Основы эконометрического анализа
Содержание
регрессия эконометрический уравнение интервал
1.
Теоретическая часть. Модель простой регрессии
1.1 Общие
сведения
1.2 Основные
элементы эконометрической модели
1.3 Спецификация модели парной линейной
регрессии
1.4 Оценка параметров. Метод наименьших
квадратов
1.5 Основные предположения регрессионного
анализа
1.6
Характеристика оценок коэффициентов уравнения регрессии
1.7
Построение доверительных интервалов
1.8 Проверка статистической значимости
коэффициентов регрессии
1.9
Автокорреляция остатков
1.10 Гетероскедастичность остатков
Выводы
2.
Практическая часть
2.1 Задание 1
2.2 Задание 2
Список
литературы
1. Теоретическая часть. Модель простой регрессии
1.1
Общие сведения
Математические модели широко используются в экономике, в финансах, в общественных
науках. Обычно модели строятся и верифицируются на основе имеющихся наблюдений
изучаемого показателя и, так называемых, объясняющих факторов. Язык экономики
все больше становится математическим, а саму экономику все чаще упоминают как
одну из наиболее математизированных наук. В течение последних десятилетий
математические и, в частности, статистические методы в экономике стремительно
развиваются. Свидетельством признания эконометрики является присуждение за
наиболее выдающиеся работы в этой области Нобелевских премий по экономике: Р.
Фришу и Я. Тинбергу (1969) за разработку математических методов анализа
экономических процессов, Л. Клейну (1980) за создание эконометрических моделей
и их применение к анализу экономических колебаний и экономической политике, Т.
Хаавельмо (1989) за работы в области вероятностных основ эконометрики и анализ
одновременных экономических структур, Дж. Хекману и Д. Макфаддену (2000) за
развитие методов анализа селективных выборок и моделей дискретного выбора.
Вряд ли возможно в настоящее время дать единое общепринятое определение
эконометрики. Термин "эконометрика" был предложен в 1926 г.
норвежским ученым Р. Фришем и дословно означает "эконометрические
измерения". Более узкое значение этого термина подразумевает набор математико-статистических
методов, используемых в приложениях математики в экономике. Ниже приводятся
несколько определений известных ученых - экономистов, математиков, позволяющих
получить представление о содержании эконометрики.
"Эконометрика - это раздел математики, занимающийся разработкой и
применением статистических методов для измерений взаимосвязей между
экономическими переменными" (С. Фишер). "Основная задача эконометрики
- наполнить эмпирическим содержанием априорные экономические рассуждения"
(Л. Клейн).
"Цель эконометрики - эмпирический вывод экономических законов"
(Э. Маленво).
"Эконометрика есть единство трех составляющих - статистики,
экономической теории и математики" (Р. Фриш).
Не будет преувеличением сказать, что эконометрика объединяет совокупность
методов и моделей, позволяющих на базе экономической теории, экономической
статистики и математико-статистического инструментария придавать количественные
выражения качественным зависимостям. Успешное освоение и применение
эконометрических методов анализа экономических явлений требует знания основных
разделов теории вероятностей и, в особенности, математической статистики.
Часто говорят, что современное экономическое образование основывается на
макроэкономике, микроэкономике и эконометрике. Можно указать следующие
взаимосвязи между этими элементами:
• Основные результаты экономической теории носят качественный характер, а
эконометрика вносит в них эмпирическое содержание;
• Математическая экономика выражает экономические законы в виде
математических соотношений, а эконометрика осуществляет опытную проверку этих
законов;
• Экономическая статистика дает информационное обеспечение исследуемых
явлений в виде исходных статистических данных и экономических показателей, а
эконометрика проводит анализ количественных взаимосвязей между этими
показателями.
Несмотря на то, что многие эконометрические результаты являются, по сути
и форме, математическими (имеют, например, вид теорем), именно экономическая
теория определяет постановку задач и исходные предпосылки, а полученные
результаты представляют интерес лишь тогда, когда удается их экономическая
интерпретация.
1.2
Основные элементы эконометрической модели
В рамках эконометрического анализа обычно ставится задача определения
некоторой величины (показателя), значение которой формируется под воздействием
некоторых факторов. Так, цена на подержанный автомобиль может зависеть от года
выпуска, пробега, мощности двигателя и т.п. Такие показатели, как например
цена, обычно называют зависимыми (объясняемыми) переменными, а факторы, от
которых они зависят - объясняющими переменными (факторами). Нас обычно
интересует среднее или ожидаемое значение зависимой переменной при заданных
значениях объясняющих переменных.
Конкретное значение зависимой переменной (наблюдаемое значение) обычно
зависит и от случайных явлений. В примере с автомобилем случайным может быть
состоянием рынка, характер продавца и т.д. Для экономики типична такая форма
связи между переменными величинами, когда каждому значению одной переменной
соответствует не какое-то определенное значение другой переменной, а множество
возможных значений (более точно - некоторое условное распределение) другой
переменной. Такая зависимость называется статистической (стохастической,
вероятностной). Стохастическая форма связи обуславливается тем, что зависимая
переменная подвержена влиянию ряд неконтролируемых или неучтенных факторов, а
также тем, что измерение значений переменных обычно сопровождается некоторыми
случайными ошибками.
Таким образом, зависимая переменная является случайной величиной, имеющей
при заданных значениях факторов некоторое распределение. В любой
эконометрической модели зависимая переменная обычно разбивается на две части:
объясненную и случайную. В общем виде задача эконометрического моделирования состоит
в следующем:
На основании экспериментальных данных определить (оценить) объясненную
часть зависимой переменной и, рассматривая случайную составляющую как случайную
величину, получить оценки параметров ее распределения.
Обозначим зависимую переменную через y, ее объясненную часть, зависящую
от значений объясняющих переменных x = (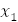 ,
,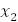 ,k ,
,k ,
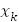 ) через f(x) (т.е. объясненная часть представляет собой
функцию от значений факторов), а случайную составляющую (называемую также
возмущением или ошибкой) - через ε. Тогда в общем виде эконометрическая
модель имеет вид:
) через f(x) (т.е. объясненная часть представляет собой
функцию от значений факторов), а случайную составляющую (называемую также
возмущением или ошибкой) - через ε. Тогда в общем виде эконометрическая
модель имеет вид:
= f(x) + ε. (1.2.1)
В качестве объясненной части f(x) случайной величины y естественно
выбрать ее среднее (ожидаемое) значение при заданных значениях X - иными
словами, условное математическое ожидание 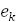 (y) , полученное при данном значении
объясняющих переменных x = (,,k,):
(y) , полученное при данном значении
объясняющих переменных x = (,,k,):
(y)= f(x) (1.2.2)
Это уравнение (зависимость) называется теоретическим уравнением
регрессии, функция f(x) - теоретической функцией регрессии, а уравнение
= 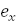 (y)
+ ε, (1.2.3)
(y)
+ ε, (1.2.3)
уравнением регрессионной модели.
В силу своего определения регрессионная модель обладает особыми
свойствами. Так, взяв от обеих частей равенства математическое ожидание при
заданном наборе значений объясняющих переменных, получаем, что
(ε) = 0 ,
а значит, что и e(ε) = 0 - т.е. в регрессионной модели среднее
значений случайной ошибки равно нулю. Это свойство оказывается весьма
существенным условием, влияющим на статистические свойства получаемых
результатов.
Исходной точкой любого эконометрического исследования является выборка
наблюдений зависимой переменной y и объясняющих переменных 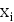 ,
,
= 1,K k.
Такие выборки представляют собой наборы значений (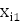 ,
, 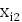 , k,
, k, 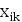 ,
, 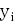 ), где i = 1,k, n - номер наблюдения,
k - количество объясняющих переменных (факторов). Обычно выделяются два типа
выборочных данных:
), где i = 1,k, n - номер наблюдения,
k - количество объясняющих переменных (факторов). Обычно выделяются два типа
выборочных данных:
• Пространственная выборка (cross-sectional data) - набор экономических
показателей, полученных в некоторый момент времени (или в относительно
небольшом промежутке времени), т.е. набор независимых выборочных данных из
некоторой генеральной совокупности (так как практически независимость случайных
величин проверить трудно, то обычно за независимые принимаются величины, не
связанные причинно);
• Временной (динамический) ряд (time-series data) - выборка, в которой
важны не только сами наблюдаемые значения, но и порядок их следования друг за
другом. Чаще всего данные представляют собой наблюдения одной и той же величины
в последовательные моменты времени.
Необходимо, однако, заметить, что такое разделение во многом условно и
определяется целью и содержанием исследования.
После того, как определен набор объясняющих переменных, получены
эмпирические (выборочные) данные, для точного описания уравнения регрессии
необходимо найти объясненную часть зависимой переменной y, обозначенную нами
через f (x) (как указывалось выше, представляющую собой условное математическое
ожидание). Однако на практике точное ее определение, как правило, невозможно,
поэтому можно говорить только об оценке (приближенном выражении, аппроксимации)
теоретической функции регрессии по выборке. Стандартная процедура оценивания
состоит в следующем:
Шаг 1. Выбирается вид функции f(x) (точнее - параметрическое семейство, к
которому принадлежит искомая функция, рассматриваемая как функция от значений
объясняющих переменных x);
Шаг 2. С помощью методов математической статистики находятся оценки
параметров этой функции.
Важно иметь в виду, что в общем случае не существует формальных способов
выбора наилучшего семейства функций f(x) на шаге 1. Очень часто выбирается
семейство линейных функций. Выбор линейной модели, кроме вполне очевидного
преимущества - простоты, имеет ряд существенных математических оснований,
оправдывающих этот выбор.
В целом формулировку исходных предпосылок и ограничений, выбор структуры
уравнения модели, представление в математической форме обнаруженных
взаимосвязей и соотношений, установление состава объясняющих переменных
называют спецификацией модели.
От того, насколько удачно решена проблема спецификации, в значительной
степени зависит успех всего процесса эконометрического моделирования.
Оценку теоретической функции регрессии, построенную по эмпирическим
данным, обозначим через y . Уравнение
'= f '(x,b), (1.2.4)
полученное по выборке, где y' - оценка условной средней переменной y при
значениях переменных x = (,,k,), b - вектор параметров функции f' (которая является
аппроксимацией функции f), называется выборочным (эмпирическим) уравнением
регрессии (модельной функцией регрессии).
Итак, можно выделить несколько основных этапов эконометрического
моделирования и анализа:
Этап 1. Постановочный - формируется цель исследования (анализ
экономического объекта, прогноз его показателей, имитация развития, выработка
управленческих решений), теоретическое обоснование выбора переменных;
Этап 2. Априорный - анализ сущности изучаемого объекта, формирование и
формализация имеющейся информации;
Этап 3. Параметризация - выбор вида модели (вида функции f (x)), анализ
взаимосвязей и спецификация модели;
Этап 4. Информационный - сбор необходимой статистической информации -
наблюдаемых значений переменных;
Этап 5. Идентификация модели - статистический анализ модели и оценка ее
параметров;
Этап 6. Верификация модели - проверка адекватности, статистической
значимости модели.
1.3
Спецификация модели парной линейной регрессии
В случае парной регрессии рассматривается один объясняющий фактор: через
y обозначим изучаемый эконометрический показатель; через x - объясняющий
фактор. Эконометрическая модель, приводящая к парной регрессии, имеет следующий
вид
y = f (x) + ε,
где f(x) - неизвестная функциональная зависимость (теоретическая
регрессия); ε - возмущение, случайное слагаемое, представляющее собой
совокупное действие не включенных в модель факторов, погрешностей.
Основная задача эконометрического моделирования - построение по выборке
эмпирической модели, выборочной парной регрессии'(x), являющейся оценкой
теоретической регрессии (функции f(x)):
' = f '(x),
здесь f' (x) - эмпирическая (выборочная) регрессия, описывающая
усредненную по x зависимость между изучаемым показателем и объясняющим
фактором. После построения выборочной регрессии обычно производится верификация
модели - проверка статистической значимости и адекватности построенной парной
регрессии имеющимся эмпирическим данным.
Экспериментальная основа построения парной эмпирической регрессии -
двумерная выборка:
(, ),k,(
),k,(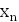 ,
,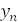 ),
),
где n - объем выборки (объем массива экспериментальных данных).
Основная задача спецификации модели - выбор вида функциональной
зависимости. В случае парной регрессии обычно рассматриваются функциональные
зависимости следующего вида:
линейная:
 (1.3.3)
(1.3.3)
полиномиальная
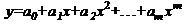 (1.3.4)
(1.3.4)
степенная:
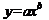 (1.3.5)
(1.3.5)
экспоненциальная:
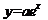 (1.3.6)
(1.3.6)
логистическая:
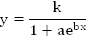 (1.3.7)
(1.3.7)
Основные методы выбора функциональной зависимости f (x):
) Геометрический;
) Эмпирический;
) Аналитический.
Геометрический метод выбора функциональной зависимости сводится к
следующему. На координатной плоскости Oxy наносятся
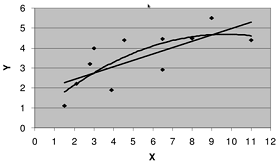
Рисунок 1. Геометрический метод выбора функциональной зависимости
точки (, ), i = 1,K, n, соответствующие выборке. Полученное
графическое изображение называется полем корреляции (диаграммой рассеяния).
Исходя из получившейся конфигурации точек, выбирается наиболее подходящий
вид параметрической функциональной зависимости f(x). На рисунке 1.3.1 приведен
пример поля корреляции для некоторой выборки объемом 11 наблюдений (каждому
наблюдению соответствует одна точка) с графиками двух функциональных
зависимостей - линейной функции и параболы.
Эмпирический метод состоит в следующем. Выбирается некоторая
параметрическая функциональная зависимость f(x) (см., например, 1.3.3-1.3.7).
Для построения по выборке оценки f'(x) этой зависимости чаще всего используется
метод наименьших квадратов (МНК).
Согласно методу наименьших квадратов значения параметров функции f'(x)
(будем обозначать их через a, b) выбираются таким образом, чтобы сумма
квадратов отклонений выборочных значений f(x) от значений f'() была минимальной
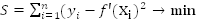 , (1.3.8)
, (1.3.8)
минимум ищется по параметрам a b , которые входят в зависимость f' (x).
Найденные значения параметров, которые минимизируют указанную сумму
квадратов разностей, называются оценками неизвестных параметров регрессии по методу
наименьших квадратов (оценками МНК). Выборочная регрессия y' = f '(x) (или ' = f'(), i = 1,K, n), в которую подставлены
найденные значения, уже не содержит неизвестных параметров и является оценкой
теоретической регрессии. Именно эту зависимость f'(x) будем рассматривать как
эмпирическую усредненную зависимость изучаемого показателя от объясняющего
фактора.
После нахождения эмпирического уравнения регрессии вычисляются значения
'= f'() и остатки 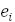 = −', i = 1, n . По величине n
остаточной суммы квадратов
= −', i = 1, n . По величине n
остаточной суммы квадратов
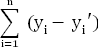
можно судить о качестве соответствия эмпирической функции f'(x) имеющимся
в наличии статистическим наблюдениям. Перебирая разные функциональные
зависимости и, каждый раз, действуя подобным образом можно практически
подобрать наиболее подходящую функцию для описания имеющихся данных.
Аналитический метод сводится к попытке выяснения содержательного смысла
зависимости изучаемого показателя от объясняющего фактора и последующего выбора
на этой основе соответствующей функциональной зависимости. Так, если y - расходы
фирмы, x - объем выпущенной продукции за месяц, то нетрудно получить следующую
модель зависимости расходов от объема выпущенной продукции:
y =α + β x+ε,
где α - условно-постоянные расходы, β x - условно-переменные расходы.
В практике эконометрического анализа часто используют линейную парную
регрессию. В модели парной линейной регрессии зависимость 1.3.1 между
переменными представляется в виде
y =α + β x +ε, (1.3.9)
т.е. теоретическая регрессия имеет вид 1.3.3.
На основе выборочных наблюдений оценка теоретической регрессии -
выборочная (эмпирическая) регрессия y строится в виде:
' = a + bx , (1.3.10)
где a,b являются оценками параметров α,β теоретической регрессии.
1.4
Оценка параметров. Метод наименьших квадратов
Рассматривается модель парной линейной регрессии
= α + β + 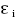 , i = 1, n .
, i = 1, n .
На основе эмпирических наблюдений построим оценку теоретической регрессии
- найдем выборочное уравнение регрессии
' = a + bx , i = 1, n .
Оценки a,b параметров α,β определяются по методу наименьших
квадратов из соотношения:
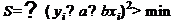
т.е. a, b выбираются таким образом, чтобы минимизировать сумму квадратов
отклонений выборочных (эмпирических) значений показателя от расчетных '.
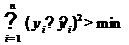
подставим в задачу формулу:
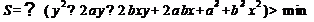
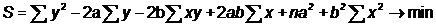
В данном случае у нас a и b - переменные, а х и у - параметры. Для
нахождения экстремума функции, возьмем частные производные по a и b и
приравняем их к нулю.
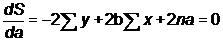

Получили систему из двух линейных уравнений. Разделим оба на 2n:
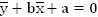
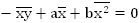
Из первого уравнения выразим неизвестную а:
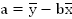
и подставим это выражение во второе уравнение:
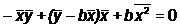
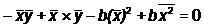
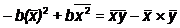
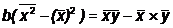
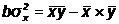
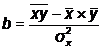
Построив оценки a и b коэффициентов и, мы можем рассчитать т. н.
"предсказанные", или "смоделированные" значения ŷi = a
+ bxi и их вероятностные характеристики - среднее арифметическое и дисперсию.
Несложно заметить, что оказалось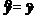 . Так должно быть всегда:
. Так должно быть всегда:
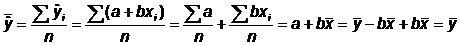
Кроме того, вычислим т. н. случайные остатки 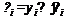 и рассчитаем их вероятностные
характеристики.
и рассчитаем их вероятностные
характеристики.
Оказалось,  . Это также закономерно:
. Это также закономерно:
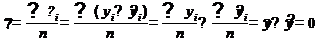
Таким образом, дисперсия случайных остатков будет равна:
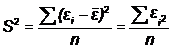
Мы произвели вычисления, и построили регрессионное уравнение, позволяющее
нам построить некую оценку переменной у (эту оценку мы обозначили ŷ).
Однако, если бы мы взяли другие данные, по другим областям (или за другой
период времени), то исходные, экспериментальные значения х и у у нас были бы
другими и, соответственно, а и b, скорее всего, получились бы иными.
1.5 Основные предположения регрессионного анализа
Основные предположения регрессионного анализа относятся к случайной
компоненте ε и имеют решающее значение для правильного и обоснованного
применения регрессионного анализа в эконометрических исследованиях.
В классической модели регрессионного анализа предполагаются выполненными
следующие предположения (условия Гаусса-Маркова):
Условие 1.5.1. Величины ε i являются случайными.
Условие 1.5.2. Математическое ожидание возмущений равно ну-
лю: E () = 0 .
Условие 1.5.3. Возмущения и ε j некоррелированы: E (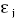 ) = 0 , i≠ j.
) = 0 , i≠ j.
Условие 1.5.4. Дисперсия возмущения постоянна для каждого i: D()
= σ 2. Это условие
называется условием гомоскедастичности. Нарушение этого условия называется
гетероскедастичностью.
Условие 1.5.5. Величины ε i взаимно независимы со значениями
объясняющих переменных.
Здесь, во всех условиях i = 1,2,K, n.
Эти предположения образуют первую группу предположений, необходимых для
проведения регрессионного анализа в рамках классической модели.
Вторая группа предположений дает достаточные условия для обоснованного
проведения проверки статистической значимости эмпирических регрессий:
Условие 1.5.6. Совместное распределение случайных величин 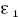 ,K,
,K, 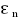 является нормальным.
является нормальным.
При выполнении предположений первой и второй групп случайные величины ,K, оказываются взаимно независимыми,
одинаково распределенными случайными величинами, подчиняющимися нормальному
распределению с нулевым математическим ожиданием и дисперсией σ2.
1.6 Характеристика оценок коэффициентов уравнения регрессии
) математическое ожидание
Теорема: М(а) = , M(b) = - несмещенность оценок
Это означает, что при увеличении количества наблюдений значения
МНК-оценок a и b будут приближаться к истинным значениям и ;
) дисперсия
Теорема:
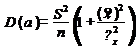 ;
; 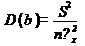
Благодаря этой теореме, мы можем получить представление о том, как
далеко, в среднем, наши оценки a и b находятся от истинных значений и.
Необходимо иметь в виду, что дисперсии характеризуют не отклонения, а
"отклонения в квадрате". Чтобы перейти к сопоставимым значениям,
рассчитаем стандартные отклонения a и b:
 ;
; 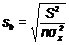
Будем называть эти величины стандартными ошибками a и b соответственно.
1.7
Построение доверительных интервалов
Пусть мы имеем оценку а. Реальное значение коэффициента уравнения
регрессии лежит где-то рядом, но где точно, мы узнать не можем. Однако, мы
можем построить интервал, в который это реальное значение попадет с некоторой
вероятностью. Доказано, что:
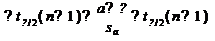
с вероятностью Р = 1 -
где/2(n-1) - /2-процентная точка распределения Стьюдента с (n-1)
степенями свободы - определяется из специальных таблиц.
При этом уровень значимости устанавливается произвольно.
Неравенство можно преобразовать следующим образом:
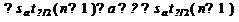
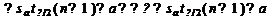
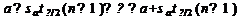 ,
,
или, что то же самое:
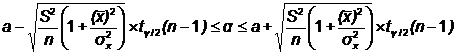
Аналогично, с вероятностью Р = 1 -:
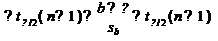
откуда следует:
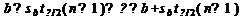 ,
,
или:
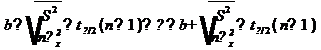
Уровень значимости - это вероятность того, что на самом деле истинные
значения и лежат за пределами построенных доверительных интервалов. Чем меньше
его значение, тем больше величина t/2(n-1), соответственно, тем шире будет
доверительный интервал.
1.8
Проверка статистической значимости коэффициентов регрессии
Мы получили МНК-оценки коэффициентов, рассчитали для них доверительные
интервалы. Однако мы не можем судить, не слишком ли широки эти интервалы, можно
ли вообще говорить о значимости коэффициентов регрессии.
Гипотеза Н0: предположим, что =0, т.е. на самом деле независимой
постоянной составляющей в отклике нет (альтернатива - гипотеза Н1: 0).
Для проверки этой гипотезы, с заданным уровнем значимости, рассчитывается
t-статистика, для парной регрессии:
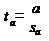
Значение t-статистики сравнивается с табличным значением t/2(n-1) -
/2-процентной точка распределения Стьюдента с (n-1) степенями свободы.
Если t < t/2(n-1) - гипотеза Н0 не отвергается (обратить внимание: не
"верна", а "не отвергается"), т.е. мы считаем, что с
вероятностью 1- можно утверждать, что = 0.
В противном случае гипотеза Н0 отвергается, принимается гипотеза Н1.
Аналогично для коэффициента b формулируем гипотезу Н0: = 0, т.е.
переменная, выбранная нами в качестве фактора, на самом деле никакого влияния на
отклик не оказывае.
Для проверки этой гипотезы, с заданным уровнем значимости ,
рассчитывается t-статистика:
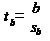
и сравнивается с табличным значением t/2(n-1).
Если t < t/2(n-1) - гипотеза Н0 не отвергается, т.е. мы считаем, что с
вероятностью 1- можно утверждать, что = 0.
В противном случае гипотеза Н0 отвергается, принимается гипотеза Н1.
1.9
Автокорреляция остатков
. Примеры автокорреляции.
Возможные причины:
) неверно выбрана функция регрессии;
) имеется неучтенная объясняющая переменная (переменные)
. Статистика Дарбина-Уотсона
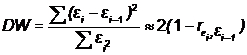
Очевидно: 0 DW 4
Если DW близко к нулю, это позволяет предполагать наличие положительной
автокорреляции, если близко к 4 - отрицательной.
Распределение DW зависит от наблюденных значений, поэтому получить
однозначный критерий, при выполнении которого DW считается "хорошим",
а при невыполнении - "плохим", нельзя. Однако, для различных величин
n и найдены верхние и нижние границы, DWL и DWU, которые в ряде случаев
позволяют с уверенностью судить о наличии (отсутствии) автокорреляции в модели.
Правило:
) При DW < 2:
а) если DW < DWL - делаем вывод о наличии положительной автокорреляции
(с вероятностью 1-);
б) если DW > DWU - делаем вывод об отсутствии автокорреляции (с
вероятностью 1-);
в) если DWL DW DWU - нельзя сделать никакого вывода;
) При DW > 2:
а) если (4 - DW) < DWL - делаем вывод о наличии отрицательной
автокорреляции (с вероятностью 1-);
б) если (4 - DW) > DWU - делаем вывод об отсутствии автокорреляции (с
вероятностью 1-);
в) если DWL (4 - DW) DWU - нельзя сделать никакого вывода;
1.10
Гетероскедастичность остатков
Возможные причины:
ошибки в исходных данных;
наличие закономерностей;
Обнаружение - возможны различные тесты. Наиболее простой:
(упрощенный тест Голдфелда-Куандта)
) упорядочиваем выборку по возрастанию одной из объясняющих переменных;
) формулируем гипотезу Н0: остатки гомоскедастичны
) делим выборку приблизительно на три части, выделяя k остатков,
соответствующих "маленьким" х и k остатков, соответствующих
"большим" х (kn/3);
) строим модели парной линейной регрессии отдельно для
"меньшей" и "большей" частей
) оцениваем дисперсии остатков в "меньшей" (s21) и
"большей" (s21) частях;
) рассчитываем дисперсионное соотношение:
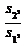
) определяем табличное значение F-статистики Фишера с (k-m-1) степенями
свободы числителя и (k - m - 1) степенями свободы знаменателя при заданном
уровне значимости
) если дисперсионное соотношение не превышает табличное значение
F-статистики (т.е., оно подчиняется F-распределению Фишера с (k-m-1) степенями
свободы числителя и (k - m - 1) степенями свободы знаменателя), то гипотеза Н0
не отвергается - делаем вывод о гомоскедастичности остатков. Иначе -
предполагаем их гетероскедатичность.
Метод устранения: взвешенный МНК.
Идея: если значения х оказывают какое-то воздействие на величину
остатков, то можно ввести в модель некие "весовые коэффициенты",
чтобы свести это влияние к нулю.
Например, если предположить, что величина остатка i пропорциональна
значению xi (т.е., дисперсия остатков пропорциональна xi2), то можно
перестроить модель следующим образом:
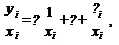
т.е. перейдем к модели наблюдений

Где

Таким образом, задача оценки параметров уравнения регрессии методом
наименьших квадратов сводится к минимизации функции:
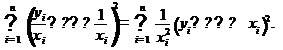
Или
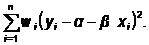
где 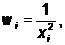 - весовой коэффициент.
- весовой коэффициент.
Выводы
Эконометрика - это наука, в рамках которой на базе реальных
статистических данных строятся, анализируются и совершенствуются математические
модели экономических явлений. Эконометрика позволяет найти количественное
подтверждение либо опровержение экономического закона, либо гипотезы. Одним из
важнейших направлений эконометрики является построение прогнозов по различным
экономическим показателям.
Модель парной линейной регрессии является наиболее распространенным (и
простым) уравнением зависимости между экономическими переменными. Метод
наименьших квадратов дает наилучшие (в определенном смысле) оценки параметров
регрессии. Решающее значение для правильного и обоснованного применения
регрессионного анализа в эконометрических исследованиях имеет выполнение
условий Гаусса-Маркова.
Необходимым элементом эконометрического анализа является проверка
статистической значимости полученных оценок коэффициентов, а также всего
уравнения регрессии в целом. В качестве показателя качества регрессии может
использоваться коэффициент детерминации.
При использовании парной линейной регрессии для построения прогнозов
необходимо учитывать доверительные интервалы прогноза и параметров регрессии.
2. Практическая часть
2.1
Задание 1
На основе данных 154 сельскохозяйственных предприятий Кемеровской области
2003 г. изучите зависимость рентабельность производства зерновых от урожайности
зерновых (табл. 13).
Задание:
. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
. Рассчитайте параметры уравнения регрессии (линейное,
полулогарифмическое, логарифмическое, полиномиальное).
. Оцените с помощью F-критерий Фишера статистическую надежность
результатов регрессионного моделирования. По значениям характеристик каждого
уравнения выберите лучшее уравнение и дайте обоснование.
. Интерпретируйте полученные результаты.
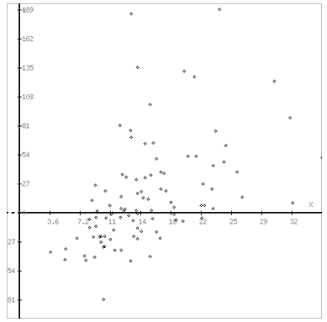
Рисунок 2. Поле корреляции
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между
изучаемыми экономическими показателями. Для этого в прямоугольной системе
координат строят график, по оси ординат откладывают индивидуальные значения
результативного признака Y, а по оси абсцисс - индивидуальные значения
факторного признака X.
Совокупность точек результативного и факторного признаков называется
полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной
совокупности) о том, что связь между всеми возможными значениями X и Y носит
линейный характер.
Линейное уравнение регрессии имеет вид
= bx + a
Оценочное уравнение регрессии (построенное по выборочным данным) будет
иметь вид
y = bx + a + ε,
где ei - наблюдаемые значения (оценки) ошибок εi,
а и b соответственно
оценки параметров α и β регрессионной модели, которые следует
найти.
Здесь ε - случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
. Невключение в регрессионную модель значимых объясняющих переменных;
. Агрегирование переменных. Например, функция суммарного потребления -
это попытка общего выражения совокупности решений отдельных индивидов о
расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные
параметры.
. Неправильное описание структуры модели;
. Неправильная функциональная спецификация;
. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i - случайны и их
значения в выборке неизвестны, то:
) по наблюдениям xi и yi можно получить только оценки параметров α
и β
) Оценками параметров α и β регрессионной модели являются
соответственно величины а и b, которые носят случайный характер, т.к.
соответствуют случайной выборке;
Для оценки параметров α и β - используют МНК (метод наименьших
квадратов).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и
несмещенные) оценки параметров уравнения регрессии. Но только в том случае,
если выполняются определенные предпосылки относительно случайного члена (ε)
и независимой переменной
(x).
Формально критерий МНК можно записать так:
= ∑(yi - y*i)2 → min
Система нормальных уравнений.
a•n + b∑x = ∑y∑x + b∑x2 = ∑y•x
Для наших данных система уравнений имеет вид
a + 1491.7 b = 1562.3
.7 a + 26193.35 b = 37818.86
Домножим уравнение (1) системы на (-15.07), получим систему, которую
решим методом алгебраического сложения.
-1491.7a -22479.92 b = -23543.86
.7 a + 26193.35 b = 37818.86
Получаем:
.43 b = 14275
Откуда b = 3.8415
Теперь найдем коэффициент "a" из уравнения (1):
a + 1491.7 b = 1562.3
a + 1491.7 • 3.8415 = 1562.3
a = -4168.13= -42.1024
Получаем эмпирические коэффициенты регрессии:
= 3.8415, a = -42.1024
Уравнение регрессии (эмпирическое уравнение регрессии):
= 3.8415 x + 42.1024
Эмпирические коэффициенты регрессии a и b являются лишь оценками
теоретических коэффициентов βi.
Само уравнение отражает лишь общую тенденцию в поведении рассматриваемых
переменных.
Для расчета параметров регрессии построим расчетную таблицу (табл. 1)
|
x
|
y
|
x2
|
y2
|
x • y
|
|
10
|
-31.6
|
100
|
998.56
|
-316
|
|
12.7
|
33.3
|
161.29
|
1108.89
|
422.91
|
|
18
|
10
|
324
|
100
|
180
|
|
14.5
|
-16.9
|
210.25
|
285.61
|
-245.05
|
|
11
|
0
|
121
|
0
|
0
|
|
8.3
|
-13.5
|
68.89
|
182.25
|
-112.05
|
|
11.2
|
-15.8
|
125.44
|
249.64
|
-176.96
|
|
16.8
|
22.2
|
282.24
|
492.84
|
372.96
|
|
10
|
-80.3
|
6448.09
|
-803
|
|
14.7
|
14.2
|
216.09
|
201.64
|
208.74
|
|
15.6
|
35.2
|
243.36
|
1239.04
|
549.12
|
|
9.2
|
1.6
|
84.64
|
2.56
|
14.72
|
|
12.5
|
3.6
|
156.25
|
12.96
|
45
|
|
8.8
|
-22.2
|
77.44
|
492.84
|
-195.36
|
|
14.9
|
64.6
|
222.01
|
4173.16
|
962.54
|
|
10.8
|
-24.9
|
116.64
|
620.01
|
-268.92
|
|
7.9
|
-44
|
62.41
|
1936
|
-347.6
|
|
23
|
4.2
|
529
|
17.64
|
96.6
|
|
10.7
|
6.8
|
114.49
|
46.24
|
72.76
|
|
21.8
|
26.8
|
475.24
|
718.24
|
584.24
|
|
14
|
18.5
|
196
|
342.25
|
259
|
|
18.6
|
-6.6
|
345.96
|
43.56
|
-122.76
|
|
13
|
-2.4
|
169
|
5.76
|
-31.2
|
|
11.3
|
-34.7
|
127.69
|
1204.09
|
-392.11
|
|
13.5
|
-7.1
|
182.25
|
50.41
|
-95.85
|
|
9.7
|
-21.7
|
94.09
|
470.89
|
-210.49
|
|
12.1
|
4
|
146.41
|
16
|
48.4
|
|
13.2
|
76.9
|
174.24
|
5913.61
|
1015.08
|
|
10.2
|
20.4
|
104.04
|
416.16
|
208.08
|
|
23.8
|
190.3
|
566.44
|
36214.09
|
4529.14
|
|
12.1
|
-34.8
|
146.41
|
1211.04
|
-421.08
|
|
32.2
|
88.6
|
1036.84
|
7849.96
|
2852.92
|
|
16.3
|
-17.6
|
265.69
|
309.76
|
-286.88
|
|
3.7
|
-36.7
|
13.69
|
1346.89
|
-135.79
|
|
19.6
|
132.4
|
384.16
|
17529.76
|
2595.04
|
|
15.3
|
13.2
|
234.09
|
174.24
|
201.96
|
|
13.3
|
186.1
|
176.89
|
34633.21
|
2475.13
|
|
14
|
-14.1
|
196
|
198.81
|
-197.4
|
|
13.9
|
2.6
|
193.21
|
6.76
|
36.14
|
|
9.2
|
0.7
|
84.64
|
0.49
|
6.44
|
|
15.5
|
-40.7
|
240.25
|
1656.49
|
-630.85
|
|
7.7
|
-40
|
59.29
|
1600
|
-308
|
|
20
|
53.1
|
400
|
2819.61
|
1062
|
|
25.9
|
38.4
|
670.81
|
1474.56
|
994.56
|
|
14.9
|
32.8
|
222.01
|
1075.84
|
488.72
|
|
17.4
|
20.7
|
302.76
|
428.49
|
360.18
|
|
10.9
|
-1
|
118.81
|
1
|
-10.9
|
|
36
|
51.6
|
1296
|
2662.56
|
1857.6
|
|
8.3
|
-5.6
|
68.89
|
31.36
|
-46.48
|
|
21.7
|
-4.6
|
470.89
|
21.16
|
-99.82
|
|
23.3
|
76.4
|
542.89
|
5836.96
|
1780.12
|
|
9.5
|
-22.4
|
90.25
|
501.76
|
-212.8
|
|
5.5
|
-33.3
|
30.25
|
1108.89
|
-183.15
|
|
14
|
135.8
|
196
|
18441.64
|
1901.2
|
|
24.5
|
62.8
|
600.25
|
3943.84
|
1538.6
|
|
10.3
|
-5
|
106.09
|
25
|
-51.5
|
|
12.1
|
15.4
|
146.41
|
237.16
|
186.34
|
|
16.8
|
38.1
|
282.24
|
1451.61
|
640.08
|
|
6.8
|
-23.7
|
46.24
|
561.69
|
-161.16
|
|
13.6
|
-21.9
|
184.96
|
479.61
|
-297.84
|
|
19.4
|
-7.7
|
376.36
|
59.29
|
-149.38
|
|
22.9
|
22.1
|
524.41
|
488.41
|
506.09
|
|
14
|
-24.3
|
196
|
590.49
|
-340.2
|
|
10.1
|
-21.5
|
102.01
|
462.25
|
-217.15
|
|
8.6
|
11.7
|
73.96
|
136.89
|
100.62
|
|
12.4
|
1.8
|
153.76
|
3.24
|
22.32
|
|
13.2
|
-44.8
|
174.24
|
2007.04
|
-591.36
|
|
22
|
7.1
|
484
|
50.41
|
156.2
|
|
20.8
|
127.2
|
432.64
|
16179.84
|
2645.76
|
|
26.5
|
14.6
|
702.25
|
213.16
|
386.9
|
|
15.8
|
-5.4
|
249.64
|
29.16
|
-85.32
|
|
21
|
52.9
|
441
|
2798.41
|
1110.9
|
|
18.4
|
5.3
|
338.56
|
28.09
|
97.52
|
|
15.5
|
101.3
|
240.25
|
10261.69
|
1570.15
|
|
14
|
-0.6
|
196
|
0.36
|
-8.4
|
|
16.7
|
-23.4
|
278.89
|
547.56
|
-390.78
|
|
9.1
|
-4.2
|
82.81
|
17.64
|
-38.22
|
|
13.3
|
70.5
|
176.89
|
4970.25
|
937.65
|
|
17.2
|
37.3
|
295.84
|
641.56
|
|
5.4
|
-43.7
|
29.16
|
1909.69
|
-235.98
|
|
12
|
-4.1
|
144
|
16.81
|
-49.2
|
|
15.7
|
2.2
|
246.49
|
4.84
|
34.54
|
|
23
|
44.4
|
529
|
1971.36
|
1021.2
|
|
10.1
|
-30.9
|
102.01
|
954.81
|
-312.09
|
|
30.3
|
123.2
|
918.09
|
15178.24
|
3732.96
|
|
24.3
|
47.9
|
590.49
|
2294.41
|
1163.97
|
|
14.5
|
20.1
|
210.25
|
404.01
|
291.45
|
|
21.6
|
7
|
466.56
|
49
|
151.2
|
|
32.5
|
9.4
|
1056.25
|
88.36
|
305.5
|
|
12.2
|
36
|
148.84
|
1296
|
439.2
|
|
16.3
|
50.7
|
265.69
|
2570.49
|
826.41
|
|
9
|
25.7
|
81
|
660.49
|
231.3
|
|
15.9
|
65.2
|
252.81
|
4251.04
|
1036.68
|
|
9.1
|
-12.5
|
82.81
|
156.25
|
-113.75
|
|
18.4
|
-1.3
|
338.56
|
1.69
|
-23.92
|
|
9.7
|
-27
|
94.09
|
729
|
-261.9
|
|
13.9
|
31.1
|
193.21
|
967.21
|
432.29
|
|
8.9
|
-41.1
|
79.21
|
1689.21
|
-365.79
|
|
11.9
|
81.9
|
141.61
|
6707.61
|
974.61
|
|
1491.7
|
1562.3
|
26193.35
|
253759.17
|
37818.86
|
. Параметры уравнения регрессии.
Выборочные средние.
EQ \x\to(x) = \f(∑i;n) = \f(1491.7;99) = 15.07\x\to(y)
= \f(∑i;n) = \f(1562.3;99) = 15.78\x\to(xy) = \f(∑ii;n) =
\f(37818.86;99) = 382.01
Выборочные дисперсии:
EQ S(x) = \f(∑2i;n) - \x\to(x) = \f(26193.35;99) -
15.07 = 37.54S(y) = \f(∑2i;n) - \x\to(y) = \f(253759.17;99) - 15.78 =
2314.19
Среднеквадратическое отклонение
S(x) = \r(S(x)) = \r(37.54) = 6.127S(y) = \r(S(y)) = \r(2314.19) = 48.106
Коэффициент корреляции b можно находить по формуле, не решая систему
непосредственно:
EQ b = \f(\x\to(x • y)-\x\to(x) • \x\to(y);S(x)) =
\f(382.01-15.07 • 15.78;37.54) = 3.8415
Коэффициент корреляции
Ковариация.
EQ cov(x,y) = \x\to(x • y) - \x\to(x) • \x\to(y) = 382.01 -
15.07 • 15.78 = 144.23
Рассчитываем показатель тесноты связи. Таким показателем является
выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
EQ r = \f(\x\to(x • y) -\x\to(x) • \x\to(y) ;S(x) • S(y)) =
\f(382.01 - 15.07 • 15.78;6.127 • 48.106) = 0.489
Линейный коэффициент корреляции принимает значения от -1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии
оцениваются по шкале Чеддока:
.1 < rxy < 0.3: слабая;
.3 < rxy < 0.5: умеренная;
.5 < rxy < 0.7: заметная;
.7 < rxy < 0.9: высокая;
.9 < rxy < 1: весьма высокая;
В нашем примере связь между признаком Y фактором X умеренная и прямая.
Кроме того, коэффициент линейной парной корреляции может быть определен
через коэффициент регрессии b:
EQ r = b\f(S(x);S(y)) = 3.84\f(6.127;48.106) = 0.489
Уравнение регрессии (оценка уравнения регрессии).
EQ y = r \f(x - \x\to(x);S(x)) S(y) + \x\to(y) = 0.489 \f(x -
15.07;6.127) 48.106 + 15.78 = 3.84x -42.1
Линейное уравнение регрессии имеет вид y = 3.84 x -42.1
Коэффициентам уравнения линейной регрессии можно придать экономический
смысл.
Коэффициент регрессии b = 3.84 показывает среднее изменение результативного
показателя (в единицах измерения у) с повышением или понижением величины
фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу
y повышается в среднем на 3.84.
Коэффициент a = -42.1 формально показывает прогнозируемый уровень у, но
только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений х, то буквальная
интерпретация может привести к неверным результатам, и даже если линия
регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий,
что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения х, можно
определить выровненные (предсказанные) значения результативного показателя y(x)
для каждого наблюдения.
Связь между у и х определяет знак коэффициента регрессии b (если > 0 -
прямая связь, иначе - обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для
непосредственной оценки влияния факторов на результативный признак в том
случае, если существует различие единиц измерения результативного показателя у
и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета -
коэффициенты.
Средний коэффициент эластичности E показывает, на сколько процентов в
среднем по совокупности изменится результат у от своей средней величины при
изменении фактора x на 1% от своего среднего значения.
Коэффициент эластичности находится по формуле:
EQ E = \f(∂y;∂x) \f(x;y) = b\f(\x\to(x);\x\to(y))
EQ E = 3.84\f(15.07;15.78) = 3.67
В нашем примере коэффициент эластичности больше 1. Следовательно, при
изменении Х на 1%, Y изменится более чем на 1%. Другими словами - Х существенно
влияет на Y.
Бета - коэффициент
Бета - коэффициент показывает, на какую часть величины своего среднего
квадратичного отклонения изменится в среднем значение результативного признака
при изменении факторного признака на величину его среднеквадратического
отклонения при фиксированном на постоянном уровне значении остальных
независимых переменных:
EQ β = b\f(S(x);S(y)) =
3.84\f(6.127;48.106) = 0.489
Т.е. увеличение x на величину среднеквадратического отклонения Sx
приведет к увеличению среднего значения Y на 48,9% среднеквадратичного
отклонения Sy.
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной
аппроксимации.
Средняя ошибка аппроксимации - среднее отклонение расчетных значений от
фактических:
\x\to(A) = \f(∑;n)100%
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе
уравнения регрессии к исходным данным.
\x\to(A) = \f(91.898;99) 100% = 92.83%
Поскольку ошибка больше 7%, то данное уравнение не желательно
использовать в качестве регрессии.
Эмпирическое корреляционное отношение.
Эмпирическое корреляционное отношение вычисляется для всех форм связи и
служит для измерение тесноты зависимости. Изменяется в пределах [0;1].
EQ η = \r(\f(∑x2; ∑i2) )
EQ η =
\r(\f(54852.006;229104.81)) = 0.489
Где EQ
(\x\to(y) - y) = 229104.81 - 174252.81 = 54852.006
Индекс корреляции.
Для линейной регрессии индекс корреляции равен коэффициенту корреляции
rxy = 0.489.
Полученная величина свидетельствует о том, что фактор x умеренно влияет
на y
Для любой формы зависимости теснота связи определяется с помощью
множественного коэффициента корреляции:
R = \r(1 - \f(∑ix2; ∑i2))
Данный коэффициент является универсальным, так как отражает тесноту связи
и точность модели, а также может использоваться при любой форме связи
переменных.
При построении однофакторной корреляционной модели коэффициент
множественной корреляции равен коэффициенту парной корреляции rxy.
В отличие от линейного коэффициента корреляции он характеризует тесноту
нелинейной связи и не характеризует ее направление.
Изменяется в пределах [0; 1].
Теоретическое корреляционное отношение для линейной связи равно
коэффициенту корреляции rxy.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом
детерминации, который показывает долю вариации результативного признака,
объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в
процентах.
= 0.4892 = 0.2394
т.е. в 23,94% случаев изменения х приводят к изменению y. Другими словами
- точность подбора уравнения регрессии - низкая.
Остальные 76,06% изменения Y объясняются факторами, не учтенными в модели
(а также ошибками спецификации).
Для оценки качества параметров регрессии построим расчетную таблицу
(табл. 2)
|
x
|
y
|
y(x)
|
(yi-ycp)2
|
(y-y(x))2
|
(xi-xcp)2
|
|y - yx|:y
|
|
10
|
-31.6
|
-3.69
|
2244.94
|
779.14
|
25.68
|
0
|
|
12.7
|
33.3
|
6.69
|
306.92
|
708.34
|
5.61
|
0.8
|
|
18
|
10
|
27.05
|
33.42
|
290.55
|
8.6
|
1.7
|
|
14.5
|
-16.9
|
13.6
|
1068.04
|
930.25
|
0.32
|
0
|
|
11
|
0
|
0.15
|
249.03
|
0.0239
|
16.55
|
0
|
|
8.3
|
-13.5
|
-10.22
|
857.37
|
10.77
|
45.8
|
0
|
|
11.2
|
-15.8
|
0.92
|
997.35
|
279.66
|
14.96
|
0
|
|
16.8
|
22.2
|
22.44
|
41.21
|
0.0555
|
3
|
0.0106
|
|
10
|
-80.3
|
-3.69
|
9231.52
|
5869.57
|
25.68
|
0
|
|
14.7
|
14.2
|
14.37
|
2.5
|
0.0283
|
0.14
|
0.0119
|
|
15.6
|
35.2
|
17.83
|
377.11
|
301.86
|
0.28
|
0.49
|
|
9.2
|
1.6
|
-6.76
|
201.1
|
69.89
|
34.43
|
5.23
|
|
12.5
|
3.6
|
5.92
|
148.37
|
5.37
|
6.59
|
0.64
|
|
8.8
|
-22.2
|
-8.3
|
1442.54
|
193.3
|
39.28
|
0
|
|
14.9
|
64.6
|
15.14
|
2383.31
|
2446.62
|
0.0281
|
0.77
|
|
10.8
|
-24.9
|
-0.61
|
1654.93
|
589.83
|
18.21
|
0
|
|
7.9
|
-44
|
-11.75
|
3573.75
|
1039.79
|
51.38
|
0
|
|
23
|
4.2
|
46.25
|
134.12
|
1768.47
|
62.92
|
10.01
|
|
10.7
|
6.8
|
-1
|
80.65
|
60.81
|
19.08
|
1.15
|
|
21.8
|
26.8
|
41.64
|
121.42
|
220.32
|
45.32
|
0.55
|
|
14
|
18.5
|
11.68
|
7.39
|
46.52
|
1.14
|
0.37
|
|
18.6
|
-6.6
|
29.35
|
500.9
|
1292.43
|
12.48
|
0
|
|
13
|
-2.4
|
7.84
|
330.54
|
104.81
|
4.28
|
0
|
|
11.3
|
-34.7
|
2548.31
|
1296.51
|
14.2
|
0
|
|
13.5
|
-7.1
|
9.76
|
523.53
|
284.21
|
2.46
|
0
|
|
9.7
|
-21.7
|
-4.84
|
1404.81
|
284.28
|
28.81
|
0
|
|
12.1
|
4
|
4.38
|
138.79
|
0.14
|
8.81
|
0.0951
|
|
13.2
|
76.9
|
8.61
|
3735.56
|
4664.06
|
3.49
|
0.89
|
|
10.2
|
20.4
|
-2.92
|
21.34
|
543.76
|
23.69
|
1.14
|
|
23.8
|
190.3
|
49.33
|
30456.95
|
19873.55
|
76.25
|
0.74
|
|
12.1
|
-34.8
|
4.38
|
2558.42
|
1535.1
|
8.81
|
0
|
|
32.2
|
88.6
|
81.6
|
5302.63
|
49.06
|
293.52
|
0.0791
|
|
16.3
|
-17.6
|
20.51
|
1114.28
|
1452.74
|
1.52
|
0
|
|
3.7
|
-36.7
|
-27.89
|
2754.24
|
77.64
|
129.22
|
0
|
|
19.6
|
132.4
|
33.19
|
13600.04
|
9842.24
|
20.54
|
0.75
|
|
15.3
|
13.2
|
16.67
|
6.66
|
12.06
|
0.054
|
0.26
|
|
13.3
|
186.1
|
8.99
|
29008.63
|
31367.88
|
3.12
|
0.95
|
|
14
|
-14.1
|
11.68
|
892.86
|
664.57
|
1.14
|
0
|
|
13.9
|
2.6
|
11.3
|
173.73
|
75.61
|
1.36
|
3.34
|
|
9.2
|
0.7
|
-6.76
|
227.43
|
55.65
|
34.43
|
10.66
|
|
15.5
|
-40.7
|
17.44
|
3190.08
|
3380.45
|
0.19
|
0
|
|
7.7
|
-40
|
-12.52
|
3111.5
|
755.02
|
54.28
|
0
|
|
20
|
53.1
|
34.73
|
1392.72
|
337.51
|
24.33
|
0.35
|
|
25.9
|
38.4
|
57.39
|
511.63
|
360.76
|
117.34
|
0.49
|
|
14.9
|
32.8
|
15.14
|
289.65
|
311.99
|
0.0281
|
0.54
|
|
17.4
|
20.7
|
24.74
|
24.2
|
16.33
|
5.44
|
0.2
|
|
10.9
|
-1
|
-0.23
|
281.6
|
0.59
|
17.37
|
0
|
|
36
|
51.6
|
96.19
|
1283.01
|
1988.56
|
438.16
|
0.86
|
|
8.3
|
-5.6
|
-10.22
|
457.14
|
21.32
|
45.8
|
0
|
|
21.7
|
-4.6
|
41.26
|
415.38
|
2103.06
|
43.99
|
0
|
|
23.3
|
76.4
|
47.41
|
3674.69
|
840.67
|
67.77
|
0.38
|
|
9.5
|
-22.4
|
-5.61
|
1457.77
|
281.98
|
31
|
0
|
|
5.5
|
-33.3
|
-20.97
|
2408.93
|
151.93
|
91.54
|
0
|
|
14
|
135.8
|
11.68
|
14404.61
|
15405.95
|
1.14
|
0.91
|
|
24.5
|
62.8
|
52.02
|
2210.8
|
116.31
|
88.97
|
0.17
|
|
10.3
|
-5
|
-2.53
|
431.84
|
6.08
|
22.73
|
0
|
|
12.1
|
15.4
|
4.38
|
0.15
|
121.43
|
8.81
|
0.72
|
|
16.8
|
38.1
|
22.44
|
498.15
|
245.37
|
3
|
0.41
|
|
6.8
|
-23.7
|
-15.98
|
1558.73
|
59.6
|
68.35
|
0
|
|
13.6
|
-21.9
|
10.14
|
1419.84
|
1026.73
|
2.15
|
0
|
|
19.4
|
-7.7
|
32.42
|
551.35
|
1609.91
|
18.77
|
0
|
|
22.9
|
22.1
|
45.87
|
39.93
|
564.97
|
61.35
|
1.08
|
|
14
|
-24.3
|
11.68
|
1606.47
|
1294.51
|
1.14
|
0
|
|
10.1
|
-21.5
|
-3.3
|
1389.86
|
331.14
|
24.68
|
0
|
|
8.6
|
11.7
|
-9.07
|
16.65
|
431.19
|
41.83
|
1.77
|
|
12.4
|
1.8
|
5.53
|
195.46
|
13.93
|
7.12
|
2.07
|
|
13.2
|
-44.8
|
8.61
|
3670.03
|
2852.21
|
3.49
|
0
|
|
22
|
7.1
|
42.41
|
75.36
|
1246.91
|
48.06
|
4.97
|
|
20.8
|
127.2
|
37.8
|
12414.24
|
7992.04
|
32.86
|
0.7
|
|
26.5
|
14.6
|
59.7
|
1.39
|
2033.88
|
130.7
|
3.09
|
|
15.8
|
-5.4
|
18.59
|
448.63
|
575.71
|
0.54
|
0
|
|
21
|
52.9
|
38.57
|
1377.83
|
205.35
|
35.19
|
0.27
|
|
18.4
|
5.3
|
28.58
|
109.85
|
542.06
|
11.1
|
4.39
|
|
15.5
|
101.3
|
17.44
|
7032.23
|
0.19
|
0.83
|
|
14
|
-0.6
|
11.68
|
268.33
|
150.78
|
1.14
|
0
|
|
16.7
|
-23.4
|
22.05
|
1535.14
|
2065.83
|
2.66
|
0
|
|
9.1
|
-4.2
|
-7.14
|
399.23
|
8.67
|
35.61
|
0
|
|
13.3
|
70.5
|
8.99
|
2994.19
|
3783.46
|
3.12
|
0.87
|
|
17.2
|
37.3
|
23.97
|
463.08
|
177.63
|
4.55
|
0.36
|
|
5.4
|
-43.7
|
-21.36
|
3537.97
|
499.16
|
93.46
|
0
|
|
12
|
-4.1
|
4
|
395.25
|
65.55
|
9.41
|
0
|
|
15.7
|
2.2
|
18.21
|
184.44
|
256.32
|
0.4
|
7.28
|
|
23
|
44.4
|
46.25
|
819.06
|
3.43
|
62.92
|
0.0417
|
|
10.1
|
-30.9
|
-3.3
|
2179.1
|
761.61
|
24.68
|
0
|
|
30.3
|
123.2
|
74.3
|
11538.88
|
2391.55
|
232.02
|
0.4
|
|
24.3
|
47.9
|
51.25
|
1031.64
|
11.2
|
85.24
|
0.0699
|
|
14.5
|
20.1
|
13.6
|
18.66
|
42.25
|
0.32
|
0.32
|
|
21.6
|
7
|
40.88
|
77.1
|
1147.52
|
42.67
|
4.84
|
|
32.5
|
9.4
|
82.75
|
40.71
|
5379.91
|
303.89
|
7.8
|
|
12.2
|
36
|
4.76
|
408.82
|
975.66
|
8.22
|
0.87
|
|
16.3
|
50.7
|
20.51
|
1219.35
|
911.14
|
1.52
|
0.6
|
|
9
|
25.7
|
-7.53
|
98.39
|
1104.13
|
36.82
|
1.29
|
|
15.9
|
65.2
|
18.98
|
2442.26
|
2136.45
|
0.69
|
0.71
|
|
9.1
|
-12.5
|
-7.14
|
799.8
|
28.68
|
35.61
|
0
|
|
18.4
|
-1.3
|
28.58
|
291.75
|
892.94
|
11.1
|
0
|
|
9.7
|
-27
|
-4.84
|
1830.2
|
491.09
|
28.81
|
0
|
|
13.9
|
31.1
|
11.3
|
234.68
|
392.23
|
1.36
|
0.64
|
|
8.9
|
-41.1
|
-7.91
|
3235.43
|
1101.4
|
38.04
|
0
|
|
11.9
|
81.9
|
3.61
|
4371.75
|
6129.01
|
10.03
|
0.96
|
|
1491.7
|
1562.3
|
1562.3
|
229104.81
|
174252.81
|
3716.9
|
91.9
|
. Оценка параметров уравнения регрессии.
Значимость коэффициента корреляции.
Выдвигаем гипотезы:: rxy = 0, нет линейной взаимосвязи между
переменными;: rxy ≠ 0, есть линейная взаимосвязь между переменными;
Для того чтобы при уровне значимости α проверить нулевую гипотезу о
равенстве нулю генерального коэффициента корреляции нормальной двумерной
случайной величины при конкурирующей гипотезе H1 ≠ 0, надо вычислить
наблюдаемое значение критерия (величина случайной ошибки)
t = r \f(\r(n-2);\r(1 - r))
и по таблице критических точек распределения Стьюдента, по заданному
уровню значимости α и числу степеней свободы k = n - 2 найти критическую
точку tкрит двусторонней критической области. Если tнабл < tкрит оснований
отвергнуть нулевую гипотезу. Если |tнабл| > tкрит - нулевую гипотезу
отвергают.
t = 0.489 \f(\r(97);\r(1 - 0.489)) = 5.53
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=97 находим
tкрит:
крит (n-m-1;α/2) = (97;0.025) = 1.984
где m = 1 - количество объясняющих переменных.
Если |tнабл| > tкритич, то полученное значение коэффициента корреляции
признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента
корреляции, отвергается). Поскольку |tнабл| > tкрит, то отклоняем гипотезу о
равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции
статистически - значим
Отметим значения на числовой оси.
|
Принятие H0
|
Отклонение H0, принятие H1
|
|
95%
|
5%
|
|
1.984
|
5.53
|
В парной линейной регрессии t2r = t2b и тогда проверка гипотез о
значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о
существенности линейного уравнения регрессии.
Интервальная оценка для коэффициента корреляции (доверительный интервал).
EQ (r - t \r(\f(1-r;n-2)); r + t \r(\f(1-r;n-2)))
Доверительный интервал для коэффициента корреляции.
(0.489 - 1.984\r(\f(1-0.489;99-2)); 0.489 +
1.984\r(\f(1-0.489;99-2)))(0.314;0.665)
Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
EQ S = \f(∑ix2;n - m - 1)S = \f(174252.81;97) =
1796.421
= 1796.421 - необъясненная дисперсия (мера разброса зависимой переменной
вокруг линии регрессии).
S = \r(S) = \r(1796.421) = 42.38
= 42.38 - стандартная ошибка оценки (стандартная ошибка регрессии).-
стандартное отклонение случайной величины a.
EQ S = S \f(\r( ∑2);n S(x))S = 42.38 \f(
\r(26193.35);99 • 6.127) = 11.31
- стандартное отклонение случайной величины b.
EQ S = \f(S;\r(n) S(x))S = \f( 42.38; \r(99) • 6.127) = 0.7
Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает,
что сохраняются ранее существовавшие взаимосвязи переменных и на период
упреждения. Для прогнозирования зависимой переменной результативного признака
необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные
прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
Где EQ ε = t S \r(\f(1;n) +
\f((\x\to(x)-x);∑i2))
tкрит (n-m-1;α/2) = (97;0.025) = 1.984
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных
значений Y при неограниченно большом числе наблюдений и Xp = 17
Вычислим ошибку прогноза для уравнения
= bx + a
EQ ε = 1.984 • 42.384
\r(\f(1;99) + \f((15.07 - 17);3716.9)) = 8.862(17) = 3.842*17 -42.102 = 23.204
.204 ± 8.862 (14.34;32.07)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно
большом числе наблюдений не выйдет за пределы найденных интервалов.
Вычислим ошибку прогноза для уравнения
y = bx + a + ε
EQ ε = t S \r(1 + \f(1;n) +
\f((\x\to(x)-x);∑i2))
EQ ε = 1.984 • 42.384 \r(1 +
\f(1;99) + \f((15.07 - 17);3716.9)) = 84.56
(-61.35;107.76)
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bxi ± ε)
Где EQ ε = t S \r(1 + \f(1;n) +
\f((\x\to(x)-x);∑i2 ))ε = 1.984 • 42.38 \r(1 + \f(1;99) +
\f((15.07 - x);3716.9))крит (n-m-1;α/2) = (97;0.025) = 1.984
|
xi
|
y = -42.1 + 3.84xi
|
εi
|
ymin
= y - εi
|
ymax
= y + εi
|
|
10
|
-3.69
|
84.8
|
-88.49
|
81.12
|
|
12.7
|
6.69
|
84.58
|
-77.89
|
91.26
|
|
18
|
27.05
|
84.61
|
-57.57
|
111.66
|
|
14.5
|
13.6
|
84.52
|
-70.92
|
98.12
|
|
11
|
0.15
|
84.7
|
-84.55
|
84.85
|
|
8.3
|
-10.22
|
85.03
|
-95.25
|
74.81
|
|
11.2
|
0.92
|
84.68
|
-83.76
|
85.61
|
|
16.8
|
22.44
|
84.55
|
-62.11
|
106.98
|
|
10
|
-3.69
|
84.8
|
-88.49
|
81.12
|
|
14.7
|
14.37
|
84.52
|
-70.15
|
98.88
|
|
15.6
|
17.83
|
84.52
|
-66.69
|
102.34
|
|
9.2
|
-6.76
|
84.9
|
-91.66
|
78.14
|
|
12.5
|
5.92
|
84.59
|
-78.67
|
90.51
|
|
8.8
|
-8.3
|
84.95
|
-93.25
|
76.66
|
|
14.9
|
15.14
|
84.51
|
-69.38
|
99.65
|
|
10.8
|
-0.61
|
84.72
|
-85.33
|
84.1
|
|
7.9
|
-11.75
|
85.09
|
-96.84
|
73.34
|
|
23
|
46.25
|
85.22
|
-38.97
|
131.47
|
|
10.7
|
-1
|
84.73
|
-85.73
|
83.73
|
|
21.8
|
41.64
|
85.02
|
-43.38
|
126.67
|
|
14
|
11.68
|
84.53
|
-72.85
|
96.21
|
|
18.6
|
29.35
|
84.65
|
114
|
|
13
|
7.84
|
84.56
|
-76.72
|
92.4
|
|
11.3
|
1.31
|
84.67
|
-83.37
|
85.98
|
|
13.5
|
9.76
|
84.54
|
-74.78
|
94.3
|
|
9.7
|
-4.84
|
84.84
|
-89.68
|
80
|
|
12.1
|
4.38
|
84.61
|
-80.23
|
88.99
|
|
13.2
|
8.61
|
84.55
|
-75.95
|
93.16
|
|
10.2
|
-2.92
|
84.78
|
-87.7
|
81.86
|
|
23.8
|
49.33
|
85.37
|
-36.04
|
134.69
|
|
12.1
|
4.38
|
84.61
|
-80.23
|
88.99
|
|
32.2
|
81.6
|
87.76
|
-6.16
|
169.35
|
|
16.3
|
20.51
|
84.53
|
-64.02
|
105.05
|
|
3.7
|
-27.89
|
85.96
|
-113.84
|
58.07
|
|
19.6
|
33.19
|
84.74
|
-51.55
|
117.94
|
|
15.3
|
16.67
|
84.51
|
-67.84
|
101.19
|
|
13.3
|
8.99
|
84.55
|
-75.56
|
93.54
|
|
14
|
11.68
|
84.53
|
-72.85
|
96.21
|
|
13.9
|
11.3
|
84.53
|
-73.23
|
95.82
|
|
9.2
|
-6.76
|
84.9
|
-91.66
|
78.14
|
|
15.5
|
17.44
|
84.52
|
-67.07
|
101.96
|
|
7.7
|
-12.52
|
85.12
|
-97.65
|
72.6
|
|
20
|
34.73
|
84.79
|
-50.06
|
119.52
|
|
25.9
|
57.39
|
85.82
|
-28.43
|
143.22
|
|
14.9
|
15.14
|
84.51
|
-69.38
|
99.65
|
|
17.4
|
24.74
|
84.58
|
-59.83
|
109.32
|
|
10.9
|
-0.23
|
84.71
|
-84.94
|
84.48
|
|
36
|
96.19
|
89.31
|
6.88
|
185.5
|
|
8.3
|
-10.22
|
85.03
|
-95.25
|
74.81
|
|
21.7
|
41.26
|
85.01
|
-43.75
|
126.27
|
|
23.3
|
47.41
|
85.27
|
-37.87
|
132.68
|
|
9.5
|
-5.61
|
84.86
|
-90.47
|
79.25
|
|
5.5
|
-20.97
|
85.54
|
-106.51
|
64.56
|
|
14
|
11.68
|
84.53
|
-72.85
|
96.21
|
|
24.5
|
52.02
|
85.51
|
-33.49
|
137.52
|
|
10.3
|
-2.53
|
84.77
|
-87.3
|
82.23
|
|
12.1
|
4.38
|
84.61
|
-80.23
|
88.99
|
|
16.8
|
22.44
|
84.55
|
-62.11
|
106.98
|
|
6.8
|
-15.98
|
85.28
|
-101.26
|
69.3
|
|
13.6
|
10.14
|
84.54
|
-74.4
|
94.68
|
|
19.4
|
32.42
|
84.72
|
-52.3
|
117.15
|
|
22.9
|
45.87
|
85.2
|
-39.33
|
131.07
|
|
14
|
11.68
|
84.53
|
-72.85
|
96.21
|
|
10.1
|
-3.3
|
84.79
|
-88.09
|
81.49
|
|
8.6
|
-9.07
|
84.98
|
-94.05
|
75.92
|
|
12.4
|
5.53
|
84.59
|
-79.06
|
90.13
|
|
13.2
|
8.61
|
84.55
|
-75.95
|
93.16
|
|
22
|
42.41
|
85.05
|
-42.64
|
127.46
|
|
20.8
|
37.8
|
84.88
|
-47.08
|
122.68
|
|
26.5
|
59.7
|
85.97
|
-26.27
|
145.67
|
|
15.8
|
18.59
|
84.52
|
-65.93
|
103.11
|
|
21
|
38.57
|
84.91
|
-46.34
|
123.48
|
|
18.4
|
28.58
|
84.64
|
-56.06
|
113.22
|
|
15.5
|
17.44
|
84.52
|
-67.07
|
101.96
|
|
14
|
11.68
|
84.53
|
-72.85
|
96.21
|
|
16.7
|
22.05
|
84.54
|
-62.49
|
106.6
|
|
9.1
|
-7.14
|
84.91
|
-92.06
|
77.77
|
|
13.3
|
8.99
|
84.55
|
-75.56
|
93.54
|
|
17.2
|
23.97
|
84.57
|
-60.59
|
108.54
|
|
5.4
|
-21.36
|
85.56
|
-106.92
|
64.2
|
|
12
|
4
|
84.62
|
-80.62
|
88.62
|
|
15.7
|
18.21
|
84.52
|
-66.31
|
102.73
|
|
23
|
46.25
|
85.22
|
-38.97
|
131.47
|
|
10.1
|
-3.3
|
84.79
|
-88.09
|
81.49
|
|
30.3
|
74.3
|
87.09
|
-12.79
|
161.38
|
|
24.3
|
51.25
|
85.47
|
-34.22
|
136.72
|
|
14.5
|
13.6
|
84.52
|
-70.92
|
98.12
|
|
21.6
|
40.88
|
84.99
|
-44.12
|
125.87
|
|
32.5
|
82.75
|
87.87
|
-5.12
|
170.62
|
|
12.2
|
4.76
|
84.61
|
-79.84
|
89.37
|
|
16.3
|
20.51
|
84.53
|
-64.02
|
105.05
|
|
9
|
-7.53
|
84.93
|
-92.46
|
|
15.9
|
18.98
|
84.52
|
-65.54
|
103.5
|
|
9.1
|
-7.14
|
84.91
|
-92.06
|
77.77
|
|
18.4
|
28.58
|
84.64
|
-56.06
|
113.22
|
|
9.7
|
-4.84
|
84.84
|
-89.68
|
80
|
|
13.9
|
11.3
|
84.53
|
-73.23
|
95.82
|
|
8.9
|
-7.91
|
84.94
|
-92.85
|
77.03
|
С вероятностью 95% можно гарантировать, что значения Y при неограниченно
большом числе наблюдений не выйдет за пределы найденных интервалов.
Проверка гипотез относительно коэффициентов линейного уравнения
регрессии.
) t-статистика. Критерий Стьюдента.
С помощью МНК мы получили лишь оценки параметров уравнения регрессии,
которые характерны для конкретного статистического наблюдения (конкретного
набора значений x и y).
Для оценки статистической значимости коэффициентов регрессии и корреляции
рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из
показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о
незначимом их отличии от нуля.
Чтобы проверить, значимы ли параметры, т.е. значимо ли они отличаются от
нуля для генеральной совокупности используют статистические методы проверки
гипотез.
В качестве основной (нулевой) гипотезы выдвигают гипотезу о незначимом
отличии от нуля параметра или статистической характеристики в генеральной
совокупности. Наряду с основной (проверяемой) гипотезой выдвигают
альтернативную (конкурирующую) гипотезу о неравенстве нулю параметра или
статистической характеристики в генеральной совокупности.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю
(при альтернативе H1 не равно) на уровне значимости α=0.05.: b = 0, то есть между переменными x
и y отсутствует линейная взаимосвязь в генеральной совокупности;: b ≠ 0,
то есть между переменными x и y есть линейная взаимосвязь в генеральной
совокупности.
В случае если основная гипотеза окажется неверной, мы принимаем альтернативную.
Для проверки этой гипотезы используется t-критерий Стьюдента.
Найденное по данным наблюдений значение t-критерия (его еще называют
наблюдаемым или фактическим) сравнивается с табличным (критическим) значением,
определяемым по таблицам распределения Стьюдента (которые обычно приводятся в
конце учебников и практикумов по статистике или эконометрике).
Табличное значение определяется в зависимости от уровня значимости (α)
и числа степеней
свободы, которое в случае линейной парной регрессии равно (n-2), n-число
наблюдений.
Если фактическое значение t-критерия больше табличного (по модулю), то
основную гипотезу отвергают и считают, что с вероятностью (1-α)
параметр или
статистическая характеристика в генеральной совокупности значимо отличается от
нуля.
Если фактическое значение t-критерия меньше табличного (по модулю), то
нет оснований отвергать основную гипотезу, т.е. параметр или статистическая
характеристика в генеральной совокупности незначимо отличается от нуля при
уровне значимости α.
tкрит (n-m-1;α/2) = (97;0.025) = 1.984t
= \f(b;S)
EQ t = \f(3.84;0.7) = 5.53
Отметим значения на числовой оси.
|
Отклонение H0, принятие H1
|
Принятие H0
|
Отклонение H0, принятие H1
|
|
2.5%
|
95%
|
2.5%
|
|
-1.984 1.984
|
5.53
|
Поскольку 5.53 > 1.984, то статистическая значимость коэффициента
регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого
коэффициента).
EQ t = \f(a;S)t = \f(-42.1;11.31) = 3.72
Поскольку 3.72 > 1.984, то статистическая значимость коэффициента
регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого
коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с
надежность 95% будут следующими:
(b - tкрит Sb; b + tкрит Sb)
(3.84 - 1.984 • 0.7; 3.84 + 1.984 • 0.7)
(2.462;5.221)
С вероятностью 95% можно утверждать, что значение данного параметра будут
лежать в найденном интервале.
(a - tкрит Sa; a + tкрит Sa)
(-42.102 - 1.984 • 11.31; -42.102 + 1.984 • 11.31) (-64.538;-19.667)
С вероятностью 95% можно утверждать, что значение данного параметра будут
лежать в найденном интервале.
) F-статистика. Критерий Фишера.
Коэффициент детерминации R2 используется для проверки существенности
уравнения линейной регрессии в целом.
Проверка значимости модели регрессии проводится с использованием
F-критерия Фишера, расчетное значение которого находится как отношение
дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки
дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше
табличного при заданном уровне значимости, то модель считается значимой.
EQ R = 1 - \f(∑ix2; ∑i2) = 1 - \f(174252.81;229104.81) =
0.2394
где m - число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится
по следующему алгоритму:
. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически
незначимо: H0: R2=0 на уровне значимости α.
. Далее определяют фактическое значение F-критерия:
EQ F = \f(R;1 - R)\f((n - m -1);m)
EQ F = \f(0.2394;1 - 0.2394)\f((99-1-1);1) = 30.53
Где=1 для парной регрессии.
. Табличное значение определяется по таблицам распределения Фишера для
заданного уровня значимости, принимая во внимание, что число степеней свободы
для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы
остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно
n-2.табл - это максимально возможное значение критерия под влиянием случайных
факторов при данных степенях свободы и уровне значимости α.
Уровень значимости α
- вероятность отвергнуть
правильную гипотезу при условии, что она верна.
Обычно α принимается равной 0,05 или 0,01.
. Если фактическое значение F-критерия меньше табличного, то говорят, что
нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α)
принимается
альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=97, Fтабл =
3.92
Отметим значения на числовой оси.
|
Принятие H0
|
Отклонение H0, принятие H1
|
|
95%
|
5%
|
|
3.92
|
30.53
|
Поскольку фактическое значение F > Fтабл, то коэффициент детерминации
статистически значим (найденная оценка уравнения регрессии статистически надежна).
Связь между F-критерием Фишера и t-статистикой Стьюдента выражается
равенством:
t = t = \r(F) = \r(30.53) = 5.53
Показатели качества уравнения регрессии.
|
Показатель
|
Значение
|
|
Коэффициент детерминации
|
0.24
|
|
Средний коэффициент
эластичности
|
3.67
|
|
Средняя ошибка
аппроксимации
|
92.83
|
2.2
Задание 2
Имеются данные о продаже трехкомнатных квартир на рынке жилья в Кемерово
на 24 августа 2004 года (табл. 12)
. Постройте матрицу парных коэффициентов корреляции.
. Постройте парные уравнения регрессии, оцените их статистическую
значимость и их параметров с помощью критериев Фишера и Стьюдента.
. Постройте модель формирования цены квартиры за счет значимых факторов.
. Существует ли разница в ценах квартир, расположенных в Центральном
районе и в периферийных районах Кемерово?- номер по порядку; price- цена
квартиры (тыс. руб.);- общая площадь квартиры (м2);- жилая площадь
квартиры (м2);- площадь кухни (m2);оог - этаж: 1 -
крайний этаж.
- средний этаж;- наличие балкона/лоджии:
- квартира с балконом/лоджией,
- квартира без балкона/лоджии,- квартира расположена в:
- Центральном р-не,
- Ленинском р-не,
- Заводском р-не.
Уравнение множественной регрессии может быть представлено в виде:
Y = f(β, X) + ε
где X = X(X1, X2, ..., Xm) - вектор независимых (объясняющих) переменных;
β
- вектор параметров
(подлежащих определению); ε - случайная ошибка (отклонение); Y -
зависимая (объясняемая) переменная.
Теоретическое линейное уравнение множественной регрессии имеет вид:
Y = β0 + β1X1 + β2X2
+ ... + βmXm + ε
β0 - свободный член, определяющий значение
Y, в случае, когда все объясняющие переменные Xj равны 0.
Прежде чем перейти к определению нахождения оценок коэффициентов
регрессии, необходимо проверить ряд предпосылок МНК.
Предпосылки МНК.
. Математическое ожидание случайного отклонения εi
равно 0 для всех
наблюдений (M(εi) = 0).
. Гомоскедастичность (постоянство дисперсий отклонений). Дисперсия
случайных отклонений εi постоянна: D(εi) = D(εj)
= S2 для любых i и j.
. отсутствие автокорреляции.
. Случайное отклонение должно быть независимо от объясняющих переменных:
Yeixi = 0.
. Модель является линейное относительно параметров.
. отсутствие мультиколлинеарности. Между объясняющими переменными
отсутствует строгая (сильная) линейная зависимость.
. Ошибки εi имеют нормальное распределение. Выполнимость данной
предпосылки важна для проверки статистических гипотез и построения
доверительных интервалов.
Эмпирическое уравнение множественной регрессии представим в виде:
Y = b0 + b1X1 + b1X1 + ... + bmXm + e
Здесь b0, b1, ..., bm - оценки теоретических значений β0,
β1, β2, ..., βm коэффициентов регрессии (эмпирические коэффициенты регрессии); e - оценка
отклонения ε.
При выполнении предпосылок МНК относительно ошибок εi,
оценки b0, b1, ..., bm
параметров β0, β1, β2, ..., βm множественной линейной регрессии по
МНК являются несмещенными, эффективными и состоятельными (т.е. BLUE-оценками).
Для оценки параметров уравнения множественной регрессии применяют МНК.
. Оценка уравнения регрессии.
Определим вектор оценок коэффициентов регрессии. Согласно методу
наименьших квадратов, вектор s получается из выражения: s = (XTX)-1XTY
К матрице с переменными Xj добавляем единичный столбец:
|
1
|
62
|
41
|
6
|
0
|
1
|
1
|
|
1
|
86
|
54
|
10
|
0
|
1
|
1
|
|
1
|
60
|
45
|
6
|
1
|
0
|
1
|
|
1
|
58
|
44
|
6
|
1
|
0
|
1
|
|
1
|
59
|
43
|
6
|
1
|
0
|
1
|
|
1
|
57
|
43
|
6
|
0
|
1
|
1
|
|
1
|
60
|
42
|
6
|
0
|
0
|
1
|
|
1
|
80
|
50
|
9
|
1
|
0
|
1
|
|
1
|
60
|
42
|
6
|
0
|
0
|
1
|
|
1
|
57
|
39
|
6
|
1
|
1
|
1
|
|
1
|
64
|
39
|
9
|
0
|
1
|
1
|
|
1
|
61
|
43
|
6
|
1
|
0
|
1
|
|
1
|
58
|
43
|
6
|
1
|
0
|
1
|
|
1
|
58
|
43
|
6
|
1
|
0
|
1
|
|
1
|
60
|
51
|
7
|
0
|
0
|
1
|
|
1
|
88
|
54
|
10
|
1
|
1
|
1
|
|
1
|
78
|
54
|
12
|
0
|
1
|
1
|
|
1
|
87
|
57
|
12
|
1
|
0
|
1
|
|
1
|
80
|
52
|
9
|
1
|
0
|
1
|
|
1
|
55
|
40
|
6
|
1
|
0
|
1
|
|
1
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
47
|
34
|
6
|
1
|
0
|
1
|
|
1
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
48
|
34
|
6
|
1
|
0
|
1
|
|
1
|
62
|
45
|
6
|
1
|
0
|
1
|
|
1
|
58
|
40
|
6
|
1
|
1
|
1
|
|
1
|
56
|
40
|
6
|
1
|
0
|
1
|
|
1
|
54
|
40
|
6
|
1
|
0
|
1
|
|
1
|
57
|
41
|
6
|
0
|
1
|
1
|
|
1
|
74
|
48
|
9
|
1
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
47
|
33
|
6
|
0
|
1
|
2
|
|
1
|
38
|
27
|
6
|
0
|
1
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
60
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
61
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
1
|
2
|
|
1
|
62
|
43
|
7
|
0
|
1
|
2
|
|
1
|
69
|
47
|
9
|
0
|
1
|
1
|
|
1
|
61
|
43
|
7
|
1
|
0
|
2
|
|
1
|
64
|
43
|
7
|
0
|
0
|
2
|
|
1
|
70
|
48
|
9
|
0
|
1
|
2
|
|
1
|
95
|
51
|
1
|
0
|
0
|
2
|
|
1
|
62
|
43
|
8
|
0
|
1
|
2
|
|
1
|
63
|
43
|
7
|
0
|
1
|
2
|
|
1
|
63
|
39
|
9
|
0
|
1
|
2
|
|
1
|
74
|
48
|
7
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
80
|
50
|
12
|
0
|
1
|
2
|
|
1
|
63
|
39
|
9
|
1
|
1
|
2
|
|
1
|
62
|
39
|
9
|
1
|
0
|
2
|
|
1
|
62
|
39
|
9
|
0
|
0
|
2
|
|
1
|
65
|
40
|
9
|
0
|
0
|
2
|
|
1
|
66
|
39
|
9
|
1
|
1
|
3
|
|
1
|
85
|
59
|
9
|
0
|
1
|
3
|
|
1
|
82
|
50
|
11
|
0
|
0
|
3
|
|
1
|
65
|
47
|
10
|
0
|
1
|
3
|
|
1
|
64
|
47
|
8
|
0
|
1
|
3
|
|
1
|
100
|
66
|
9
|
0
|
1
|
3
|
|
1
|
80
|
52
|
10
|
0
|
1
|
3
|
|
1
|
47
|
34
|
6
|
1
|
0
|
3
|
|
1
|
48
|
33
|
6
|
1
|
0
|
3
|
|
1
|
67
|
43
|
6
|
0
|
1
|
3
|
|
1
|
57
|
41
|
7
|
0
|
1
|
3
|
|
1
|
61
|
38
|
9
|
0
|
1
|
3
|
|
1
|
53
|
35
|
6
|
1
|
0
|
3
|
|
1
|
66
|
44
|
9
|
1
|
0
|
3
|
|
1
|
57
|
43
|
6
|
1
|
0
|
3
|
|
1
|
65
|
39
|
9
|
0
|
0
|
3
|
|
1
|
90
|
60
|
7
|
0
|
1
|
3
|
|
1
|
65
|
45
|
6
|
0
|
1
|
3
|
|
1
|
74
|
36
|
9
|
1
|
0
|
3
|
|
1
|
760
|
56
|
6
|
1
|
0
|
3
|
|
1
|
60
|
43
|
6
|
1
|
0
|
3
|
|
1
|
74
|
45
|
7
|
1
|
3
|
|
1
|
80
|
50
|
9
|
1
|
0
|
3
|
|
1
|
59
|
46
|
6
|
0
|
1
|
3
|
|
1
|
59
|
37
|
8
|
1
|
0
|
3
|
|
1
|
59
|
37
|
9
|
1
|
0
|
3
|
|
1
|
45
|
33
|
6
|
1
|
0
|
3
|
Матрица Y
|
820
|
|
2310
|
|
1550
|
|
1530
|
|
1600
|
|
870
|
|
870
|
|
1440
|
|
1100
|
|
730
|
|
1020
|
|
800
|
|
800
|
|
750
|
|
850
|
|
1350
|
|
1350
|
|
1350
|
|
2460
|
|
1000
|
|
830
|
|
820
|
|
820
|
|
930
|
|
820
|
|
1100
|
|
870
|
|
800
|
|
980
|
|
870
|
|
870
|
|
800
|
|
790
|
|
700
|
|
740
|
|
820
|
|
830
|
|
870
|
|
850
|
|
790
|
|
990
|
|
820
|
|
980
|
|
980
|
|
1200
|
|
1130
|
|
1070
|
|
3960
|
|
860
|
|
1100
|
|
1250
|
|
910
|
|
850
|
|
900
|
|
1400
|
|
950
|
|
960
|
|
1600
|
|
1300
|
|
1150
|
|
980
|
|
1000
|
|
820
|
|
800
|
|
1250
|
|
1120
|
|
660
|
|
680
|
|
790
|
|
800
|
|
920
|
|
630
|
|
800
|
|
720
|
|
900
|
|
970
|
|
780
|
|
850
|
|
79
|
|
1200
|
|
610
|
|
670
|
|
630
|
|
700
|
|
710
|
|
520
|
Делаем матрицу XT, а затем перемножаем матрицы, (XTX)
|
86
|
6192
|
3751
|
625
|
51
|
36
|
168
|
|
6192
|
936314
|
284459
|
45032
|
3828
|
2360
|
12952
|
|
3751
|
284459
|
167493
|
27630
|
2165
|
1595
|
7358
|
|
625
|
45032
|
27630
|
4827
|
351
|
282
|
1240
|
|
51
|
3828
|
2165
|
351
|
51
|
10
|
95
|
|
36
|
2360
|
1595
|
282
|
10
|
36
|
71
|
|
168
|
12952
|
7358
|
1240
|
95
|
71
|
386
|
В матрице, (XTX) число 86, лежащее на пересечении 1-й строки и 1-го
столбца, получено как сумма произведений элементов 1-й строки матрицы XT и 1-го
столбца матрицы X
Умножаем матрицы, (XTY)
|
86399
|
|
5812150
|
|
3854104
|
|
630254
|
|
47509
|
|
35500
|
|
160167
|
Находим обратную матрицу (XTX)-1
|
0.77
|
0.000291
|
-0.0123
|
-0.0112
|
-0.11
|
-0.0512
|
-0.0363
|
|
0.000291
|
2.0E-6
|
-1.1E-5
|
1.3E-5
|
-4.2E-5
|
6.0E-6
|
-3.8E-5
|
|
-0.0123
|
-1.1E-5
|
0.000347
|
-0.000425
|
0.000918
|
0.000377
|
0.000183
|
|
-0.0112
|
1.3E-5
|
-0.000425
|
0.00444
|
0.000859
|
-0.00316
|
-0.00132
|
|
-0.11
|
-4.2E-5
|
0.000918
|
0.000859
|
0.0735
|
0.0373
|
0.0053
|
|
-0.0512
|
6.0E-6
|
0.000377
|
-0.00316
|
0.0373
|
0.0706
|
0.00292
|
|
-0.0363
|
-3.8E-5
|
0.000183
|
-0.00132
|
0.0053
|
0.00292
|
0.0186
|
Вектор оценок коэффициентов регрессии равен
(X) = (XTX)-1XTY =
|
569.36
|
|
-1.39
|
|
27.81
|
|
-20.91
|
|
-246.78
|
|
-188.75
|
|
-153.7
|
Уравнение регрессии (оценка уравнения регрессии)
= 569.36-1.39X1 + 27.81X2-20.91X3-246.78X4-188.75X5-153.7X6
. Матрица парных коэффициентов корреляции R.
Число наблюдений n = 86.
Число независимых переменных в модели равно 6, а число регрессоров с
учетом единичного вектора равно числу неизвестных коэффициентов.
С учетом признака Y, размерность матрицы становится равным 8.
Матрица, независимых переменных Х имеет размерность (86 х 8).
Матрица, составленная из Y и X
|
1
|
820
|
62
|
41
|
6
|
0
|
1
|
1
|
|
1
|
2310
|
86
|
54
|
10
|
0
|
1
|
1
|
|
1
|
1550
|
60
|
45
|
6
|
1
|
0
|
1
|
|
1
|
1530
|
58
|
44
|
6
|
1
|
0
|
1
|
|
1
|
1600
|
59
|
43
|
6
|
1
|
0
|
1
|
|
1
|
870
|
57
|
43
|
6
|
0
|
1
|
1
|
|
1
|
870
|
60
|
42
|
6
|
0
|
0
|
1
|
|
1
|
1440
|
80
|
50
|
9
|
1
|
0
|
1
|
|
1
|
1100
|
60
|
42
|
6
|
0
|
0
|
1
|
|
1
|
730
|
57
|
39
|
6
|
1
|
1
|
1
|
|
1
|
1020
|
64
|
39
|
9
|
0
|
1
|
1
|
|
1
|
800
|
61
|
43
|
6
|
1
|
0
|
1
|
|
1
|
800
|
58
|
43
|
6
|
0
|
1
|
|
1
|
750
|
58
|
43
|
6
|
1
|
0
|
1
|
|
1
|
850
|
60
|
51
|
7
|
0
|
0
|
1
|
|
1
|
1350
|
88
|
54
|
10
|
1
|
1
|
1
|
|
1
|
1350
|
78
|
54
|
12
|
0
|
1
|
1
|
|
1
|
1350
|
87
|
57
|
12
|
1
|
0
|
1
|
|
1
|
2460
|
80
|
52
|
9
|
1
|
0
|
1
|
|
1
|
1000
|
55
|
40
|
6
|
1
|
0
|
1
|
|
1
|
830
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
820
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
820
|
47
|
34
|
6
|
1
|
0
|
1
|
|
1
|
930
|
47
|
34
|
6
|
1
|
1
|
1
|
|
1
|
820
|
48
|
34
|
6
|
1
|
0
|
1
|
|
1
|
1100
|
62
|
45
|
6
|
1
|
0
|
1
|
|
1
|
870
|
58
|
40
|
6
|
1
|
1
|
1
|
|
1
|
800
|
56
|
40
|
6
|
1
|
0
|
1
|
|
1
|
980
|
54
|
40
|
6
|
1
|
0
|
1
|
|
1
|
870
|
57
|
41
|
6
|
0
|
1
|
1
|
|
1
|
870
|
74
|
48
|
9
|
1
|
1
|
2
|
|
1
|
800
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
790
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
700
|
47
|
33
|
6
|
0
|
1
|
2
|
|
1
|
740
|
38
|
27
|
6
|
0
|
1
|
2
|
|
1
|
820
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
830
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
870
|
60
|
45
|
6
|
1
|
0
|
2
|
|
1
|
850
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
790
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
990
|
61
|
45
|
6
|
1
|
0
|
2
|
|
1
|
820
|
62
|
45
|
6
|
1
|
1
|
2
|
|
1
|
980
|
62
|
43
|
7
|
0
|
1
|
2
|
|
1
|
980
|
69
|
47
|
9
|
0
|
1
|
1
|
|
1
|
1200
|
61
|
43
|
7
|
1
|
0
|
2
|
|
1
|
1130
|
64
|
43
|
7
|
0
|
0
|
2
|
|
1
|
1070
|
70
|
48
|
9
|
0
|
1
|
2
|
|
1
|
3960
|
95
|
51
|
1
|
0
|
0
|
2
|
|
1
|
860
|
62
|
43
|
8
|
0
|
1
|
2
|
|
1
|
1100
|
63
|
43
|
7
|
0
|
1
|
2
|
|
1
|
1250
|
63
|
39
|
9
|
0
|
1
|
2
|
|
1
|
910
|
74
|
48
|
7
|
1
|
0
|
2
|
|
1
|
850
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
900
|
62
|
45
|
6
|
1
|
0
|
2
|
|
1
|
1400
|
80
|
50
|
12
|
0
|
1
|
2
|
|
1
|
950
|
63
|
39
|
9
|
1
|
1
|
2
|
|
1
|
960
|
62
|
39
|
1
|
0
|
2
|
|
1
|
1600
|
62
|
39
|
9
|
0
|
0
|
2
|
|
1
|
1300
|
65
|
40
|
9
|
0
|
0
|
2
|
|
1
|
1150
|
66
|
39
|
9
|
1
|
1
|
3
|
|
1
|
980
|
85
|
59
|
9
|
0
|
1
|
3
|
|
1
|
1000
|
82
|
50
|
11
|
0
|
0
|
3
|
|
1
|
820
|
65
|
47
|
10
|
0
|
1
|
3
|
|
1
|
800
|
64
|
47
|
8
|
0
|
1
|
3
|
|
1
|
1250
|
100
|
66
|
9
|
0
|
1
|
3
|
|
1
|
1120
|
80
|
52
|
10
|
0
|
1
|
3
|
|
1
|
660
|
47
|
34
|
6
|
1
|
0
|
3
|
|
1
|
680
|
48
|
33
|
6
|
1
|
0
|
3
|
|
1
|
790
|
67
|
43
|
6
|
0
|
1
|
3
|
|
1
|
800
|
57
|
41
|
7
|
0
|
1
|
3
|
|
1
|
920
|
61
|
38
|
9
|
0
|
1
|
3
|
|
1
|
630
|
53
|
35
|
6
|
1
|
0
|
3
|
|
1
|
800
|
66
|
44
|
9
|
1
|
0
|
3
|
|
1
|
720
|
57
|
43
|
6
|
1
|
0
|
3
|
|
1
|
900
|
65
|
39
|
9
|
0
|
0
|
3
|
|
1
|
970
|
90
|
60
|
7
|
0
|
1
|
3
|
|
1
|
780
|
65
|
45
|
6
|
0
|
1
|
3
|
|
1
|
850
|
74
|
36
|
9
|
1
|
0
|
3
|
|
1
|
79
|
760
|
56
|
6
|
1
|
0
|
3
|
|
1
|
1200
|
60
|
43
|
6
|
1
|
0
|
3
|
|
1
|
610
|
74
|
45
|
7
|
1
|
0
|
3
|
|
1
|
670
|
80
|
50
|
9
|
1
|
0
|
3
|
|
1
|
630
|
59
|
46
|
6
|
0
|
1
|
3
|
|
1
|
700
|
59
|
37
|
8
|
1
|
0
|
3
|
|
1
|
710
|
59
|
37
|
9
|
1
|
0
|
3
|
|
1
|
520
|
45
|
33
|
6
|
1
|
0
|
3
|
Транспонированная матрица (приведена частично)
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
820
|
2310
|
1550
|
1530
|
1600
|
870
|
870
|
1440
|
1100
|
730
|
1020
|
800
|
800
|
750
|
850
|
1350
|
1350
|
1350
|
2460
|
1000
|
830
|
820
|
820
|
930
|
820
|
1100
|
|
62
|
86
|
60
|
58
|
59
|
57
|
60
|
80
|
60
|
57
|
64
|
61
|
58
|
58
|
60
|
88
|
78
|
87
|
80
|
55
|
47
|
47
|
47
|
47
|
48
|
62
|
|
41
|
54
|
45
|
44
|
43
|
43
|
42
|
50
|
42
|
39
|
39
|
43
|
43
|
43
|
51
|
54
|
54
|
57
|
52
|
40
|
34
|
34
|
34
|
34
|
34
|
45
|
|
6
|
10
|
6
|
6
|
6
|
6
|
6
|
9
|
6
|
6
|
6
|
6
|
6
|
7
|
10
|
12
|
12
|
9
|
6
|
6
|
6
|
6
|
6
|
6
|
6
|
|
0
|
0
|
1
|
1
|
1
|
0
|
0
|
1
|
0
|
1
|
0
|
1
|
1
|
1
|
0
|
1
|
0
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
1
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
1
|
1
|
0
|
1
|
0
|
0
|
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
Матрица ATA
|
86
|
86399
|
6192
|
3751
|
625
|
51
|
36
|
168
|
|
86399
|
105195241
|
5812150
|
3854104
|
630254
|
47509
|
35500
|
160167
|
|
6192
|
5812150
|
936314
|
284459
|
45032
|
3828
|
2360
|
12952
|
|
3751
|
3854104
|
284459
|
167493
|
27630
|
2165
|
1595
|
7358
|
|
625
|
630254
|
45032
|
27630
|
4827
|
351
|
282
|
1240
|
|
51
|
47509
|
3828
|
2165
|
351
|
51
|
10
|
95
|
|
36
|
35500
|
2360
|
1595
|
282
|
10
|
36
|
71
|
|
168
|
160167
|
12952
|
7358
|
1240
|
95
|
71
|
386
|
Полученная матрица имеет следующее соответствие:
|
∑n
|
∑y
|
∑x1
|
∑x2
|
∑x3
|
∑x4
|
∑x5
|
∑x6
|
|
∑y
|
∑y2
|
∑x1 y
|
∑x2 y
|
∑x3 y
|
∑x4 y
|
∑x5 y
|
∑x6 y
|
|
∑x1
|
∑yx1
|
∑x1 2
|
∑x2 x1
|
∑x3 x1
|
∑x4 x1
|
∑x5 x1
|
∑x6 x1
|
|
∑x2
|
∑yx2
|
∑x1 x2
|
∑x2 2
|
∑x3 x2
|
∑x4 x2
|
∑x5 x2
|
∑x6 x2
|
|
∑x3
|
∑yx3
|
∑x1 x3
|
∑x2 x3
|
∑x3 2
|
∑x4 x3
|
∑x5 x3
|
∑x6 x3
|
|
∑x4
|
∑yx4
|
∑x1 x4
|
∑x2 x4
|
∑x3 x4
|
∑x4 2
|
∑x5 x4
|
∑x6 x4
|
|
∑x5
|
∑yx5
|
∑x1 x5
|
∑x2 x5
|
∑x3 x5
|
∑x4 x5
|
∑x5 2
|
∑x6 x5
|
|
∑x6
|
∑yx6
|
∑x1 x6
|
∑x2 x6
|
∑x3 x6
|
∑x4 x6
|
∑x5 x6
|
∑x6 2
|
Найдем парные коэффициенты корреляции.
EQ rxy = \f(\x\to(x • y) -\x\to(x) • \x\to(y) ;s(x) • s(y))
EQ ryx1 = \f(67583.14 - 72 • 1004.64;75.52 • 462.49) =
-0.136ryx2 = \f(44815.16 - 43.62 • 1004.64;6.72 • 462.49) = 0.32ryx3 = \f(7328.53 - 7.27 •
1004.64;1.82 • 462.49) = 0.0325
EQ ryx4 = \f(552.43 - 0.59 • 1004.64;0.49 • 462.49) =
-0.191ryx5 = \f(412.79 - 0.42 • 1004.64;0.49 • 462.49) = -0.034ryx6 = \f(1862.41 - 1.95 •
1004.64;0.82 • 462.49) = -0.264rx1 x2 = \f(3307.66 - 43.62 • 72;6.72 • 75.52) =
0.329rx1 x3 = \f(523.63 - 7.27 • 72;1.82 • 75.52) = 0.00271rx1 x4 = \f(44.51 -
0.59 • 72;0.49 • 75.52) = 0.0489rx1 x5 = \f(27.44 - 0.42 • 72;0.49 • 75.52) =
-0.0724
EQ rx1 x6 = \f(150.6 - 1.95 • 72;0.82 • 75.52) = 0.161rx2 x3
= \f(321.28 - 7.27 • 43.62;1.82 • 6.72) = 0.351
EQ rx2 x4 = \f(25.17 - 0.59 • 43.62;0.49 • 6.72) = -0.209rx2 x5 =
\f(18.55 - 0.42 • 43.62;0.49 • 6.72) = 0.087rx2 x6 = \f(85.56 - 1.95 •
43.62;0.82 • 6.72) = 0.0643rx3 x4 = \f(4.08 - 0.59 • 7.27;0.49 • 1.82) =
-0.255rx3 x5 = \f(3.28 - 0.42 • 7.27;0.49 • 1.82) = 0.264rx3 x6 = \f(14.42 -
1.95 • 7.27;0.82 • 1.82) = 0.149rx4 x5 = \f(0.12 - 0.42 • 0.59;0.49 • 0.49) =
-0.544rx4 x6 = \f(1.1 - 1.95 • 0.59;0.82 • 0.49) = -0.134rx5 x6 = \f(0.83 -
1.95 • 0.42;0.82 • 0.49) = 0.0194
|
Признаки x и y
|
∑xi
|
EQ \x\to(x) =
\f(∑xi;n)
|
∑yi
|
EQ \x\to(y) =
\f(∑yi;n)
|
∑xiyi
|
EQ \x\to(xy) =
\f(∑xi yi;n)
|
|
Для y и x1
|
6192
|
72
|
86399
|
1004.64
|
5812150
|
67583.14
|
|
Для y и x2
|
3751
|
43.616
|
86399
|
1004.64
|
3854104
|
44815.163
|
|
Для y и x3
|
625
|
7.267
|
86399
|
1004.64
|
630254
|
7328.535
|
|
Для y и x4
|
51
|
0.593
|
86399
|
1004.64
|
47509
|
552.43
|
|
Для y и x5
|
36
|
0.419
|
86399
|
1004.64
|
35500
|
412.791
|
|
Для y и x6
|
168
|
1.953
|
86399
|
1004.64
|
160167
|
1862.407
|
|
Для x1 и x2
|
3751
|
43.616
|
6192
|
72
|
284459
|
3307.663
|
|
Для x1 и x3
|
625
|
7.267
|
6192
|
72
|
45032
|
523.628
|
|
Для x1 и x4
|
51
|
0.593
|
6192
|
72
|
3828
|
44.512
|
|
Для x1 и x5
|
36
|
0.419
|
6192
|
72
|
2360
|
27.442
|
|
Для x1 и x6
|
168
|
1.953
|
6192
|
72
|
12952
|
150.605
|
|
Для x2 и x3
|
625
|
7.267
|
3751
|
43.616
|
27630
|
321.279
|
|
Для x2 и x4
|
51
|
0.593
|
3751
|
43.616
|
2165
|
25.174
|
|
Для x2 и x5
|
36
|
0.419
|
3751
|
43.616
|
1595
|
18.547
|
|
Для x2 и x6
|
168
|
1.953
|
3751
|
43.616
|
7358
|
85.558
|
|
Для x3 и x4
|
51
|
0.593
|
625
|
7.267
|
351
|
4.081
|
|
Для x3 и x5
|
36
|
625
|
7.267
|
282
|
3.279
|
|
Для x3 и x6
|
168
|
1.953
|
625
|
7.267
|
1240
|
14.419
|
|
Для x4 и x5
|
36
|
0.419
|
51
|
0.593
|
10
|
0.116
|
|
Для x4 и x6
|
168
|
1.953
|
51
|
0.593
|
95
|
1.105
|
|
Для x5 и x6
|
168
|
1.953
|
36
|
0.419
|
71
|
0.826
|
|
Признаки x и y
|
EQ D(x) = \f(∑x2i;n)
- \x\to(x)2
|
EQ D(y) = \f(∑y2i;n)
- \x\to(x)2
|
EQ s(x) = \r(D(x))
|
EQ s(y) = \r(D(y))
|
|
Для y и x1
|
5703.372
|
213899.882
|
75.521
|
462.493
|
|
Для y и x2
|
45.213
|
213899.882
|
6.724
|
462.493
|
|
Для y и x3
|
3.312
|
213899.882
|
1.82
|
462.493
|
|
Для y и x4
|
0.241
|
213899.882
|
0.491
|
462.493
|
|
Для y и x5
|
0.243
|
213899.882
|
0.493
|
462.493
|
|
Для y и x6
|
0.672
|
213899.882
|
0.82
|
462.493
|
|
Для x1 и x2
|
45.213
|
5703.372
|
6.724
|
75.521
|
|
Для x1 и x3
|
3.312
|
5703.372
|
1.82
|
75.521
|
|
Для x1 и x4
|
0.241
|
5703.372
|
0.491
|
75.521
|
|
Для x1 и x5
|
0.243
|
5703.372
|
0.493
|
75.521
|
|
Для x1 и x6
|
0.672
|
5703.372
|
0.82
|
75.521
|
|
Для x2 и x3
|
3.312
|
45.213
|
1.82
|
6.724
|
|
Для x2 и x4
|
0.241
|
45.213
|
0.491
|
6.724
|
|
Для x2 и x5
|
0.243
|
45.213
|
0.493
|
6.724
|
|
Для x2 и x6
|
0.672
|
45.213
|
0.82
|
6.724
|
|
Для x3 и x4
|
0.241
|
3.312
|
0.491
|
1.82
|
|
Для x3 и x5
|
0.243
|
3.312
|
0.493
|
1.82
|
|
Для x3 и x6
|
0.672
|
3.312
|
0.82
|
1.82
|
|
Для x4 и x5
|
0.243
|
0.241
|
0.493
|
0.491
|
|
Для x4 и x6
|
0.672
|
0.241
|
0.82
|
0.491
|
|
Для x5 и x6
|
0.672
|
0.243
|
0.82
|
0.493
|
Матрица парных коэффициентов корреляции R:
|
-
|
y
|
x1
|
x2
|
x3
|
x4
|
x5
|
x6
|
|
y
|
1
|
-0.136
|
0.32
|
0.0325
|
-0.191
|
-0.034
|
-0.264
|
|
x1
|
-0.136
|
1
|
0.329
|
0.00271
|
0.0489
|
-0.0724
|
0.161
|
|
x2
|
0.32
|
0.329
|
1
|
0.351
|
-0.209
|
0.087
|
0.0643
|
|
x3
|
0.0325
|
0.00271
|
0.351
|
1
|
-0.255
|
0.264
|
0.149
|
|
x4
|
-0.191
|
0.0489
|
-0.209
|
-0.255
|
1
|
-0.544
|
-0.134
|
|
x5
|
-0.034
|
-0.0724
|
0.087
|
0.264
|
-0.544
|
1
|
0.0194
|
|
x6
|
-0.264
|
0.161
|
0.0643
|
0.149
|
-0.134
|
0.0194
|
1
|
Коллинеарность - зависимость между факторами. В качестве критерия
мультиколлинеарности может быть принято соблюдение следующих неравенств:
(xjy) > r(xkxj); r(xky) > r(xkxj).
Если одно из неравенств не соблюдается, то исключается тот параметр xk
или xj, связь которого с результативным показателем Y оказывается наименее
тесной.
Для отбора наиболее значимых факторов xi учитываются следующие условия:
связь между результативным признаком и факторным должна быть выше
межфакторной связи;
связь между факторами должна быть не более 0.7. Если в матрице есть
межфакторный коэффициент корреляции rxjxi > 0.7, то в данной модели
множественной регрессии существует мультиколлинеарность.;
при высокой межфакторной связи признака отбираются факторы с меньшим
коэффициентом корреляции между ними.
Если факторные переменные связаны строгой функциональной зависимостью, то
говорят о полной мультиколлинеарности. В этом случае среди столбцов матрицы
факторных переменных Х имеются линейно зависимые столбцы, и, по свойству
определителей матрицы, det(XTX = 0).
Вид мультиколлинеарности, при котором факторные переменные связаны
некоторой стохастической зависимостью, называется частичной. Если между
факторными переменными имеется высокая степень корреляции, то матрица (XTX)
близка к вырожденной, т. е. det(XTX ≧ 0) (чем ближе к 0 определитель
матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и
ненадежнее результаты множественной регрессии).
В нашем случае все парные коэффициенты корреляции |r|<0.7, что говорит
об отсутствии мультиколлинеарности факторов.
Анализ первой строки этой матрицы позволяет произвести отбор факторных
признаков, которые могут быть включены в модель множественной корреляционной
зависимости. Факторные признаки, у которых |ryxi| < 0.5 исключают из модели.
Можно дать следующую качественную интерпретацию возможных значений коэффициента
корреляции (по шкале Чеддока): если |r|>0.3 - связь практически отсутствует;
0.3 ≤ |r| ≤ 0.7 - связь средняя; 0.7 ≤ |r| ≤ 0.9 -
связь сильная; |r| > 0.9 - связь весьма сильная.
Проверим значимость полученных парных коэффициентов корреляции с помощью
t-критерия Стьюдента. Коэффициенты, для которых значения t-статистики по модулю
больше найденного критического значения, считаются значимыми.
Рассчитаем наблюдаемые значения t-статистики для ryx1 по формуле:
tнабл = ryx1 \f(\r(n-m-1);\r(1 - ryx1 2))
где m = 1 - количество факторов в уравнении регрессии.
tнабл = 0.14 \f(\r(86 - 1 - 1);\r(1 - 0.142)) = 1.26
По таблице Стьюдента находим Tтабл
крит(n-m-1;α/2) = (84;0.025) = 1.984
Поскольку tнабл < tкрит, то принимаем гипотезу о равенстве 0 коэффициента
корреляции. Другими словами, коэффициент корреляции статистически - не значим
Рассчитаем наблюдаемые значения t-статистики для ryx2 по формуле:
tнабл = 0.32 \f(\r(86 - 1 - 1);\r(1 - 0.322)) = 3.1
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0
коэффициента корреляции. Другими словами, коэффициент корреляции статистически
- значим
Рассчитаем наблюдаемые значения t-статистики для ryx3 по формуле:
tнабл = 0.0325 \f(\r(86 - 1 - 1);\r(1 - 0.03252)) = 0.3
Поскольку tнабл < tкрит, то принимаем гипотезу о равенстве 0
коэффициента корреляции. Другими словами, коэффициент корреляции статистически
- не значим
Рассчитаем наблюдаемые значения t-статистики для ryx4 по формуле:
tнабл = 0.19 \f(\r(86 - 1 - 1);\r(1 - 0.192)) = 1.78
Поскольку tнабл < tкрит, то принимаем гипотезу о равенстве 0
коэффициента корреляции. Другими словами, коэффициент корреляции статистически
- не значим
Рассчитаем наблюдаемые значения t-статистики для ryx5 по формуле:
EQ tнабл = 0.034 \f(\r(86 - 1 - 1);\r(1 - 0.0342)) = 0.31
Поскольку tнабл < tкрит, то принимаем гипотезу о равенстве 0
коэффициента корреляции. Другими словами, коэффициент корреляции статистически
- не значим
Рассчитаем наблюдаемые значения t-статистики для ryx6 по формуле:
tнабл = 0.26 \f(\r(86 - 1 - 1);\r(1 - 0.262)) = 2.51
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0
коэффициента корреляции. Другими словами, коэффициент корреляции статистически
- значим
Таким образом, связь между (y и xx2 ), (y и xx6 ) является существенной,
т.е. цена квартир зависит от жилой площади и расположения в центре или на
окраине.
Наибольшее влияние на результативный признак оказывает фактор x2 (r =
0.32), значит, при построении модели он войдет в регрессионное уравнение
первым.
Тестирование и устранение мультиколлинеарности.
Наиболее полным алгоритмом исследования мультиколлинеарности является
алгоритм Фаррара-Глобера. С его помощью тестируют три вида
мультиколлинеарности:
. Всех факторов (χ2 - хи-квадрат).
. Каждого фактора с остальными (критерий Фишера).
. Каждой пары факторов (критерий Стьюдента).
Проверим переменные на мультиколлинеарность методом Фаррара-Глоубера по
первому виду статистических критериев (критерий "хи-квадрат").
Формула для расчета значения статистики Фаррара-Глоубера:
χ2 = -[n-1-(2m+5)/6]ln(det[R])
где m = 6 - количество факторов, n = 86 - количество наблюдений, det[R] -
определитель матрицы парных коэффициентов корреляции R.
Сравниваем его с табличным значением при v = m/2(m-1) = 15 степенях
свободы и уровне значимости α. Если χ2 >
χтабл2, то в
векторе факторов есть присутствует мультиколлинеарность.
χтабл2(15;0.05) = 24.99579
Проверим переменные на мультиколлинеарность по второму виду
статистических критериев (критерий Фишера).
Определяем обратную матрицу D = R-1:
|
1.4
|
0.32
|
-0.57
|
0.12
|
0.37
|
0.28
|
0.38
|
|
0.32
|
1.26
|
-0.59
|
0.18
|
-0.0505
|
0.0819
|
-0.12
|
|
-0.57
|
-0.59
|
1.58
|
-0.49
|
0.11
|
-0.00659
|
-0.0676
|
|
0.12
|
0.18
|
-0.49
|
1.27
|
0.0963
|
-0.22
|
-0.14
|
|
0.37
|
-0.0505
|
0.11
|
0.0963
|
1.62
|
0.85
|
0.28
|
|
0.28
|
0.0819
|
-0.00659
|
-0.22
|
0.85
|
1.53
|
0.18
|
|
0.38
|
-0.12
|
-0.0676
|
-0.14
|
0.28
|
0.18
|
1.18
|
Вычисляем F-критерии Фишера:
EQ Fk = (dkk-1)\f(n-m;m-1)
где dkk - диагональные элементы матрицы.
Рассчитанные значения критериев сравниваются с табличными при v1=n-m и
v2=m-1 степенях свободы и уровне значимости α. Если Fk > FТабл, то k-я переменная
мультиколлинеарна с другими.=86-6 = 80; v2=6-1 = 5. FТабл(80;5) = 4.4
EQ F1 = (1.402-1)\f(86-6;6-1) = 6.43
оскольку F1 > Fтабл, то переменная y мультиколлинеарна с другими.
F2 = (1.264-1)\f(86-6;6-1) = 4.23
Поскольку F2 ≤ Fтабл, то переменная x1 немультиколлинеарна с
другими.
F3 = (1.578-1)\f(86-6;6-1) = 9.25
Поскольку F3 > Fтабл, то переменная x2 мультиколлинеарна с другими.
F4 = (1.273-1)\f(86-6;6-1) = 4.37
Поскольку F4 ≤ Fтабл, то переменная x3 немультиколлинеарна с
другими.
F5 = (1.622-1)\f(86-6;6-1) = 9.95
Поскольку F5 > Fтабл, то переменная x4 мультиколлинеарна с другими.
F6 = (1.535-1)\f(86-6;6-1) = 8.55
Поскольку F6 > Fтабл, то переменная x5 мультиколлинеарна с другими.
F7 = (1.179-1)\f(86-6;6-1) = 2.86
Поскольку F7 ≤ Fтабл, то переменная x6 немультиколлинеарна с
другими.
Проверим переменные на мультиколлинеарность по третьему виду
статистических критериев (критерий Стьюдента). Для этого найдем частные
коэффициенты корреляции.
Частные коэффициенты корреляции.
Коэффициент частной корреляции отличается от простого коэффициента
линейной парной корреляции тем, что он измеряет парную корреляцию
соответствующих признаков (y и xi) при условии, что влияние на них остальных
факторов (xj) устранено.
На основании частных коэффициентов можно сделать вывод об обоснованности
включения переменных в регрессионную модель. Если значение коэффициента мало
или он незначим, то это означает, что связь между данным фактором и
результативной переменной либо очень слаба, либо вовсе отсутствует, поэтому фактор
можно исключить из модели.
Можно сделать вывод, что при построении регрессионного уравнения следует
отобрать факторы x2, x6.
Модель регрессии в стандартном масштабе.
Модель регрессии в стандартном масштабе предполагает, что все значения
исследуемых признаков переводятся в стандарты (стандартизованные значения) по
формулам:
EQ tj = \f(xji-\x\to(xj);S(xj))
где хji - значение переменной хji в i-ом наблюдении.
EQ ty = \f(yi-\x\to(xj);S(y))
Таким образом, начало отсчета каждой стандартизованной переменной
совмещается с ее средним значением, а в качестве единицы изменения принимается
ее среднее квадратическое отклонение S.
Если связь между переменными в естественном масштабе линейная, то
изменение начала отсчета и единицы измерения этого свойства не нарушат, так что
и стандартизованные переменные будут связаны линейным соотношением:
= ∑βjtxj
Для оценки β-коэффциентов применим МНК. При этом система нормальных
уравнений будет иметь вид:
rx1y=β1+rx1x2•β2 + ... +
rx1xm•βm
rx2y=rx2x1•β1 + β2 + ...
+ rx2xm•βm
...
rxmy=rxmx1•β1 + rxmx2•β2
+ ... + βm
Для наших данных (берем из матрицы парных коэффициентов корреляции):
-0.136 = β1 + 0.329β2 +
0.00271β3 + 0.0489β4 -0.0724β5 + 0.161β6
0.32 = 0.329β1 + β2 +
0.351β3 -0.209β4 + 0.087β5 + 0.0643β6
0.0325 = 0.00271β1 + 0.351β2
+ β3 -0.255β4 + 0.264β5 + 0.149β6
-0.191 = 0.0489β1
-0.209β2 -0.255β3 + β4 -0.544β5 -0.134β6
-0.034 = -0.0724β1 +
0.087β2 + 0.264β3 -0.544β4 + β5 + 0.0194β6
.264 = 0.161β1 + 0.0643β2 + 0.149β3
-0.134β4 + 0.0194β5 + β6
Данную систему линейных уравнений решаем методом Гаусса:
β1 = -0.227; β2 = 0.404;
β3 = -0.0823; β4 = -0.262; β5 = -0.201; β6 = -0.272;
= -0.227x1 + 0.404x2 -0.0823x3 -0.262x4 -0.201x5 -0.272x6
Найденные из данной системы β-коэффициенты позволяют определить
значения коэффициентов в регрессии в естественном масштабе по формулам:
EQ bj = β\f(S(y);S(xj))
EQ a = \x\to(y) - ∑bj\x\to(xj)
. Анализ параметров уравнения регрессии.
Перейдем к статистическому анализу полученного уравнения регрессии:
проверке значимости уравнения и его коэффициентов, исследованию абсолютных и
относительных ошибок аппроксимации
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка ε = Y - Y(x) = Y - X*s (абсолютная ошибка аппроксимации)
|
Y
|
Y(x)
|
ε
= Y - Y(x)
|
ε2
|
(Y-Yср)2
|
|ε
: Y|
|
|
820
|
1155.44
|
-335.44
|
112522.19
|
34091.76
|
0.41
|
|
2310
|
1399.96
|
910.04
|
828169.83
|
1703965.94
|
0.39
|
|
1550
|
1211.43
|
338.57
|
114632.45
|
297418.04
|
0.22
|
|
1530
|
1186.4
|
343.6
|
118063.12
|
276003.62
|
0.22
|
|
1600
|
1157.2
|
442.8
|
196073.44
|
354454.08
|
0.28
|
|
870
|
1218.01
|
-348.01
|
121111.13
|
18127.8
|
0.4
|
|
870
|
1374.78
|
-504.78
|
254804.7
|
18127.8
|
0.58
|
|
1440
|
1259.94
|
180.06
|
32420.46
|
189538.73
|
0.13
|
|
1100
|
1374.78
|
-274.78
|
75505.06
|
9093.62
|
0.25
|
|
730
|
859.99
|
-129.99
|
16898.14
|
75426.87
|
0.18
|
|
1020
|
1034.32
|
-14.32
|
204.98
|
235.94
|
0.014
|
|
800
|
1154.42
|
-354.42
|
125612.42
|
41877.34
|
0.44
|
|
800
|
1158.59
|
-358.59
|
128585.41
|
41877.34
|
0.45
|
|
750
|
1158.59
|
-408.59
|
166944.22
|
64841.29
|
0.54
|
|
850
|
1604.15
|
-754.15
|
568743.99
|
23913.39
|
0.89
|
|
1350
|
1150.4
|
199.6
|
39840.33
|
119273.85
|
0.15
|
|
1350
|
1369.26
|
-19.26
|
371.01
|
119273.85
|
0.0143
|
|
1350
|
1382.15
|
-32.15
|
1033.4
|
119273.85
|
0.0238
|
|
2460
|
1315.56
|
1144.44
|
1309741.25
|
2118074.08
|
0.47
|
|
1000
|
1079.33
|
-79.33
|
6293.47
|
21.53
|
0.0793
|
|
830
|
734.85
|
95.15
|
9053.93
|
30498.97
|
0.11
|
|
820
|
734.85
|
85.15
|
7250.89
|
34091.76
|
0.1
|
|
820
|
923.6
|
-103.6
|
10732.52
|
34091.76
|
0.13
|
|
930
|
734.85
|
195.15
|
38084.36
|
5571.06
|
0.21
|
|
820
|
922.21
|
-102.21
|
10446.47
|
34091.76
|
0.12
|
|
1100
|
1208.65
|
-108.65
|
11803.97
|
9093.62
|
0.0988
|
|
870
|
886.41
|
-16.41
|
269.35
|
18127.8
|
0.0189
|
|
800
|
1077.94
|
-277.94
|
77251.5
|
41877.34
|
0.35
|
|
980
|
1080.72
|
-100.72
|
10144.78
|
607.11
|
0.1
|
|
870
|
1162.39
|
-292.39
|
85493.49
|
18127.8
|
0.34
|
|
870
|
870.22
|
-0.22
|
0.0466
|
18127.8
|
0.000248
|
|
800
|
1054.95
|
-254.95
|
64997.95
|
41877.34
|
0.32
|
|
790
|
1054.95
|
-264.95
|
70196.88
|
46070.13
|
0.34
|
|
700
|
800.12
|
-100.12
|
10024.46
|
92805.25
|
0.14
|
|
740
|
645.78
|
94.22
|
8877.68
|
70034.08
|
0.13
|
|
820
|
1054.95
|
-234.95
|
55200.07
|
34091.76
|
0.29
|
|
830
|
1054.95
|
-224.95
|
50601.13
|
30498.97
|
0.27
|
|
870
|
1057.73
|
-187.73
|
35241.32
|
18127.8
|
0.22
|
|
850
|
1054.95
|
-204.95
|
42003.25
|
23913.39
|
0.24
|
|
790
|
1054.95
|
-264.95
|
70196.88
|
46070.13
|
0.34
|
|
990
|
1056.34
|
-66.34
|
4400.58
|
214.32
|
0.067
|
|
820
|
866.2
|
-46.2
|
2134.16
|
34091.76
|
0.0563
|
|
980
|
1036.45
|
-56.45
|
3186.84
|
607.11
|
0.0576
|
|
980
|
1249.84
|
-269.84
|
72812.48
|
607.11
|
0.28
|
|
1200
|
979.81
|
220.19
|
48483.78
|
38165.71
|
0.18
|
|
1130
|
1222.42
|
-92.42
|
8541.89
|
15715.25
|
0.0818
|
|
1070
|
1122.56
|
-52.56
|
2762.31
|
4271.99
|
0.0491
|
|
3960
|
1527.26
|
2432.74
|
5918205.83
|
8734155.48
|
0.61
|
|
860
|
1015.54
|
-155.54
|
24193.46
|
20920.6
|
0.18
|
|
1100
|
1035.06
|
64.94
|
4216.92
|
9093.62
|
0.059
|
|
1250
|
882.01
|
367.99
|
135418.2
|
60201.76
|
0.29
|
|
910
|
1100.79
|
-190.79
|
36398.93
|
8956.64
|
0.21
|
|
850
|
1054.95
|
-204.95
|
42003.25
|
23913.39
|
0.24
|
|
900
|
1054.95
|
-154.95
|
24008.56
|
10949.43
|
0.17
|
|
1400
|
1101.55
|
298.45
|
89073.89
|
156309.9
|
0.21
|
|
950
|
635.23
|
314.77
|
99082.93
|
2985.48
|
0.33
|
825.37
|
134.63
|
18126.45
|
1992.69
|
0.14
|
|
1600
|
1072.15
|
527.85
|
278627.96
|
354454.08
|
0.33
|
|
1300
|
1095.79
|
204.21
|
41702.99
|
87237.8
|
0.16
|
|
1150
|
477.36
|
672.64
|
452448.88
|
21129.66
|
0.58
|
|
980
|
1253.91
|
-273.91
|
75024.89
|
607.11
|
0.28
|
|
1000
|
1154.73
|
-154.73
|
23940.82
|
21.53
|
0.15
|
|
820
|
927.09
|
-107.09
|
11468.17
|
34091.76
|
0.13
|
|
800
|
970.3
|
-170.3
|
29001.63
|
41877.34
|
0.21
|
|
1250
|
1427.72
|
-177.72
|
31584.34
|
60201.76
|
0.14
|
|
1120
|
1045.29
|
74.71
|
5582.31
|
13308.04
|
0.0667
|
|
660
|
616.2
|
43.8
|
1918.48
|
118776.41
|
0.0664
|
|
680
|
587
|
93
|
8648.82
|
105390.83
|
0.14
|
|
790
|
896.71
|
-106.71
|
11387.69
|
46070.13
|
0.14
|
|
800
|
834.08
|
-34.08
|
1161.78
|
41877.34
|
0.0426
|
|
920
|
703.28
|
216.72
|
46967.67
|
7163.85
|
0.24
|
|
630
|
635.67
|
-5.67
|
32.14
|
140354.78
|
0.009
|
|
800
|
805.15
|
-5.15
|
26.53
|
41877.34
|
0.00644
|
|
720
|
852.58
|
-132.58
|
17577.38
|
81019.66
|
0.18
|
|
900
|
914.28
|
-14.28
|
203.89
|
10949.43
|
0.0159
|
|
970
|
1316.59
|
-346.59
|
120121.36
|
1199.9
|
0.36
|
|
780
|
955.11
|
-175.11
|
30663.67
|
50462.92
|
0.22
|
|
850
|
571.56
|
278.44
|
77528.04
|
23913.39
|
0.33
|
|
79
|
237
|
-158
|
24965.43
|
856808.55
|
2
|
|
1200
|
848.41
|
351.59
|
123615.5
|
38165.71
|
0.29
|
|
610
|
863.66
|
-253.66
|
64343.18
|
155740.36
|
0.42
|
|
670
|
952.54
|
-282.54
|
79831.63
|
111983.62
|
0.42
|
|
630
|
991.26
|
-361.26
|
130507.72
|
140354.78
|
0.57
|
|
700
|
641.13
|
58.87
|
3465.9
|
92805.25
|
0.0841
|
|
710
|
620.22
|
89.78
|
8060.72
|
86812.46
|
0.13
|
|
520
|
591.17
|
-71.17
|
5065.25
|
234875.48
|
0.14
|
|
|
|
0
|
13123967.15
|
18395389.83
|
21.06
|
Средняя ошибка аппроксимации
A = \f(∑|ε : Y|;n) 100% = \f(21.06;86) 100%
= 24.488
Оценка дисперсии равна:
se2 = (Y - X*Y(X))T(Y - X*Y(X)) = 13123967.15
Несмещенная оценка дисперсии равна:
s2 = \f(1;n-m-1) s2e = \f(1;86 - 6 - 1)13123967.15 = 166126.17
Оценка среднеквадратичного отклонения (стандартная ошибка для оценки Y):
S = \r(S2) = \r(166126.17) = 407.59
Найдем оценку ковариационной матрицы вектора k = S • (XTX)-1
|
313.71
|
0.12
|
-5.03
|
-4.57
|
-45.98
|
-20.88
|
-14.81
|
|
0.12
|
0.000991
|
-0.00431
|
0.00518
|
-0.0171
|
0.00227
|
-0.0155
|
|
-5.03
|
-0.00431
|
0.14
|
-0.17
|
0.37
|
0.15
|
0.0747
|
|
-4.57
|
0.00518
|
-0.17
|
1.81
|
0.35
|
-1.29
|
-0.54
|
|
-45.98
|
-0.0171
|
0.37
|
0.35
|
29.96
|
15.2
|
2.16
|
|
-20.88
|
0.00227
|
0.15
|
-1.29
|
15.2
|
28.78
|
1.19
|
|
-14.81
|
-0.0155
|
0.0747
|
-0.54
|
2.16
|
1.19
|
7.58
|
Дисперсии параметров модели определяются соотношением S2i = Kii, т.е. это
элементы, лежащие на главной диагонали
Показатели тесноты связи факторов с результатом.
Если факторные признаки различны по своей сущности и (или) имеют
различные единицы измерения, то коэффициенты регрессии bj при разных факторах
являются несопоставимыми. Поэтому уравнение регрессии дополняют соизмеримыми
показателями тесноты связи фактора с результатом, позволяющими ранжировать
факторы по силе влияния на результат.
К таким показателям тесноты связи относят: частные коэффициенты эластичности,
β-коэффициенты, частные коэффициенты
корреляции.
Частные коэффициенты эластичности.
С целью расширения возможностей содержательного анализа модели регрессии
используются частные коэффициенты эластичности, которые определяются по
формуле:
EQ Ei = bi \f(\x\to(x)i; \x\to(y) )
Частный коэффициент эластичности показывает, насколько процентов в
среднем изменяется признак-результат у с увеличением признака-фактора хj на 1%
от своего среднего уровня при фиксированном положении других факторов модели.
E1 = -1.39 \f(72; 1004.64 ) = -0.0996
Частный коэффициент эластичности |E1| < 1. Следовательно, его влияние
на результативный признак Y незначительно.
E2 = 27.81 \f(43.62; 1004.64 ) = 1.21
Частные коэффициент эластичности |E2| > 1. Следовательно, он существенно
влияет на результативный признак Y.
E3 = -20.91 \f(7.27; 1004.64 ) = -0.15
Частный коэффициент эластичности |E3| < 1. Следовательно, его влияние
на результативный признак Y незначительно.
E4 = -246.78 \f(0.59; 1004.64 ) = -0.15
Частный коэффициент эластичности |E4| < 1. Следовательно, его влияние
на результативный признак Y незначительно.
E5 = -188.75 \f(0.42; 1004.64 ) = -0.0786
Частный коэффициент эластичности |E5| < 1. Следовательно, его влияние
на результативный признак Y незначительно.
E6 = -153.7 \f(1.95; 1004.64 ) = -0.3
Частный коэффициент эластичности |E6| < 1. Следовательно, его влияние
на результативный признак Y незначительно.
Стандартизированные частные коэффициенты регрессии.
Стандартизированные частные коэффициенты регрессии - β-коэффициенты (βj)
показывают, на какую
часть своего среднего квадратического отклонения S(у) изменится
признак-результат y с изменением соответствующего фактора хj на величину своего
среднего квадратического отклонения (Sхj) при неизменном влиянии прочих факторов
(входящих в уравнение).
По максимальному βj можно судить, какой фактор сильнее влияет на результат
Y.
По коэффициентам эластичности и β-коэффициентам могут быть сделаны
противоположные выводы. Причины этого: а) вариация одного фактора очень велика;
б) разнонаправленное воздействие факторов на результат.
Коэффициент βj может также интерпретироваться как показатель прямого
(непосредственного) влияния j-ого фактора (xj) на результат (y). Во
множественной регрессии j-ый фактор оказывает не только прямое, но и косвенное
(опосредованное) влияние на результат (т.е. влияние через другие факторы
модели).
Косвенное влияние измеряется величиной: ∑βirxj,xi,
где m - число факторов в
модели. Полное влияние j-ого фактора на результат равное сумме прямого и
косвенного влияний измеряет коэффициент линейной парной корреляции данного
фактора и результата - rxj,y.
Так для нашего примера непосредственное влияние фактора x1 на результат Y
в уравнении регрессии измеряется βj и составляет -0.227; косвенное
(опосредованное) влияние данного фактора на результат определяется как:
rx1x2β2 = 0.329 * 0.404 =
0.1332
Сравнительная оценка влияния анализируемых факторов на результативный
признак.
. Сравнительная оценка влияния анализируемых факторов на результативный
признак производится:
средним коэффициентом эластичности, показывающим на сколько процентов
среднем по совокупности изменится результат y от своей средней величины при
изменении фактора xi на 1% от своего среднего значения;
- β-коэффициенты, показывающие, что, если
величина фактора изменится на одно среднеквадратическое отклонение Sxi, то
значение результативного признака изменится в среднем на β
своего
среднеквадратического отклонения;
долю каждого фактора в общей вариации результативного признака определяют
коэффициенты раздельной детерминации (отдельного определения):
d2i
= ryxiβi.= -0.14 • (-0.227) =
0.0309= 0.32 • 0.404 = 0.13= 0.0325 • (-0.0823) = -0.00268= -0.19 • (-0.262) =
0.05= -0.034 • (-0.201) = 0.00684= -0.26 • (-0.272) = 0.072
При этом должно выполняться
равенство:
∑d2i = R2 = 0.29
Множественный коэффициент
корреляции (Индекс множественной корреляции).
Тесноту совместного влияния
факторов на результат оценивает индекс множественной корреляции.
В отличие от парного
коэффициента корреляции, который может принимать отрицательные значения, он
принимает значения от 0 до 1.
Поэтому R не может быть
использован для интерпретации направления связи. Чем плотнее фактические
значения yi располагаются относительно линии регрессии, тем меньше остаточная
дисперсия и, следовательно, больше величина Ry(x1,...,xm).
Таким образом, при значении R
близком к 1, уравнение регрессии лучше описывает фактические данные и факторы
сильнее влияют на результат. При значении R близком к 0 уравнение регрессии
плохо описывает фактические данные и факторы оказывают слабое воздействие на
результат.
EQ R = \r(1 -
\f(s2e; ∑(yi - \x\to(y))2)) = \r(1 - \f(13123967.15;18395389.83)) = 0.535
Связь между признаком Y
факторами X умеренная
Расчёт коэффициента
корреляции выполним, используя известные значения линейных коэффициентов парной
корреляции и β-коэффициентов.
EQ R = \r(∑ryxiβyxi) =
\r(ryx1βyx1 + ryx2βyx2 + ryx3βyx3 + ryx4βyx4 +
ryx5βyx5 + ryx6βyx6)R =
\r(-0.136 • -0.227 + 0.32 • 0.404 + 0.0325 • -0.0823 + -0.191 • -0.262 + -0.034
• -0.201 + -0.264 • -0.272) = 0.535
Коэффициент детерминации.
= 0.5352 = 0.287
. Проверка гипотез
относительно коэффициентов уравнения регрессии (проверка значимости параметров
множественного уравнения регрессии).
Число v = n - m - 1
называется числом степеней свободы. Считается, что при оценивании множественной
линейной регрессии для обеспечения статистической надежности требуется, чтобы
число наблюдений, по крайней мере, в 3 раза превосходило число оцениваемых
параметров.
) t-статистика
табл (n-m-1;α/2) =
(79;0.025) = 1.99
EQ ti = \f(bi;Sbi)
Находим стандартную ошибку
коэффициента регрессии b0:
Sb0 = \r(313.71) = 17.71t0 =
\f(569.36;17.71) = 32.15>1.99
Статистическая значимость
коэффициента регрессии b0 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b1:
EQ Sb1 = \r(0.000991) =
0.0315t1 = \f(-1.39;0.0315) = 44.16>1.99
атистическая значимость
коэффициента регрессии b1 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b2:
Sb2 = \r(0.14) = 0.38t2 =
\f(27.81;0.38) = 73.95>1.99
Статистическая значимость
коэффициента регрессии b2 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b3:
Sb3 = \r(1.81) = 1.34t3 =
\f(-20.91;1.34) = 15.55>1.99
Статистическая значимость
коэффициента регрессии b3 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b4:
Sb4 = \r(29.96) = 5.47t4 =
\f(-246.78;5.47) = 45.08>1.99
Статистическая значимость
коэффициента регрессии b4 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b5:
Sb5 = \r(28.78) = 5.36t5 =
\f(-188.75;5.36) = 35.19>1.99
Статистическая значимость
коэффициента регрессии b5 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b6:
Sb6 = \r(7.58) = 2.75t6 =
\f(-153.7;2.75) = 55.84>1.99
Статистическая значимость
коэффициента регрессии b6 подтверждается.
Доверительный интервал для
коэффициентов уравнения регрессии.
Определим доверительные
интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(bi - ti Sbi; bi +
ti Sbi)
b0: (569.36 - 1.99 • 17.71 ;
569.36 + 1.99 • 17.71) = (534.12;604.61): (-1.39 - 1.99 • 0.0315 ; -1.39 + 1.99
• 0.0315) = (-1.45;-1.33): (27.81 - 1.99 • 0.38 ; 27.81 + 1.99 • 0.38) =
(27.06;28.56): (-20.91 - 1.99 • 1.34 ; -20.91 + 1.99 • 1.34) = (-23.59;-18.23):
(-246.78 - 1.99 • 5.47 ; -246.78 + 1.99 • 5.47) = (-257.68;-235.89): (-188.75 -
1.99 • 5.36 ; -188.75 + 1.99 • 5.36) = (-199.43;-178.07): (-153.7 - 1.99 • 2.75
; -153.7 + 1.99 • 2.75) = (-159.18;-148.22)
. Проверка общего качества
уравнения множественной регрессии.
Оценка значимости уравнения
множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю
коэффициент детерминации рассчитанного по данным генеральной совокупности: R2
или b1 = b2 =... = bm = 0 (гипотеза о незначимости уравнения регрессии,
рассчитанного по данным генеральной совокупности).
Для ее проверки используют
F-критерий Фишера.
При этом вычисляют
фактическое (наблюдаемое) значение F-критерия, через коэффициент детерминации
R2, рассчитанный по данным конкретного наблюдения.
По таблицам распределения
Фишера-Снедоккора находят критическое значение F-критерия (Fкр). Для этого
задаются уровнем значимости α (обычно
его берут равным 0,05) и двумя числами степеней свободы k1=m и k2=n-m-1.
) F-статистика. Критерий
Фишера.
EQ R2 = 1 -
\f(s2e;∑(yi - \x\to(y))2) = 1 - \f(13123967.15;18395389.83) = 0,287
Чем ближе этот коэффициент к
единице, тем больше уравнение регрессии объясняет поведение Y.
Более объективной оценкой
является скорректированный коэффициент детерминации:
EQ \x\to(R)2 = 1 -
(1 - R2)\f(n-1;n-m-1)\x\to(R)2 = 1 - (1 -
0.287)\f(86-1;86-6-1) = 0.232
Добавление в модель новых
объясняющих переменных осуществляется до тех пор, пока растет скорректированный
коэффициент детерминации.
Проверим гипотезу об общей
значимости - гипотезу об одновременном равенстве нулю всех коэффициентов
регрессии при объясняющих переменных:
H0:
R2 = 0; β1 = β2 = ... = βm = 0.: R2 ≠ 0.
Проверка этой гипотезы
осуществляется с помощью F-статистики распределения Фишера (правосторонняя
проверка).
Если F < Fkp = Fα ;
n-m-1, то нет оснований для отклонения
гипотезы H0.
EQ F = \f(R2;1 -
R2)\f((n - m -1);m) = \f(0.287;1 - 0.287)\f(86-6-1;6) = 5,29
Табличное значение при
степенях свободы k1 = 6 и k2 = n-m-1 = 86 - 6 - 1 = 79, Fkp(6;79) = 2.17
Отметим значения на числовой
оси.
|
Принятие H0
|
Отклонение H0, принятие H1
|
|
95%
|
5%
|
|
2.17
|
5.29
|
Поскольку фактическое значение F > Fkp, то коэффициент детерминации
статистически значим и уравнение регрессии статистически надежно
Оценка значимости дополнительного включения фактора (частный F-критерий).
Необходимость такой оценки связана с тем, что не каждый фактор, вошедший
в модель, может существенно увеличить долю объясненной вариации результативного
признака. Это может быть связано с последовательностью вводимых факторов (т. к.
существует корреляция между самими факторами).
Мерой оценки значимости улучшения качества модели, после включения в нее
фактора хj, служит частный F-критерий - Fxj:
Fxj = \f(R2 - R2(x1,xn);1-R2) (n - m - 1)
где m - число оцениваемых параметров.
Если наблюдаемое значение Fxj больше Fkp, то дополнительное введение
фактора xj в модель статистически оправдано.
Частный F-критерий оценивает значимость коэффициентов "чистой"
регрессии (bj). Существует взаимосвязь между частным F-критерием - Fxj и
t-критерием, используемым для оценки значимости коэффициента регрессии при j-м
факторе:
t(bj=0) = \r(Fxj)
Список литературы
1. Айвазян
С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. - М.: ЮНИТИ, 1998.
- 650 с.
. Буре
В.М.. Евсеев Е.А. Основы эконометрики: Учеб. Пособие. - СПб.: Изд-во С.-Петерб.
ун-та, 2004.- 72 с.
. Валландер
С.С. Заметки по эконометрике. - СПб.: Европ. ун-т ,2001. - 46 с.
. Доугерти
К. Введение в эконометрику: учебник. 2-е изд. М.: ИНФРА-М, 2004.- 432 с.
. Кремер
Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов.- М.: ЮНИТИ-ДАНА, 2004.- 311
с.
. Магнус
Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. - М.: Дело,
2000. - 400 с.
. Практикум
по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и
др.; Под ред. И.И. Елисеевой. - М.: Финансы и статистика, 2001, с. 49..105.
. Эконометрика:
Учебник / Под ред. И.И.Елисеевой. - М.: Финансы и статистика, 2001. - 344 с.