Зависимость численности занятого населения от различных социально-экономических факторов в различных субъектах Российской Федерации
Всероссийская академия внешней
торговли
Факультет экономистов-международников
Кафедра информатики и математики
Предметно-аналитическая справка
по эконометрике
Тема:
Зависимость численности занятого
населения от различных социально-экономических факторов в различных субъектах
Российской Федерации
Москва - 2016
Оглавление
Введение
. Тест на
мультиколлинеарность Фаррара-Глобера
. Диаграммы
рассеивания
. Исходные
данные. Оценка значимости исходных данных
. Тест
Длинная - Короткая
. Тест Чоу
. Тесты на
гетероскедастичность
. Тест
Гольдфельда-Куандта
. Тест
Бреуша-Пагана
. Тест Уайта
. Тест
Дарбина-Уотсона
Заключение
Список
использованной литературы
Введение
В работе проводится исследование зависимости численности занятого
населения от различных социально-экономических факторов в различных субъектах
Российской Федерации.
В данной работе использовано 56 наблюдений - 56 субъектов РФ. Данные
используются за 2013 год. Одно наблюдение соответствует одному конкретному
субъекту Российской Федерации. Целью исследования в курсовой работе - построение
модели для анализа зависимости между объясняемой переменной Y - численностью занятого населения
(тыс. человек.) за 2013 год и объясняющих переменных:
Y = β0 + β1X1 + β2X2 + β3X3 + β4X4+ β5X5 + β6X6 + β7X7+ β8X8 +
+ β9X9 + β10X10 + β11X11 + β12X12+ εi ,
Где Х1 - численность безработных (тыс. человек)
Х2 - валовой региональный продукт (млн. рублей)
Х3 - среднедушевые денежные доходы (руб.)
Х4 - число организаций, выполняющие научные исследования и разработки
(ед.)
Х5 - численность городов (ед.)
Х6 - численность работников государственных органов и органов местного
самоуправления (чел.)
Х7 - оборот средних организаций (млрд. рублей.)
Х8 - количество предприятий, имеющих иностранное участие (ед.)
Х9 - индекс промышленного производства (в % к предыдущему году)
Х10 - объем отгруженных товаров собственного производства, выполненных
работ и услуг собственными силами (млн. рублей)
Х11 - число квартирных телефонных аппаратов сети общего пользования (шт.
на 1000человек населения)
Х12 - охват населения телевизионным и радио вещанием (в % от общего
количества).
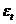 - случайная компонента
- случайная компонента
Данные, используемые в предметно-аналитической справке, взяты с сайта
Федеральная служба государственной статистики.
1. Тест на
мультиколлинеарность Фаррара-Глобера
Одним из условий теоремы Гаусса-Маркова для множественной регрессии
является независимость объясняющих переменных. Только в этом случае оценки
коэффициентов регрессии, полученные по методу наименьших квадратов являются
эффективными, несмещенными и состоятельными. Для проверки данных на наличие
мультиколлинеарности используется тест Фаррара - Глобера. Для начала строится
матрица парных коэффициентов корреляции, причем их значение по модулю не должно
превышать 0,7. Коэффициент по модулю больше 0,7 может вызвать
мультиколлинеарность, которая в свою очередь может привести к неправильной
оценке регрессии, а именно,
. Оценки коэффициентов регрессии по МНК, оставаясь несмещенными, имеют
большие стандартные ошибки
2. Вычисленные t-статистики
могут оказаться заниженными (коэффициенты незначимыми). При этом модель может
быть в целом значима по F-
критерию.
. Оценки становятся очень чувствительными к изменению исходных
данных.
. Оценки некоторых коэффициентов могут иметь «неправильные» знаки
и «неоправданно большие» значения.
Построим матрицу парных коэффициентов корреляции для всех 12 факторов.

Т.к. FGнабл (760) > FGкр (73) (более чем в 10 раз), то гипотеза Н0
отклоняется, факторы мультиколлинеарны. Для дальнейшего анализа модели
необходимо попытаться избавиться от мультиколлиниарности. Мы можем заметить,
что наиболее всего на мультиколлинеарность оказывают влияние факторы x2, х4,
х6, х7, х8. (коэффициенты по модулю больше 0,7). Проведем новый тест
Фаррара-Глобера без учета этих факторов.

Т.к FGнабл (79) > FGкр (33), гипотеза Н0 по-прежнему отклоняется,
факторы мультиколлинеарны, но т.к. Fнабл больше Fкр не более чем в 3 раза, то с
такой моделью работать можно. В дальнейшем в анализе будут участвовать только
данные факторы, которые не влияют на мультиколлинеарность.
матрица корреляция занятый социальный экономический
2.2
Диаграммы рассеивания
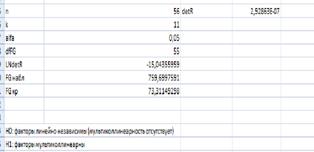
Зависимость условно линейная, вероятно гетероскедастична

Зависимость условно линейная, вероятно гетероскедастична
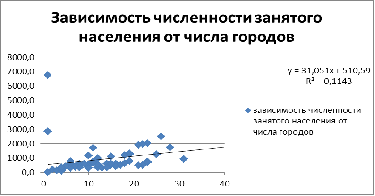
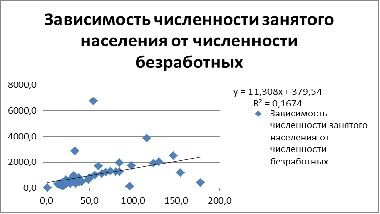
Зависимость условно-линейная, вероятно гомоскедастична. Возможно
присутствие 2 точек выброса - т.е. города федерального значения. Они являются
отдельными субъектами РФ. (Москва, Санкт-Петербург).
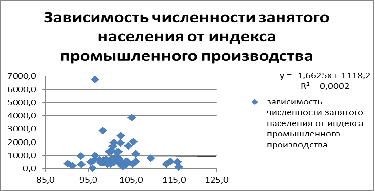
Зависимость условно линейная, вероятно гетероскедастична
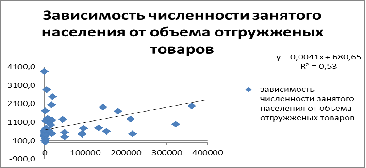
Зависимость условно линейная, вероятно гетероскедастична
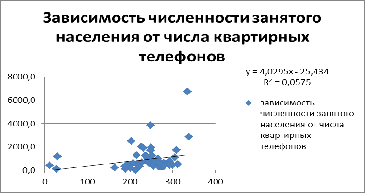
Зависимость условно линейная, вероятно гетероскедастична

Зависимость условно линейная, вероятно гетероскедастична.
2.3
Исходные данные. Оценка значимости исходных данных
Y -
численность занятого населения (тыс. человек.) за 2013 год
Х1 - численность безработных (тыс. человек)
Х2 - валовой региональный продукт ( млн. рублей)
Х3 - среднедушевые денежные доходы (руб.)
Х4 - число организаций, выполняющие научные исследования и разработки
(ед.)
Х5 - численность городов (ед.)
Х6 - численность работников государственных органов и органов местного
самоуправления (чел.)
Х7 - оборот средних организаций (млрд. рублей.)
Х8 - количество предприятий, имеющих иностранное участие (ед.)
Х9 - индекс промышленного производства (в % к предыдущему году.)
Х10 - объем отгруженных товаров собственного производства, выполненных
работ и услуг собственными силами (млн. рублей.)
Х12 - охват населения телевизионным и радио вещанием (в % от общего
количества).
1) Теоретическое уравнение регрессии:
Y = β0 + β1X1 + β2X2+ β3X3+ β4X4+ β5X5+ β6X6+ β7X7+ β8X8 + β9X9+
+ β10X10 + β11X11 + β12X12+ εi
2) Выборочное уравнение регрессии:
y^i= -1693,299+ 11,64*x1 + 0,01467 * x3 + 19,199336 * x5 + 0,902 * х9 +
+ 0,00341 * х10 + 4,47385 * х11 + 1,01877 * х12
3) Коэффициент детерминации: Примерно 80% вариации зависимой переменной У
объясняется вариациями независимых переменных Х, входящих в модель. Остальные
20% влияние неучтенных случайных факторов. Т.к R^2 равен 80%, то в данном случае модель является моделью
высокой точности.
4) Значимость модели в целом
В ходе проведения исследования на значимость модели в целом был
использован 1 метод проверки модели на значимость. Он подтвердил значимость
модели, следовательно, данную модель можно использовать

5) Значимость коэффициентов
Для выявления значимых коэффициентов было использован метод - сравнения P-value с заданным уровнем значимости alpha (в данном случае он равен 0,05).
Если P-value будет меньше уровня значимости - коэффициент значим,
иначе - незначим.

Данный метод показал, что для данной модели значимыми являются:
Х1 - численность безработных (тыс. человек)
Х5 - численность городов (ед.)
Х10 - объем отгруженных товаров собственного производства, выполненных работ
и услуг собственными силами (млн. рублей.)
Х11 - число квартирных телефонных аппаратов сети общего пользования (шт.
на 1000 человек населения).
Коэффициенты Х3, Х9, Х12 являются незначимыми. С экономической точки
зрения можно сделать вывод, что они в меньшей степени влияют на численность
занятого населения.
Для простоты обозначения факторов модели, считаю необходимым изменить
нумерацию факторов, которые в связи с тем, что они оказывают влияние на
мультиколлинеарность не участвуют в дальнейшем анализе, (факторы х2, х4, х6,
х7, х8). Новая нумерация факторов:
Х1 - численность безработных (тыс. человек)
Х2 - среднедушевые денежные доходы (руб.)
Х3 - численность городов (ед.)
Х4 - индекс промышленного производства (в % к предыдущему году.)
Х5 - объем отгруженных товаров собственного производства, выполненных
работ и услуг собственными силами (млн.рублей.)
Х6 -число квартирных телефонных аппаратов сети общего пользования (шт. на
1000 человек населения.)
Х7 - охват населения телевизионным и радио вещанием (в % от общего
количества).
2.4 Тест
Длинная - Короткая
В данной модели есть незначимые факторы. Исключив их, можно сравнить две
модели - «длинную» и «короткую», а затем выбрать лучшую для последующих
расчетов.
Для того, чтобы выбрать наилучшую модель мы должны сравнить значения
коэффициента детерминации R2
и выбрать
наибольшее. R2 длинной равен 0,800, а R2 короткой 0,791. Несмотря на то, что первое больше, показатели
не сильно различаются, поэтому переходим к выполнению другого способа сравнения
- тест по критерию Фишера.
Формируются гипотезы
Но:β2 = β4 = β7 = 0 (можно использовать короткую
модель)
Н1:β2 ≠ β4 ≠ β7 ≠ 0 (нужно использовать
длинную модель)

Согласно результатам можно сделать вывод: можно использовать как длинную,
так и короткую модель. В дальнейшем в анализе будем использоваться короткую
модель.
.5 Тест
Чоу
Часто исходные данные могут быть неоднородными. Для разных групп
наблюдений может быть неодинаковые форма и характер зависимости. Может
получиться так, что модель будет точнее, если взять несколько моделей, в
которые входят содержательно различные наблюдения. Для проверки однородности
объясняемой переменной и объясняющих переменных используем тест Чоу. Для этого
разобьём всю подвыборку на 2 отдельные в зависимости от численности безработных
(У). Первая включает в себя области с численность менее 35 тыс. безработных на
субъект , а вторая - более 35тыс. безработных на субъект. Гипотезы в данном
тесте будут такими.
Н0: нужно использовать одну общую модель
Н1: нужно использовать две разные модели
Н0: βi = γi: βi ≠ γi

По результатам теста получили Fст < Fкр, гипотеза Н0 принимается,
следовательно нужно использовать одну общую модель.
.6 Тесты
на гетероскедастичность
Гомоскедастичность, т.е. независимость дисперсии случайных возмущений от
значений объясняющих переменных модели является одним из условий теоремы
Гаусса-Маркова. Гетероскедастичность - дисперсия объясняемой переменной
непостоянна, зависимость от значений объясняющих переменных.
.7 Тест
Гольдфельда-Куандта
Этот тест проверяет, зависит ли дисперсия случайных возмущений от
«подозреваемого» Х, входящего в модель. Для того, чтобы определить показатель,
“подозреваемый” в гетероскедастичности, т.е. ту объясняющую переменную, от
которой может зависеть дисперсия случайных возмущений, нужно визуально
определить это на графике. В качестве «подозреваемых» выбираем Х1. По
результатам теста приходим к выводу, что дисперсия случайных возмущений зависит
от Х1, т.е. модель гетероскедастична.

Наличие гетероскедастичности случайных ошибок приводит к неэффективности
оценок, полученных с помощью метода наименьших квадратов. Кроме того, в этом
случае оказывается смещённой и несостоятельной классическая оценка
ковариационной матрицы МНК-оценок параметров. Следовательно, статистические
выводы о качестве полученных оценок могут быть неадекватными.
В связи с тем, что в цели моей работы не входило «избавление от
гетероскедастичности», то было решено продолжить анализ, оставив
гетероскедастичность. Но существуют различные способы, которые могут позволить
избавиться от нее, такие как:
· Использование взвешенного метода наименьших квадратов
· Замена исходных данных их производными, например,
логарифмом, относительным изменением или другой нелинейной функцией. Этот
подход часто используется в случае увеличения дисперсии ошибки с ростом
значения независимой переменной и приводит к стабилизации дисперсии в более
широком диапазоне входных данных.
· Определение «областей компетенции»
моделей, внутри которых дисперсия ошибки сравнительно стабильна, и
использование комбинации моделей. Таким образом, каждая модель работает только
в области своей компетенции, и дисперсия ошибки не превышает заданное граничное
значение. Этот подход распространен в области распознавания образов, где часто
используются сложные нелинейные модели и эвристики.
.8 Тест
Бреуша-Пагана
Чтобы узнать, зависит ли дисперсия случайных возмущений от факторов, не
включенных в модель, проводим тест Бреуша-Пагана. В данном случае мы
рассматриваем фактор Х4, в диаграмме рассеяния которого у нас было подозрение
на гетероскедастичность Результаты теста показали, что дисперсия случайных
возмущений не зависит от Х4, модель гомоскедастична.

2.9 Тест
Уайта
Проведём тест Уайта на гетероскедастичность, чтобы понять, зависит ли
дисперсия случайных возмущений от всех факторов квадратично, т.к. тест
Гольдфельда-Куандта даёт нам сведения только по одному из факторов.
Формулируем гипотезы
Н0: Var(Ui/X) = σ2 - модель гомоскедастична, дисперсия случайных
возмущений не зависит от всех факторов квадратично
Н1: Var(Ui/X) = f(х) - модель гетероскедастична, дисперсия случайных
возмущений зависит от всех факторов квадратично.
Т.к значимость F< alpha, то H0 отклоняется, модель гетероскедастична, дисперсия случайных
возмущений зависит от всех факторов квадратично.

.10 Тест
Дарбина-Уотсона
Автокорреляция - наличие сильной линейной связи между значениями
случайных возмущений хоть и не приводит к смещению оценок коэффициентов
регрессии, но занижает оценки стандартных ошибок и при положительной автокорреляции
может приводить к увеличению дисперсии оценок. В пространственных данных
автокорреляции обычно не бывает. Для данной пространственной выборки
некорректно судить о наличии или отсутствии автокорреляции, но анализ
автокорреляции был проведен в учебных целях.
Тест Дарбина - Уотсона применяется для обнаружения автокорреляции первого
порядка, то есть проверяет некоррелированность не любых, а только соседних
величин εt. В данном случае соседними будут
соседние по возрастанию переменной Y. Переменная Y выбирается таким
образом, чтобы каждое следующее наблюдение могло зависеть от предыдущего.
Упорядочив данные по Y, по
исходным данным строится регрессия с остатками, а по ним рассчитывается
статистика DW:
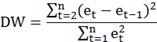
По таблице критических точек распределения Дарбина-Уотсона для заданного
уровня значимости alpha, числа
наблюдений n и количества объясняющих переменных k определяем два значения dl и du.

Согласно результатам данного теста, мы можем судить что автокорреляция
первого порядка отсутствует.
2.11 Тест Бреуша - Годфри

Согласно результатам данного теста, можно судить что автокорреляция
первого порядка отсутствует.
Заключение
Целью данной работы было изучить зависимость объясняемой переменной Y, которая показывает численность занятого
населения на 2013 год, от объясняющих переменных Xi. Анализ статистических данных показывает, что Y (численность занятого населения) в
данном примере, при данных факторах в большей степени зависит от численности
безработных, объема отгруженных товаров и числа квартирных телефонных
аппаратов.
Мною были проведены тесты, которые позволили сделать вывод:
. Несмотря на то, что присутствует мультиколлинеарность, регрессионный
анализ был проведен успешно.
. Модель в целом значима.
. По тесту «Длинная-короткая» выигрывает короткая модель, которую
используем для дальнейших расчетов.
. Проверка однородности выборки - тест Чоу показал, что выборка однородна
и можно использовать одну модель.
. Согласно тестам на гетероскедастичность, дисперсия случайных возмущений
зависит от значимого фактора Х1 (тест GQ), и не зависит от незначимого фактора Х4 (BP).
. Результат по тесту Уайта указывает на то, что модель в целом
гетероскедастична.
Выбранный для проверки автокорреляции тест Дарбина-Уотсона подтвердил
предположение об отсутствии автокорреляции первого порядка.
. Результаты теста Бреуша-Годфри показали, что автокорреляции порядка не
наблюдается. В целом, считаю, что анализ произошел успешно, все поставленные
цели были достигнуты. Кроме того, были получены практические и теоретические
навыки, как в построении, так и анализе регрессии и тестов, проведенных в
данной работе.
Список
использованной литературы
1. Е.Н.
Кузнецов, Т.А. Спиридонова "Подготовка и оформление
предметно-аналитической справки (курсовой работы) по эконометрике",
Москва, 2007.
2. Е.В.
Бауман, Н.Е. Москаленко "Методические рекомендации к решению задач по
курсу «Эконометрика» с помощью Microsoft Excel", Москва, 2003.