Простые вычисления и кодирования сообщений
МИНОБРНАУКИ
РОССИИ
Федеральное
государственное бюджетное образовательное учреждение
Высшего
профессионального образования
«Пензенский
государственный технологический университет»
(ПензГТУ)
Факультет
«Информационных и образовательных технологий»
Кафедра «Информационные
технологии и системы»
Дисциплина
«Основы теории информации»
КОНТРОЛЬНАЯ РАБОТА
Дисциплина «Основы теории информации»
Выполнил:
студент группы 13ИС2Б
Чинков М.Ю
Проверил: ст.
преподаватель каф. ИТС
Пискаев К.Ю
Пенза 2015
ВВЕДЕНИЕ
Цель данной контрольной работы - актуализация знаний в предмете «Основы
теории информации».
В рамках контрольной работы было выполнено 5 заданий в соответствии с
моим вариантом (вариант №23):
. Определить среднее количество информации, содержащееся в сообщении,
используемом три независимых символа S1, S2, S3. Известны вероятности появления
символов p(S1)=p1, p(S2)=p2, p(S3)=p3. Оценить избыточность сообщения.
. В условии предыдущей задачи учесть зависимость между символами,
которая задана матрицей условных вероятностей P(Si / Sj).
. Провести кодирование по одной и блоками по две буквы, используя
метод Шеннона - Фано. Сравнить эффективности кодов (величина энтропии). Данные
взять из задачи 1.
. Алфавит передаваемых сообщений состоит из независимых букв Si.
Вероятности появления каждой буквы в сообщении заданы. Определить и сравнить
эффективность кодирования сообщений методом Хаффмана при побуквенном
кодировании и при кодировании блоками по две буквы.
. Определить пропускную способность канала связи, по которому
передаются сигналы Si. Помехи в канале определяются матрицей условных
вероятностей P(Si / Sj). За секунду может быть передано N = 10 сигналов.
Простые вычисления и кодирования сообщений в заданиях были сделаны
вручную, более сложные были сделаны с помощью среды разработки MATLAB R2014a.
Формулы и решения задач были введены с помощью программы MathType.
.
1. ОПРЕДЕЛЕНИЕ
СРЕДНЕГО КОЛИЧЕСТВА ИНФОРМАЦИИ
Энтропия источника - среднее количество информации в одном сообщении. Не
следует путать энтропию с количеством информации в одном конкретном сообщении.
Если в источнике есть множество сообщений, точно знать о каждом из них
необязательно. В этом заключается преимущество среднего значения количества
информации. Усреднение позволило Шеннону оценить как редкие, так и частые
сообщения. Энтропия характеризует источник сообщения. Аналогично можно получить
и “энтропийную характеристику сигнала”.
Задание: определить среднее количество информации, содержащееся в
сообщении, используемом три независимых символа S1, S2, S3. Известны
вероятности появления символов p(S1)=p1, p(S2)=p2, p(S3)=p3. Оценить
избыточность сообщения. Вариант №23: p1=0.12; p2=0.13; p3=0.75.
Решение. Максимальное среднее количество информации на символ сообщения
имеет место при равновероятном распределении и равно, согласно формуле

Рассчитаем
среднее количество информации на символ сообщения при заданных вероятностях по
формуле, где n - число символов в алфавите, p - вероятность появления события.

Оценим
избыточность сообщения по формуле.

Максимальная энтропия.

Реальная
энтропия.

Избыточность
сообщения.

2. ЗАВИСИМОСТЬ
МЕЖДУ СИМВОЛАМИ МАТРИЦЫ УСЛОВНЫХ ВЕРОЯТНОСТЕЙ
В большинстве реальных случаев появление элемента хi в сообщении зависит
от того, какой элемент хj был предшествующим. Взаимосвязь элементов в сообщении
характеризуется матрицей условных вероятностей.
Задание: в условии предыдущей задачи учесть зависимость между символами,
которая задана матрицей условных вероятностей P(Si / Sj).
Вариант №23.

Решение. Рассчитаем энтропию источника по формуле.
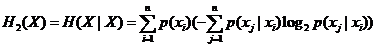
Подставим
числовые данные, используя задание 1.

Вычисление
энтропии в программе MATLAB.
=p1*((0.7*log2(0.7)+0.3*log2(0.3)))+p2*((0.5*log2(0.5)+0.5*log2(0.5))++p3*(-(0.1*log2(0.1)+0.5*log2(0.5)+0.4*log2(0.4)));
3. КОДИРОВАНИЕ
МЕТОДОМ ШЕННОНА-ФАНО
Кодирование Шеннона - Фано (англ. Shannon-Fano coding) - алгоритм
префиксного неоднородного кодирования. Относится к вероятностным методам сжатия
(точнее, методам контекстного моделирования нулевого порядка). Алгоритм Шеннона
- Фано использует избыточность сообщения, заключённую в неоднородном
распределении частот символов его (первичного) алфавита, то есть заменяет коды
более частых символов короткими двоичными последовательностями, а коды более
редких символов - более длинными двоичными последовательностями. Алгоритм был
независимо друг от друга разработан Шенноном (публикация «Математическая теория
связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
Задание: провести кодирование по одной и блоками по две буквы, используя
метод Шеннона - Фано. Сравнить эффективности кодов (величина энтропии). Данные
взять из задачи 1.
Решение. Проведем кодирование методом Шеннона - Фэно и рассчитаем
характеристики кода. Пусть исходный алфавит состоит из трех (по одной букве) и
девяти (по две буквы) букв и заданы их вероятности. Проведем разбиения по
алгоритму Шеннона - Фэно и составим кодовые комбинации.
|
xi
|
P(xi)
|
1
|
2
|
3
|
4
|
|
P3
|
0.75
|
0
|
0
|
1
|
|
|
P2
|
0.13
|
0
|
0
|
0
|
1
|
|
P1
|
0.12
|
0
|
0
|
0
|
Кодовые комбинации по одной букве.
|
xi
|
P(xi)
|
1
|
2
|
3
|
4
|
5
|
|
p3p3
|
0.5625
|
1
|
1
|
|
|
|
|
p3p2
|
0.0975
|
1
|
0
|
|
|
|
|
p2p3
|
0.0975
|
0
|
1
|
1
|
|
|
|
p3p1
|
0.09
|
0
|
1
|
0
|
|
|
|
p1p3
|
0.09
|
0
|
0
|
1
|
1
|
|
|
p2p2
|
0.0169
|
0
|
0
|
1
|
0
|
|
|
p2p1
|
0.0156
|
0
|
0
|
0
|
1
|
|
|
p1p2
|
0.0156
|
0
|
0
|
0
|
0
|
1
|
|
p1p1
|
0.0144
|
0
|
0
|
0
|
0
|
0
|
Кодовые комбинации по две буквы.
Рассчитаем энтропию по формуле.

Рассчитаем
среднюю длину кодовой комбинации по формуле.

Рассчитаем
эффективность кода, согласно формуле.

Энтропия
источника. По одной букве:
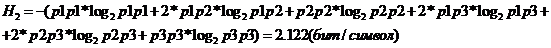
Средняя
длина кодовой комбинации источника. По одной букве:

По
две буквы:

Эффективность
кода. По одной букве:

По
две буквы:

4. КОДИРОВАНИЕ
АЛГОРИТМОМ ХАФФМАНА
Один из первых алгоритмов эффективного кодирования информации был
предложен Д.А. Хаффманом в 1952 году.
Идея алгоритма состоит в следующем: зная вероятности символов в
сообщении, можно описать процедуру построения кодов переменной длины, состоящих
из целого количества битов.
Символам с большей вероятностью ставятся в соответствие более короткие
коды.
Коды Хаффмана обладают свойством префиксности (то есть ни одно кодовое
слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости
символов в сообщении.
Далее на основании этой таблицы строится дерево кодирования Хаффмана
(Н-дерево).
Задание: алфавит передаваемых сообщений состоит из независимых букв Si.
Вероятности появления каждой буквы в сообщении заданы. Определить и сравнить
эффективность кодирования сообщений методом Хаффмена при побуквенном
кодировании и при кодировании блоками по две буквы. Вариант №23:
(0,8;0,0;0,08;0,12).
Решение. Проведем кодирование методом Шеннона-Фэно.
|
xi
|
P(xi)
|
1
|
2
|
3
|
|
p1
|
0.8
|
1
|
|
|
|
p4
|
0.12
|
0
|
1
|
|
|
p3
|
0.08
|
0
|
0
|
1
|
|
p2
|
0
|
0
|
0
|
0
|
По одной букве.
|
xi
|
P(xi)
|
|
P1p1
|
0.64
|
|
P4p1
|
0.096
|
|
P1p4
|
0.096
|
|
P3p1
|
0.064
|
|
P1p3
|
0.064
|
|
P4p4
|
0.0144
|
|
P4p3
|
0.0096
|
|
P3p4
|
0.0096
|
|
P3p3
|
0.0064
|
|
P4p2
|
0
|
|
P2p4
|
0
|
|
P3p2
|
0
|
|
P2p3
|
0
|
|
P2p1
|
0
|
|
P1p2
|
|
P2p2
|
0
|
По две буквы.
Проведем кодирование по методу Хаффмена. Исходный алфавит состоит из
нескольких букв с заданными вероятностями. Составим таблицу.
|
xi
|
P(xi)
|
Вспомогательный столбец
|
|
p1
|
0.8
|
0.8
|
|
p4
|
0.12
|
0.2
|
|
p3
|
0.08
|
|
|
p2
|
0
|
|
По одной букве
|
xi
|
P(xi)
|
Вспомогательные столбцы
|
|
P1p1
|
0.64
|
|
|
|
|
0.64
|
|
P4p1
|
0.096
|
|
|
0.096
|
0.192
|
0.36
|
|
P1p4
|
0.096
|
|
|
0.096
|
0.168
|
|
|
P3p1
|
0.064
|
|
0.064
|
0.128
|
|
|
|
P1p3
|
0.064
|
|
0.064
|
0.040
|
|
|
|
P4p4
|
0.0144
|
|
0.0144
|
|
|
|
|
P4p3
|
0.0096
|
0.0096
|
0.0256
|
|
|
|
|
P3p4
|
0.0096
|
0.0160
|
|
|
|
|
|
P3p3
|
0.0064
|
|
|
|
|
|
|
P4p2
|
0
|
|
|
|
|
|
|
P2p4
|
0
|
|
|
|
|
|
|
P3p2
|
0
|
|
|
|
|
|
|
P2p3
|
0
|
|
|
|
|
|
|
P2p1
|
0
|
|
|
|
|
|
|
P1p2
|
0
|
|
|
|
|
|
|
P2p2
|
0
|
|
|
|
|
|
По две буквы.
Характеристики кода рассчитываются по тем же формулам, что и для кода
Шеннона-Фано.
Рассчитаем энтропию по формуле.
Рассчитаем
минимальную среднюю длину кодовой комбинации по формуле.

Рассчитаем
эффективность кода, согласно формуле.
Энтропия
источника. По одной букве:

По
две буквы:

Средняя
длина кодовой комбинации источника. По одной букве:

По
две буквы:

Эффективность
кода. По одной букве:

По
две буквы:

5. ПРОПУСКНАЯ
СПОСОБНОСТЬ КАНАЛА СВЯЗИ
хаффман
код шеннон символ
Пропускная способность - метрическая характеристика, показывающая
соотношение предельного количества проходящих единиц (информации, предметов,
объёма) в единицу времени через канал, систему, узел. В информатике определение
пропускной способности обычно применяется к каналу связи и определяется
максимальным количеством переданной или полученной информации за единицу
времени.
Задание: Определить пропускную способность канала связи, по которому
передаются сигналы Si. Помехи в канале определяются матрицей условных
вероятностей P(Si / Sj). За секунду может быть передано N = 10 сигналов.
Вариант №23.
Решение. Рассчитаем условную энтропию по формуле.

Рассчитаем
пропускную способность канала связи по формуле.

Условная
энтропия.
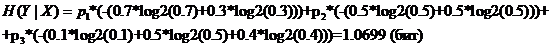
Пропускная
способность канала связи.

заключение
В рамках контрольной работы были изучены различные алгоритмы решения
задач на определение среднего количества информации, содержащейся в сообщении,
определение пропускной способности канала связи и алгоритмы кодирования
сообщений (метод Шеннона-Фано, алгоритм Хаффмана).
Было выполнено 5 заданий:
. Определить среднее количество информации, содержащееся в
сообщении, используемом три независимых символа S1, S2, S3. Известны
вероятности появления символов p(S1)=p1, p(S2)=p2, p(S3)=p3. Оценить
избыточность сообщения.
. В условии предыдущей задачи учесть зависимость между символами,
которая задана матрицей условных вероятностей P(Si / Sj).
. Провести кодирование по одной и блоками по две буквы, используя
метод Шеннона - Фано. Сравнить эффективности кодов (величина энтропии). Данные
взять из задачи 1.
. Алфавит передаваемых сообщений состоит из независимых букв Si.
Вероятности появления каждой буквы в сообщении заданы. Определить и сравнить
эффективность кодирования сообщений методом Хаффмана при побуквенном
кодировании и при кодировании блоками по две буквы.
. Определить пропускную способность канала связи, по которому
передаются сигналы Si. Помехи в канале определяются матрицей условных
вероятностей P(Si / Sj). За секунду может быть передано N = 10 сигналов.
Простые вычисления и кодирования сообщений в заданиях были сделаны
вручную, более сложные были сделаны с помощью среды разработки MATLAB R2014a.
Формулы и решения задач были введены с помощью программы MathType.
список литературы
1. Зверева
Е.Н. Сборник примеров и задач по основам теории информации и кодирования
сообщений/ Е.Н. Зверева, Е.Г.Лебедько. - СПб: НИУ ИТМО, 2014. - 76 с.
. Калинцев
С.В. Методические указания к контрольной работе по курсу «Теория кодирования»/
С.В.Калинцев. -2012. - 20 с.