Моделирование информационного портала ОСУ УлГУ 'Династия'
ГОСУДАРСТВЕННОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО
ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
УЛЬЯНВОСКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Факультет
Математики и Информационных технологий
Кафедра
Телекоммуникационные технологии и сети
КУРСОВАЯ
РАБОТА
Моделирование
информационного портала ОСУ УлГУ «Династия»
Информационные
системы и технологии 230400
Проект выполнил
студент ИС-о-12/1
Ледюков О.Н.
Научный
руководитель
Чекал Е.Г
Введение
На сегодняшний день существует проблема
получения информационного ресурса по проведения и участию в мероприятиях
созданных студенческих самоуправления и студенческим советом УлГУ «Династия»
для студентов ульяновского государственного университета. У студенческого
самоуправления УлГУ отсутствует официальный информационный портал, где бы была
собрана информация со всех альтернативных информационных ресурсов. Таких как:
Официальный сайт УлГУ.(вкладка студент)
Группы в социальных сетях
Цель данной работы создания официального
информационного портала для студенческого совета УлГУ «Династия» и объедения
всех альтернативных информационных ресурсов в единый информационный портал для
студентов Ульяновского государственного университета.
Объектом исследования в работе является система
студенческого совета УлГУ «Династия», развивающая молодежную политику в
ульяновском государственном университете.
Предметом разработки и исследования являются
информационная система и её модели.
Для программной реализации и экспериментальных
исследований использовались методы структурного и объектно-ориентированного
программирования, инструментальные средства WordPress, СУБД MySQL.
Структура работы. Курсовая работа содержит
введение, 3 раздела, заключение, список используемой литературы.
Во введении показана актуальность темы,
определены цели и задачи курсовой работы.
В первой главе рассматриваются системы
интеллектуальной обработки данных. В данной работе исследуются алгоритмы поиска
ассоциативных правил, такие как FPG и Apriori. А так же приведена сравнительная
характеристика этих алгоритмов.
Во второй главе рассмотрены принципы построение
и создания хранилища данных, а так же витрины данных.
В третьей главе рассмотрен вопрос особенности
реализации при построение и переносе информационного портала на сервер ulsu.ru,
а так же найдены пути решения при возникновения ошибок с работой БД.
В заключении кратко изложены основные результаты
курсовой работы в виде выводов.
информационный портал алгоритм
ассоциативный
Глава 1 Интеллектуальные система обработки
данных
.1FPG - альтернативный алгоритм поиска
ассоциативных правил
Алгоритм
Frequent Pattern-Growth Strategy (FPG)
В основе метода лежит предобработка базы
транзакций, в процессе которой эта база данных преобразуется в компактную
древовидную структуру, называемую Frequent-Pattern Tree - дерево популярных
предметных наборов (откуда и название алгоритма). В дальнейшем для краткости
будем называть эту структуру FP-дерево
Рассмотрим работу алгоритма FPG на конкретном
примере. Пусть имеется БД транзакций (табл. 1).
Таблица 1
|
N
|
Предметный
набор
|
|
1
|
a
b c d e
|
|
2
|
a
b c
|
|
3
|
a
c d e
|
|
4
|
b
c d e
|
|
5
|
b
c
|
|
6
|
b
d e
|
|
7
|
c
d e
|
Для данной БД требуется обнаружить все
популярные предметные наборы с минимальной поддержкой, равной 3, используя
алгоритм FPG.
Производится первое сканирование БД транзакций,
и отбирается множество часто встречающихся предметов, т.е. предметов, которые
встречаются три или более раза. Упорядочим обнаруженные частые предметы в
порядке возрастания их поддержки и получим следующий набор: (c, 6), (b, 5), (d,
5), (e, 5), (a, 3).
Построим FP-дерево. Сначала упорядочим предметы
в транзакциях по убыванию значений их поддержек (табл. 2).
Таблица 2
|
N
|
Исходный
предметный набор
|
Упорядоченный
предметный набор
|
|
1
|
a
b c d e
|
c
b d e a
|
|
2
|
a
b c
|
c
b a
|
|
3
|
a
c d e
|
c
d e a
|
|
4
|
b
c d e
|
c
b d e
|
|
5
|
b
c
|
|
6
|
b
d e
|
b
d e
|
|
7
|
c
d e
|
c
d e
|
|
Правило
1. Если для очередного предмета в дереве встречается узел, имя которого
совпадает с именем предмета, то предмет не создает нового узла, а индекс
соответствующего узла в дереве увеличивается на 1. В противном случае для
этого предмета создается новый узел и ему присваивается индекс 1.
|
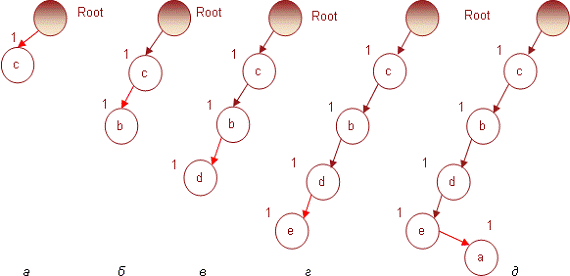
Рис. 1. Построение FP-дерева на транзакции № 1
Сначала берем предмет с из транзакции №1.
Поскольку он является первым, то формируем для него узел и соединяем с
родительским (корневым) (рис. 1, а). Затем берем следующий предмет b и
поскольку других узлов с тем же именем дерево пока не содержит, добавляем его в
виде нового узла, потомка узла с (рис 1, б).Таким же образом формируем узлы для
предметов d, e и a из транзакции № 1 (случаи в, г, и д на рис 1). На этом
использование первой транзакции для построения дерева закончено.
Для транзакции № 2, содержащей предметы c, b и
a, выбираем первый предмет, c. Поскольку дочерний узел с таким именем уже
существует, то в соответствии с правилом построения дерева новый узел не
создается, а добавляется к уже имеющемуся (рис. 2, а). При добавлении
следующего предмета b используем то же правило: поскольку узел b является
дочерним по отношению к текущему (т.е.c), то мы также не создаем новый узел, а
увеличиваем индекс для имеющегося (рис. 2, б). Для следующего предмета из
второй транзакции a в соответствии с правилом построения FP-дерева придется
создать новый узел, поскольку у узла b дочерние узлы с именем a отсутствуют
(рис. 2, в).
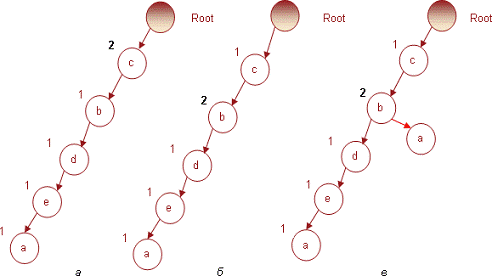
Рис. 2. Построение FP-дерева на транзакции № 2
Транзакция № 3 содержит предметы (c d e a). В
соответствии с правилом построения FP-дерева, предмет c не создаст нового узла,
а увеличит индекс уже имеющегося узла на 1 (рис. 3, а). Следующий предмет d
породит в дереве новый узел, дочерний к c, поскольку тот не содержит потомков с
таким именем (рис 3, б). Аналогично предметы e и a создадут новые узлы -
потомки d (рис. 3 в, г).
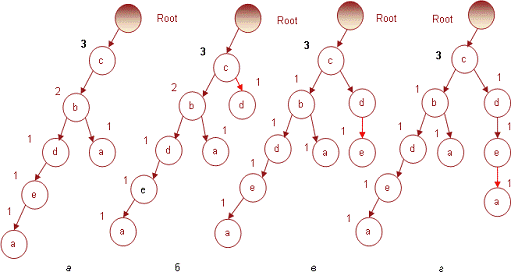
Рис. 3. Использование транзакции № 3 для
построения FP-дерева
Использование транзакции № 4, содержащей набор
предметов (c b d e), не создаст новых узлов, а увеличит индексы узлов с
аналогичной последовательностью имен. Дерево, полученное в результате
использования четвертой транзакции, представлено на рис 4.
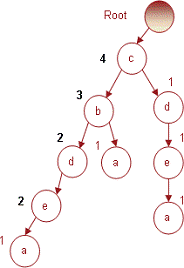
Рис. 4. Дерево, полученное в результате
использования четвертой транзакции
Транзакция № 5 содержит набор c b, предметы
которого увеличат индексы одноименных узлов в дереве, как показано на рис. 5.
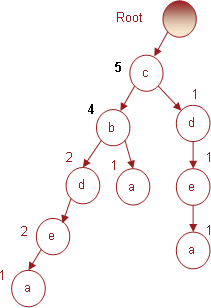
Рис. 5. Дерево, полученное в результате
использования пятой транзакции
Транзакция № 6 содержит предметы (b d e).
Поскольку корневой узел не содержит непосредственного потомка с именем b, то в
соответствии с правилом построения дерева для него будет создан новый узел,
который «потянет» за собой два других - d и e. Все узлы будут добавлены с
индексами 1. В результате дерево примет вид, представленный на рис. 6.
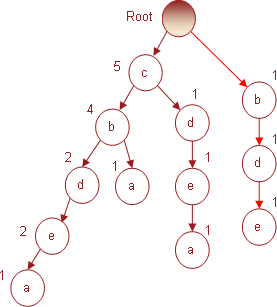
Рис. 6. Дерево, полученное в результате использования
6-й транзакции
И, наконец, последняя транзакция № 7, содержащая
предметный набор (c d e), увеличит на 1 индексы соответствующих узлов.
Получившееся дерево, которое также является результирующим для всей БД
транзакций, представлено на рис. 7.
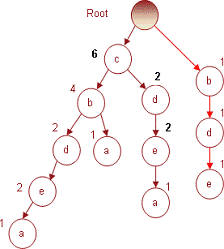
Рис. 7. Результирующее дерево, построенное по
всей БД транзакций
Таким образом, после первого прохода базы данных
и выполнения соответствующих манипуляций с предметными наборами мы построили
FP-дерево, которое в компактном виде представляет информацию о частых
предметных наборах и позволяет производить их эффективное извлечение, что и
делается на втором сканировании БД.
Представление базы данных транзакций в виде
FP-дерева очевидно. Если в исходной базе данных каждый предмет повторяется
многократно, то в FP-дереве каждый предмет представляется в виде узла, а его
индекс указывает на то, сколько раз данный предмет появляется. Иными словами,
если предмет в исходной базе данных транзакций появляется 100 раз, то в дереве
для него достаточно создать узел и установить индекс 100.
Извлечение частых предметных наборов из
FP-дерева
Для каждого предмета в FP-дереве, а точнее, для
связанных с ними узлов, можно указать путь, т.е. последовательность узлов,
которую надо пройти от корневого узла до узла, связанного с данным предметом.
Если предмет представлен в нескольких ветвях дерева (что чаще всего и
происходит), то таких путей будет насколько. Например, для FP-дерева на рис. 7
для предмета a можно указать 3 пути: {cbdea, cba, cdea}. Такой набор путей
называется условным базисом предмета (англ.: conditional base). Каждый путь в
базисе состоит из двух частей - префикса и суффикса. Префикс - это
последовательность узлов, которые проходит путь для того чтобы достичь узла,
связанного с предметом. Суффикс - это сам узел, к которому «прокладывается»
путь. Таким образом, в условном базисе все пути будут иметь различные префиксы
и одинаковый суффикс. Например, в пути cbdea префиксом будет cbde, а суффиксом
- a.
Процесс извлечения из FP-дерева частых предметных
наборов будет заключаться в следующем.
Выбираем предмет (например, a) и находим в
дереве все пути, которые ведут к узлам этого предмета Иными словами, для a это
будет набор {cbdea, cba, cdea}. Затем для каждого пути подсчитываем, сколько
раз данный предмет встречается в нем, и записываем это в виде (cbdea, 1), (cba,
1) и (cdea, 1).
Удалим сам предмет (суффикс набора) из ведущих к
нему путей, т.е. {cbdea, cba, cdea}. После это останутся только префиксы:
{cbde, cb, cde}.
Подсчитаем, сколько раз каждый предмет
появляется в префиксах путей, полученных на предыдущем шаге, и упорядочим в
порядке убывания этих значений, получив новый набор транзакций.
На его основе построим новое FP-дерево, которое
назовем условным FP-деревом (conditional FP-tree), поскольку оно связано только
с одним объектом (в нашем случае, a).
В этом FP-дереве найдем все предметы (узлы), для
которых поддержка (количество появлений в дереве) равна 3 и больше, что
соответствует заданному уровню минимальной поддержки. Если предмет встречается
два или более раза, то его индексы, т.е. частоты появлений в условном базисе,
суммируются.
Начиная с верхушки дерева,
записываем пути, которые ведут к каждому узлу, для которого поддержка/индекс
больше или равны 3, возвращаем назад предмет (суффикс шаблона), удаленный на
шаге 2, и подсчитываем индекс/поддержку, полученную в результате. Например,
если предмет a имеет индекс 3, то можно записать (c b a, 3), что и будет
являться популярным предметным набором
<#"864746.files/image008.gif">
Рис. 8. Условное FP-дерево для
предмета a
Поскольку предметы d и e встречаются
два раза, то их индексы суммируются, и в итоге мы получим следующий порядок
предметов: (c, 3), (b, 2), (d, 2), (e, 2). Таким образом, только узел
cудовлетворяет уровню минимальной поддержки 3. Следовательно, для предмета a
может быть сгенерирован только один популярный набор
<#"864746.files/image009.gif">
Рис. 9. Условное FP-дерево для
суффикса b
Таким образом, префиксы путей будут
(c b, 4) и (b, 1), и, следовательно, для предмета b будет иметь место только
один популярный набор (c b, 4).
Для предмета c, поскольку он
является непосредственным потомком корневого узла, нельзя указать путь (см. рис
7). Значит, префикс путей для него будет пустым, из чего следует, что и
популярные предметные наборы отсутствуют.
Следующий предмет, для которого мы
произведем поиск популярных предметных наборов, будет d с поддержкой равной 5.
Условное FP-дерево, связанное с предметом d представлено на рис. 10.
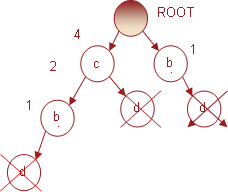
Рис. 10. Условное FP-дерево для
предмета d
Префиксы путей для условного дерева,
связанного с предметом d, будут: (c b d, 2), (c d, 2) и (b dd, 1). Учитывая,
что индексы для узлов b суммируются, то соответствующие популярные предметные
наборы будут (c, d, 4) и (b, d, 3).
И, наконец, для последнего предмета
е, имеющего поддержку 5, условное FP-дерево представлено на рис. 11.
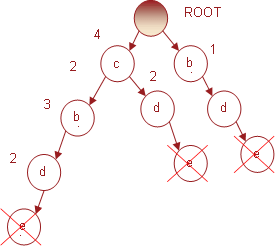
Рис. 11. Условное FP-3 дерево для предмета e
Префиксы путей, ведущих в условном дереве к
узлам, связанным с предметом e, будут: (c b d e, 2) (c d e, 2) (b d e, 1).
Подсчитав суммарную поддержку каждого предмета в условном дереве и упорядочив
предметы по ее убыванию, получим: (d, 5), (c, 4), (b, 3). Следовательно,
популярными предметными наборами для предмета e будут: (d, e, 5), (d, c, e, 4),
(d, b, e, 3).
Таким образом, мы получили следующие популярные
предметные наборы:
(c, a, 3), (c, b, 4), (c, d, 4), (b,
d, 3), (d, e, 5), (d, c, e, 4), (d, b, e, 3).
1.2APRIORI - масштабируемый алгоритм поиска
ассоциативных правил
Для того, чтобы было возможно применить
алгоритм, необходимо провести предобработку данных: во-первых, привести все
данные к бинарному виду; во-вторых, изменить структуру данных.
Обычный вид базы данных транзакций:
|
Номер
транзакции
|
Наименование
элемента
|
Количество
|
|
1001
|
А
|
2
|
|
1001
|
D
|
3
|
|
1001
|
E
|
1
|
|
1002
|
2
|
|
1002
|
F
|
1
|
|
1003
|
B
|
2
|
|
1003
|
A
|
2
|
|
1003
|
C
|
2
|
|
…
|
…
|
…
|
Таблица 1
Нормализованный вид:
|
TID
|
A
|
B
|
C
|
D
|
E
|
F
|
G
|
H
|
I
|
K
|
...
|
|
1001
|
1
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
0
|
0
|
…
|
|
1002
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
…
|
|
1003
|
1
|
1
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
…
|
Количество столбцов в таблице равно количеству
элементов, присутствующих в множестве транзакций D. Каждая запись соответствует
транзакции, где в соответствующем столбце стоит 1, если элемент присутствует в
транзакции, и 0 в противном случае. Заметим, что исходный вид таблицы может
быть отличным от приведенного в таблице 1. Главное, чтобы данные были
преобразованы к нормализованному виду, иначе алгоритм не применим.
Более того, как видно из таблицы, все элементы
упорядочены в алфавитном порядке (если это числа, они должны быть упорядочены в
числовом порядке). Как вы, наверное, уже догадались, это сделано неслучайно.
Но, не будем забегать вперед, всему свое время.
Итак, данные преобразованы, теперь можно приступить
к описанию самого алгоритма. Как было сказано в предыдущей статье, такие
алгоритмы работают в два этапа, не является исключением и рассматриваемый нами
алгоритм Apriori. На первом шаге необходимо найти часто встречающиеся наборы
элементов, а затем, на втором, извлечь из них правила. Количество элементов в
наборе будем называть размером набора, а набор, состоящий из k элементов, -
k-элементным набором.
Свойство анти-монотонности
Это свойство носит название
анти-монотонности и служит для снижения размерности
<#"864746.files/image012.gif">
Алгоритм Apriori
На первом шаге алгоритма
подсчитываются 1-элементные часто встречающиеся наборы. Для этого необходимо
пройтись по всему набору данных и подсчитать для них поддержку, т.е. сколько
раз встречается в базе.
Следующие шаги будут состоять из
двух частей: генерации потенциально часто встречающихся наборов элементов (их
называют кандидатами) и подсчета поддержки для кандидатов.
Описанный выше алгоритм можно
записать в виде следующего псевдо-кода:= {часто встречающиеся 1-элементные
наборы}
для (k=2; Fk-1 <>  ; k++) {=
Apriorigen(Fk-1) // генерация кандидатов
; k++) {=
Apriorigen(Fk-1) // генерация кандидатов
для всех транзакций t  T {=
subset(Ck, t) // удаление избыточных правил
T {=
subset(Ck, t) // удаление избыточных правил
для всех кандидатов c Ct.count ++
}= { c Ck |
c.count >= minsupport} // отбор кандидатов
}
Результат  Fk
Fk
Опишем функцию генерации кандидатов.
На это раз нет никакой необходимости вновь обращаться к базе данных. Для того,
чтобы получить k-элементные наборы, воспользуемся (k-1)-элементными наборами,
которые были определены на предыдущем шаге и являются часто встречающимися.
Вспомним, что наш исходный набор
хранится в упорядоченном виде. Генерация кандидатов также будет состоять из
двух шагов.
Объединение. Каждый кандидат Ck
будет формироваться путем расширения часто встречающегося набора размера (k-1)
добавлением элемента из другого (k-1)- элементного набора.
Приведем алгоритм этой функции
Apriorigen в виде небольшого SQL-подобного запроса.
insert into
Ckp.item1, p.item2, …, p.itemk-1, q.itemk-1Fk-1 p, Fk-1 qp.item1= q.item1,
p.item2 = q.item2, … , p.itemk-2 = q.itemk-2, p.itemk-1 < q.itemk-1
Удаление избыточных правил. На
основании свойства анти-монотонности, следует удалить все наборы c Ck если
хотя бы одно из его (k-1) подмножеств не является часто встречающимся.
После генерации кандидатов следующей
задачей является подсчет поддержки для каждого кандидата. Очевидно, что
количество кандидатов может быть очень большим и нужен эффективный способ
подсчета. Самый тривиальный способ - сравнить каждую транзакцию с каждым
кандидатом. Но это далеко не лучшее решение. Гораздо быстрее и эффективнее
использовать подход, основанный на хранении кандидатов в хэш-дереве. Внутренние
узлы дерева содержат хэш-таблицы с указателями на потомков, а листья - на
кандидатов. Это дерево нам пригодится для быстрого подсчета поддержки для
кандидатов.
Хэш-дерево строится каждый раз,
когда формируются кандидаты. Первоначально дерево состоит только из корня,
который является листом, и не содержит никаких кандидатов-наборов. Каждый раз
когда формируется новый кандидат, он заносится в корень дерева и так до тех
пор, пока количество кандидатов в корне-листе не превысит некоего порога. Как
только количество кандидатов становится больше порога, корень преобразуется в
хэш-таблицу, т.е. становится внутренним узлом, и для него создаются
потомки-листья. И все примеры распределяются по узлам-потомкам согласно
хэш-значениям элементов, входящих в набор, и т.д. Каждый новый кандидат
хэшируется на внутренних узлах, пока он не достигнет первого узла-листа, где он
и будет храниться, пока количество наборов опять же не превысит порога.
Хэш-дерево с кандидатами-наборами
построено, теперь, используя хэш-дерево, легко подсчитать поддержку для каждого
кандидата. Для этого нужно "пропустить" каждую транзакцию через
дерево и увеличить счетчики для тех кандидатов, чьи элементы также содержатся и
в транзакции, т.е. Ck  Ti = Ck. На
корневом уровне хэш-функция применяется к каждому элементу из транзакции.
Далее, на втором уровне, хэш-функция применяется ко вторым элементам и т.д. На
k-уровне хэшируется k-элемент. И так до тех пор, пока не достигнем листа. Если
кандидат, хранящийся в листе, является подмножеством рассматриваемой
транзакции, тогда увеличиваем счетчик поддержки этого кандидата на единицу.
Ti = Ck. На
корневом уровне хэш-функция применяется к каждому элементу из транзакции.
Далее, на втором уровне, хэш-функция применяется ко вторым элементам и т.д. На
k-уровне хэшируется k-элемент. И так до тех пор, пока не достигнем листа. Если
кандидат, хранящийся в листе, является подмножеством рассматриваемой
транзакции, тогда увеличиваем счетчик поддержки этого кандидата на единицу.
После того, как каждая транзакция из
исходного набора данных "пропущена" через дерево, можно проверить
удовлетворяют ли значения поддержки кандидатов минимальному порогу. Кандидаты,
для которых это условие выполняется, переносятся в разряд часто встречающихся.
Кроме того, следует запомнить и поддержку набора, она нам пригодится при
извлечении правил. Эти же действия применяются для нахождения (k+1)-элементных
наборов и т.д.
После того как найдены все часто
встречающиеся наборы элементов, можно приступить непосредственно к генерации
правил.
Извлечение правил - менее трудоемкая
задача. Во-первых, для подсчета достоверности <#"864746.files/image017.gif"> C.
Поддержка самого набора нам известна, но и его множество {A, B}, лежащее в
условии правила, также является часто встречающимся в силу свойства
анти-монотонности, и значит его поддержка нам известна. Тогда мы легко сможем
подсчитать достоверность. Это избавляет нас от нежелательного просмотра базы
транзакций, который потребовался в том случае если бы это поддержка была
неизвестна.
Чтобы извлечь правило из часто
встречающегося набора F, следует найти все его непустые подмножества. И для
каждого подмножества s мы сможем сформулировать правило s  (F - s),
если достоверность правила conf(s (F - s)) = supp(F)/supp(s) не
меньше порога minconf.
(F - s),
если достоверность правила conf(s (F - s)) = supp(F)/supp(s) не
меньше порога minconf.
Заметим, что числитель остается
постоянным. Тогда достоверность имеет минимальное значение, если знаменатель
имеет максимальное значение, а это происходит в том случае, когда в условии
правила имеется набор, состоящий из одного элемента. Все супермножества данного
множества имеют меньшую или равную поддержку и, соответственно, большее
значение достоверности. Это свойство может быть использовано при извлечении
правил. Если мы начнем извлекать правила, рассматривая сначала только один
элемент в условии правила, и это правило имеет необходимую поддержку, тогда все
правила, где в условии стоят супермножества этого элемента, также имеют
значение достоверности выше заданного порога. Например, если правило A  BCDE
удовлетворяет минимальному порогу достоверности minconf, тогда AB CDE также
удовлетворяет. Для того, чтобы извлечь все правила используется рекурсивная
процедура. Важное замечание: любое правило, составленное из часто
встречающегося набора, должно содержать все элементы набора. Например, если
набор состоит из элементов {A, B, C}, то правило A B не должно
рассматриваться.
BCDE
удовлетворяет минимальному порогу достоверности minconf, тогда AB CDE также
удовлетворяет. Для того, чтобы извлечь все правила используется рекурсивная
процедура. Важное замечание: любое правило, составленное из часто
встречающегося набора, должно содержать все элементы набора. Например, если
набор состоит из элементов {A, B, C}, то правило A B не должно
рассматриваться.
.3Сравнительная характеристика
алгоритмов поиска ассоциативных правил
Узким местом в алгоритме a priori
<#"864746.files/image020.gif">
Рис. 12. Сравнение алгоритмов FPG и
a priori
Повышение эффективности обработки
популярных наборов
Одним из направлений повышения
эффективности обработки популярных предметных наборов
<#"864746.files/image021.gif"> <#"864746.files/image022.gif"> <#"864746.files/image023.gif"> <#"864746.files/image024.gif"> <#"864746.files/image025.gif"> <#"864746.files/image026.gif"> <http://gruz0.ru/wp-content/uploads/2013/08/ispravlyaem-oshibku-ustanovki-soedineniya-s-bazoy-dannyih-01.png>
Нажать кнопку «Починить базу данных»
и дождаться завершения операции.
Это может занять некоторое время, в
зависимости от размера данных в таблицах базы вашего сайта.
Если же не удаётся подключиться к
базе данных через phpMyAdmin, то используем следующий алгоритм.
Создаёте на компьютере файл, назовём
его test.php и добавляем в него следующий код:
|
1
2 3 4 5 6 7
|
<?php $resource =
mysql_connect('localhost', 'пользователь',
'пароль');
if (!$resource) { die('Ошибка
при
подключении:
' . mysql_error()); } echo 'Подключено
успешно!';
mysql_close($link);
|
Вместо «пользователь» и «пароль» укажите свои
данные для подключения к базе данных.
Загружайте этот файл на FTP вашего хостинга
Открывайте в браузере адрес
http://ваш-сайт.ru/test.php
Если на экране отразилось «Ошибка при
подключении», то рядом с ней будет выведено сообщение.
Если же отобразилось «Подключено успешно», тогда
внесите используемые ваши логин и пароль для подключения к базе данных в файл
wp-config.php.
Заключение
В курсовой работе были рассмотрены алгоритмы
построение интеллектуальных систем обработки данных, а так же принципы создания
хранилища данных. Описаны особенности реализации и переноса информационного
портала на сервер ulsu.ru и пути решение при возникновения ошибок при переносе
базы данных.
Список литературы
Колисниченко
Д.Н., «PHP и MySQL. Разработка Web-приложений», 4 издание, перераб. и доп. -
СПб.: БХВ-Петербург, 2013. - 560 с.: ил. - (Профессиональное программирование).
Котеров
Д.В., Костарев А.Ф. «PHP 5»/ СПб.: БХВ-Петербург, 2005. - 1120 с.:ил.
R. Agrawal, T. Imielinski, A. Swami.
1993. Mining Associations between Sets of Items <http://www.basegroup.ru/glossary_ajax/definitions/itemset>
in Massive Databases
<http://www.basegroup.ru/glossary_ajax/definitions/database>. In Proc. of
the 1993 ACM-SIGMOD
<http://www.basegroup.ru/glossary_ajax/definitions/sigmoid> Int’l Conf.
on Management of Data, 207-216.. Agrawal, R. Srikant. "Fast Discovery of
Association Rules", In Proc. of the 20th International Conference on VLDB
<http://www.basegroup.ru/glossary_ajax/definitions/vldb>, Santiago,
Chile, September 1994.
Сайт
<http://php-myadmin.ru/>
Сайт
<http://ru.wordpress.org/>
Дронов
Владимир PHP, MySQL и Dreamweaver MX 2004. Разработка интерактивных Web-сайтов;
БХВ-Петербург - Москва, 2010. - 448 c.
Дронов
Владимир РНР 5/6, MySQL 5/6 и Dreamweaver CS4. Разработка интерактивных
Web-сайтов; БХВ-Петербург - Москва, 2009. - 544 c.
Дронов,
Владимир Macromedia Dreamweaver 4: разработка Web-сайтов; M.: БХВ - Москва,
2014. - 608 c.
Китинг,
Джоди Flash MX. Искусство создания web-сайтов; ТИД ДС - Москва, 2012. - 848 c.
Костин
С. П. Самоучитель создания Web-сайтов; Триумф - Москва, 2009. - 176 c.
Приложение
Скрипт repair.php
<?php
/**
* Database Repair and Optimization
Script.
*
* @package WordPress
* @subpackage Database
*/('WP_REPAIRING', true);
_once( dirname( dirname( dirname(
__FILE__ ) ) ) . '/wp-load.php' );
( 'Content-Type: text/html;
charset=utf-8' );
?>
<!DOCTYPE html>
<html
xmlns="http://www.w3.org/1999/xhtml" <?php language_attributes();
?>>
<head>
<meta name="viewport"
content="width=device-width" />
<title><?php _e( 'WordPress
› Database Repair' ); ?></title>
<?php_admin_css( 'install', true
);
?>
</head>
<body>
<h1 id="logo"><a
href="<?php echo esc_url( __( 'https://wordpress.org/' ) ); ?>"
tabindex="-1"><?php _e( 'WordPress' );
?></a></h1>
<?php
( ! defined( 'WP_ALLOW_REPAIR' ) ) {'<p>'
. __( 'To allow use of this page to automatically repair database problems,
please add the following line to your <code>wp-config.php</code>
file. Once this line is added to your config, reload this page.' ) .
"</p><p><code>define('WP_ALLOW_REPAIR', true);</code></p>";
} elseif ( isset( $_GET['repair'] )
) {
$optimize = 2 == $_GET['repair'];
$okay = true;
$problems = array();
$tables = $wpdb->tables();
// Sitecategories may not exist if
global terms are disabled.
$query = $wpdb->prepare(
"SHOW TABLES LIKE %s", $wpdb->esc_like( $wpdb->sitecategories )
);( is_multisite() && ! $wpdb->get_var( $query ) ) {(
$tables['sitecategories'] );
}
/**
* Filter additional database tables
to repair.
*
* @since 3.0.0
*
* @param array $tables Array of
prefixed table names to be repaired.
*/
$tables = array_merge( $tables,
(array) apply_filters( 'tables_to_repair', array() ) );
// Loop over the tables, checking
and repairing as needed.( $tables as $table ) {
$check = $wpdb->get_row(
"CHECK TABLE $table" );
'<p>';( 'OK' ==
$check->Msg_text ) {
/* translators: %s: table name */(
__( 'The %s table is okay.' ), "<code>$table</code>" );
} else {
/* translators: 1: table name, 2:
error message, */( __( 'The %1$s table is not okay. It is reporting the
following error: %2$s. WordPress will attempt to repair this table…'
) , "<code>$table</code>",
"<code>$check->Msg_text</code>" );
$repair = $wpdb->get_row(
"REPAIR TABLE $table" );'<br /> ';(
'OK' == $check->Msg_text ) {
/* translators: %s: table name */(
__( 'Successfully repaired the %s table.' ),
"<code>$table</code>" );
} else {
/* translators: 1: table name, 2:
error message, */sprintf( __( 'Failed to repair the %1$s table. Error: %2$s' ),
"<code>$table</code>",
"<code>$check->Msg_text</code>" ) . '<br />';
$problems[$table] =
$check->Msg_text;
$okay = false;
}
}
( $okay && $optimize ) {
$check = $wpdb->get_row(
"ANALYZE TABLE $table" );
'<br
/> ';( 'Table is already up to date'
== $check->Msg_text ) {
/* translators: %s: table name */(
__( 'The %s table is already optimized.' ),
"<code>$table</code>" );
} else {
$check = $wpdb->get_row(
"OPTIMIZE TABLE $table" );
'<br
/> ';( 'OK' == $check->Msg_text ||
'Table is already up to date' == $check->Msg_text ) {
/* translators: %s: table name */(
__( 'Successfully optimized the %s table.' ),
"<code>$table</code>" );
} else {
/* translators: 1: table name, 2:
error message, */( __( 'Failed to optimize the %1$s table. Error: %2$s' ),
"<code>$table</code>",
"<code>$check->Msg_text</code>" );
}
}
}'</p>';
}
( $problems ) {( '<p>' .
__('Some database problems could not be repaired. Please copy-and-paste the
following list of errors to the <a href="%s">WordPress support
forums</a> to get additional assistance.') . '</p>', __(
'https://wordpress.org/support/forum/how-to-and-troubleshooting' ) );
$problem_output = '';( $problems as
$table => $problem )
$problem_output .= "$table:
$problem\n";'<p><textarea name="errors"
id="errors" rows="20" cols="60">' .
esc_textarea( $problem_output ) . '</textarea></p>';
} else {'<p>' . __( 'Repairs
complete. Please remove the following line from wp-config.php to prevent this
page from being used by unauthorized users.' ) .
"</p><p><code>define('WP_ALLOW_REPAIR',
true);</code></p>";
}
} else {( isset( $_GET['referrer'] )
&& 'is_blog_installed' == $_GET['referrer'] )'<p>' . __( 'One or
more database tables are unavailable. To allow WordPress to attempt to repair
these tables, press the “Repair Database” button. Repairing
can take a while, so please be patient.' ) . '</p>';'<p>' . __(
'WordPress can automatically look for some common database problems and repair
them. Repairing can take a while, so please be patient.' ) . '</p>';
?>
<p>
<p><?php _e( 'WordPress can
also attempt to optimize the database. This improves performance in some
situations. Repairing and optimizing the database can take a long time and the
database will be locked while optimizing.' ); ?></p>
<p>
<?php
}
?>
</body>
</html>