Исследование оборота розничной торговли
Министерство
образования и науки Российской Федерации
Федеральное
агентство по образованию
Государственное
образовательное учреждение
высшего
профессионального образования
"Российский
государственный торгово-экономический университет"
Кафедра
Таможенное дело
Контрольная
работа
по дисциплине
"Экономико-математические методы и модели в таможенной статистике"
Выполнила:
студентка 5 курса,
группы ТД-51 з/о,
зачетная книжка №09369,
Миникаева Л.А.
Проверил:
проф. Ярных Э.А.
Задача
По данным за два года изучается зависимость оборота розничной торговли
(Y, млрд. руб.) от ряда факторов: Х1 - денежные доходы населения, млрд. руб.,
Х2 - доля доходов, используемая на покупку товаров и оплату услуг, млрд. руб.;
Х3 - численность безработных, млн. чел.; Х4 - официальный курс рубля по
отношению к доллару США.
розничный торговля регрессионный безработный
Таблица 1
|
Месяц
|
Y
|
Х1
|
Х2
|
Х3
|
Х4
|
|
1
|
72,9
|
117,7
|
81,6
|
8,3
|
6,026
|
|
2
|
67,0
|
123,8
|
73,2
|
8,4
|
6,072
|
|
3
|
69,7
|
126,9
|
75,3
|
8,5
|
6,106
|
|
4
|
70,0
|
134,1
|
71,3
|
8,5
|
6,133
|
|
5
|
69,8
|
123,1
|
77,3
|
8,3
|
6,164
|
|
6
|
69,1
|
126,7
|
76,0
|
8,1
|
6,198
|
|
7
|
70,7
|
130,4
|
76,6
|
8,1
|
6,238
|
|
8
|
80,1
|
129,3
|
84,7
|
8,3
|
7,905
|
|
9
|
105,2
|
145,4
|
92,4
|
8,6
|
16,065
|
|
10
|
102,5
|
163,8
|
80,3
|
8,9
|
16,010
|
|
11
|
108,7
|
164,8
|
82,6
|
9,4
|
17,880
|
|
12
|
134,8
|
227,2
|
70,9
|
9,7
|
20,650
|
|
13
|
116,7
|
164,0
|
89,9
|
10,1
|
22,600
|
|
14
|
117,8
|
183,7
|
81,3
|
10,4
|
22,860
|
|
15
|
128,7
|
195,8
|
83,7
|
10,0
|
24,180
|
|
16
|
129,8
|
219,4
|
76,1
|
9,6
|
24,230
|
|
17
|
133,1
|
209,8
|
80,4
|
9,1
|
24,440
|
|
18
|
136,3
|
223,3
|
78,1
|
8,8
|
24,220
|
|
19
|
139,7
|
223,6
|
79,8
|
8,7
|
24,190
|
|
20
|
151,0
|
236,6
|
82,1
|
8,6
|
24,750
|
|
21
|
154,6
|
236,6
|
83,2
|
8,7
|
25,080
|
|
22
|
160,2
|
248,6
|
80,8
|
8,9
|
26,050
|
|
23
|
163,2
|
253,4
|
81,8
|
9,1
|
26,420
|
|
24
|
191,7
|
351,4
|
68,3
|
9,1
|
27,000
|
Задание:
. Для заданного набора данных постройте линейную модель множественной
регрессии. Оцените точность и адекватность построенного уравнения регрессии.
. Выделите значимые и незначимые факторы в модели. Постройте уравнение
регрессии со статистически значимыми факторами. Дайте экономическую
интерпретацию параметров модели.
. Для полученной модели проверьте выполнение условия гомоскедастичности
остатков, применив тест Голдфельда-Квандта.
. Проверьте полученную модель на наличие автокорреляции остатков с
помощью теста Дарбина-Уотсона.
. Проверьте, адекватно ли предположение об однородности исходных данных в
регрессионном смысле. Можно ли объединить две выборки (по первым 12 и остальным
наблюдениям) в одну и рассматривать единую модель регрессии Y по X?
Решение. 1. Для нахождения параметров линейного уравнения множественной
регрессии  = a + b1X1 + b2X2 + b3X3 + b4X4 воспользуемся средствами
Excel.
= a + b1X1 + b2X2 + b3X3 + b4X4 воспользуемся средствами
Excel.
Выполним команду Сервис - Анализ данных - Регрессия, зададим параметры
регрессии:

Рис. 1
В результате получим:

Рис. 2
Из рис. 2 находим  .
.
Уравнение регрессии примет вид:
 .
.
квадрат - это  . В нашем примере значение = 0,9954 свидетельствует о том, что
изменения зависимой переменной Y (оборот розничной торговли) в основном (на
99,54%) можно объяснить изменениями включенных в модель объясняющих переменных
- Х1, Х2, Х3, Х4. Такое значение свидетельствует об адекватности модели.
. В нашем примере значение = 0,9954 свидетельствует о том, что
изменения зависимой переменной Y (оборот розничной торговли) в основном (на
99,54%) можно объяснить изменениями включенных в модель объясняющих переменных
- Х1, Х2, Х3, Х4. Такое значение свидетельствует об адекватности модели.
Значимость модели можно оценить с помощью критерия Фишера. На рис. 2
расчетное значение F-критерия Фишера находится в ячейке Е38. Для проверки
значимости уравнения регрессии в целом можно посмотреть Значимость F. На уровне
значимости a = 0,05
уравнение регрессии признается значимым в целом, если Значимость  , и незначимым, если Значимость
, и незначимым, если Значимость 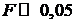 . В нашем примере Значимость F =
5,97Е-22, что меньше 0,05. Таким образом, полученное уравнение в целом значимо.
. В нашем примере Значимость F =
5,97Е-22, что меньше 0,05. Таким образом, полученное уравнение в целом значимо.
. В последней таблице приведены значения параметров (коэффициентов)
модели, их стандартные ошибки и расчетные значения t-критерия Стьюдента для
оценки значимости отдельных параметров модели (ячейки В42:J47).
Таблица 2
|
Коэффициенты
|
Стандартная ошибка
|
t- статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y
|
a = -63,123
|
 24,039 24,039
|
 -2,626 -2,626
|
0,017
|
113,438 -12,809 -12,809
|
|
Х1
|
b1 =0,495
|
 0,036 0,036
|
 13,682 13,682
|
2,74Е-11
|
0,419 0,571 0,571
|
|
Х2
|
b2 == 0,983
|
 0,175 0,175
|
 5,611 5,611
|
2,07Е-5
|
0,617 1,35 1,35
|
|
Х3
|
b3 =-1,307
|
 1,446 1,446
|
 -0,904 -0,904
|
0,377
|
-4,333 1,719 1,719
|
|
Х4
|
b4 =1,088
|
 0,292 0,292
|
 3,726 3,726
|
0,001
|
0,477 1,699 1,699
|
Анализ таблицы для рассматриваемого примера позволяет сделать вывод о
том, что на уровне значимости a = 0,05 значимыми оказываются лишь коэффициенты при факторах Х1, Х2 и Х4,
так как только для них Р-значение меньше 0,05. Таким образом, фактор Х3 не
существенен, и его включение в модель нецелесообразно.
Поскольку коэффициент регрессии в эконометрических исследованиях имеют
четкую экономическую интерпретацию, то границы доверительного интервала для
коэффициента регрессии не должны содержать противоречивых результатов, как
например, -4,3331,719. Такого рода запись указывает, что истинное значение
коэффициента регрессии одновременно содержит положительные и отрицательные
величины и даже ноль, чего не может быть. Это также подтверждает вывод о
статистической незначимости коэффициента регрессии при факторе Х3.
Исключим несущественный фактор Х3 и построим уравнение зависимости  (оборот розничной торговли) от
объясняющих переменных Х1, Х2, и Х4. Результаты регрессионного анализа
приведены на рис. 3.
(оборот розничной торговли) от
объясняющих переменных Х1, Х2, и Х4. Результаты регрессионного анализа
приведены на рис. 3.

Рис. 3
Оценим точность и адекватность полученной модели.
Значение  = 0,9952 свидетельствует о том, что вариация зависимой
переменной (оборот розничной торговли) по-прежнему в основном (на
99,52%) можно объяснить вариацией включенных в модель объясняющих переменных -
Х1, Х2 и Х4. Это свидетельствует об адекватности модели.
= 0,9952 свидетельствует о том, что вариация зависимой
переменной (оборот розничной торговли) по-прежнему в основном (на
99,52%) можно объяснить вариацией включенных в модель объясняющих переменных -
Х1, Х2 и Х4. Это свидетельствует об адекватности модели.
Значение поправленного коэффициента детерминации (нормированный R2 =
0,994535) возросло по сравнению с первой моделью, в которую были включены все
объясняющие переменные (0,994485).
Стандартная ошибка регрессии во втором случае меньше, чем в первом
(2,7175 < 2,799).
Расчетное значение F-критерия Фишера составляет 1396,179. Значимость F =
2,17E-23, что меньше 0,05. Таким образом, полученное уравнение в целом значимо.
Далее оценим значимость отдельных параметров построенной модели. Из рис.
3 видно, что теперь на уровне значимости  все включенные в модель факторы
являются значимыми: Р-значение < 0,05.
все включенные в модель факторы
являются значимыми: Р-значение < 0,05.
Границы доверительного интервала для коэффициентов регрессии не содержат
противоречивых результатов:
- с надежностью 0,95 (c вероятностью 95%) коэффициент b1 лежит в
интервале 0,455 ≤ b1 ≤ 0,575;
- с надежностью 0,95 (c вероятностью 95%) коэффициент b2 лежит в
интервале 0,731 ≤ b2 ≤ 1,38;
- с надежностью 0,95 (c вероятностью 95%) коэффициент b3 лежит в
интервале 0,479 ≤ b3 ≤ 1,314.
Таким образом, модель балансовой прибыли предприятия торговли запишется в
следующем виде:
 .
.
Рассмотрим теперь экономическую интерпретацию параметров модели.
Коэффициент b1 = 0,515, означает, что при увеличении только денежных
доходов населения (Х1) на 1 млрд.руб. оборот розничной торговли в среднем
возрастает на 0,515 млрд. руб. Ф; при увеличении доли доходов, используемых на
покупку товаров и оплату услуг на 1 млрд. руб. оборот розничной торговли в
среднем возрастет на 1,055 млрд. руб.; рост официального курса рубля по
отношению к доллару США приведет к росту оборота розничной торговли в среднем
на 0,897 млрд. руб.
3. Проверим выполнение условия гомоскедастичности остатков, применив тест
Голдфельда-Квандта. Гипотеза о равенстве дисперсий двух нормально
распределенных совокупностей, проверяется с помощью критерия Фишера-Снедекора.
Нулевая гипотеза (Н0) о равенстве дисперсий двух наборов по т наблюдений (т. е.
гипотеза об отсутствии гетероскедастичности) отвергается, если:

где p - число регрессоров (р = 2), m - число наблюдений, m = n/3 = 24/3 =
8.
Для множественной регрессии этот тест, как правило, проводится для той
объясняющей переменной, которая в наибольшей степени связана с у. Вычислим
коэффициенты парной корреляции (Сервис - Анализ данных - Корреляция).

Рис. 4.
По коэффициентам парной корреляции можно сделать вывод, что Х1 теснее
связан с Y, чем Х1 и Х4 ( ). Упорядочим наблюдения по возрастанию переменной Х1.
). Упорядочим наблюдения по возрастанию переменной Х1.
Таблица 3
|
Месяц
|
Y
|
Х1
|
Х2
|
Х4
|
|
25
|
72,9
|
117,7
|
81,6
|
6,026
|
|
26
|
67,0
|
123,8
|
73,2
|
6,072
|
|
27
|
69,7
|
126,9
|
75,3
|
6,106
|
|
28
|
70,0
|
134,1
|
71,3
|
6,133
|
|
29
|
69,8
|
123,1
|
77,3
|
6,164
|
|
30
|
69,1
|
126,7
|
76,0
|
6,198
|
|
31
|
70,7
|
130,4
|
76,6
|
6,238
|
|
32
|
80,1
|
129,3
|
84,7
|
7,905
|
|
33
|
105,2
|
145,4
|
92,4
|
16,065
|
|
34
|
102,5
|
163,8
|
80,3
|
16,010
|
|
35
|
108,7
|
164,8
|
82,6
|
17,880
|
|
36
|
134,8
|
227,2
|
70,9
|
20,650
|
|
37
|
116,7
|
164,0
|
89,9
|
22,600
|
|
38
|
117,8
|
183,7
|
81,3
|
22,860
|
|
39
|
128,7
|
195,8
|
83,7
|
24,180
|
|
40
|
129,8
|
219,4
|
76,1
|
24,230
|
|
41
|
133,1
|
209,8
|
80,4
|
24,440
|
|
42
|
136,3
|
223,3
|
78,1
|
24,220
|
|
43
|
139,7
|
223,6
|
24,190
|
|
44
|
151,0
|
236,6
|
82,1
|
24,750
|
|
45
|
154,6
|
236,6
|
83,2
|
25,080
|
|
46
|
160,2
|
248,6
|
80,8
|
26,050
|
|
47
|
163,2
|
253,4
|
81,8
|
26,420
|
|
48
|
191,7
|
351,4
|
68,3
|
27,000
|
Построим модель по первым 8 наблюдениям. Результаты дисперсионного
анализа модели множественной регрессии, построенной по первым 8 наблюдениям,
приведены в таблице 4.
Таблица 4
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
3
|
104,2369
|
34,74564
|
23,95492
|
0,00512
|
|
Остаток
|
4
|
ESS1 = 5,801837
|
1,450459
|
|
|
|
Итого
|
7
|
110,0388
|
|
|
|
Результаты дисперсионного анализа модели, построенной по последним 8
наблюдениям, приведены в таблице 5.
Таблица 5
|
dfSSMSFЗначимость F
|
|
|
|
|
|
|
Регрессия
|
3
|
2393,725
|
797,9083
|
68,79414
|
0,000673
|
|
Остаток
|
4
|
ESS2 = 46,39397
|
11,59849
|
|
|
|
Итого
|
7
|
2440,119
|
|
|
|
Рассчитаем статистику (так как  )
)
 .
.
Для того, чтобы узнать табличное значение, воспользуемся встроенной в
EXCEL функцией FРАСПОБР(). Зададим параметры: 0,05 - заданная вероятность
ошибки гипотезы H0; число степеней свободы:
 .
.
 .
.
Поскольку  , то модель не является гомоскедастичной, т.е.
гетероскедастична.
, то модель не является гомоскедастичной, т.е.
гетероскедастична.
. Проверим полученную модель на наличие автокорреляции остатков с помощью
теста Дарбина-Уотсона. Коэффициент автокорреляции рассчитывается по формуле ( ):
):
 .
.
Для того чтобы определить значения отклонений ei, в диалоговом окне
Регрессия в группе Остатки следует установить одноименный флажок Остатки.
Приведем расчетную таблицу:
Таблица 6
|
ei
|

|

|

|
|
1,7906898
|
|
|
3,20657
|
|
1,2123518
|
1,79069
|
0,3344749
|
1,469797
|
|
0,4059213
|
1,212352
|
0,65033006
|
0,164772
|
|
1,0456052
|
0,405921
|
0,40919547
|
1,09329
|
|
0,0958707
|
1,045605
|
0,90199555
|
0,009191
|
|
-1,4064696
|
0,095871
|
2,25702647
|
1,978157
|
|
-2,2720072
|
-1,40647
|
0,74915529
|
5,162017
|
|
-1,8456298
|
-2,27201
|
0,18179763
|
3,40635
|
|
-0,7749455
|
-1,84563
|
1,14636501
|
0,60054
|
|
-0,2330439
|
-0,77495
|
0,29365731
|
0,054309
|
|
1,8290734
|
-0,23304
|
4,25232777
|
3,345509
|
|
5,9190669
|
1,829073
|
16,7280466
|
35,03535
|
|
-1,1740676
|
5,919067
|
50,3125567
|
1,378435
|
|
-1,2606767
|
-1,17407
|
0,00750113
|
1,589306
|
|
-0,6708753
|
-1,26068
|
0,34786573
|
0,450074
|
|
-4,3585229
|
-0,67088
|
13,5987455
|
18,99672
|
|
-1,4164182
|
-4,35852
|
8,65598011
|
2,006241
|
|
-2,7913427
|
-1,41642
|
1,89041716
|
7,791594
|
|
-1,3098737
|
-2,79134
|
2,19475012
|
1,715769
|
|
0,5516491
|
-1,30987
|
3,46526743
|
0,304317
|
|
2,8415393
|
0,551649
|
5,24359684
|
8,074345
|
|
4,0666464
|
2,841539
|
1,5008874
|
16,53761
|
|
3,5655262
|
4,066646
|
0,25112141
|
12,71298
|
|
-3,8100669
|
3,565526
|
54,3993743
|
14,51661
|
|
СУММА
|
169,772436
|
141,5999
|
 .
.
Зададим уровень значимости  . По таблице значений критерия
Дарбина-Уотсона определим для числа наблюдений
. По таблице значений критерия
Дарбина-Уотсона определим для числа наблюдений  и числа независимых параметров
модели
и числа независимых параметров
модели  критические значения
критические значения  и
и  . Фактическое значение
. Фактическое значение  -критерия Дарбина-Уотсона попадает в
интервал
-критерия Дарбина-Уотсона попадает в
интервал  (1,19 < 1,199 < 1,55) - зону
неопределенности. Если фактическое значение критерия Дарбина-Уотсона попадает в
зону неопределенности, то на практике предполагают существование автокорреляции
остатков. Следовательно, в ряду остатков существует положительная
автокорреляция.
(1,19 < 1,199 < 1,55) - зону
неопределенности. Если фактическое значение критерия Дарбина-Уотсона попадает в
зону неопределенности, то на практике предполагают существование автокорреляции
остатков. Следовательно, в ряду остатков существует положительная
автокорреляция.
5. Проверим, адекватно ли предложение об однородности исходных данных в
регрессивном смысле. Можно ли объединить две выборки (по первым 12 и остальным
12 наблюдениям) в одну и рассмотреть единую модель регрессии У и Х?
Для проверки предположения об однородности исходных данных в
регрессионном смысле применим тест Чоу.
В соответствии со схемой теста построим уравнения регрессии по первым
n1=12 наблюдениям. Результаты представлены в таблице 7.
Таблица 7
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
4
|
5387,101
|
1346,775
|
877,1593
|
1,58E-09
|
|
Остаток
|
7
|
ESS1 = 10,74768
|
1,535383
|
|
|
|
Итого
|
11
|
5397,849
|
|
|
|
Результаты дисперсионного анализа модели, построенной по оставшимся n2=12
наблюдениям, представлены в таблице 8.
Таблица 9
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
4
|
5115,151
|
1278,788
|
622,702
|
5,23E-09
|
|
Остаток
|
7
|
ESS2 = 14,37528
|
2,053611
|
|
|
|
Итого
|
11
|
5129,527
|
|
|
|
Результаты регрессионного и дисперсионного анализа модели, построенной по
всем n = n1 + n2 = 24 наблюдениям, представлены на рис. 2 (ESS = 141,5999):
Рассчитаем статистику F по формуле:
 .
.
Находим табличное значение Fтабл= FРАСПОБР(0,05;3;18) = 3,16.
Так как, Fрасч > Fтабл, то две регрессионные модели нельзя объединить
в одну.
Список
используемой литературы
1.
Эконометрика: Учебник / Под ред. И.И. Елисеевой. - М.: Финансы и статистика,
2002. - 344 с.
. Практикум
по эконометрике: Учеб. пособие / Под ред. И.И. Елисеевой. - М.: Финансы и
статистика, 2003. - 192 с.
. Кремер Н.Ш,
Путко Б.А. Эконометрика: Учеб. для вузов - М.: ЮНИТИ-ДАНА, 2003.