|
|
|
|
|
|
Решение. Составим следующую расчетную табл. 14.2.
Найдем искомые параметры из соотношений (14.9) и (14.10):
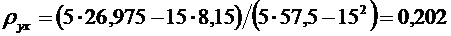 ;
;
 .
.
Напишем
искомое уравнение прямой линии регрессии на :
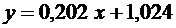 .
.
Таблица 14.2
|
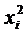 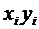
|
|
|
|
|
1,00
|
1,25
|
1,00
|
1,250
|
|
1,50
|
1,40
|
2,25
|
2,100
|
|
3,00
|
1,50
|
9,00
|
4,500
|
|
4,50
|
1,75
|
20,25
|
7,875
|
|
5,00
|
2,25
|
25,00
|
11,250
|
|
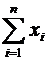 =15 =15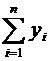 =8,15 =8,15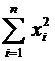 =57,50 =57,50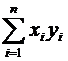 =26,975 =26,975
|
|
|
|
При
большом числе наблюдений одно и тоже значение может
встретится раз, одно и тоже значение - 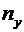 раз,
одна и та же пара чисел
раз,
одна и та же пара чисел 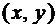 может наблюдаться
может наблюдаться  раз.
Поэтому данные наблюдений следует группировать, для этого подсчитываются
частоты , , . Все сгруппированные данные записываются в виде
таблицы (например, табл. 14.3), которая называется корреляционной.
раз.
Поэтому данные наблюдений следует группировать, для этого подсчитываются
частоты , , . Все сгруппированные данные записываются в виде
таблицы (например, табл. 14.3), которая называется корреляционной.
Таблица 14.3
|
|
|
|
|
10
|
20
|
30
|
40
|
|
|
0,4
|
5
|
-
|
7
|
14
|
26
|
|
0,6
|
-
|
2
|
6
|
4
|
12
|
|
0,8
|
3
|
19
|
-
|
-
|
22
|
|
8211318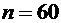
|
|
|
|
|
|
В
первой строке корреляционной таблицы 14.3 указаны наблюдаемые значения (10; 20;
30; 40) признака , а в первом столбце - наблюдаемые значения (0,4; 0,6;
0,8) признака . На пересечении строк и столбцов находятся частоты наблюдаемых пар значений признаков.
В
последнем столбце записаны суммы частот строк, а в последней строке - суммы
частот столбцов. В клетке, расположенной в нижнем правом углу таблицы, помещена
сумма всех частот, т.е. общее число всех наблюдений . Очевидно, что
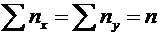 .
.
Теперь
определим параметры выборочного уравнения прямой линии регрессии на в
случае, когда получено большое число данных (практически для удовлетворительной
оценки искомых параметров должно быть хотя бы 50 наблюдений), среди них есть
повторяющиеся, и они сгруппированы в виде корреляционной таблицы.
Из
системы (14.8) можно получить следующую систему:
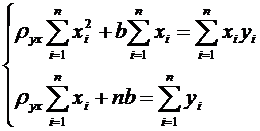 . (14.12)
. (14.12)
Для
простоты приняв обозначения 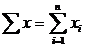 ,
, 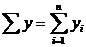 ,
, 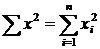 ,
, 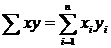 и воспользовавшись соотношениями
и воспользовавшись соотношениями 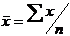 ,
, 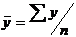 ,
, 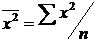 ,
, 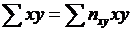 (в
предположении, что пара чисел наблюдалась
раз), из (14.12) получаем
(в
предположении, что пара чисел наблюдалась
раз), из (14.12) получаем
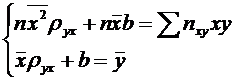 . (14.13)
. (14.13)
Второе
уравнение системы (14.13) преобразуем к виду 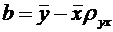 и
подставив правую часть этого равенства в уравнение
и
подставив правую часть этого равенства в уравнение 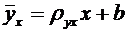 , получим следующее соотношение
, получим следующее соотношение
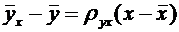 . (14.14)
. (14.14)
Учитывая
соотношения (12.15) и (12.19), найдем из системы (14.13) выборочный коэффициент
регрессии :
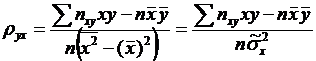 .
.
Умножим
обе части этого равенства на дробь 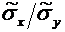 :
:
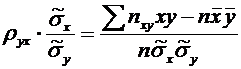 . (14.15)
. (14.15)
Обозначим
правую часть равенства (14.15) через 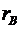 :
:
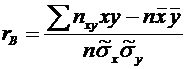 . (14.16)
. (14.16)
Тогда
из (14.15) получаем
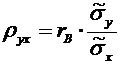 . (14.17)
. (14.17)
Подставив
правую часть этого равенства в (14.14), окончательно получим выборочное
уравнение прямой линии регрессии на вида
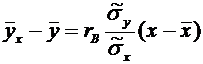 . (14.18)
. (14.18)
Аналогично
можно найти выборочное уравнение прямой линии регрессии на :
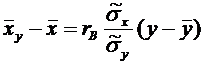 . (14.19)
. (14.19)
Вопросы для повторения и контроля:
1. Что изучают корреляционный и регрессионный анализ, как могут
быть связаны случайные величины, что такое функция случайного аргумента и
функциональная зависимость?
2. Что вы знаете о статистической зависимости и корреляционной
зависимости?
. Что такое условное среднее, выборочное уравнение регрессии,
выборочная регрессия, выборочная линия регрессии, и какие две задачи теории
корреляции вы знаете?
. В каком виде ищется выборочное уравнение прямой линии регрессии
по несгруппированным данным и что такое выборочный коэффициент регрессии?
. В чем суть метода наименьших квадратов и как с его помощью
находится выборочное уравнение прямой линии регрессии?
. Что вы знаете о корреляционной таблице?
. Как находятся параметры выборочного уравнения прямой линии
регрессии по сгруппированным данным?
Опорные слова:
Корреляционный анализ, регрессионный анализ, функция случайного
аргумента, функциональная зависимость, статистическая зависимость,
корреляционная зависимость, условное среднее, выборочное уравнение регрессии,
выборочная регрессия, выборочная линия регрессии, две задачи теории корреляции,
выборочное уравнение прямой линии регрессии по несгруппированным данным,
выборочный коэффициент регрессии, метод наименьших квадратов, корреляционная
таблица, выборочное уравнение прямой линии регрессии по сгруппированным данным.
15. Выборочный коэффициент корреляции и его свойства
Корреляционным
моментом  случайных величин и называется математическое ожидание произведения
отклонений этих величин:
случайных величин и называется математическое ожидание произведения
отклонений этих величин:
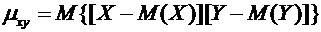 . (15.1)
. (15.1)
Отсюда
легко можно получить соотношение
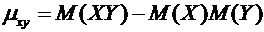 . (15.2)
. (15.2)
Коэффициентом
корреляции 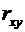 случайных величин и называется отношение корреляционного момента к
произведению средних квадратических отклонений этих величин:
случайных величин и называется отношение корреляционного момента к
произведению средних квадратических отклонений этих величин:
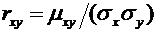 . (15.3)
. (15.3)
Из соотношения (15.2) вытекает, что корреляционный момент и,
следовательно, коэффициент корреляции независимых случайных величин равен нулю.
Две
случайные величины и называются
коррелированными, если их коэффициент корреляции отличен от нуля; и называются
некоррелированными величинами, если их коэффициент корреляции равен нулю.
Из
вышесказанного следует, что независимые случайные величины всегда являются
некоррелированными, а две коррелированные случайные величины также и зависимы.
Действительно, если предположить, что коррелированные случайные величины
независимы, то для них должно выполняться соотношение 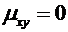 , а это противоречит тому, что для коррелированных
величин всегда выполняется
, а это противоречит тому, что для коррелированных
величин всегда выполняется 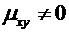 .
.
С
другой стороны, две зависимые случайные величины могут быть как
коррелированными, так и некоррелированными; некоррелированные случайные
величины могут быть как зависимыми, так и независимыми.
Если
случайные величины и независимы,
то коэффициент корреляции  ; если
; если  , то случайные величины и связаны линейной функциональной зависимостью. Отсюда
следует, что коэффициент корреляции измеряет силу (тесноту) линейной связи
между и .
, то случайные величины и связаны линейной функциональной зависимостью. Отсюда
следует, что коэффициент корреляции измеряет силу (тесноту) линейной связи
между и .
Величина
, определяемая равенством
, (15.4)
называется
выборочным коэффициентом корреляции. Здесь и - варианты (наблюдавшиеся значения) признаков и ; - частота пары вариант ; - объем выборки (сумма всех частот); 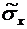 ,
, 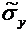 -
выборочные средние квадратические отклонения; ,
-
выборочные средние квадратические отклонения; , 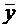 - выборочные средние.
- выборочные средние.
Выборочный
коэффициент корреляции является оценкой коэффициента корреляции генеральной совокупности. Поэтому его можно
использовать и для измерения линейной связи между величинами - количественными
признаками и .
Пример
1. Найти выборочное уравнение прямой линии регрессии на по
данным следующей корреляционной таблицы:
Таблица 15.1
|
|
|
|
|
10
|
20
|
30
|
40
|
50
|
60
|
|
|
15
|
5
|
7
|
-
|
-
|
-
|
-
|
12
|
|
25
|
-
|
20
|
23
|
-
|
-
|
-
|
43
|
|
35
|
-
|
-
|
30
|
47
|
2
|
-
|
79
|
|
45
|
-
|
-
|
10
|
11
|
20
|
6
|
47
|
|
55
|
-
|
-
|
-
|
9
|
7
|
3
|
19
|
|
5276367299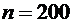
|
|
|
|
|
|
|
|
Решение. Сначала вычислим выборочный коэффициент корреляции по формуле (15.4):
 ;
;
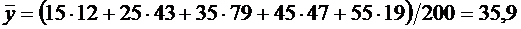 ;
;
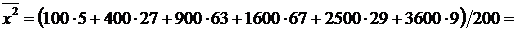
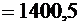 ;
;
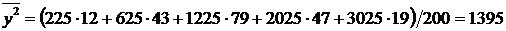 ;
;
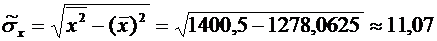 ;
;
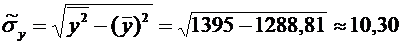 ;
;
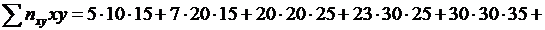
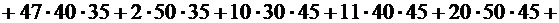
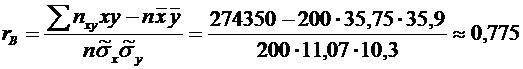 .
.
Теперь
подставим найденные значения в формулу (14.18) и получим выборочное уравнение
прямой линии регрессии на :
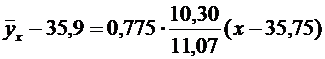
или
окончательно
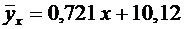 .
.
Если
выборка имеет достаточно большой объем и хорошо представляет генеральную
совокупность (репрезентативна), то заключение о тесноте линейной зависимости между
признаками, полученное по данным выборки, в известной степени может быть
распространено и на генеральную совокупность. Например, для оценки коэффициента корреляции 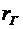 нормально
распределенной генеральной совокупности (при
нормально
распределенной генеральной совокупности (при 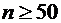 ) можно
воспользоваться формулой
) можно
воспользоваться формулой
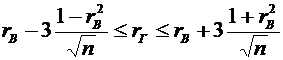 .
.
Итак,
для оценки тесноты линейной корреляционной связи между признаками в выборке
служит выборочный коэффициент корреляции.
Для оценки тесноты нелинейной корреляционной связи вводится понятие выборочного
корреляционного отношения.
Выборочным
корреляционным отношением к называется
следующее отношение
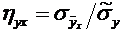 . (15.5)
. (15.5)
Здесь
 ;
;
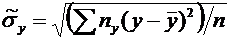 ,
,
де
- объем выборки (сумма всех частот); - частота значения признака
; -
частота значения  признака
признака  ; - общая средняя признака ; -
условная средняя признака .
; - общая средняя признака ; -
условная средняя признака .
Аналогично
определяется выборочное корреляционное отношение к :
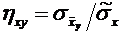 . (15.6)
. (15.6)
Пример
2. Найти  по данным следующей корреляционной таблицы:
по данным следующей корреляционной таблицы:
Таблица 15.2
|
|
|
|
|
10
|
20
|
30
|
|
|
15
|
4
|
28
|
6
|
38
|
|
25
|
6
|
-
|
6
|
12
|
|
102812
|
|
|
|
|
|
211520
|
|
|
|
|
Решение.
Сначала найдем , и 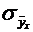 :
:
 ;
;
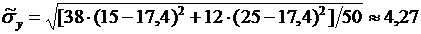 ;
;
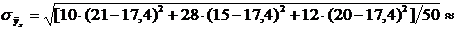
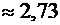 .
.
Теперь
подставим все эти значения в формулу (15.5) и найдем :
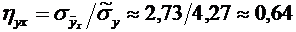 .
.
Перечислим
свойства выборочного корреляционного отношения.
Свойство
15.1. Выборочное корреляционное отношение удовлетворяет двойному неравенству
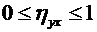 .
.
Свойство
15.2. Если 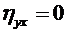 , то признак с
признаком корреляционной зависимостью не связан.
, то признак с
признаком корреляционной зависимостью не связан.
Свойство
15.3. Если 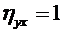 , то признак связан с
признаком функциональной зависимостью.
, то признак связан с
признаком функциональной зависимостью.
Свойство
15.4. Выборочное корреляционное отношение не меньше абсолютной величины
выборочного коэффициента корреляции: 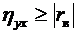 .
.
Свойство
15.5. Если выборочное корреляционное отношение равно абсолютной величине
выборочного коэффициента корреляции, то имеет место точная линейная
корреляционная зависимость.
Вопросы для повторения и контроля:
1. Что называется корреляционным моментом и что называется
коэффициентом корреляции?
2. Что такое коррелированные и некоррелированные случайные величины, и какова связь между
понятиями зависимости и коррелированности случайных величин?
. Что вы знаете о выборочном коэффициенте корреляции?
. Что такое выборочное корреляционное отношение и для чего оно
служит?
. Какие свойства выборочного корреляционного отношения вы знаете?
Опорные слова:
Корреляционный момент, коэффициент корреляции, коррелированные случайные
величины, некоррелированные
случайные величины, выборочный коэффициент корреляции, выборочное
корреляционное отношение.
. Статистические гипотезы и их классификация. Статистический критерий
Пусть требуется определить закон распределения генеральной совокупности и
назовем его А. Если закон распределения неизвестен, но имеются основания
предположить, что он имеет определенный вид, выдвигают гипотезу: генеральная
совокупность распределена по закону А. Таким образом, в этой гипотезе речь идет
о виде предполагаемого распределения.
Возможен
случай, когда закон распределения известен, а его параметры неизвестны. Если
есть основания предположить, что неизвестный параметр  равен определенному значению
равен определенному значению  , то выдвигают гипотезу:
, то выдвигают гипотезу: 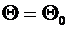 . Таким образом, в этой гипотезе речь идет о
предполагаемой величине параметра одного известного распределения.
. Таким образом, в этой гипотезе речь идет о
предполагаемой величине параметра одного известного распределения.
Статистической
называется гипотеза о виде неизвестного распределения или гипотеза о параметрах
известных распределений. Например, статистическими являются гипотезы:
1) генеральная совокупность распределена по закону Пуассона;
2) дисперсии двух нормальных совокупностей равны между собой.
В первой гипотезе сделано предположение о виде неизвестного
распределения, во второй - о параметрах двух известных распределений.
Нулевой
(основной) называется выдвинутая гипотеза  .
.
Конкурирующей
(альтернативной) называется гипотеза  , которая
противоречит нулевой.
, которая
противоречит нулевой.
Например,
если нулевая гипотеза состоит в предположении, что математическое ожидание нормального распределения равно 10, то конкурирующая
гипотеза может состоять в предположении, что  ; т.е. :
; т.е. :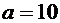 ; :.
; :.
Простой
называется гипотеза, содержащая только одно предположение. Например, гипотеза : математическое ожидание нормального распределения
равно 3 ( известно) - простая.
Сложной
называется гипотеза, которая состоит из конечного или бесконечного числа
простых гипотез. Например, сложная гипотеза  :
: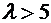 состоит из бесчисленного множества простых гипотез
вида
состоит из бесчисленного множества простых гипотез
вида  :
: , где
, где 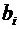 - любое
число, большее 5.
- любое
число, большее 5.
Выдвинутая
гипотеза может быть правильной или неправильной, поэтому возникает
необходимость статистической (производимой статистическими методами) проверки
этой гипотезы. В итоге статистической проверки гипотезы могут быть допущены
ошибки.
Ошибка
первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка
второго рода состоит в том, что будет принята неправильная гипотеза.
Для
проверки нулевой гипотезы используется специально подобранная случайная
величина, точное или приближенное распределение которой известно. Эта случайная
величина обозначается через 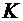 и
называется статистическим критерием (или просто критерием).
и
называется статистическим критерием (или просто критерием).
Приведем
пример статистического критерия. Если проверяется гипотеза о равенстве
дисперсий двух нормальных генеральных совокупностей, то в качестве критерия принимается отношение исправленных выборочных
дисперсий:
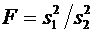 .
.
Наблюдаемым
значением  называется значение критерия, вычисленное по
выборкам. Например, если по двум выборкам найдены исправленные выборочные
дисперсии
называется значение критерия, вычисленное по
выборкам. Например, если по двум выборкам найдены исправленные выборочные
дисперсии 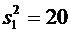 и
и 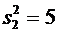 , то
наблюдаемое значение критерия
, то
наблюдаемое значение критерия  равно
равно
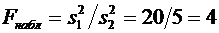 .
.
После
выбора определенного критерия множество всех его возможных значений разбивается
на два непересекающихся подмножества: одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается, а другая - при которых она
принимается.
Критической
областью называется совокупность значений критерия, при которых нулевая
гипотеза отвергается.
Областью
принятия гипотезы (областью допустимых значений) называется совокупность
значений критерия, при которых нулевая гипотеза принимается.
Поскольку
критерий - одномерная случайная величина, все ее возможные
значения принадлежат некоторому интервалу. Поэтому критическая область и
область принятия гипотезы также являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами) 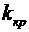 называются точки, отделяющие критическую область от
области принятия гипотезы.
называются точки, отделяющие критическую область от
области принятия гипотезы.
Правосторонней
называется критическая область, определяемая неравенством 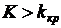 , где -
положительное число (рис. 16.1).
, где -
положительное число (рис. 16.1).

Рис.
16.1.
Левосторонней
называется критическая область, определяемая неравенством 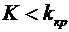 , где -
отрицательное число (рис. 16.2).
, где -
отрицательное число (рис. 16.2).
Рис.
16.2.
Односторонней
называется правосторонняя или левосторонняя критическая область.
Двусторонней
называется критическая область, определяемая неравенствами 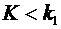 ,
, 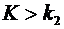 , где
, где 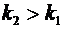 .
.
В
частности, если критические точки симметричны относительно нуля, двусторонняя критическая
область определяется неравенствами (в предположении, что 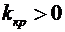 )
) 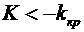 ,
, 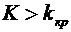 , или равносильным неравенством
, или равносильным неравенством 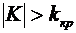 (рис. 16.3).
(рис. 16.3).
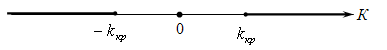
Рис.
16.3.
Для
нахождения критической области достаточно найти критическую точку (точки). Для
нахождения же такой точки задается достаточно малая вероятность - уровень значимости
 . Затем критическая точка ищется исходя из требования, чтобы при условии
справедливости нулевой гипотезы вероятность того, что критерий примет значения из критической области, была равна
принятому уровню значимости.
. Затем критическая точка ищется исходя из требования, чтобы при условии
справедливости нулевой гипотезы вероятность того, что критерий примет значения из критической области, была равна
принятому уровню значимости.
Например,
для правосторонней критической области должно выполняться соотношение
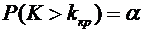 , (16.1)
, (16.1)
для
левосторонней -
 , (16.2)
, (16.2)
а
для двусторонней -
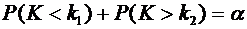 . (16.3)
. (16.3)
Для
каждого критерия имеются соответствующие таблицы, по которым и находится
критическая точка, удовлетворяющая требованиям вида (16.1) - (16.3).
Если
распределение критерия симметрично относительно нуля и имеются основания
выбрать симметричные относительно нуля точки 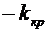 и (), то
и (), то 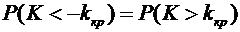 . Учитывая это соотношение, из (16.3) для двусторонней
критической области получим соотношение
. Учитывая это соотношение, из (16.3) для двусторонней
критической области получим соотношение
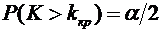 . (16.4)
. (16.4)
Мощностью
критерия называется вероятность попадания критерия в критическую область при
условии, что справедлива конкурирующая гипотеза. Другими словами, мощность
критерия есть вероятность того, что нулевая гипотеза будет отвергнута, если
верна конкурирующая гипотеза.
Пусть
для проверки гипотезы принят определенный уровень значимости, и выборка имеет
фиксированный объем. Если  - вероятность ошибки второго рода, т.е. события
"принята нулевая гипотеза, причем справедлива конкурирующая", то
мощность критерия равна
- вероятность ошибки второго рода, т.е. события
"принята нулевая гипотеза, причем справедлива конкурирующая", то
мощность критерия равна  .
.
Пусть
мощность возрастает; следовательно, уменьшается вероятность совершить ошибку второго рода. Таким образом, чем
мощность больше, тем меньше вероятность ошибки второго рода.
Итак,
если уровень значимости уже выбран, то критическую область следует строить так,
чтобы мощность критерия была максимальной. Это позволит минимизировать ошибку
второго рода.
Далее
нам потребуется распределение Фишера -
Снедекора.
Если
 и -
независимые случайные величины, распределенные по закону со степенями свободы и
и -
независимые случайные величины, распределенные по закону со степенями свободы и 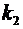 , то величина
, то величина
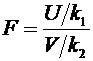 (16.5)
(16.5)
имеет
распределение, которое называется
распределением Фишера - Снедекора со степенями свободы и .
Функция
плотности этого распределения имеет вид
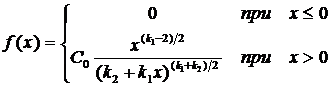 ,
,
Где
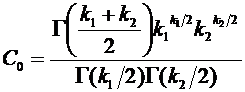 .
.
Распределение
определяется двумя параметрами - числами степеней
свободы и .
Пусть
генеральные совокупности и распределены
нормально. По независимым выборкам с объемами, соответственно равными и ,
извлеченным из этих совокупностей, найдены исправленные выборочные дисперсии 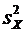 и
и 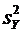 . Требуется
по исправленным дисперсиям при заданном уровне значимости проверить нулевую гипотезу, состоящую в том, что
генеральные дисперсии рассматриваемых совокупностей равны между собой:
. Требуется
по исправленным дисперсиям при заданном уровне значимости проверить нулевую гипотезу, состоящую в том, что
генеральные дисперсии рассматриваемых совокупностей равны между собой:
: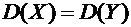 . (16.6)
. (16.6)
Учитывая,
что исправленные дисперсии являются несмещенными оценками генеральных
дисперсий, т.е.
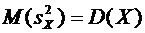 ,
, 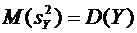 ,
,
нулевую
гипотезу можно записать так:
: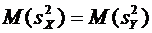 . (16.7)
. (16.7)
На
практике задача сравнения дисперсий возникает, если требуется сравнить точность
приборов, инструментов, самих методов измерений и т.д. Очевидно,
предпочтительнее тот прибор, инструмент и метод, который обеспечивает
наименьшее рассеяние результатов измерений, т.е. наименьшую дисперсию.
В
качестве критерия проверки нулевой гипотезы о равенстве генеральных дисперсий
принимается отношение большей исправленной дисперсии к меньшей, т.е. случайная
величина
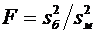 . (16.8)
. (16.8)
Величина
при условии справедливости нулевой гипотезы имеет
распределение Фишера - Снедекора со степенями свободы 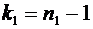 и
и 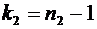 , где - объем выборки, по которой вычислена большая
исправленная дисперсия, - объем выборки, по которой найдена меньшая
исправленная дисперсия.
, где - объем выборки, по которой вычислена большая
исправленная дисперсия, - объем выборки, по которой найдена меньшая
исправленная дисперсия.
Критическая
область строится в зависимости от вида конкурирующей гипотезы.
Первый
случай. Нулевая гипотеза :. Конкурирующая гипотеза :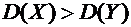 .
.
В
этом случае строится правосторонняя критическая область, исходя из требования,
чтобы вероятность попадания критерия в эту
область в предположении справедливости нулевой гипотезы была равна принятому
уровню значимости:
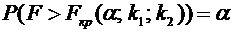 . (16.9)
. (16.9)
Критическая
точка 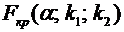 находится по таблице критических точек распределения
Фишера - Снедекора.
находится по таблице критических точек распределения
Фишера - Снедекора.
Правило
1. Для того чтобы при заданном уровне значимости проверить нулевую гипотезу : о равенстве генеральных дисперсий нормальных совокупностей
при конкурирующей гипотезе :, надо вычислить отношение большей исправленной
дисперсии к меньшей, т.е.
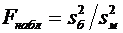 , (16.10)
, (16.10)
и
по таблице критических точек распределения Фишера - Снедекора, по заданному
уровню значимости и числам степеней свободы и ( - число степеней свободы большей исправленной
дисперсии) найти критическую точку .
Если
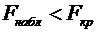 - нет оснований отвергнуть нулевую гипотезу. Если
- нет оснований отвергнуть нулевую гипотезу. Если 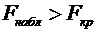 - нулевая гипотеза отвергается.
- нулевая гипотеза отвергается.
Пример
1. По двум независимым выборкам объемов 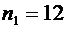 и
и 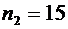 , извлеченным из нормальных генеральных совокупностей и , найдены
исправленные выборочные дисперсии
, извлеченным из нормальных генеральных совокупностей и , найдены
исправленные выборочные дисперсии 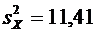 и
и  . При уровне значимости 0,05 проверить нулевую
гипотезу : о равенстве генеральных дисперсий при конкурирующей
гипотезе :
. При уровне значимости 0,05 проверить нулевую
гипотезу : о равенстве генеральных дисперсий при конкурирующей
гипотезе :
Решение.
Найдем отношение большей исправленной дисперсии к меньшей:
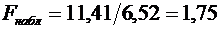 .
.
Конкурирующая
гипотеза имеет вид , поэтому критическая область - правосторонняя.
По
таблице критических точек распределения
Фишера - Снедекора, по уровню значимости 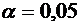 и числам
степеней свободы
и числам
степеней свободы 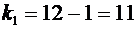 и
и 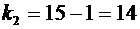 находим
критическую точку
находим
критическую точку 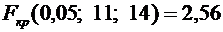 .
.
Так
как , то нет оснований отвергнуть нулевую гипотезу о
равенстве генеральных дисперсий.
Второй
случай. Нулевая гипотеза :. Конкурирующая гипотеза :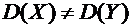 .
.
В
этом случае строится двусторонняя критическая область, исходя из требования,
чтобы вероятность попадания критерия в эту
область в предположении справедливости нулевой гипотезы была равна принятому
уровню значимости .
Наибольшая
мощность критерия (вероятность попадания критерия в критическую область при
справедливости конкурирующей гипотезы) достигается тогда, когда вероятность
попадания критерия в каждый из двух интервалов критической области равна  .
.
Если
обозначить через  левую границу критической области и через
левую границу критической области и через 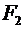 - правую, то должны иметь место соотношения:
- правую, то должны иметь место соотношения:
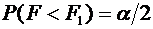 ,
, 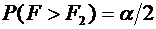 . (16.11)
. (16.11)
Для
обеспечения попадания критерия в
двустороннюю критическую область с вероятностью, равной принятому уровню
значимости , в случае конкурирующей гипотезы : достаточно найти критическую точку
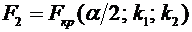 .
.
Правило
2. Для того чтобы при заданном уровне значимости проверить нулевую гипотезу : о равенстве генеральных дисперсий нормальных
совокупностей при конкурирующей гипотезе :, надо вычислить отношение большей исправленной
дисперсии к меньшей, т.е. (16.10) и по таблице критических точек распределения
Фишера - Снедекора, по заданному уровню значимости (вдвое меньшем заданного) и числам степеней свободы и ( - число степеней свободы большей исправленной
дисперсии) найти критическую точку  .
.
Если
- нет оснований отвергнуть нулевую гипотезу. Если - нулевая гипотеза отвергается.
Пример
2. По двум независимым выборкам объемов  и
и 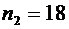 , извлеченным из нормальных генеральных совокупностей и , найдены
исправленные выборочные дисперсии
, извлеченным из нормальных генеральных совокупностей и , найдены
исправленные выборочные дисперсии 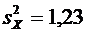 и
и 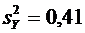 . При уровне значимости 0,1 проверить нулевую гипотезу
: о равенстве генеральных дисперсий при конкурирующей
гипотезе :
. При уровне значимости 0,1 проверить нулевую гипотезу
: о равенстве генеральных дисперсий при конкурирующей
гипотезе :
Решение.
Найдем отношение большей исправленной дисперсии к меньшей:
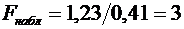 .
.
Конкурирующая
гипотеза имеет вид , поэтому критическая область - двусторонняя.
По
таблице критических точек распределения
Фишера - Снедекора, по уровню значимости, вдвое меньшем заданного, т.е. при 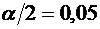 и числам степеней свободы
и числам степеней свободы 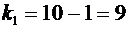 и
и 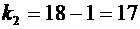 находим
критическую точку
находим
критическую точку
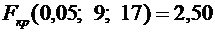 .
.
Так
как , нулевая гипотеза о равенстве генеральных дисперсий
отвергается.
Пусть
генеральные совокупности и распределены
нормально, причем их дисперсии известны. По независимым выборкам с объемами,
соответственно равными и 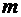 , извлеченным
из этих совокупностей, найдены выборочные средние и .
Требуется по выборочным средним при заданном уровне значимости проверить нулевую гипотезу, состоящую в том, что
генеральные средние (математические ожидания) рассматриваемых совокупностей
равны между собой:
, извлеченным
из этих совокупностей, найдены выборочные средние и .
Требуется по выборочным средним при заданном уровне значимости проверить нулевую гипотезу, состоящую в том, что
генеральные средние (математические ожидания) рассматриваемых совокупностей
равны между собой:
: . (16.12)
. (16.12)
Учитывая,
что выборочные средние являются несмещенными оценками генеральных средних, т.е.
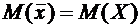 ,
, 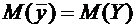 ,
,
нулевую
гипотезу можно записать так:
: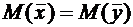 . (16.13)
. (16.13)
В
качестве критерия проверки нулевой гипотезы о равенстве генеральных средних
принимается нормированная нормальная случайная величина
 . (16.14)
. (16.14)
Критическая
область строится в зависимости от вида конкурирующей гипотезы.
Первый
случай. Нулевая гипотеза :. Конкурирующая гипотеза :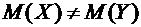 .
.
В
этом случае строится двусторонняя критическая область, исходя из требования,
чтобы вероятность попадания критерия в эту
область в предположении справедливости нулевой гипотезы была равна принятому
уровню значимости .
Поскольку
распределение симметрично относительно нуля, то критические точки
симметричны относительно нуля, т.е. если обозначить через 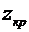 правую критическую точку, то
правую критическую точку, то 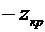 будет левой критической точкой.
будет левой критической точкой.
Наибольшая
мощность критерия (вероятность попадания критерия в критическую область при
справедливости конкурирующей гипотезы) достигается тогда, когда вероятность
попадания критерия в каждый из двух интервалов критической области равна :
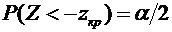 ,
, 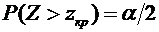 . (16.15)
. (16.15)
Для
того, чтобы найти правую границу двусторонней критической области, достаточно найти
значение аргумента функции Лапласа, которому соответствует значение функции,
равное 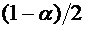 :
:
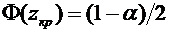 . (16.16)
. (16.16)
Обозначим
значение критерия, вычисленное по данным наблюдений, через 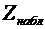 .
.
Если
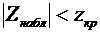 - нет оснований отвергнуть нулевую гипотезу.
- нет оснований отвергнуть нулевую гипотезу.
Если
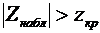 - нулевая гипотеза отвергается.
- нулевая гипотеза отвергается.
Второй
случай. Нулевая гипотеза :. Конкурирующая гипотеза :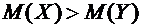 .
.
В
этом случае строится правосторонняя критическая область, исходя из требования,
чтобы вероятность попадания критерия в эту
область в предположении справедливости нулевой гипотезы была равна принятому
уровню значимости:
 . (16.17)
. (16.17)
Для
того, чтобы найти границу правосторонней
критической области, достаточно найти значение аргумента функции Лапласа,
которому соответствует значение функции, равное 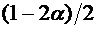 :
:
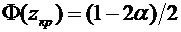 . (16.18)
. (16.18)
Обозначим
значение критерия, вычисленное по данным наблюдений, через .
Если
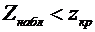 - нет оснований отвергнуть нулевую гипотезу.
- нет оснований отвергнуть нулевую гипотезу.
Если
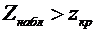 - нулевая гипотеза отвергается.
- нулевая гипотеза отвергается.
Вопросы для повторения и контроля:
1. Что вы понимаете под статистической гипотезой? Приведите
примеры.
2. Что такое нулевая (основная), конкурирующая (альтернативная),
простая, сложная гипотезы?
. В чем состоят ошибки первого и второго рода, что называется
статистическим критерием?
4. Что называется наблюдаемым значением критерия, критической
областью, областью принятия гипотезы (областью допустимых значений)?
5. Что такое критические точки (границы), правосторонняя,
левосторонняя, односторонняя, двусторонняя критическая области?
. Что называется уровнем значимости и как находится критическая
область?
. Что такое мощность критерия и как она связана с ошибкой второго
рода?
. Что вы знаете о распределении Фишера - Снедекора?
. Как сравниваются две дисперсии нормальных генеральных
совокупностей в первом случае?
. Как сравниваются две дисперсии нормальных генеральных
совокупностей в втором случае?
. Как сравниваются два средних нормальных генеральных
совокупностей в первом случае?
. Как сравниваются два средних нормальных генеральных
совокупностей в втором случае?
Опорные слова:
Статистическая гипотеза, нулевая (основная) гипотеза, конкурирующая
(альтернативная) гипотеза, простая гипотеза, сложная гипотеза, ошибка первого
рода, ошибка второго рода, статистический критерий, наблюдаемое значение
критерия, критическая область, область принятия гипотезы (область допустимых
значений), критические точки (границы), правосторонняя критическая область,
левосторонняя критическая область, односторонняя критическая область,
двусторонняя критическая область, уровень значимости, мощность критерия,
распределение Фишера - Снедекора, степени свободы.
17. Критерии согласия
Если закон распределения генеральной совокупности неизвестен, но есть
основания предположить, что он имеет определенный вид (назовем его А), то
проверяется нулевая гипотеза: генеральная совокупность распределена по закону
А.
Проверка гипотезы о предполагаемом законе неизвестного распределения
производится так же, как и проверка гипотезы о параметрах распределения, т.е.
при помощи специально подобранной случайной величины - критерия согласия.
Критерием согласия называется критерий проверки гипотезы о предполагаемом
законе неизвестного распределения.
Одним
из критериев согласия является критерий ("хи
квадрат") К.Пирсона проверки гипотезы о нормальном распределении
генеральной совокупности (этот критерий можно применять и для других распределений).
Для применения этого критерия будем сравнивать эмпирические (наблюдаемые) и
теоретические (вычисленные в предположении нормального распределения) частоты.
Обычно
эмпирические и теоретические частоты различаются. Например:
|
эмп. частоты . . . . .
|
6
|
13
|
38
|
74
|
106
|
85
|
30
|
10
|
4
|
|
теорет. частоты . .
|
3
|
14
|
42
|
82
|
99
|
76
|
37
|
11
|
2
|
Расхождение эмпирических и теоретических частот может быть случайным
(незначимым) и объясняется либо малым числом наблюдений, либо способом их
группировки, либо другими причинами. С другой стороны, расхождение частот может
быть неслучайным (значимым) и объясняется тем, что теоретические частоты
вычислены исходя из неверной гипотезы о нормальном распределении генеральной
совокупности.
Критерий Пирсона отвечает на вопрос: случайно ли расхождение эмпирических
и теоретических частот? Правда, как и любой критерий, он не доказывает
справедливость гипотезы, а лишь устанавливает на принятом уровне значимости ее
согласие или несогласие с данными наблюдений.
Пусть
по выборке объема получено эмпирическое распределение:
Допустим,
что в предположении нормального распределения генеральной совокупности
вычислены теоретические частоты  . При
уровне значимости требуется проверить нулевую гипотезу: генеральная
совокупность распределена нормально.
. При
уровне значимости требуется проверить нулевую гипотезу: генеральная
совокупность распределена нормально.
В
качестве критерия проверки нулевой гипотезы принимается случайная величина
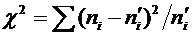 . (17.1)
. (17.1)
Эта
величина случайная, так как в различных опытах она принимает различные, заранее
не известные значения. Ясно, что чем меньше различаются эмпирические и
теоретические частоты, тем меньше величина критерия (17.1), и, следовательно,
он в известной степени характеризует близость эмпирического и теоретического
распределений.
При
закон распределения случайной величины (17.1)
независимо от того, какому закону распределения подчинена генеральная
совокупность, стремится к закону распределения с степенями свободы.
Число
степеней свободы находится по равенству 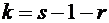 , где - число групп (частичных интервалов) выборки;
, где - число групп (частичных интервалов) выборки; 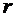 - число параметров предполагаемого распределения,
которые оценены по данным выборки.
- число параметров предполагаемого распределения,
которые оценены по данным выборки.
В
частности, если предполагаемое распределение - нормальное, то оцениваются два
параметра (математическое ожидание и среднее квадратическое отклонение),
поэтому 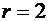 и число степеней свободы
и число степеней свободы
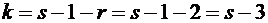 .
.
Если
же предполагается, что генеральная совокупность распределена по закону
Пуассона, то оценивается один параметр , поэтому
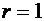 и
и 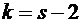 .
.
Построим
правостороннюю критическую область, исходя из требования, чтобы вероятность
попадания критерия в эту область в предположении справедливости нулевой
гипотезы была равна принятому уровню значимости:
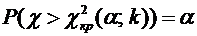 . (17.2)
. (17.2)
Таким
образом, правосторонняя критическая область определяется неравенством 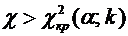 , а область принятия нулевой гипотезы - неравенством
, а область принятия нулевой гипотезы - неравенством 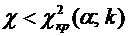 .
.
Правило.
Для того чтобы при заданном уровне значимости проверить нулевую гипотезу : генеральная совокупность распределена нормально,
надо сначала вычислить теоретические частоты, а затем наблюдаемое значение
критерия
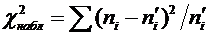 (17.3)
(17.3)
и
по таблице критических точек распределения , по заданному
уровню значимости и числу степеней свободы 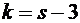 найти критическую точку
найти критическую точку 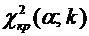 .
.
Если
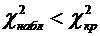 - нет оснований отвергнуть нулевую гипотезу. Если
- нет оснований отвергнуть нулевую гипотезу. Если 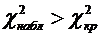 - нулевая гипотеза отвергается.
- нулевая гипотеза отвергается.
Сущность
критерия согласия Пирсона состоит в сравнении эмпирических и теоретических
частот. Ясно, что эмпирические частоты находятся из опыта. Как найти
теоретические частоты, если предполагается, что генеральная совокупность
распределена нормально? Эту задачу, например, можно решить следующим способом.
.
Весь интервал наблюдаемых значений (выборки
объема ) делится на частичных
интервалов 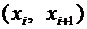 одинаковой длины. Затем находятся середины частичных
интервалов
одинаковой длины. Затем находятся середины частичных
интервалов 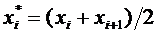 ; в качестве частоты варианты
; в качестве частоты варианты
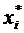 принимается число вариант, которые попали в i-й
интервал. В итоге получается последовательность равноотстоящих вариант и
соответствующих им частот:
принимается число вариант, которые попали в i-й
интервал. В итоге получается последовательность равноотстоящих вариант и
соответствующих им частот:
При
этом .
.
Вычисляются выборочная средняя 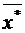 и
выборочное среднее квадратическое отклонение
и
выборочное среднее квадратическое отклонение  .
.
.
Нормируется случайная величина , т.е.
переходят к величине 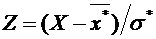 и вычисляются концы интервалов
и вычисляются концы интервалов  :
:
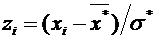 ,
, 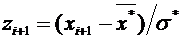 ,
,
причем
наименьшее значение , т.е. 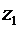 ,
полагают равным , а наибольшее, т.е.
,
полагают равным , а наибольшее, т.е. 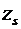 ,
полагают равным .
,
полагают равным .
.
Вычисляются теоретические вероятности попадания
в интервалы по
равенству ( - функция Лапласа)
- функция Лапласа)
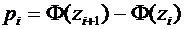
и,
наконец, находятся искомые теоретические частоты 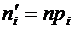 .
.
Вопросы для повторения и контроля:
1. Что называется критерием согласия и как применяется критерий
Пирсона?
2. По каким причинам различаются эмпирические и теоретические
частоты?
. Какая случайная величина принимается в качестве критерия
проверки нулевой гипотезы о нормальном распределении генеральной совокупности и
какие ее свойства вы знаете?
. В чем суть правила проверки нулевой гипотезы о нормальном
распределении генеральной совокупности?
. Каким способом находятся теоретические частоты?
Опорные слова:
Критерий согласия, критерий Пирсона, эмпирическая частота, теоретическая
частота, правило проверки нулевой гипотезы о нормальном распределении
генеральной совокупности.
Список
литературы
1. Адиров
Т.Т., Мамуров Э.Н. Эћтимоллар назарияси ва математик статистикадан маърузалар
матни. Т.: ТМИ, 2001 й.
2. Г.М.
Булдык. Теория вероятностей и математическая статистика. М.: Наука, 1989 г.
3. Венецкий
И.Г., Венецкая В.И. Основные математико-статистические понятия и формулы в
экономическом анализе. М.: "Высшая школа", 1987 г.
. Гмурман
В.Е. Теория вероятностей и математическая статистика. Издание шестое. М.:
"Высшая школа", 1998 г.
. Гмурман
В.Е. Эћтимоллар назарияси ва математик статистика. Русча тўлдирилган 4-нашридан
тарж. Инж.-экон. институтлари студентлари учун ўќув ќўлланма. Т.: Ўќитувчи,
1977 й.
6. В.Е.
Гмурман. Руководство к решению задач по теории вероятностей и математической
статистике: учеб. пособие для втузов. 3-е изд., перераб. и доп. М.:
"Высшая школа", 1979 г.
7. Гмурман
В.Е. Эћтимоллар назарияси ва математик статистикадан масалалар ечишга доир
ќўлланма. Русча тўлдирилган 2-нашридан таржима. Т.: Ўќитувчи, 1980 й.
. Замков
О.О., Толстопятенко А.В., Черемных Ю.Н. Математические методы в экономике. М.:
Изд. ДИС, 1998 г.
. Колемаев
В.А., Калинина В.А. Теория вероятностей и математическая статистика. М.:
Инфра-М, 1997 г.
. Колемаев
В.А., О.В.Староверов, В.Б.Турундаевский. Теория вероятностей и математическая
статистика: учеб. пособие для экон. спец. вузов. М.: "Высшая школа",
1991 г.
. Кремер
Ш.А. Теория вероятностей и математическая статистика. М.: "Высшая
школа", 2001 г.
12. Мамуров
Э.Н., Адиров Т.Ћ Эћтимоллар назарияси ва математик статистикадан масалалар
ечишга доир ќўлланма. Т.: ТМИ, 2000 й.
13. Соатов
Ё.У. Олий математика курси. 2-ќисм. Т.: Ўќитувчи, 1994 й.
. Справочник
по математике для экономистов. / Под редакцией проф. Ермакова. М.: "Высшая
школа", 1987 г.