Распознавание образов с помощью неординарного алгоритма и программной реализации, осуществляющей функционирование новой разделенной структуры искусственной нейронной сети
Содержание
1.
Теоретическая часть
.1 Цель
работы
.2 Научная
новизна
.3 Мозг и биологический нейрон
.4 Биологический нейрон и нейронные сети
.5 Аналогия между компьютером и
человеческим мозгом
.6
Искусственные нейронные сети
.7 Этапы развития искусственных
нейронных сетей
.8
Архитектура искусственных нейронных сетей
. Проблема
классификации данных
.1
Рецепторная структура восприятия информации
.2 Понятие
класса
.3 Проблема
кластеризации данных
.4
Геометрический и структурный подходы
.5 Гипотеза
компактности
.6 Обучение,
самообучение и адаптация
.7 Подготовка
данных для обучения
2.7.1
Максимизация энтропии как цель предобработки
.7.2
Нормировка данных
2.8
Алгоритмические построения
.9 Обучение
искусственных нейронных сетей
2.9.1
Обучение с учителем
.9.2 Обучение
без учителя
.9.3 Процесс
обучения нейронных сетей
.9.4 Алгоритм
секущих плоскостей
2.10 Обучение
сети Кохонена
.11 Клеточный
автомат в нейронных сетях
2.11.1
Устройство клеточного автомата
2.11.2
Клеточная нейронная сеть
3.
Классификация данных
.1 Постановка задачи и сложности,
связанные с ее реализацией
3.1.1 Выбор
топологии сети
3.2 Алгоритм
кластеризации данных
.3 Блок схема
нейронной сети
.4 Создание
табличной модели нейронной сети Кохонена
3.4.1 Рабочий
лист "Выборки"
.4.2 Рабочий
лист "Обучение"
3.5 Обучение
сети
.6 Создание
табличной модели обученной сети
.7
Тестирование сети
.8 Создание,
обучение и тестирование сети Кохонена в Matlab
3.8.1
Обоснование выбора среды для создания сети
.8.2
Архитектура сети
.8.3 Создание
сети
.8.4 Обучение
сети
.8.5 Тестирование
сети
3.9 Сравнение
результатов кластеризации в Matlab и Excel
Заключение
Список
литературы
1.
Теоретическая часть
.1 Цель
работы
Целью диссертации является разработка нового детерминированного алгоритма
обучения ИНС Кохонена с использованием непрерывного клеточного автомата,
позволяющего устранить большинство перечисленных недостатков, и его
практическая реализация в электронных таблицах.
Для достижения этой цели в работе поставлены и решены следующие задачи:
сбор и ввод нормализованных выборок данных, состоящих из двухмерных и
четырех мерных векторов;
исследование и анализ методов обучения для выявления математических
закономерностей и свойств, применимых в ИНС;
построение графиков и диаграмм, определяющих степень сравнительной
удаленности между различными объектами;
формирование пошагового алгоритма и графической блок-схемы ИНС;
достижение высокого результата классификации при минимальном количестве
образцов из каждого набора;
моделирование, тестирование и отладка программной реализации комплексной
структурной модели ИНС, использующей клеточный автомат;
сравнение параметров обучение с уже существующими аналогами.
Методы исследования.
В работе использованы теория искусственных самоорганизующихся нейронных
сетей для графических массивов базы данных с применением процесса распознавания
без учителя, статистический анализ, теория множеств и
кластеризации/категоризации объектов, методы алгоритмизации, методы
компьютерного моделирования в VBA для Excel и создание нейронной сети на основе
MS Excel, а также среда Matlab.
1.2 Научная
новизна
Имеющиеся в арсенале алгоритмы классификации в основном используют
неадаптивные алгоритмы распознавания образцов, которые работают для небольшого
количества обучаемых образцов. Значительное увеличение обучающей выборки
приводит к большому увеличению трудоемкости обучения. На основе проведенных
исследований в настоящей работе предложена новая и эффективная методика
распознавания образцов с помощью разделенной схемы искусственной нейронной сети
без учителя на основе клеточного автомата не только для двумерных, но и для
четырехмерных векторов. Научная новизна заключается в формулировании методики и
создании нового, адаптивного алгоритма, с использованием разделенной
искусственной нейронной сети без учителя и параллельного
вероятностно-статистического анализа информации.
.3 Мозг и
биологический нейрон
Мозг (рис. 1.1а) и Центральный Процессор (ЦП) ЭВМ (рис. 1.1б), являются
самыми сложными системами переработки информации. ЦП интегрирует миллионы
полупроводниковых транзисторов и подобен мозгу, в котором содержится около 100
миллиардов нейронов, каждый из которых имеет в среднем 10000 связей. По
аналогии с схемотехникой больших интегральных схем (БИС) ЭВМ, где происходит
прием, передача и переработка цифровой информации, биологическая сеть нейронов
отвечает за все явления, которые мы называем мыслями, эмоциями, памятью,
сенсомоторными и автономными функциями.

Рис. 1.1а. Строение и функции головного мозга

Рис. 1.1б. Пример схемы ЦП
Мозг, в котором, в отличие от ЦП, ежедневно погибает большое количество
нейронов, чрезвычайно надежен и продолжает функционировать. Обработка огромных
объемов информации мозгом осуществляется очень быстро, за доли секунды,
несмотря на то, что сам нейрон является медленнодействующим элементом со
временем реакции нескольких миллисекунд.
В отличие от биологического нейрона, электрические полупроводники ЦП
являются более быстродействующими и безошибочными, однако количество связей
между нейронами мозга во много раз превышает связи между полупроводниками ЦП,
что обеспечивает параллелизм и много поточность обработки информации. Головной
мозг человека состоит из серого и белого вещества. Серое вещество представляет
собой сеть дендритов, аксонов и тел нервных клеток. Миелинизированные волокна,
соединяющие различные области мозга друг с другом, с органами чувств и
мускулами, образуют белое вещество. Мозг состоит из двух полушарий, каждое
полушарие в свою очередь из четырех частей - лобной, теменной, височной и
затылочной.
В лобной части находится отдел эмоций и центры управления движениями -
правое полушарие отвечает за движение левой руки и ноги, а левое за движение
правой руки и ноги. В теменной части - зона телесных ощущений и осязаний. К ней
примыкает височная зона, в которой расположены центр речи, слуха, вкуса. В
затылочной части расположен зрительный отдел, также отдел распознавания
окружающих предметов посредством зрения. В мозге существуют структурно
обособленные отделы такие, как кора, гипоталамус, мозжечок, миндалина,
полосатое тело и т. д. Каждый из отделов, в свою очередь, имеет сложное
модульное строение. Особое место в мозге зажимает церебральная кора.
Считается, что именно здесь происходят важнейшие процессы ассоциативной
переработки информации. Мозг является основным потребителем энергии тела.
Включая в себя лишь 2% массы тела, в состоянии покоя, мозг использует
приблизительно 20% кислорода тела. Мозг также содержит густую сеть кровеносных
сосудов, которые обеспечивают кислородом и питательными веществами нейроны и
другие ткани. Эта система кровоснабжения связана с главной системой
кровообращения посредством высокоэффективной фильтрующей системы, называемой
гематоэнцефалическим барьером, являющимся механизмом защиты, предохраняющим
мозг от возможных токсичных веществ, находящихся в крови.
Защита обеспечивается низкой проницаемостью кровеносных сосудов мозга, а
также плотным перекрытием глиальных клеток, окружающих нейроны. Фактически весь
объем мозга, не занятый нейронами и кровеносными сосудами, заполнен глиальными
клетками, которые обеспечивают структурную основу мозга.
1.4
Биологический нейрон и нейронные сети
Каждый нейрон обладает многими качествами, общими с другими элементами
тела, но его уникальной способностью является прием, обработка и передача
электрохимических сигналов по нервным путям, которые образуют коммуникационную
систему мозга. На рис. 1.2а и рис. 1.2б. показана структура и строение типичных
биологических нейронов. Нейрон состоит из трех частей: тела клетки, дендритов и
аксона, каждая часть со своими, но взаимосвязанными функциями. Дендриты идут от
тела нервной клетки (сома) к другим нейронам, где они принимают сигналы в
точках соединения, называемых синапсами.
Принятые синапсом входные сигналы подводятся к телу нейрона. Здесь они
суммируются, причем одни входы стремятся возбудить нейрон, другие -
воспрепятствовать его возбуждению. Когда суммарное возбуждение в теле нейрона
превышает некоторый порог, нейрон возбуждается, посылая по аксону сигнал другим
нейронам. У этой основной функциональной схемы много усложнений и исключений,
тем не менее большинство искусственных нейронных сетей моделируют лишь простые
свойства.

Рис. 1.2а. Структура типичных биологических нейронов

Рис. 1.2б. Строение типичных биологических нейронов
Нервные клетки, или нейроны, представляют собой особый вид клеток в живых
организмах, обладающих электрической активностью, основное назначение которых
заключается в оперативном управлении организмом. Сома, как правило, имеет
поперечный размер несколько десятков микрон. Длина дендритов может достигать 1
мм, дендриты сильно ветвятся, пронизывая сравнительно большое пространство в
окрестности нейрона. Длина аксона может достигать сотен миллиметров. На соме и
на дендритах располагаются окончания (коллатерали) аксонов, идущих от других
нервных клеток. Каждое такое окончание имеет вид утолщения, называемого
синаптической бляшкой, или синапсом. Поперечные размеры синапса, как правило,
не превышают нескольких микрон, чаще всего эти размеры составляют около 1 мкм.
Входные сигналы дендритного дерева (постсинаптические потенциалы)
взвешиваются и суммируются на пути к аксонному холмику, где генерируется
выходной импульс (спайк) или пачка импульсов. Его наличие (или интенсивность),
следовательно, является функцией взвешенной суммы входных сигналов. Выходной
сигнал проходит по ветвям аксона и достигает синапсов, которые соединяют аксоны
с дендритными деревьями других нейронов. Через синапсы сигнал трансформируется
в новый входной сигнал для смежных нейронов. Этот входной сигнал может быть
положительным и отрицательным (возбуждающим или тормозящим) в зависимости от
вида синапсов. Величина входного сигнала, генерируемого синапсом, может быть
различной даже при одинаковой величине сигнала, приходящего в синапс. Эти
различия определяются эффективностью или весом синапса. Синаптический вес может
изменяться в процессе функционирования синапса. Нейроны можно разбить на три
большие группы: рецепторные, промежуточные и эффекторные. Рецепторные нейроны
обеспечивают ввод в мозг сенсорной информации. Они трансформируют сигналы,
поступающие на органы чувств (оптические сигналы в сетчатке глаза, акустические
в ушной улитке или обонятельные в хеморецепторах носа), в электрическую
импульсацию своих аксонов. Эффекторные нейроны передают приходящие на них
сигналы исполнительным органам. На конце их аксонов имеются специальные
синаптические соединения с исполнительными органами, например мышцами, где
возбуждение нейронов трансформируется в сокращения мышц. Промежуточные нейроны
осуществляют обработку информации, получаемой от рецепторов, и формируют
управляющие сигналы для эффекторов. Они образуют центральную нервную систему.
.5 Аналогия
между компьютером и человеческим мозгом
Основные положения теории деятельности головного мозга и математическая
модель нейрона были разработаны У. Мак-Каллоком и Ч. Питтсом в 1943 году.
Согласно предложенной модели мозг представляет собой множество нейронов,
имеющих одинаковую структуру. Каждый нейрон реализует некоторую функцию,
называемую пороговой, над входными значениями. Если значение функции превышает
определенную величину - порог (что характеризует суммарную значимость
полученной нейроном информации), нейрон возбуждается и формирует выходной
сигнал для передачи его другим нейронам. Пройдя путь от рецепторов (слуховых,
зрительных и других) через нейронные структуры мозга до исполнительных органов,
входная информация преобразуется в набор управляющих воздействий, адекватных
ситуации.
Отдельные нейроны, соединяясь между собой, образуют новое качество,
которое, в зависимости от характера межнейронных соединений, имеет различные
уровни биологического моделирования:
группа нейронов;
нейронная сеть;
нервная система;
мыслительная деятельность;
мозг.
Существует подобие между мозгом и цифровым компьютером: оба оперируют
электронными сигналами, оба состоят из большого количества простых элементов,
оба выполняют функции, являющиеся, грубо говоря, вычислительными, тем не менее,
существуют и фундаментальные отличия. По сравнению с микросекундными и даже
наносекундными интервалами вычислений современных компьютеров нервные импульсы
являются слишком медленными. Хотя каждый нейрон требует наличия миллисекундного
интервала между передаваемыми сигналами, высокая скорость вычислений мозга
обеспечивается огромным числом параллельных вычислительных блоков, причем
количество их намного превышает доступное современным ЭВМ. Диапазон ошибок
представляет другое фундаментальное отличие: ЭВМ присуща свобода от ошибок,
если входные сигналы безупречно точны и ее аппаратное и программное обеспечение
не повреждены. Мозг же часто производит лучшее угадывание и приближение при
частично незавершенных и неточных входных сигналах. Часто он ошибается, но
величина ошибки должна гарантировать наше выживание в течение миллионов лет.
Эти две системы явно различаются в каждой своей части. Они оптимизированы для
решения различных типов проблем, имеют существенные различия в структуре и их
работа оценивается различными критериями.
Развитие искусственных нейронных сетей вдохновляется биологией. Структура
искусственных нейронных сетей была смоделирована как результат изучения человеческого
мозга. Искусственные нейронные сети чрезвычайно разнообразны по своим
конфигурациям, функциональности и целевому назначению. Рассматривая сетевые
конфигурации и алгоритмы, исследователи мыслят их в терминах организации
мозговой деятельности, но на этом аналогия может и закончиться. Сходство между
ними очень незначительно, однако, даже эта скромная эмуляция мозга дает
ощутимые результаты.
Например, искусственные нейронные сети имеют такие аналогичные мозгу
свойства, как способность обучаться на опыте, основанном на знаниях, делать
абстрактные умозаключения и совершать ошибки, что является более характерным
для человеческой мысли, чем для созданных человеком компьютеров. Разработчикам
сетей приходится выходить за пределы современных биологических знаний в поисках
структур, способных выполнять полезные функции. Во многих случаях это приводит
к необходимости отказа от биологического правдоподобия, мозг становится просто
метафорой, и создаются сети, невозможные в живой материи или требующие
неправдоподобно больших допущений об анатомии и функционировании мозга.
В настоящее время возникли и остаются две взаимно обогащающие друг друга
цели нейронного моделирования: первая - понять функционирование нервной системы
человека на уровне физиологии и психологии и вторая - создать вычислительные
системы (искусственные нейронные сети), выполняющие функции, сходные с
функциями мозга. Нейроны можно моделировать довольно простыми автоматами, а вся
сложность мозга, гибкость его функционирования и другие важнейшие качества определяются
связями между нейронами.
Каждая связь представляется как простой элемент, служащий для передачи
сигнала и его линейного усиления или ослабления.
Существует большой класс задач: нейронные системы ассоциативной памяти,
статистической обработки, фильтрации и другие, для которых связи формируются по
определенным формулам, при этом обучение нейронных сетей оказалось осуществимым
при моделировании задач на обычных персональных компьютерах.
.6
Искусственные нейронные сети
Сегодня, как и сто лет назад, несомненно, что мозг работает более
эффективно и принципиально другим образом, чем любая вычислительная машина,
созданная человеком. Именно этот факт в течение стольких лет побуждает и
направляет работы ученых всего мира по созданию и исследованию искусственных
нейронных сетей (ИНС).
К первым попыткам раскрыть секрет высокой эффективности мозга можно
отнести работу Рамон-и-Кахаля (1911), в которой была высказана идея о нейроне
как структурной единице мозга. Однако нейрон имеет на 5-6 порядков меньшую скорость
срабатывания, чем полупроводниковый логический элемент. Как показали более
поздние исследования, секрет высокой производительности мозга заключается в
огромном количестве нейронов и массивных взаимосвязях между ними.
Сеть нейронов, образующая человеческий мозг, представляет собой
высокоэффективную, комплексную, нелинейную, существенно параллельную систему
обработки информации. Она способна организовать свои нейроны таким образом,
чтобы реализовать восприятие образа, его распознание или управление движением,
во много раз быстрее, чем эти задачи будут решены самыми современными
компьютерами.
ИНС является упрощенной моделью мозга. Она строится на основе
искусственных нейронов, которые обладают тем же основным свойством, что и
живые: пластичностью. Использование структуры мозга и пластичности нейронов
делает ИНС универсальной системой обработки информации. В общем случае ИНС -
это машина, моделирующая способ работы мозга. Обычно ИНС реализуются в виде
электронных устройств или компьютерных программ. Среди многих можно выделить
определение ИНС как адаптивной машины, данное в: искусственная нейронная сеть -
это существенно параллельно распределенный процессор, который обладает
естественной склонностью к сохранению опытного знания и возможностью
предоставления его нам. Она сходна с мозгом в двух аспектах: знание
приобретается сетью в процессе обучения, для сохранения знания используются
силы межнейронных соединений, называемые также синаптическими весами.
Процедура, используемая для осуществления процесса обучения, называется
алгоритмом обучения. Ее функция состоит в модификации синаптических весов ИНС
определенным образом так, чтобы она приобрела необходимые свойства.
Модификация весов является традиционным способом обучения ИНС. Такой
подход близок к теории адаптивных линейных фильтров, которые уже давно и
успешно применяются в управлении. Однако для ИНС существует еще и возможность
модификации собственной топологии, основывающаяся на том факте, что в живом
мозге нейроны могут появляться, умирать и менять свои связи с другими
нейронами.
Из сказанного выше становится ясно, что ИНС реализуют свою вычислительную
мощь, благодаря двум основным своим свойствам: существенно параллельно
распределенной структуре и способности обучаться и обобщать полученные знания.
Под свойством обобщения понимается способность ИНС генерировать правильные
выходы для входных сигналов, которые не были учтены в процессе обучения
(тренировки). Эти два свойства делают ИНС системой переработки информации,
которая решает сложные многомерные задачи, непосильные другим техникам.
С точки зрения машинного обучения, нейронная сеть представляет собой
частный случай методов распознавания образов, дискриминантного анализа, методов
кластеризации и т.п. С математической точки зрения, обучение нейронных сетей -
это многопараметрическая задача нелинейной оптимизации. С точки зрения
кибернетики, нейронная сеть используется в задачах адаптивного управления и как
алгоритмы для робототехники. С точки зрения развития вычислительной техники и
программирования, нейронная сеть - способ решения проблемы эффективного
параллелизма. А с точки зрения искусственного интеллекта, ИНС является основой
философского течения коннективизма и основным направлением в структурном
подходе по изучению возможности построения (моделирования) естественного
интеллекта с помощью компьютерных алгоритмов.
Нейронные сети не программируются в привычном смысле этого слова, они
обучаются. Возможность обучения - одно из главных преимуществ нейронных сетей
перед традиционными алгоритмами. Технически обучение заключается в нахождении
коэффициентов связей между нейронами. В процессе обучения нейронная сеть
способна выявлять сложные зависимости между входными данными и выходными, а
также выполнять обобщение. Это значит, что, в случае успешного обучения, сеть
сможет вернуть верный результат на основании данных, которые отсутствовали в
обучающей выборке, а также неполных и/или "зашумленных", частично
искаженных данных.
Искусственная нейронная сеть (ИНС, нейронная сеть) - это набор нейронов,
соединенных между собой. Как правило, передаточные функции всех нейронов в
нейронной сети фиксированы, а веса являются параметрами нейронной сети и могут
изменяться. Некоторые входы нейронов помечены как внешние входы нейронной сети,
а некоторые выходы - как внешние выходы нейронной сети. Подавая любые числа на
входы нейронной сети, мы получаем какой-то набор чисел на выходах нейронной
сети. Таким образом, работа нейронной сети состоит в преобразовании входного
вектора в выходной вектор, причем это преобразование задается весами нейронной
сети.
Искусственная нейронная сеть это совокупность нейронных элементов и
связей между ними (рис. 1.3).
Основу каждой искусственной нейронной сети составляют относительно
простые, в большинстве случаев - однотипные, элементы (ячейки), имитирующие
работу нейронов мозга (далее под нейроном мы будем подразумевать искусственный
нейрон, ячейку искусственной нейронной сети).

Рис. 1.3. Искусственный нейрон
Нейрон обладает группой синапсов - однонаправленных входных связей,
соединенных с выходами других нейронов. Каждый синапс характеризуется величиной
синоптической связи или ее весом.
Каждый нейрон имеет текущее состояние, которое обычно определяется, как
взвешенная сумма его входов:

Нейрон имеет аксон - выходную связь данного нейрона, с которой сигнал
(возбуждения или торможения) поступает на синапсы следующих нейронов. Выход
нейрона есть функция его состояния:
= f(s)
Функция f называется функцией активации (рис. 1.4).

Рис.1.4 . Функция активации
Функция активации может иметь разный вид:
пороговый (рис. 1.4a),
кусочно-линейный (рис. 1.4б),
пигмоид (рис. 1.4в, 1.4г).
Множество всех нейронов искусственной нейронной сети можно разделить на
подмножества - т.н. слои. Взаимодействие нейронов происходит послойно.
Слой искусственной нейронной сети - это множество нейронов, на которые в
каждый такт времени параллельно поступают сигналы от других нейронов данной
сети
Выбор архитектуры искусственной нейронной сети определяется задачей. Для
некоторых классов задач уже существуют оптимальные конфигурации. Если же задача
не может быть сведена ни к одному из известных классов, разработчику приходится
решать задачу синтеза новой конфигурации. Проблема синтеза искусственной
нейронной сети сильно зависит от задачи, дать общие подробные рекомендации
затруднительно. В большинстве случаев оптимальный вариант искусственной
нейронной сети получается опытным путем.
Искусственные нейронные сети могут быть программного и аппаратного
исполнения. Реализация аппаратная обычно представляет собой параллельный
вычислитель, состоящий из множества простых процессоров.
1.7 Этапы
развития искусственных нейронных сетей
Если опустить чисто биологический этап, то можно сказать, что современная
эпоха развития ИНС началась в 1943 году с пионерской работы Мак-Каллока и
Питтса. В этой работе Мак-Каллок и Питтс ввели понятие "порогового
логического нейрона" и описали логическую модель ИНС.
В 1948 году была опубликована известная книга Винера
"Кибернетика", описывающая ряд важных концепций управления. В более
поздних изданиях в нее были добавлены разделы, посвященные обучению,
самоорганизации и нейрокибернетике.
Следующим событием, продвинувшим развитие ИНС, стал выход в свет книги
Хебба, в которой впервые было представлено физиологическое обучающее правило
модификации синапсов. Хебб предположил, что соединения в мозге непрерывно
меняются по мере того, как организм обучается новым функциональным задачам, и
что таким образом создаются нейронные ансамбли. Хебб следовал сделанному ранее
предположению Рамон-и-Кахаля и ввел "постулат обучения", который
гласит, что эффективность (усиление) переменного синапса между двумя нейронами
увеличивается в процессе повторяющейся активации одного нейрона другим через
этот синапс.
Книга Хебба стала настоящим источником вдохновения для создания
обучающихся и адаптивных систем. Работы Рочестера, Холланда, Хейбта и Дуде в
1956 г. были, наверное, первыми попытками использовать компьютерное
моделирование для тестирования теории ИНС, базирующейся не постулате обучения
Хебба. Полученные ими результаты показали, что не только активация, но и
торможение должны присутствовать в процессе обучения. В тот же год Уитли
продемонстрировал, что ИНС с модифицируемыми синапсами может быть обучена
классифицировать простые наборы бинарных шаблонов по соответствующим классам. В
более поздней своей работе Уитли также выдвинул гипотезу о том, что
эффективность переменного синапса в нервной системе зависит от статистических взаимоотношений
между изменяющимися состояниями с обеих сторон от синапса, тем самым проведя
связь с информационной теорией Шеннона.
В 1952 году вышла в свет книга Эшби "Design for a Brain: The Origin
of Adaptive Behavior". Одна из главных идей этой книги состоит в том, что адаптивное поведение
живых систем не является наследственным, а скорее появляется в процессе
обучения, и что обычно в процессе обучения поведение живых систем улучшается.
Важным моментом в истории ИНС было написание Минским в 1954 году докторской
диссертации, посвященной ИНС. В 1961 году он опубликовал статью "Steps
Toward Artificial Intelligence", которая была посвящена искусственному
интеллекту и содержала большой раздел, посвященный тому, что сейчас называют
ИНС.
Необходимо отметить огромную важность работ фон Неймана по созданию
цифровых компьютеров для развития всего кибернетического направления. Особое
значение для теории ИНС имела его идея избыточности, которая подтолкнула
Винограда и Коуэна (1963) [14] к созданию распределенного избыточного
представления ИНС.
Примерно 15 лет спустя появления эпохальной статьи Мак-Каллока и Питтса,
в 1958 году Розенблатт в своей работе, посвященной перцептрону [15], предложил
новый подход к решению задачи распознания шаблонов. В ней он ввел так называемую
теорему о сходимости перцептрона, доказательство которой появилось лишь в 1960
году. В 1960 Видроу и Хофф предложили метод наименьших квадратов и использовали
его для описания Adaline. Основное различие между перцептроном и Adaline лежало
в процедурах их обучения.
Одной из первых обучаемых ИНС со слойной структурой был Madaline,
предложенный Видроу и его студентами в 1962 г. Не менее важным событием было
введение в 1967 г. Коуэн сигмоидальной активационной функции для модели
логического нейрона.
В течение классического периода перцептрона 60-х годов казалось, что ИНС
могут делать все. Однако в 1969 г. вышла книга Минского и Пейперта, в которой
строго математически было доказано существование фундаментальных ограничений
возможностей однослойного перцептрона. Также было показано, что однослойная
сеть любой размерности не может решать задачи доступные многослойным
конфигурациям.
Для многослойных перцептронов десятилетие 70-х не принесло ничего нового.
Это было связано отчасти с низким уровнем финансирования работ, отчасти с
отсутствием персональных компьютеров. Негативное влияние оказало также не
подтвердившееся позже мнение об аналогии между спиновыми стеклами и ИНС. С
другой стороны, в это же время были получены значительные результаты в развитии
самоорганизующихся карт на базе соревновательного обучения. В 1976 году фон
Мальсбург и Вильшоу опубликовали первую работу по самоорганизующимся картам,
продемонстрировав действующую самоорганизующуюся ИНС.
С начала 80-х наступил новый период в развитии ИНС. Основными событиями
были разработка Хопфилдом ИНС с полностью связанной структурой и оригинальным
алгоритмом настройки весов. В 1982 в продолжение исследований фон Мальсбурга
выходит работа Кохонена, посвященная самоорганизующимся картам. Но настоящий
прорыв в применении ИНС для решения практических задач (в том числе и
управления) был сделан после того, как в 1986 г. Румельхарт, Хинтон и Вильямс
описали алгоритм обратного распространения. Это был первый эффективный алгоритм
обучения многослойных перцептронов любой структуры (и, как оказалось позже, не
только их).
Интересно, что в еще 1985 г. независимо вышли две работы Паркера и
Ле-Кана с описанием алгоритма обратного распространения. Однако оказалось, что
впервые этот алгоритм был детально описан в 1974 г. в докторской диссертации
Вербоса. К сожалению, тогда на него никто не обратил внимания, и потребовалось
более десяти лет, чтобы эта простая, но изящная схема была переоткрыта.
В 1988 г. произошло последнее на сегодняшний день крупное открытие в
теории ИНС, связанное с введением Брумхедом и Лоуе РБФ-сетей. Это -
альтернативная многослойному перцептрону схема слойной прямонаправленной сети,
использующая скрытые нейроны с радиально-базисной активационной функцией.
Идеологически идея радиально-базисных функции связана с методом потенциальных
функций, предложенным в 1964 г. Башкировым, Браверманом и Мучником. В своих
работах Брумхед и Лоуе не только предложили новый метод синтеза ИНС, но и
уделили огромное внимание установлению связей между ИНС и классическими методами
численного анализа, а также теорией линейных адаптивных фильтров.
.8
Архитектура искусственных нейронных сетей
ИНС может рассматриваться как направленный граф со взвешенными связями, в
котором искусственные нейроны являются узлами. По архитектуре связей ИНС могут
быть сгруппированы в два класса (рис. 1.5): сети прямого распространения, в
которых графы не имеют петель, и рекуррентные сети, или сети с обратными
связями.

Рис. 1.5. Архитектуре связей ИНС
В наиболее распространенном семействе сетей первого класса, называемых
многослойным персептроном, нейроны расположены слоями и имеют однонаправленные
связи между слоями. На рис. представлены типовые сети каждого класса. Сети
прямого распространения являются статическими в том смысле, что на заданный
вход они вырабатывают одну совокупность выходных значений, не зависящих от
предыдущего состояния сети. Рекуррентные сети являются динамическими, так как в
силу обратных связей в них модифицируются входы нейронов, что приводит к
изменению состояния сети.
В общем случае понятие "искусственная нейронная сеть"
охватывает ансамбли нейронов любой структуры, однако практическое применение
нашли только некоторые из них. Это объясняется тем, что архитектура ИНС
непосредственно связана с методом ее обучения. Даже различные этапы развития
ИНС определялись появлением новых архитектур сетей и специально разработанных
для них методов обучения.
Искусственный нейрон (или просто нейрон) является элементарным
функциональным модулем, из множества которых строятся ИНС. Он представляет
собой модель живого нейрона, однако лишь в смысле осуществляемых им
преобразований, а не способа функционирования. Существуют логические,
непрерывные и импульсные [28] модели нейрона. Логические модели нейрона (в частности,
описываемый картой Вена формальный нейрон) активно исследовались в 60-70-х
годах, но не получили дальнейшего развития. Импульсные модели более близки к
физической природе процессов, происходящих в нервной клетке, однако их теория
не так развита как у непрерывных, и они все еще не находят широкого применения.
Нейрон (рис. 1.6) состоит из:
Адаптивный сумматор вычисляет скалярное произведение вектора входного
сигнала на вектор параметров. Адаптивным он называется из-за наличия вектора
настраиваемых параметров. Для многих задач полезно иметь линейную неоднородную
функцию выходных сигналов, для этого добавляют постоянный единичный входной
сигнал.
Нелинейный преобразователь сигнала - получает скалярный входной сигнал и
соответствующим образом его преобразовывает.
Точка ветвления служит для рассылки одного сигнала по нескольким адресам.
Она получает скалярный входной сигнал и передает его всем своим выходам.

Рис. 1.6 Формальный нейрон
Формальный нейрон реализует передаточную функцию:
 (1.1)
(1.1)
Из формальных нейронов можно составлять слои нейронов, которые в свою
очередь можно объединять в многослойные сети (рис. 1.7). Нейроны входного слоя
получают сигналы, преобразуют их и через точки ветвления передают нейронам
скрытого слоя. Далее срабатывает следующий слой вплоть до выходного, который
выдает сигналы для интерпретатора и пользователя. Каждый вывод нейронов любого
слоя подается на вход всех нейронов следующего слоя. Число нейронов в слое может
быть любым.

Рис.1.7. Искусственная нейронная сеть
2. Проблема
классификации данных
.1
Рецепторная структура восприятия информации
Для того чтобы человек сознательно воспринял информацию, она должна
пройти довольно длительный цикл предварительной обработки. Вначале свет
попадает в глаз. Пройдя через всю оптическую систему фотоны, в конце концов,
попадают на сетчатку - слой светочувствительных клеток - палочек и колбочек
(рис. 2.1).

Рис. 2.1 Структура зрительного аппарата.
Уже здесь - еще очень далеко от головного мозга, происходит первый этап
обработки информации, поскольку, например, у млекопитающих, сразу за
светочувствительными клетками находится обычно два слоя нервных клеток, которые
выполняют сравнительно несложную обработку.
Теперь информация поступает по зрительному нерву в головной мозг
человека, в так называемые "зрительные бугры", на которые
проецируется зрительная информация то, что мы видим. Далее зрительная информация
поступает в отделы мозга, которые уже выделяют из нее отдельные составляющие -
горизонтальные, вертикальные, диагональные линии, контуры, области светлого,
темного, цветного. Постепенно линии становятся все более сложными и размытыми,
но графический образ пройдет еще долгий путь, прежде чем достигнет уровня
сознания.
К проблеме классификации данных можно подходить, отталкиваясь от аналогии
с биологическими процессами. В некоторых условиях способности животных к
распознаванию превышают способности любой машины, которую только можно
построить.
При классификации, основанной на непосредственном сенсорном опыте, т.е.
при распознавании лиц или произнесенных слов, люди легко превосходят
технические устройства. В "несенсорных ситуациях! действия людей не столь
эффективны. Например, люди не могут соперничать с программами классификации
данных, если правильный класс классификации включает логические комбинации
свойств. Поскольку это должно быть функцией нейронов животного, можно искать
ключ к биологическому распознаванию данных в свойствах самого нейрона. Для
многих целей нейрон можно рассматривать как пороговый элемент. Это значит, что
он либо дает на выходе некоторую постоянную величину, если сумма его входов
достигает определенного значения, либо же остается пассивным. Мак-Каллок и
Питтс доказали, что любую вычислимую функцию можно реализовать с помощью
должным образом организованной сети идеальных нейронов - пороговых элементов,
логические свойства которых с достаточным основанием можно приписать реальному
нейрону. Проблема состоит в том, можно ли найти разумный принцип реорганизации
сети, позволяющий случайно объединенной вначале группе идеальных нейронов
самоорганизоваться в "вычислительное устройство", способное решать
произвольную задачу. Такой принцип реорганизации явился бы теорией обучения,
применимой на уровне отдельного нейрона.
.2 Понятие
класса
Класс - классификационная группировка в системе классификации,
объединяющая определенную группу объектов по некоторому признаку. Образное
восприятие мира - одно из свойств живого мозга, позволяющее разобраться в
бесконечном потоке воспринимаемой информации и сохранять ориентацию в
разрозненных данных о внешнем мире. Воспринимая внешний мир, мы всегда
производим классификацию информации, т.е. разбиваем их на группы похожих, но не
тождественных явлений. Например, несмотря на существенное различие, к одной
группе относятся все буквы "А", написанные различными почерками, или
все звуки, соответствующие одной и той же ноте, взятой в любой октаве и на любом
инструменте. Для составления понятия о группе восприятий достаточно
ознакомиться с незначительным количеством ее представителей. Это свойство мозга
позволяет сформулировать такое понятие, как класс.
Классы обладают характерным свойством, проявляющимся в том, что ознакомление
с конечным числом явлений из одного и того же множества дает возможность
узнавать сколь угодно большое число его представителей.
Классы обладают характерными объективными свойствами в том смысле, что
разные люди, обучающиеся на различном материале наблюдений, большей частью
одинаково и независимо друг от друга классифицируют одни и те же объекты.
Именно эта объективность образов позволяет людям всего мира понимать друг
друга.
Способность восприятия внешнего мира в форме классов позволяет с определенной
достоверностью узнавать бесконечное число объектов на основании ознакомления с
конечным их числом, а объективный характер основного свойства классов позволяет
моделировать процесс их распознавания.
.3 Проблема
кластеризации данных
Классификация - это задача идентификации объекта или определения каких-
либо его свойств по его изображению (оптическое распознавание), числовым
параметрам или аудиозаписи (акустическое распознавание).
В процессе биологической эволюции многие животные с помощью зрительного и
слухового аппарата решили эту задачу достаточно хорошо.
Создание искусственных систем с функциями классификации остаётся сложной
технической проблемой.

Рис. 2.2. Пример объектов обучения.
В целом проблема кластеризации состоит из двух частей: обучения и
кластеризации. Обучение осуществляется путем ввода отдельных векторов с
указанием их принадлежности тому или другому классу. В результате обучения
распознающая система должна приобрести способность реагировать одинаковыми
реакциями на все объекты одного класса и другими реакциями - на все объекты
отличимых классов. Очень важно, что процесс обучения должен завершиться только
путем показов конечного числа объектов. В качестве объектов обучения могут быть
либо векторы (рис. 2.2), либо другие визуальные изображения (буквы, цифры).
Важно, что в процессе обучения указываются только сами объекты и их
принадлежность классу. За обучением следует процесс распознавания новых
объектов, который характеризует действия уже обученной системы. Автоматизация
этих процедур и составляет проблему обучения распознаванию классов. В том
случае, когда человек сам разгадывает или придумывает, а затем навязывает
машине правило классификации, проблема распознавания решается частично, так как
основную и главную часть проблемы (обучение) человек берет на себя.
Круг задач, которые могут решаться с помощью классифицирующих систем,
чрезвычайно широк. Сюда относятся не только задачи распознавания точек и
векторов, но и задачи классификации сложных процессов и явлений, возникающих,
например, при выборе целесообразных действий руководителем предприятия или
выборе оптимального управления технологическими, экономическими, транспортными
или военными задачами. Прежде чем начать анализ какого-либо объекта, нужно получить
о нем определенную, упорядоченную информацию.
Выбор исходного описания объектов является одной из центральных задач
проблемы кластеризации. При удачном выборе исходного описания (пространства
параметров) задача распознавания может оказаться тривиальной и, наоборот,
неудачно выбранное исходное описание может привести либо к очень сложной
дальнейшей переработку информации, либо вообще к отсутствию решения.
.4
Геометрический и структурный подходы
Любой набор данных, который возникает в результате наблюдения какого-либо
объекта в процессе обучения или экзамена, можно представить в виде вектора, а
значит и в виде точки некоторого пространства признаков. Если утверждается, что
при вводе образцов возможно однозначно отнести их к одному из двух (или нескольких)
классов, то тем самым утверждается, что в некотором пространстве существует две
(или несколько) области, не имеющие общих точек, и что класс - точки из этих
областей. Каждой такой области можно приписать наименование, т.е. дать
название, соответствующее классу.
Проинтерпретируем теперь в терминах геометрической картины процесс
обучения классификации данных, ограничившись пока случаем распознавания только
двух векторов. Заранее считается известным лишь только то, что требуется
разделить две области в некотором пространстве, и что показываются точки только
из этих областей. Сами эти области заранее не определены, т. е. нет каких-либо
сведений о расположении их границ или правил определения принадлежности точки к
той или иной области.
В ходе обучения предъявляются точки, случайно выбранные из этих областей,
и сообщается информация о том, к какой области принадлежат предъявляемые точки.
Никакой дополнительной информации об этих областях, т.е. о расположении их
границ, в ходе обучения не сообщается. Цель обучения состоит либо в построении
поверхности, которая разделяла бы не только показанные в процессе обучения
точки, но и все остальные точки, принадлежащие этим областям, либо в построении
поверхностей, ограничивающих эти области так, чтобы в каждой из них находились
только точки одного класса. Цель обучения состоит в построении таких функций от
векторов, которые были бы, например, положительны на всех точках одного и
отрицательны на всех точках другого класса. В связи с тем, что области не имеют
общих точек, всегда существует целое множество таких разделяющих функций, а в
результате обучения должна быть построена одна из них (рис. 2.3).
Если предъявляемые векторы принадлежат не двум, а большему числу классов,
то задача состоит в построении по показанным в ходе обучения точкам
поверхности, разделяющей все области, соответствующие этим классам, друг от
друга. Задача эта может быть решена, например, путем построения функции,
принимающей над точками каждой из областей одинаковое значение, а над точками
из разных областей значение этой функции должно быть различно.

Рис. 2.3. Разделение двух классов в пространстве.
Наряду с геометрической интерпретацией проблемы обучения классификации
существует и иной подход, который назван структурным, или лингвистическим.
Поясним лингвистический подход на примере распознавания зрительных изображений.
Сначала выделяется набор исходных понятий - типичных фрагментов, встречающихся
на изображениях, и характеристик взаимного расположения фрагментов -
"слева", "снизу", "внутри" и т.д. Эти исходные
понятия образуют словарь, позволяющий строить различные логические
высказывания. Задача состоит в том, чтобы из большого количества высказываний,
которые могли бы быть построены с использованием этих понятий, отобрать
наиболее существенные для данного конкретного случая.
Далее, просматривая конечное и по возможности небольшое число объектов из
каждого образа, нужно построить описание этих образов. Построенные описания
должны быть столь полными, чтобы решить вопрос о том, к какому образу
принадлежит данный объект. При реализации лингвистического подхода возникают
две задачи: задача построения исходного словаря, т.е. набор типичных
фрагментов, и задача построения правил описания из элементов заданного словаря.
В рамках лингвистической интерпретации проводится аналогия между
структурой изображений и синтаксисом языка. Стремление к этой аналогии было
вызвано возможностью, использовать аппарат математической лингвистики, т.е.
методы по своей природе являются синтаксическими. Использование аппарата
математической лингвистики для описания структуры изображений можно применять
только после того, как произведена сегментация изображений на составные части,
т.е. выработаны слова для описания типичных фрагментов и методы их поиска.
После предварительной работы, обеспечивающей выделение слов, возникают
собственно лингвистические задачи, состоящие из задач автоматического
грамматического разбора описаний для распознавания изображений. При этом
проявляется самостоятельная область исследований, которая требует не только
знания основ математической лингвистики, но и овладения приемами, которые
разработаны специально для лингвистической обработки изображений.
.5 Гипотеза
компактности
Если предположить, что в процессе обучения пространство признаков
формируется исходя из задуманной классификации, то задание в пространстве
признаков само по себе задает свойство, под действием которого образы в этом
пространстве легко разделяются. Гипотеза компактности гласит: компактным
классам соответствуют компактные множества в пространстве признаков. Под
компактным множеством понимаются некие "сгустки" точек в пространстве
изображений, предполагая, что между этими сгустками существуют разделяющие их
разряжения. Эту гипотезу не всегда удавалось подтвердить экспериментально,
однако те задачи, в рамках которых гипотеза компактности хорошо выполнялась
(рис. 2.3), находилось простое решение. И наоборот, те задачи, для которых
гипотеза не подтверждалась (рис. 2.3), либо совсем не решались, либо решались с
большим трудом. Этот факт заставил, по меньшей мере, усомниться в
справедливости гипотезы компактности, так как для опровержения любой гипотезы
достаточно одного отрицающего ее примера. Вместе с этим, выполнение гипотезы
всюду там, где удавалось хорошо решить задачу обучения классификации, сохраняло
к этой гипотезе интерес. Сама гипотеза компактности превратилась в признак
возможности удовлетворительного решения задач классификации.
Формулировка гипотезы компактности подводит вплотную к понятию абстрактного
класса. Если координаты пространства выбирать случайно, то и векторы в нем
будут распределены случайно. Они будут в некоторых частях пространства
располагаться более плотно, чем в других. В случайно выбранном абстрактном
пространстве почти наверняка будут существовать компактные множества точек.
Поэтому в соответствии с гипотезой компактности множества объектов, которым в
абстрактном пространстве соответствуют компактные множества точек, будут
абстрактными классами данного пространства.
.6 Обучение,
самообучение и адаптация
Обучение - это процесс, в результате которого система постепенно
приобретает способность отвечать нужными реакциями на определенные совокупности
внешних воздействий, а адаптация - это подстройка параметров и структуры
системы с целью достижения требуемого качества управления в условиях
непрерывных изменений внешних условий. Все картинки, представленные на рис.2.2,
характеризуют задачу обучения. В каждой из этих задач задается несколько
примеров (обучающая последовательность) правильно решенных задач. Если бы
удалось подметить некое всеобщее свойство, не зависящее ни от природы классов,
ни от их изображений, а определяющее лишь их способность к разделимости, то
наряду с обычной задачей обучения кластеризации с использованием информации о
принадлежности каждого объекта из обучающей последовательности тому или иному
классу, можно было бы поставить иную классификационную задачу - так называемую
задачу обучения без учителя. Задачу такого рода на описательном уровне можно
сформулировать следующим образом: системе одновременно или последовательно
предъявляются объекты без каких-либо указаний об их принадлежности к классам.
Входное устройство системы отображает множество объектов на множество классов
и, используя некоторое заложенное в нее заранее свойство разделимости классов,
производит самостоятельную классификацию этих объектов. После такого процесса
самообучения система должна приобрести способность к распознаванию не только
уже знакомых объектов (объектов из обучающей последовательности), но и тех,
которые ранее не предъявлялись. Процессом самообучения некоторой системы
называется такой процесс, в результате которого эта система без подсказки
учителя приобретает способность к выработке одинаковых реакций на изображения
объектов одного и того же образа и различных реакций на изображения различных
образов. Роль учителя при этом состоит лишь в подсказке системе некоторого
объективного свойства, одинакового для всех образов и определяющего способность
к разделению множества объектов на образы. Таким объективным свойством является
свойство компактности образов. Взаимное расположение точек в выбранном
пространстве уже содержит информацию о том, как следует разделить множество
точек. Эта информация и определяет то свойство разделимости классов, которое
оказывается достаточным для самообучения системы распознаванию классов.
Обучением обычно называют процесс выработки в некоторой системе той или
иной реакции на группы внешних идентичных сигналов путем многократного
воздействия на систему внешней корректировки. Такую внешнюю корректировку в
обучении принято называть "поощрениями" и "наказаниями".
Механизм генерации этой корректировки практически полностью определяет алгоритм
обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация
о верности реакции системе не сообщается.
Большинство известных алгоритмов самообучения способны выделять только
абстрактные классы, т.е. компактные множества в заданных пространствах.
Различие между ними состоит, в формализации понятия компактности. Результат
самообучения характеризует пригодность выбранного пространства для конкретной
задачи обучения классификации. Если абстрактные классы, выделяемые в процессе
самообучения, совпадают с реальными, то пространство выбрано удачно. Чем
сильнее абстрактные классы отличаются от реальных, тем "неудобнее"
выбранное пространство для конкретной задачи.
Адаптация - это процесс изменения параметров и структуры системы, а
возможно, и управляющих воздействий на основе текущей информации с целью
достижения определенного состояния системы при начальной неопределенности и
изменяющихся условиях работы.
Возможен способ построения классифицирующих машин машин, основанный на
различении каких-либо признаков подлежащих распознаванию фигур. В качестве
признаков могут быть выбраны различные особенности, например, геометрические
свойства (характеристики составляющих фигуры кривых), топологические свойства
(взаимное расположение элементов фигуры) и т.п. Известны кластеризующие машины,
в которых различение производится, по так называемому "методу зондов"
(рис. 2.3), т.е. по числу пересечений контура класса с несколькими особым
образом расположенными прямыми. Если проектировать классы на поле с зондами, то
окажется, что каждый из классов пересекает вполне определенные зонды, причем
комбинации пересекаемых зондов различны для всех классов. Эти комбинации и
используются в качестве признаков, по которым производится различение классов.
Такие машины успешно справляются, например, с чтением машинописного текста, но
их возможности ограничены тем шрифтом (или группой сходных шрифтов), для
которого была разработана система признаков. Работа по созданию набора
эталонных данных или системы признаков должна производиться человеком. Качество
работы машины, т.е. надежность "узнавания" предъявляемых данных
определяется качеством этой предварительной подготовки и без участия человека
не может быть повышено. Описанная машина не являются обучающейся машиной.
Моделирование процесса обучения подразумевает обучение, которому не
предшествует сообщение машине каких-либо сведений о тех кластерах,
распознаванию которых она должна научиться; само обучение заключается в
предъявлении машине некоторого конечного числа объектов каждого кластера. В
результате обучения машина должна оказаться способной узнавать сколь угодно
большое число новых объектов, относящихся к тем же классам. Таким образом,
имеется в виду следующая схема экспериментов:
а) никакие сведения о подлежащих классификации данных в машину заранее не
вводятся;
б) в ходе обучения машине предъявляется некоторое количество объектов
каждого из подлежащих классификации набора данных и (при моделировании процесса
обучения "с учителем") сообщается, к какому классу относится каждый
объект;
в) машина автоматически обрабатывает полученную информацию, после чего
г) с достаточной надежностью различает сколь угодно большое число новых,
ранее ей не предъявлявшихся объектов из классов.
Машины, работающие по такой схеме, называются узнающими машинами.
.7 Подготовка
данных для обучения
При подготовке данных для обучения нейронной сети необходимо обращать
внимание на следующие существенные моменты. Количество наблюдений в наборе
данных. Следует учитывать тот фактор, что чем больше размерность данных, тем
больше времени потребуется для обучения сети. Следует определить наличие
выбросов и оценить необходимость их присутствия в выборке. Обучающая выборка
должна быть представительной (репрезентативной). Обучающая выборка не должна
содержать противоречий, так как нейронная сеть однозначно сопоставляет выходные
значения входным. Нейронная сеть работает только с числовыми входными данными,
поэтому важным этапом при подготовке данных является преобразование и
кодирование данных. При использовании на вход нейронной сети следует подавать
значения из того диапазона, на котором она обучалась. Например, если при
обучении нейронной сети на один из ее входов подавались значения от 0 до 10, то
при ее применении на вход следует подавать значения из этого же диапазона или
близлежащие. Существует понятие нормализации данных. Целью нормализации
значений является преобразование данных к виду, который наиболее подходит для
обработки, т.е. данные, поступающие на вход, должны иметь числовой тип, а их
значения должны быть распределены в определенном диапазоне. Нормализатор может
приводить дискретные данные к набору уникальных индексов либо преобразовывать
значения, лежащие в произвольном диапазоне, в конкретный диапазон, например,
[0..1]. Нормализация выполняется путем деления каждой компоненты входного
вектора на длину вектора, что превращает входной вектор в единичный..
Емкость ИНС - число классов, предъявляемых на входы ИНС для
распознавания. Для разделения множества входных классов, например, по двум
классам достаточно всего одного выхода. При этом каждый логический уровень -
"1" и "0" - будет обозначать отдельный класс. На двух
выходах можно закодировать уже 4 класса и так далее. Для повышения
достоверности классификации желательно ввести избыточность путем выделения
каждому классу одного нейрона в выходном слое или, что еще лучше, нескольких,
каждый из которых обучается определять принадлежность образа к классу со своей
степенью достоверности, например: высокой, средней и низкой. Такие ИНС
позволяют проводить классификацию входных данных, объединенных в нечеткие
(размытые или пересекающиеся) множества. Это свойство приближает подобные ИНС к
условиям реальной жизни.
.7.1
Максимизация энтропии как цель предобработки
Рассмотрим основной руководящий принцип, общий для всех этапов
предобработки данных. Допустим, что в исходные данные представлены в числовой
форме и после соответствующей нормировки все входные и выходные переменные
отображаются в единичном кубе. Задача нейросетевого моделирования - найти
статистически достоверные зависимости между входными и выходными переменными.
Единственным источником информации для статистического моделирования являются
примеры из обучающей выборки. Чем больше бит информации принесет пример - тем
лучше используются имеющиеся в нашем распоряжении данные.
Рассмотрим произвольную компоненту нормированных (предобработанных)
данных. Среднее количество информации, приносимой каждым примером, равно
энтропии распределения значений этой компоненты. Если эти значения
сосредоточены в относительно небольшой области единичного интервала,
информационное содержание такой компоненты мало. В пределе нулевой энтропии,
когда все значения переменной совпадают, эта переменная не несет никакой
информации. Напротив, если значения переменной равномерно распределены в
единичном интервале, информация такой переменной максимальна.
.7.2 Нормировка
данных
Как входами, так и выходами могут быть совершенно разнородные величины.
Очевидно, что результаты нейросетевого моделирования не должны зависеть от
единиц измерения этих величин. А именно, чтобы сеть трактовала их значения
единообразно, все входные и выходные величин должны быть приведены к единому
масштабу. Кроме того, для повышения скорости и качества обучения полезно
провести дополнительную предобработку, выравнивающую распределения значений еще
до этапа обучения.
Индивидуальная нормировка данных.
Приведение к единому масштабу обеспечивается нормировкой каждой
переменной на диапазон разброса ее значений. В простейшем варианте это -
линейное преобразование:
 (2.2)
(2.2)
в единичный отрезок [0;1]. Обобщение для отображения данных в интервал
[-1;1], рекомендуемого для входных данных тривиально.
Линейная нормировка оптимальна, когда значения переменной х плотно
заполняют определенный интервал. Но подобный "прямолинейный" подход
применим далеко не всегда. Так, если в данных имеются относительно редкие
выбросы, намного превышающие типичный разброс, именно эти выбросы определят
согласно предыдущей формуле масштаб нормировки. Это приведет к тому, что
основная масса значений нормированной переменной х сосредоточится вблизи нуля.
Гораздо надежнее, поэтому, ориентироваться при нормировке не а экстремальные
значения, а на типичные, т.е. статистические характеристики данных, такие как
среднее и дисперсия.
 (2.3)
(2.3)
Где  (2.4)
(2.4)
 (2.5)
(2.5)
Единичный масштаб, т.е. типичные значения все переменных будут сравнимы.
Однако, теперь нормированные величины не принадлежат гарантированно
единичному интервалу, более того, максимальный разброс значений заранее не
известен. Для входных данных это может быть и не важно, но выходные переменные
будут использоваться в качестве эталонов для выходных нейронов. В случае, если
выходные нейроны - сигмоидные, они могут принимать значения лишь в единичном диапазоне.
Чтобы установить соответствие между обучающей выборкой и нейросетью в этом
случае необходимо ограничить диапазон изменения переменных.
Линейное преобразование, представленное выше, не способно отнормировать
основную массу данных и одновременно ограничить диапазон возможных значений
этих данных. Естественный выход из этой ситуации - использовать для
предобработки данных функцию активации тех же нейронов. Например, нелинейное
преобразование:
 (2.6)
(2.6)
нормирует основную массу данных одновременно гарантируя что значение х
расположено в диапазоне от "1" до "0".
Все выше перечисленные методы нормировки направлены на то, чтобы
максимизировать энтропию каждого входа (выхода) по отдельности. Но, вообще
говоря, можно добиться гораздо большего максимизируя их совместную энтропию.
Существуют методы, позволяющие проводить нормировку для всей совокупности
входов.
.8
Алгоритмические построения
Алгоритмическая универсальность ЭВМ означает, что на них можно программно
реализовывать (т.е. представить в виде машинной программы) любые алгоритмы
преобразования информации, будь то вычислительные алгоритмы, алгоритмы
управления, поиска доказательства теорем, трехмерные графические или аудио
композиции.
Однако не следует думать, что вычислительные машины и роботы могут в
принципе решать любые задачи.
Было строго доказано существование таких типов задач, для которых
невозможен единый и эффективный алгоритм, решающий все задачи данного типа; в
этом смысле невозможно решение таких задач и с помощью вычислительных машин.
Этот факт способствует лучшему пониманию того, что могут делать машины и
чего они не могут сделать.
2.9 Обучение
искусственных нейронных сетей
Среди свойств искусственных нейронных сетей основным является их
способность к обучению, они обучаются самыми разнообразными методами.
Большинство методов обучения исходят из общих предпосылок, и имеет много
идентичных характеристик. Их обучение напоминает процесс интеллектуального
развития человеческой личности. Возможности обучения искусственных нейронных
сетей ограниченны. Тем не менее, уже получены убедительные достижения, такие
как "говорящая сеть" Сейновского, и возникает много других
практических применений. Сеть обучается, чтобы для некоторого множества входов
давать необходимое множество выходов. Каждое такое входное (или выходное)
множество рассматривается как вектор. Обучение осуществляется путем
последовательного предъявления входных векторов с одновременной подстройкой
весов в соответствии с определенной процедурой. В процессе обучения веса сети
постепенно становятся такими, чтобы каждый входной вектор вырабатывал выходной
вектор.
Обычно обучение нейронной сети осуществляется на некоторой выборке. По
мере процесса обучения, который происходит по некоторому алгоритму, сеть должна
все лучше и лучше (правильнее) реагировать на входные сигналы.
Выделяют три парадигмы обучения: с учителем, самообучение и смешанная. В
первом способе известны правильные ответы к каждому входному примеру, а веса
подстраиваются так, чтобы минимизировать ошибку. Обучение без учителя позволяет
распределить образцы по категориям за счет раскрытия внутренней структуры и
природы данных. При смешанном обучении комбинируются два вышеизложенных
подхода.
Существует большое число алгоритмов обучения, ориентированных на решение
разных задач. Среди них выделяет алгоритм обратного распространения ошибки,
который является одним из наиболее успешных современных алгоритмов. Его
основная идея заключается в том, что изменение весов синапсов происходит с
учетом локального градиента функции ошибки. Разница между реальными и
правильными ответами нейронной сети, определяемыми на выходном слое,
распространяется в обратном направлении (рис. 2.4) - навстречу потоку сигналов.
В итоге каждый нейрон способен определить вклад каждого своего веса в суммарную
ошибку сети. Простейшее правило обучения соответствует методу наискорейшего
спуска, то есть изменения синаптических весов пропорционально их вкладу в общую
ошибку.

Рис. 2.4. Метод обратного распространения ошибки для многослойной
полносвязанной нейронной сети
Конечно, при таком обучении нейронной сети нет уверенности, что она
обучилась наилучшим образом, поскольку всегда существует возможность попадания
алгоритма в локальный минимум (рис. 2.5). Для этого используются специальные
приемы, позволяющие "выбить" найденное решение из локального
экстремума. Если после нескольких таких действий нейронная сеть сходится к тому
же решению, то можно сделать вывод о том, что найденное решение, скорее всего,
оптимально.

Рис. 2.5. Метод градиентного спуска при минимизации ошибки сети
.9.1 Обучение
с учителем
При обучении с учителем существует учитель, который предъявляет входные
образы сети, сравнивает результирующие выходы с требуемыми значениями, а затем
настраивает веса сети таким образом, чтобы уменьшить различия. Обучение с
учителем предполагает, что для каждого входного вектора существует целевой
вектор, представляющий собой требуемый выход. Вместе они называются обучающей
парой. Обычно сеть обучается на некотором числе таких обучающих пар.
Предъявляется выходной вектор, вычисляется выход сети и сравнивается с
соответствующим целевым вектором, разность (ошибка) с помощью обратной связи
подается в сеть, и веса изменяются в соответствии с алгоритмом, стремящимся
минимизировать ошибку. Векторы обучающего множества предъявляются
последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора
до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо
низкого уровня.
.9.2 Обучение
без учителя
Обучение с учителем критиковалось за свою биологическую
неправдоподобность. Трудно вообразить обучающий механизм в мозге, который бы
сравнивал желаемые и действительные значения выходов, выполняя коррекцию с
помощью обратной связи. Обучение без учителя является намного более
правдоподобной моделью обучения в биологической системе. Развитая Кохоненом и
другими, она не нуждается в целевом векторе для выходов и, следовательно, не
требует сравнения с предопределенными идеальными ответами. Обучающее множество
состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети
так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление
достаточно близких входных векторов давало одинаковые выходы. Процесс обучения,
следовательно, выделяет статистические свойства обучающего множества и
группирует сходные векторы в классы. Предъявление на вход вектора из данного
класса даст определенный выходной вектор, но до обучения невозможно предсказать,
какой выход будет производиться данным классом входных векторов. Следовательно,
выходы подобной сети должны трансформироваться в некоторую понятную форму,
обусловленную процессом обучения.
Главная черта, делающая обучение без учителя привлекательным, - это его
"самостоятельность". Процесс обучения, как и в случае обучения с
учителем, заключается в подстраивании весов синапсов. Некоторые алгоритмы,
правда, изменяют и структуру сети, то есть количество нейронов и их
взаимосвязи, но такие преобразования правильнее назвать более широким термином
- самоорганизацией, и в рамках данной главы они рассматриваться не будут.
Очевидно, что подстройка синапсов может проводиться только на основании
информации, доступной в нейроне, то есть его состояния и уже имеющихся весовых
коэффициентов. Исходя из этого соображения и, что более важно, по аналогии с
известными принципами самоорганизации нервных клеток, построены алгоритмы
обучения Хебба.
Сигнальный метод обучения Хебба заключается в изменении весов по
следующему правилу:
 (2.7)
(2.7)
где yi(n-1) - выходное значение нейрона i слоя (n-1), yj(n) - выходное
значение нейрона j слоя n; wij(t) и wij(t-1) - весовой коэффициент синапса,
соединяющего эти нейроны, на итерациях t и t-1 соответственно; a - коэффициент
скорости обучения. Здесь и далее, для общности, под n подразумевается
произвольный слой сети. При обучении по данному методу усиливаются связи между
возбужденными нейронами.
Существует также и дифференциальный метод обучения Хебба.
 (2.8)
(2.8)
Здесь yi(n-1)(t) и yi(n-1)(t-1) - выходное значение нейрона i слоя n-1
соответственно на итерациях t и t-1; yj(n)(t) и yj(n)(t-1) - то же самое для
нейрона j слоя n. Как видно из формулы (2), сильнее всего обучаются синапсы,
соединяющие те нейроны, выходы которых наиболее динамично изменились в сторону
увеличения.
Полный алгоритм обучения с применением вышеприведенных формул будет
выглядеть так:
. На стадии инициализации всем весовым коэффициентам присваиваются небольшие
случайные значения.
. На входы сети подается входной образ, и сигналы возбуждения
распространяются по всем слоям согласно принципам классических прямопоточных
(feedforward) сетей[1], то есть для каждого нейрона рассчитывается взвешенная
сумма его входов, к которой затем применяется активационная (передаточная)
функция нейрона, в результате чего получается его выходное значение yi(n),
i=0...Mi-1, где Mi - число нейронов в слое i; n=0...N-1, а N - число слоев в
сети.
. На основании полученных выходных значений нейронов по формуле (2.7) или
(2.8) производится изменение весовых коэффициентов.
. Цикл с шага 2, пока выходные значения сети не застабилизируются с
заданной точностью. Применение этого нового способа определения завершения
обучения, отличного от использовавшегося для сети обратного распространения,
обусловлено тем, что подстраиваемые значения синапсов фактически не ограничены.
На втором шаге цикла попеременно предъявляются все образы из входного
набора.
Следует отметить, что вид откликов на каждый класс входных образов не
известен заранее и будет представлять собой произвольное сочетание состояний
нейронов выходного слоя, обусловленное случайным распределением весов на стадии
инициализации. Вместе с тем, сеть способна обобщать схожие образы, относя их к
одному классу. Тестирование обученной сети позволяет определить топологию
классов в выходном слое. Для приведения откликов обученной сети к удобному
представлению можно дополнить сеть одним слоем, который, например, по алгоритму
обучения однослойного перцептрона необходимо заставить отображать выходные
реакции сети в требуемые образы.
Другой алгоритм обучения без учителя - алгоритм Кохонена -
предусматривает подстройку синапсов на основании их значений от предыдущей
итерации.
 (2.9)
(2.9)
Из вышеприведенной формулы видно, что обучение сводится к минимизации
разницы между входными сигналами нейрона, поступающими с выходов нейронов
предыдущего слоя y i(n-1), и весовыми коэффициентами его синапсов.
Полный алгоритм обучения имеет примерно такую же структуру, как в методах
Хебба, но на шаге 3 из всего слоя выбирается нейрон, значения синапсов которого
максимально походят на входной образ, и подстройка весов по формуле (2.9)
проводится только для него. Эта, так называемая, аккредитация может
сопровождаться затормаживанием всех остальных нейронов слоя и введением
выбранного нейрона в насыщение. Выбор такого нейрона может осуществляться,
например, расчетом скалярного произведения вектора весовых коэффициентов с
вектором входных значений. Максимальное произведение дает выигравший нейрон.
Другой вариант - расчет расстояния между этими векторами в p-мерном
пространстве, где p - размер векторов.
 (2.10)
(2.10)
где j - индекс нейрона в слое n, i - индекс суммирования по нейронам слоя
(n-1), wij - вес синапса, соединяющего нейроны; выходы нейронов слоя (n-1)
являются входными значениями для слоя n. Корень в формуле (2.10) брать не
обязательно, так как важна лишь относительная оценка различных Dj.
В данном случае, "побеждает" нейрон с наименьшим расстоянием.
Иногда слишком часто получающие аккредитацию нейроны принудительно исключаются
из рассмотрения, чтобы "уравнять права" всех нейронов слоя.
Простейший вариант такого алгоритма заключается в торможении только что
выигравшего нейрона.
При использовании обучения по алгоритму Кохонена существует практика
нормализации входных образов, а так же - на стадии инициализации - и
нормализации начальных значений весовых коэффициентов.
 (2.11)
(2.11)
где xi - i-ая компонента вектора входного образа или вектора весовых
коэффициентов, а n - его размерность. Это позволяет сократить длительность
процесса обучения.
Инициализация весовых коэффициентов случайными значениями может привести
к тому, что различные классы, которым соответствуют плотно распределенные
входные образы, сольются или, наоборот, раздробятся на дополнительные подклассы
в случае близких образов одного и того же класса. Для избежания такой ситуации
используется метод выпуклой комбинации [3]. Суть его сводится к тому, что
входные нормализованные образы подвергаются преобразованию:
 =
=  (t) *
(t) *  (2.12)
(2.12)
где xi - i-ая компонента входного образа, n - общее число его компонент, α(t) - коэффициент, изменяющийся в
процессе обучения от нуля до единицы, в результате чего вначале на входы сети
подаются практически одинаковые образы, а с течением времени они все больше
сходятся к исходным.
Весовые коэффициенты устанавливаются на шаге инициализации равными
величине:
 (2.13)
(2.13)
где n - размерность вектора весов для нейронов инициализируемого слоя.
На основе рассмотренного выше метода строятся нейронные сети особого типа
- так называемые самоорганизующиеся структуры - self-organizing feature maps
(этот устоявшийся перевод с английского, на мой взгляд, не очень удачен, так
как, речь идет не об изменении структуры сети, а только о подстройке синапсов).
Для них после выбора из слоя n нейрона j с минимальным расстоянием Dj обучается
по формуле (2.10) не только этот нейрон, но и его соседи, расположенные в
окрестности R. Величина R на первых итерациях очень большая, так что обучаются
все нейроны, но с течением времени она уменьшается до нуля. Таким образом, чем
ближе конец обучения, тем точнее определяется группа нейронов, отвечающих
каждому классу образов.
.9.3 Процесс
обучения нейронных сетей
Процесс обучения Искусственной Нейронной Сети (ИНС) новому классу задач
включает следующие стадии:
. Формулируется постановка задачи и выделяется набор ключевых параметров,
характеризующих предметную область.
. Выбирается парадигма нейронной сети (модель, включающая в себя вид
входных данных, пороговой функции, структуры сети и алгоритмов обучения),
наиболее подходящая для решения данного класса задач. Как правило, современные
нейропакеты, нейроплаты и нейрокомпьютеры позволяют реализовать не одну, а
несколько базовых парадигм.
. Подготавливается, возможно, более широкий набор обучающих примеров,
организованных в виде наборов входных данных, ассоциированных с известными
выходными значениями. Входные значения для обучения могут быть неполны и
частично противоречивы.
. Входные данные по очереди предъявляются ИНС, а полученное выходное значение
сравнивается с эталоном. Затем производится подстройка весовых коэффициентов
межнейронных соединений для минимизации ошибки между реальным и желаемым
выходом сети.
. Обучение повторяется до тех пор, пока суммарная ошибка во всем
множестве входных значений не достигнет приемлемого уровня, либо ИНС не придет
в стационарное состояние. Рассмотренный метод обучения нейроподобной сети носит
название "обратное распространение ошибки" (error backpropagation) и
относится к числу классических алгоритмов нейроматематики.
Настроенная и обученная ИНС может использоваться на реальных входных
данных, не только подсказывая пользователю корректное решение, но и оценивая
степень его достоверности.
2.9.4
Алгоритм секущих плоскостей
Существуют различные алгоритмы, позволяющие кластеризовать данные.
Алгоритм обучения машины "узнаванию" классов, основанный на методе
секущих гиперплоскостей (рис.2.6), заключается в аппроксимации разделяющей
гиперповерхности "кусками" гиперплоскостей и состоит из следующих
основных этапов:

Рис. 2.6. Метод секущихся плоскостей
А. Обучение
(формирование разделяющей поверхности):
Проведение секущих плоскостей;
Исключение лишних плоскостей;
Исключение лишних кусков плоскостей.
Б. Распознавание новых объектов.
При использовании метода параллельных вариантов одновременно и независимо
друг от друга на одном и том же материале обучаются несколько машин. При
опознавании новых объектов каждая машина будет относить эти объекты к какому-то
классу, может быть, не к одному и тому же. Окончательное решение принимается
"голосованием" машин - объект относиться к тому классу, к которому
его отнесло большее число машин (нейронов).
Способ повышения надежности классификации состоит в некотором улучшении
метода проведения секущих плоскостей. Можно предположить, что если проводить
секущие плоскости близко к плоскости, проходящей через середину прямой,
соединяющей объект и оппонент, перпендикулярный этой прямой, то результирующая
поверхность будет ближе к истинной границе между классами. Эксперименты
подтверждают это предположение.
Алгоритмы, основанные на методе потенциалов.
В алгоритме, основанном на методе потенциалов, с каждым возбужденным
элементом поля рецепторов можно связать некоторую функцию, равную единице на
этом элементе и убывающую по всем направлениям от него, т.е. функцию ф,
аналогичную электрическому потенциалу с той лишь разницей, что в данном случае
R есть расстояние между двумя соседними элементами поля рецепторов.
 ) (2.14)
) (2.14)
Для подсчета пользуются следующим простым правилом: каждый возбужденный
элемент поля рецепторов имеет "собственный" потенциал, равный
единице, и который в свою очередь увеличивает на У потенциалы всех (в том числе
и возбужденных) соседних с ним элементов по горизонтали, вертикали и
диагоналям. Однако этот метод кодирования может быть улучшен.

Рис. 2.7 Метод потенциалов
Если связать с каждым возбужденным элементом поля рецепторов некоторую
функцию, равную единице на этом элементе и убывающую по всем направлениям от
него, т.е. функцию, аналогичную потенциалу ф, с той лишь разницей, что в данном
случае R есть расстояние между двумя соседними элементами поля рецепторов (рис.
2.7). Эта функция, может быть, аппроксимирована ступенчатой функцией,
постоянной в пределах одного рецептора и скачкообразно изменяющейся на границах
рецепторов.
Простейший алгоритм классификации, построенный на методе потенциалов,
можно осуществить в два этапа:
Обучение (в процессе обучения запоминаются коды всех появившихся точек и
указания, к какому из классов относится каждая точки).
Кластеризация (в процессе кластеризации производится идентификация и
выдается информация, к какому кластеру принадлежит закодированная матрица).
.10 Обучение
сети Кохонена
Искусственная нейронная сеть Кохонена или самоорганизующаяся карта
признаков (SOM) была предложена финским исследователем Тойво Кохоненом в начале
1980-х годов.

Рис. 2.8. Топология нейронной сети Кохонена
Она представляет собой двухслойную сеть (рис.2.8). Каждый нейрон первого
(распределительного) слоя соединен со всеми нейронами второго (выходного) слоя,
которые расположены в виде двумерной решетки.
Нейроны выходного слоя называются кластерными элементами, их количество
определят максимальное количество групп, на которые система может разделить
входные данные. Увеличивая количество нейронов второго слоя можно увеличивать
детализацию результатов процесса кластеризации.
Система работает по принципу соревнования нейроны второго слоя
соревнуются друг с другом за право наилучшим образом сочетаться с входным
вектором сигналов, побеждает тот элемент-нейрон, чей вектор весов ближе всего к
входному вектору сигналов. За меру близости двух векторов можно взять квадрат
евклидова расстояния. Таким образом, каждый входной вектор относится к
некоторому кластерному элементу.
 (2.15)
(2.15)
Для обучения сети Кохонена используется соревновательный метод. На каждом
шаге обучения из исходного набора данных случайно выбирается один вектор. Затем
производится поиск нейрона выходного слоя, для которого расстояние между его
вектором весов и входным вектором - минимально.
По определённому правилу производится корректировка весов для
нейрона-победителя и нейронов из его окрестности, которая задаётся
соответствующей функцией окрестности. В данном случае в качестве функции
окрестности была использована функция Гаусса (рис. 2.9).

Рис.2.9. Функция Гаусса
 (2.16)
(2.16)
где и - номер нейрона в двумерной решетке второго слоя сети, для которого
вычисляем значение h;- номер нейрона-победителя в двумерной решетке второго
слоя сети;- параметр времени;
Радиус окрестности h должен уменьшаться с увеличением параметра времени:
 (2.17)
(2.17)
2.11
Клеточный автомат в нейронных сетях
.11.1
Устройство клеточного автомата
Клеточным автоматом называют сеть из элементов, меняющих свое состояние в
дискретные моменты времени в зависимости от состояния самого элемента и его
ближайших соседей в предшествующий момент времени.
Различные клеточные автоматы могуть демонстрировать весьма разнообразное
поведение, которое может быть адаптировано для целей обработки информации за
счет выбора (а) закона изменения состояния элемента и (б) конкретного
определения понятия "ближайшие соседи". Внимательный читатель без
труда заметит, что, например, нейронная сеть Хопфилда вполне может
рассматриваться, как клеточный автомат, элементами которрого являются
формальные нейроны. В качестве закона изменения состояния нейро-автомата
используется пороговое преобразование взвешенной суммы входов нейронов, а
ближайшими соседями каждого элемента являются все прочие элементы автомата. В
мире клеточных автоматов имеется класиификация (S. Wolfram, 1983), согласно
которой все автоматы делятся на четыре класса, в зависимости от типа динамики
изменяющихся состояний. Автоматы первого класса по истечении конечного времени
достигают однородного состояния, в котором значения всех элементов одинаковы и
не меняются со временем. Ко второму классу автоматов относятся системы,
приводящие к локализованным структурам стационарных или периодических во времени
состояний элементов. Третий класс составляют "блуждающие" автоматы,
которые с течением времени посещают произвольным (непериодическим) образом все
возможные состояния элементов, не задерживаясь ни в одном из них. И, наконец,
четвертый класс составляют "странные" автоматы, характер динамики
которых зависит от особенностей начального состояния элементов. Некоторые
начальные состояния приводят к однородному вырождению автомата, другие - к
возникновению циклической последовательности состояний, третьи - к непрерывно
меняющимся (как "по системе", так и без видимой системы) картинам
активности элементов.
.11.2
Клеточная нейронная сеть
Как и клеточный автомат, КНС представляется в виде дискретного
однородного пространства клеток, расположенных в узлах прямоугольной,
треугольной или гексагональной решётки и взаимодействующих с другими клетками
внутри некоторой локальной окрестности. Однако, в отличие от клеточного
автомата, связи между клетками КНС имеют вес, позволяющий определить
"силу" влияния клеток друг на друга. Кроме того, состояние клетки КНС
описывается непрерывной величиной и определяется как арифметическая, а не
логическая функция состояний клеток окрестности, что является принципиальным
отличием КНС от клеточного автомата. Клеточные нейронные сети впервые были
предложены как модель для построения аналоговых электронных схем обработки
изображений в 1988 году и с тех пор нашли применение в различных областях
исследований. Специфика класса задач, решаемых с помощью КНС, основана на
параллельности и локальности обработки информации в КНС, а также на
непрерывности изменения состояний клеток. Можно выделить две наиболее
характерные области применения КНС:
обработка изображений, например, фильтрация, распознавание образов и
генерация изображений специального типа и
моделирование распределённых нелинейных процессов
реакционно-диффузионного типа, в частности, автоволн, процессов формирования
устойчивых структур и хаотических колебаний. Вторая область применения
привлекает в последнее время всё большее внимание, хотя решению задач из первой
области посвящена существенно большая часть публикаций о КНС.
В исследовании КНС для моделирования распределённых нелинейных процессов
в активных средах можно выделить несколько тенденций, различающихся способом
выбора КНС-модели и её особенностями. Интерес к использованию КНС в качестве
модели нелинейной динамики возник в результате исследования поведения клеточной
нейронной сети, ориентированной на решение задач обработки изображений с
помощью нелинейных электронных схем. В последствии такая КНС была названа
"стандартной", а ориентация на реализацию КНС модели в виде
электронной схемы определила специфику формального представления, в частности,
вид описывающих клетку уравнений и используемой нелинейной функции. Предложенная
в качестве нелинейной, кусочно-линейная функция сигмоидного типа также стала
стандартной для многих КНС-моделей. Основной задачей построения КНС-модели
распределённой нелинейной динамики на основе стандартной КНС стало построение
электронной схемы клетки, уравнения состояния которой описывают, в рамках
некоторой аксиоматики, изменение в каждой точке дискретизированного
пространства моделируемого процесса. Примерами использования стандартной КНС
являются моделирование возникновения устойчивых структур, моделирование
электромагнитного поля. Возможность аналоговой реализации клетки КНС с
практически любой нелинейностью даёт возможность построения КНС, уравнения
состояния которой соответствуют дифференциально-разностным уравнениям для
моделируемого процесса. Аналоговое решение таких уравнений на основе КНС с
помощью микросхемы или средствами универсальной КНС-машины даёт существенно
более высокую скорость и точность моделирования.
Таким образом, накопленный при исследовании различных подходов материал
требует более глубокого теоретического и экспериментального исследования с
целью разработки методов КНС-моделей для классификационных процессов,
ориентированных на применение современных высокопроизводительных вычислительных
систем. Реализация таких моделей на специализированных аналоговых КНС-машинах,
позволяющих на три порядка увеличить скорость обработки информации по сравнению
с находящимися в распоряжении исследователей вычислительными средствами, даёт
возможность существенного увеличения скорости моделирования, однако полностью
не исключает необходимость в вычислительных системах, поскольку пока ещё
имеются большие трудности в аналоговой реализации трёхмерных КНС-моделей. Кроме
того, существует задача выявления количественных соотношений между параметрами
реальных данных и параметрами их КНС-моделей с целью решения практических
исследовательских задач. В связи с этим исследование клеточно-нейронной модели
представляется актуальным.
3.
Классификация данных
.1 Постановка
задачи и сложности, связанные с ее реализацией
В настоящее время одним из актуальных вопросов информационных технологий
является проблема кластеризации данных с применением эффективных методов
нейрообработки информации. Стандартные схемы анализа и оценки данных, не всегда
приносят желаемые результаты, т.к. они негибкие и привязаны к определенному
неадаптируемому алгоритму.
Существует различные модели, которые способны классифицировать данные,
однако их основным недостатком является тот факт, что, они занимают большие
ресурсы техники и времени. Более универсальным было бы применение альтернатив,
позволяющих модели самонастроиться под новые недетерминированные объекты.
Данной работой ставиться задача возможности кластеризации данных с
помощью нейронной сети на основе клеточного автомата. Для выполнения этой цели
была построена программная модель, апробированная на примере распознавания 7-ми
нормированных выборок.
Разрешимость проблемы зависит от многих факторов. Прежде всего,
необходимо набрать достаточную информацию об исследуемых данных - Базу Данных
(БД) представителей каждого класса. Точность и эффективность классификации
непосредственно зависит от хорошо подобранных и откалиброванных эталонных
представителей. Внесение в эталонную БД плохо детерминированных и сильно
искаженных данных может повлечь за собой трудности при классификации, что
существенно снизит процент распознавания.
Условием для качественного работы является достаточный набор обучающих
образцов, используя которые можно проводить аналитические сверки и далее
применять алгоритмы нейросетовой идентификации. Для самодостаточности эталонов
представители каждого символа БД должны обладать следующими характеристиками:
быть классифицируемыми, не быть сильно схожими между собой и не содержать
сильно деформированные элементы внутри класса.
В процессе ассоциирования новых данных с объектами из БД, могут возникать
проблемы, связанные с неоднозначной классификацией, когда трудно или даже
невозможно человеку или машине дать однозначный ответ, к какому классу
принадлежит вектор. Очевидным примером трудно классифицируемых данных могут
быть векторы, лежащие на пересечении классов, не попавшие в замкнутые области,
лежащие на границе рис. 3.1.
Если на пересечении классов лежат обучающие образцы, то нейронная сеть
может отнести их и к одному и другому классу. Часть образцов мы уверенно
кластеризуем, а вызовут сомнения. Чтобы исключить подобную неоднозначность,
можно прибегнуть к разрыву связей в конце обучения сети. В процессе обработки
эта программа выявляет характеристики данных подаваемых на вход и группирует
наиболее близкие друг к другу векторы.

Рис. 3.1 Искажения классов.
.1.1 Выбор
топологии сети
Выбирать тип сети следует исходя из постановки задачи и имеющихся данных
для обучения. Для обучения с учителем требуется наличие для каждого элемента
выборки "экспертной" оценки. Иногда получение такой оценки для
большого массива данных просто невозможно. В этих случаях естественным выбором
является сеть, обучающаяся без учителя, например, самоорганизующаяся карта
Кохонена.
Сети Кохонена принципиально отличаются от всех других типов сетей, в то
время как все остальные сети предназначены для задач с управляемым обучением,
сети Кохонена главным образом рассчитаны на неуправляемое обучение.
При управляемом обучении наблюдения, составляющие обучающие данные,
вместе с входными переменными содержат также и соответствующие им выходные
значения, и сеть должна восстановить отображение, переводящее первые во вторые.
В случае же неуправляемого обучения обучающие данные содержат только значения
входных переменных.
На первый взгляд это может показаться странным. Как сеть сможет чему-то
научиться, не имея выходных значений? Ответ заключается в том, что сеть
Кохонена учится понимать саму структуру данных.
Одно из возможных применений таких сетей - разведочный анализ данных.
Сеть Кохонена может распознавать кластеры в данных, а также устанавливать
близость классов. Таким образом, пользователь может улучшить свое понимание
структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных
распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи
классификации. Сети Кохонена можно использовать и в тех задачах классификации,
где классы уже заданы, - тогда преимущество будет в том, что сеть сможет
выявить сходство между различными классами.
Другая возможная область применения - обнаружение новых явлений. Сеть
Кохонена распознает кластеры в обучающих данных и относит все данные к тем или
иным кластерам. Если после этого сеть встретится с набором данных, непохожим ни
на один из известных образцов, то она не сможет классифицировать такой набор и
тем самым выявит его новизну.
Сеть Кохонена имеет всего два слоя: входной и выходной, составленный из
радиальных элементов (выходной слой называют также слоем топологической карты).
Элементы топологической карты располагаются в некотором пространстве - как
правило двумерном (в пакете ST Neural Networks реализованы также одномерные
сети Кохонена).
Обучается сеть Кохонена методом последовательных приближений. Начиная со
случайным образом выбранного исходного расположения центров, алгоритм
постепенно улучшает его так, чтобы улавливать кластеризацию обучающих данных. В
некотором отношении эти действия похожи на алгоритмы выборки из выборки и
K-средних, которые используются для размещения центров в сетях RBF и GRNN, и
действительно, алгоритм Кохонена можно использовать для размещения центров в
сетях этих типов. Однако данный алгоритм работает и на другом уровне.
Помимо того, что уже сказано, в результате итеративной процедуры обучения
сеть организуется таким образом, что элементы, соответствующие центрам,
расположенным близко друг от друга в пространстве входов, будут располагаться
близко друг от друга и на топологической карте. Топологический слой сети можно
представлять себе как двумерную решетку, которую нужно так отобразить в
N-мерное пространство входов, чтобы по возможности сохранить исходную структуру
данных. Конечно же, при любой попытке представить N-мерное пространство на
плоскости будут потеряны многие детали; однако, такой прием иногда полезен, так
как он позволяет пользователю визуализировать данные, которые никаким иным
способом понять невозможно.
Основной итерационный алгоритм Кохонена последовательно проходит одну за
другой ряд эпох, при этом на каждой эпохе он обрабатывает каждый из обучающих
примеров, и затем применяет следующий алгоритм:
Выбрать выигравший нейрон (то есть тот, который расположен ближе всего к
входному примеру);
Скорректировать выигравший нейрон так, чтобы он стал более похож на этот
входной пример (взяв взвешенную сумму прежнего центра нейрона и обучающего
примера).
В алгоритме при вычислении взвешенной суммы используется постепенно
убывающий коэффициент скорости обучения, с тем, чтобы на каждой новой эпохе
коррекция становилась все более тонкой. В результате положение центра
установится в некоторой позиции, которая удовлетворительным образом
представляет те наблюдения, для которых данный нейрон оказался выигравшим.
Свойство топологической упорядоченности достигается в алгоритме с помощью
дополнительного использования понятия окрестности. Окрестность - это несколько
нейронов, окружающих выигравший нейрон. Подобно скорости обучения, размер
окрестности убывает со временем, так что вначале к ней принадлежит довольно
большое число нейронов (возможно, почти вся топологическая карта); на самых
последних этапах окрестность становится нулевой (т.е. состоящей только из
самого выигравшего нейрона). На самом деле в алгоритме Кохонена корректировка
применяется не только к выигравшему нейрону, но и ко всем нейронам из его текущей
окрестности.
Результатом такого изменения окрестностей является то, что изначально
довольно большие участки сети "перетягиваются" - и притом заметно - в
сторону обучающих примеров. Сеть формирует грубую структуру топологического
порядка, при которой похожие наблюдения активируют группы близко лежащих
нейронов на топологической карте. С каждой новой эпохой скорость обучения и
размер окрестности уменьшаются, тем самым внутри участков карты выявляются все
более тонкие различия, что, в конце концов, приводит к тонкой настройке каждого
нейрона. Часто обучение умышленно разбивают на две фазы: более короткую, с
большой скоростью обучения и большими окрестностями, и более длинную с малой
скоростью обучения и нулевыми или почти нулевыми окрестностями.
После того, как сеть обучена распознаванию структуры данных, ее можно
использовать как средство визуализации при анализе данных. Можно также
обрабатывать отдельные наблюдения и смотреть, как при этом меняется
топологическая карта, - это позволяет понять, имеют ли кластеры какой-то
содержательный смысл (как правило, при этом приходится возвращаться к
содержательному смыслу задачи, чтобы установить, как соотносятся друг с другом
кластеры наблюдений). После того, как кластеры выявлены, нейроны топологической
карты помечаются содержательными по смыслу метками (в некоторых случаях
помечены могут быть и отдельные наблюдения). После того, как топологическая
карта в описанном здесь виде построена, на вход сети можно подавать новые
наблюдения. Если выигравший при этом нейрон был ранее помечен именем класса, то
сеть осуществляет классификацию. В противном случае считается, что сеть не
приняла никакого решения.
При решении задач классификации в сетях Кохонена используется так
называемый порог доступа.
Ввиду того, что в такой сети уровень активации нейрона есть расстояние от
него до входного примера, порог доступа играет роль максимального расстояния,
на котором происходит распознавание. Если уровень активации выигравшего нейрона
превышает это пороговое значение, то сеть считается не принявшей никакого
решения. Поэтому, когда все нейроны помечены, а пороги установлены на нужном
уровне, сеть Кохонена может служить как детектор новых явлений (она сообщает о
непринятии решения только в том случае, если поданный ей на вход случай значительно
отличается от всех радиальных элементов).
Идея сети Кохонена возникла по аналогии с некоторыми известными
свойствами человеческого мозга.
Кора головного мозга представляет собой большой плоский лист (площадью
около 0.5 кв.м.; чтобы поместиться в черепе, она свернута складками) с
известными топологическими свойствами (например, участок, ответственный за
кисть руки, примыкает к участку, ответственному за движения всей руки, и таким
образом все изображение человеческого тела непрерывно отображается на эту двумерную
поверхность)
.2 Алгоритм
кластеризации данных
Обучение искусственной нейронной сети (ИНС) Кохонена относится к типу
самообучающегося соревнования. При обучении методом соревнований нейроны
соревнуются между собой за право активации. Это явление, известное как правило
"победитель забирает все" (Winner Takes All - WTA), имеет
нейрофизиологическую аналогию [23]. Подстройка весов связей в алгоритме WTA
осуществляется не для всех нейронов слоя, а только для
"нейрона-победителя", значение выхода которого в слое нейронов
оказывается максимальным. Главная проблема алгоритма самоорганизации WTA −
наличие "мертвых" нейронов, которые ни разу не побеждают в
конкурентной борьбе. Для разрешения этой проблемы применяются модифицированные
методы и алгоритмы самообучения, дающие обычно лучшие результаты, чем алгоритм
WTA.
Алгоритм "победитель справедливо получает все" (Conscience
Winner Takes All − CWTA) является улучшенной модификацией алгоритма WTA.
Он позволяет учитывать количество побед и поощрять нейроны с наименьшей
активностью для выравнивания их шансов на победу. Этот алгоритм считается одним
из лучших и быстрых в классе алгоритмов самоорганизации. В алгоритме
"победитель получает больше" (Winner Takes Most − WTМ) кроме
нейрона-победителя обучаются также нейроны из его ближайшего окружения. При
этом чем дальше какой-либо нейрон находится от победителя, тем меньше
изменяются его веса. Этот метод исключает "мертвые" нейроны и
улучшает распределение плотности весов. Существуют и другие, более изощренные
алгоритмы обучения ИНС Кохонена.
Общим недостатком рассмотренных алгоритмов обучения нейронной сети
Кохонена является наличие в них большого числа эвристических параметров и
искусственность предлагаемых решений проблемы "мертвых" нейронов.
Целью диссертации является разработка нового детерминированного алгоритма
обучения ИНС Кохонена с использованием непрерывного клеточного автомата,
позволяющего устранить большинство перечисленных недостатков, и его
практическая реализация в электронных таблицах.
Ячейкой клеточного автомата в нашем алгоритме является один нейрон слоя
Кохонена, топологически связанный с четырьмя (на границе - с двумя или тремя) в
окружении фон Неймана или с восемью (на границе - с тремя или пятью) в
окружении Мура ближайшими соседями двумерной самоорганизующейся карты (рис.
3.2). Соответственно, клеточный автомат - это множество взаимодействующих со
своими соседями нейронов слоя Кохонена, помещенных в нормированное пространство
обучающих образов.

Рис. 3.2. Топология самоорганизующейся карты слоя Кохонена для окружения
фон Неймана
Состояние ячейки КА задается многомерным вектором, компоненты которого
суть координаты соответствующего нейрона в пространстве обучающих образов. В
соответствии с принципом "ближайшего соседа" ячейки КА (нейроны)
являются центрами окрестностей Вороного, на которые, подобно многомерной
мозаике, делится все пространство учебных образов [73].
В итерациях эпохи любой внутренний k-ый нейрон слоя (рис. 3.2) изменяет
свой многомерный вектор состояния в двух случаях:
) нейрон стал победителем;
) нейрон является ближайшим соседом другого победившего нейрона.
Будем считать, что приращение компонент вектора состояния k-го нейрона не
зависит от причины (победил он сам или победил его сосед) этого приращения.
Тогда среднее суммарное приращение i-ой компоненты вектора состояния k-го
нейрона за одну эпоху в окружении фон Неймана будет равно
 (3.1)
(3.1)
где η - скорость обучения; k -номер нейрона-победителя;
m={k-1,k,k+1,k-L,k+L} - номера нейронов окружения k-го нейрона; L - ширина
прямоугольной самоорганизующейся карты; nm - число учебных образов, попавших в
окрестность Вороного m-го нейрона; xmi(j) - i-ая координата j-го учебного
образа из окрестности Вороного m-го нейрона; wki - i-ая координата k-го
нейрона.
Обозначая n= , выражение (1) можно переписать в виде
, выражение (1) можно переписать в виде
 (3.2)
(3.2)
где  - i-ая координата центра тяжести окрестности Вороного m-ого
нейрона.
- i-ая координата центра тяжести окрестности Вороного m-ого
нейрона.
Отсюда видно, что в конце каждой эпохи k-ый нейрон смещается на
относительную величину η в направлении центра тяжести области пространства
учебных образов, образованной объединением окрестностей Вороного k-го нейрона и
его соседей-победителей. В частности, при η=1 нейрон смещается точно в центр
тяжести этой объединенной области.
Очевидно, что приращение вектора состояния k-го нейрона всегда происходит
в направлении максимальной концентрации учебных образов этой объединенной
области.
Если пространство учебных образов образует односвязанную область, то в
предлагаемом алгоритме обучения ИНС Кохонена вообще отсутствует понятие
"мертвых" нейронов, т.е. нейронов, в окрестности Вороного которых не
содержится ни одного учебного образа.
Действительно, предположим, что все учебные образы сконцентрированы в
окрестности Вороного некоторого k-го нейрона. Тогда после первой эпохи обучения
при скорости обучения η=1 в эту окрестность сместятся все его соседние нейроны.
После второй эпохи обучения в область концентрации учебных образов
переместятся все ближайшие соседи соседей k-го нейрона и т.д., пока
пространство учебных образов не будет "справедливо" поделено между
всеми нейронами слоя Кохонена.
Для иллюстрации сказанного на рис.3.3 приведен пример работы одномерного
клеточного автомата, реализующего обучение сети Кохонена с одномерной
топологией. Здесь все учебные образы сконцентрированы в окрестности Вороного
k-го нейрона, вертикальными пунктирными линиями показаны границы окрестностей
Вороного всех нейронов.

Рис.3.3. Состояния одномерного клеточного автомата:
) начальное; 2) после 1-ой эпохи обучения; 3) после 2-х эпох обучения; 4)
после 3-х эпох обучения.
После первой эпохи обучения нейроны k-1, k и k+1 с точностью до ошибки
округления переместятся в центр тяжести всех учебных образов.
После второй эпохи обучения k-ый нейрон останется на месте, а нейроны
k-2, k-1 и k+1, k+2 сместятся к центру тяжести учебных образов, соответственно
расположенных левее и правее k-го нейрона.
После 3-ей эпохи обучения расположение нейронов станет следующим:
(k-3)-ий нейрон - в центре тяжести учебных образов, расположенных левее
(k-2)-го нейрона; (k-2)-ой нейрон - в центре тяжести окрестностей Вороного
(k-2)-го и (k-1)-го нейронов; (k-1)-ой нейрон - в центре тяжести окрестностей
Вороного (k-2)-го, (k-1)-го и k-го нейронов; k-ый нейрон - в центре тяжести окрестностей
Вороного (k-1)-го, k-го и (k+1)-го нейронов; (k+1)-ый нейрон - в центре тяжести
окрестностей Вороного k-го, (k+1)-го и (k+2)-го нейронов; (k+2)-ой нейрон - в
центре тяжести окрестностей Вороного (k+1)-го и (k+2)-го нейронов; (k+3)-ий
нейрон - в центре тяжести учебных образов, расположенных правее (k+2)-го
нейрона.
Проверка работоспособности предложенного алгоритма обучения ИНС Кохонена
производилась с помощью табличной модели Excel, описанной в следующих главах.
Слой нейронов Кохонена включал 30 нейронов, взаимодействующих между собой таким
образом, чтобы топологически они образовывали 5 независимых одномерных решеток
(клеточных автоматов) по 6 нейронов в каждой. Учебные образы (всего 4000 шт.)
равномерно распределялись в окрестности Вороного четвертого нейрона каждого из
одномерных обучающих КА.
Результаты обучения одномерной сети Кохонена в течение трех эпох
приведены на рис.3.4а и полностью подтверждают теоретические выводы,
иллюстрируемые рис.3.4б.
К достоинствам предложенного алгоритма обучения ИНС Кохонена с помощью
непрерывного клеточного автомата относятся:
его детерминированность, обусловленная тем, что конечное состояние КА
зависит только от начального состояния (положения) нейронов, числа шагов работы
автомата (итераций) и скорости обучения, которая остается фиксированной и имеет
ясный физический смысл;
отсутствие эвристических параметров обучения, таких как зависящая от
времени функция "меры соседства", монотонно убывающий обучающий
сомножитель и др.;
автоматически решается проблема "мертвых" нейронов.


Рис.3.4. Состояние нейронов сети Кохонена:
а) начальное; б) после 1-ой эпохи обучения; в) после 2-х эпох обучения;
г) после 3-х эпох обучения
3.3 Блок
схема нейронной сети
Блок-схема является вариантом формализованной записи алгоритма или
процесса. Каждый шаг алгоритма в данном представлении изображается в виде
блоков различной формы, которые соединены между собой линиями. В блок-схеме
можно отобразить все этапы решения любой задачи, начиная с ввода исходных
данных, обработки операторами, выполнения цикличных и условных функций, и
заканчивая операциями вывода результирующих значений.
Фактически задача заключается в том, что на основе введенных конфигураций
в выборке для каждого символа выявить их характерные признаки и распознать
класс представленного на опознавание символа. Задача распадается на следующие
шаги:
. Загрузка выборки векторов из выборки данных;
. Введение произвольного набора данных для последующей кластеризации;
. Считывание введенных данных для распознавания из выборки в программу;
. Преобразование данных из двоичного представления в табличный массив 0 и
1;
. Подсчет конгруэнтной промежуточной нейронной матрицы;
. Подсчет диверсивной промежуточной нейронной матрицы;
. Подсчет пассивной промежуточной нейронной матрицы;
. Подсчет итоговой симбиозной нейронной матрицы, основанной на
характеристиках матриц слоев;
. Выявление характеристик симбиозных матриц и вычисление итоговых
значений на выходах;
. Выявление наибольшего значения из выходов симбиозных матриц,
определение его кода и ассоциирование с поступившим на вход классом;
. Корректировка сумматорной матрицы (без учителя) в случае высокой
погрешности;
. Переход к шагу 2, пока величина погрешности не будет удовлетворяющей.
Блок схема соответствующего алгоритма будет иметь следующий вид:
Искусственная самоорганизующаяся нейро-матричная сеть (ИСНМС), построена
по следующей схеме (рис. 3.5): на вход нейронной сети подаетсявыборка данных,
вход можно представить, как матрицу рецепторов, а выборка может быть
представлена в виде последовательности 0 и 1, где 0 - незакрашенные ячейки, а 1
- закрашенные ячейки. Информация из матрицы рецепторов подается, и
трансформируются на второй уровень - класс нейронных матриц представителей и
критериев оценок для каждого класса базы данных, после этого подсчитываются
промежуточные веса и применяются критерии отбора элементов, которые также
прописаны в матричном виде - третий уровень.

Рис. 3.5 Условный граф матричной нейронной самоорганизующейся сети
Следующим этапом является взвешивание полученных результатов с помощью
вычисления целевой функции каждой матричной схемы, учитывая различные критерии.
После вычисления всех весов на последнем этапе просматриваются полученные
результаты, и наивысшему значению будет соответствовать наиболее приближенный
класс. В созданной схеме используется самоорганизация сети, т.е. после
определения класса происходит перенастройка весов различных матриц критериев в
цикле, таким образом, схема не является статической, а является динамически
подстраиваемой и эффективно сходящейся.
На основе построенной принципиально новой искусственной нейронной схемы с
независимыми нейронами и применения вероятностно-статистических анализов были
получены высокие результаты распознавания. Данный граф показывает структурную
схему построенной искусственной самоорганизующейся нейронной сети (ИСНС) для
кластеризации данных.
Ниже приводится более детализированная блок-схема нейронной сети.

Рис. 3.6. Блок схема работы нейронной сети
Алгоритм обучения сети Кохонена выглядит следующим образом:
. Инициировать матрицу весов малыми случайными значениями (на отрезке
[-1,1]).
. Построить очередь из элементов входного множества, расположив их в
случайном порядке, пометить их все как необработанные.
. Выбрать первый необработанный элемент x из очереди.
. Для каждого выхода j вычислить расстояние dj (1) между его вектором
весов wj и входным вектором x:
 x) (3.3)
x) (3.3)
. Найти номер выходного нейрона jm с минимальным расстоянием dj:
 (3.4)
(3.4)
. Вычислить изменение весов ΔW = {Δwu} для всех нейронов u выходного слоя:
 (3.5)
(3.5)
где c - номер (пара индексов) нейрона победителя jm в двумерной решетке
второго слоя;
и - номер (пара индексов) нейрона с вектором весов wu в двумерной решетке
второго слоя;и - вектор весовых коэффициентов связи входного слоя и выходного
нейрона номер и;- текущий вектор входов сети;(и,c,t) - значение функции
окрестности для нейрона номер u в момент времени t;
η - коэффициент скорости обучения;
. Скорректировать матрицу весов:
:=W -∆W (3.6)
. Пометить элемент входной очереди x как обработанный если в очереди
остаются не обработанные точки, то переход на п.3, если критерий остановки
обучения не достигнут то переход на п.2
. Конец.
В качестве критериев останова процесса обучения можно использовать
следующие:
Количество полных циклов обучения ограничено константой, например
количество циклов равно количеству элементов во входном множестве.
Выход сети стабилизируется, т.е. входные вектора не переходят между
кластерными элементами.
Изменения весов становятся незначительными.
3.4 Создание
табличной модели нейронной сети Кохонена
Псевдокод алгоритма обучения искусственной нейронной сети Кохонена с
помощью клеточного автомата в cnt-ой итерации имеет вид:
Переменные алгоритма:
// счетчик итераций// число нейронов в слое Кохонена// число учебных
образов в выборке// размерность пространства учебных образов={x1(k),
x2(k),…,xD(k)} // вектор состояния k-го учебного образа={w1(i), w2(i),…,wD(i)} //
вектор состояния i-го нейрона// вектор приращения состояния i-го нейрона за
эпоху
Функции алгоритма:(i) // логическая функция, возвращающая значение True,
если // i - нейрон-победитель или связанный с ним нейрон // окружения, иначе
функция возвращает значение False
Псевдокод алгоритма:
= ОСТАТ(cnt;smplNums) // текущая итерация эпохиi=1 to nNums
Процедура получения координат k-ого учебного образа
// Найти новый вектор состояния i-го нейрона (i-ой ячейки КА)
If fix Then=wistart=1 Then(ieCnt<=smplNums)&(ieCnt=0)
Then=wi+IIF(IsWinner(i);dwi;0)=wiIf=wiначIfIf
// Расстояние между k-ым учебным образом и i-ым нейроном
 (3.7)
(3.7)
// Найти нейрон-победитель rp=min(rki)
// расстояние между k-ым учебным образом и нейроном-
// победителем, p - порядковый номер нейрона-победителяi=1 to nNums
Процедура вычисление компонент вектора приращения dwi состояния i-го
нейрона за эпоху
Книга Excel с табличной моделью ИНС Кохонена, реализующей этот алгоритм
обучения, содержит три рабочих листа: Выборки, Обучение и AuxData.
.4.1 Рабочий
лист "Выборки"
Рабочий лист Выборки содержит набор тестовых выборок учебных образов и
элементы пользовательского интерфейса для активизации одной из выборок этого
набора.
Необходимо сделать так, чтобы в одной из ячеек листа был выпадающий
список с наименованиями, при выборе из которого должна происходить активация
нужной выборки данных:
На рабочем листе Выборки рис.3.7 производится активация интересующей
пользователя нормированной выборки учебных образов из имеющегося набора
выборок.

Рис. 3.7. Рабочий лист выборки
Каждая выборка может содержать до 8000 учебных образов в четырехмерном
пространстве. Заметим, однако, что простым приравниванием к нулю части
отдельных координат учебных образов пользователь может определять, как частные
случаи, выборки учебных образов и в пространствах с одним, двумя и тремя
измерениями.
На рабочем листе Выборки используются следующие формулы;
. [F3]:=СЧЁТЕСЛИ(dataType;0) число учебных образов
. [F4]:=СЧЁТЕСЛИ(dataType;2) число исключенных образов
. [F5]:=R[-2]C+R[-1]C всего образов в активной выборке

. [E15:H15]:= =МИН(СМЕЩ(E$21;0;0;$F$3;1))минимальные координаты
образов активной выборки
. [E16:H16]:=МАКС(СМЕЩ(E$21;0;0;$F$3;1)) максимальные координаты
образов активной выборки
. [E17:H17]:=ЕСЛИ(И(МИН(E21:E8020)=0;МАКС(E21:E8020)=0);0;1) флаг
включения координаты в пространство активной выборки
. [E18:H18]:=СРЗНАЧ(СМЕЩ(E$21;0;0;$F$3;1))среднее значение
координат образов активной выборки

. [I21:I8020}:=ЕСЛИ(Slct=1;P21;ЕСЛИ(Slct=2;X21;ЕСЛИ(Slct=3;AH21;ЕСЛИ(Slct=4;AP21;ЕСЛИ(Slct=5;AX21;BE21)))))
нормированный класс образов активной выборки
. [J21:J8020}:=ЕСЛИ(Slct=1;Q21;ЕСЛИ(Slct=2;Y21;ЕСЛИ(Slct=3;AI21;ЕСЛИ(Slct=4;AQ21;ЕСЛИ(Slct=5;AY21;ЕСЛИ(Slct=6;BF21;BM21))))))
тип образа в активной выборке.

.[E21:E8020}:=ЕСЛИ(Slct=1;L21;ЕСЛИ(Slct=2;T21;ЕСЛИ(Slct=3;AD21;ЕСЛИ(Slct=4;AL21;ЕСЛИ(Slct=5;AT21;ЕСЛИ(Slct=6;BA21;BH21))))))*scale;
[F21:F8020}:==ЕСЛИ(Slct=1;M21;ЕСЛИ(Slct=2;U21;ЕСЛИ(Slct=3;AE21;ЕСЛИ(Slct=4;AM21;ЕСЛИ(Slct=5;AU21;ЕСЛИ(Slct=6;BB21;BI21))))))*scal;
[G21:G8020}:=ЕСЛИ(Slct=1;N21;ЕСЛИ(Slct=2;V21;ЕСЛИ(Slct=3;AF21;ЕСЛИ(Slct=4;AN21;ЕСЛИ(Slct=5;AV21;ЕСЛИ(Slct=6;BC21;BJ21))))))*scale;
[H21:H8020}:=ЕСЛИ(Slct=1;O21;ЕСЛИ(Slct=2;W21;ЕСЛИ(Slct=3;AG21;ЕСЛИ(Slct=4;AO21;ЕСЛИ(Slct=5;AW21;ЕСЛИ(Slct=6;BD21;BK21))))))*scale
нормированные координаты образов активной выборки
Любые изменения на рабочем листе Выборки контролируются процедурой
Worksheet_Change() - обработчиком события Change вида (рис. 3.8):

Рис. 3.8. Рабочий лист выборки
На листе "Выборки" 5 выборок учебных образцов:
Выборка 1 состоит из 8000 образцов равномерно расположенных по всей
координатной сетке.
Выборка 2 состоит из 4000 образцов.
Выборка 3 состоит из 150 норированных образцов на плоскости задачи Ирисы
Фишера.
Выборка 4 так же состоит из образцов задачи Ирисы Фишера, но уже с 4-мя
координатами.
Выборка 5 включает в себя 2000 образцов на плоскости с треугольным
расположением.

Рис. 3.9. Рабочий лист выборки
3.4.2 Рабочий
лист "Обучение"
Рабочий лист Обучение содержит табличную реализацию ИНС, содержащую слой
из 30 нейронов Кохонена. В совокупности нейроны слоя Кохонена образуют
двумерную прямоугольную самоорганизующуюся карту, показанную на рис. 3.103.

Рис. 3.10. Самоорганизующаяся карта нейронов слоя Кохонена (заливкой
показано окружение фон Неймана для 14-го нейрона)
В процессе обучения ИНС Кохонена каждый ее нейрон взаимодействует только
со своими соседями из окружения фон Неймана радиуса r=1, т.е. с нейронами,
расположенными левее, выше, правее и ниже искомого нейрона. Однако по желанию
пользователя табличной модели отдельные связи между нейронами можно
принудительно разорвать. Так, на рис.3.33 крестиками показаны разрывы связей
между нейронами 6 и 12, 12 и 13, 13 и 19, 19 и 20, 20 и 26, 26 и 27. В
результате первоначально односвязная самоорганизующаяся карта оказалась
разорванной на две не взаимодействующие между собой карты (множества нейронов
{12, 18-19, 24-26} и {0-11, 13-17, 20-23, 27-29}). Как показано ниже,
возможность выборочного разрыва связей между нейронами играет важную роль в
решении проблемы "мертвых" нейронов.
Обучение ИНС Кохонена выполняется в две фазы. В эпохах первой фазы
обучение сети выполняется в соответствии с алгоритмом, описанным в разделе
3.4.1. Во второй фазе взаимодействие между соседними нейронами отключается, и
выполняется окончательная подстройка положений нейронов-победителей
относительно положения нейронов, достигнутого в первой фазе обучения ИНС.
Табличная модель ИНС Кохонена состоит из области пользовательского
интерфейса в диапазоне ячеек R1C1:R18C10 (рис.3.11), семи двумерных диапазонов
ячеек с данными и формулами, реализующими алгоритм обучения сети с помощью
клеточного автомата, нескольких вспомогательных диапазонов ячеек:
R23C20:R52C23 - входной диапазон ячеек Начальное состояние нейронов
(ячеек КА) для ручного задания детерминированной начальной конфигурации слоя
нейронов Кохонена (рис.3.12а);
R60C20:R60C23 - диапазон ячеек Входной порт данных, в процессе обучения
ИНС через этот порт подаются учебные образы на входы слоя нейронов Кохонена
(рис.3.13);
R64C20:R64C23 - диапазон ячеек Входы слоя нейронов Кохонена (рис.3.12б);
R65C20: R94C23 - диапазон ячеек Слой нейронов Кохонена (рис.3.12б);
R108C29:R112C34 - диапазон ячеек Окружение нейрона-победителя, табличный
эквивалент самоорганизующейся карты Кохонена, ячейки нейрона-победителя и его
кружения имеют значение 1, остальные ячейки - значение 0 (рис.3.14);
R116C20:R145C23 - диапазон ячеек Предыдущие приращения координат нейронов
(рис.3.38б);
R149C20:R178C23 - диапазон ячеек Приращения координат нейронов
(рис.3.15а);
R65C24: R94C24, R116C24: R145C24, R116C25: R145C25, R149C19:R178C19,
R149C24:R178C24, R149C25:R178C25 - вспомогательные диапазоны ячеек.
Пользовательский интерфейс табличной модели ИНС Кохонена представлен на
рис. 3.11.

Рис. 3.11. Пользовательский интерфейс табличной модели ИНС Кохонена
(входные ячейки выделены заливкой).

Рис. 3.12. Начальные веса
(а) и структура слоя нейронов (б) табличной модели ИНС Кохонена
Пользовательский интерфейс табличной модели включает:
управляющие кнопки Пуск, Сброс и Выполнить, с которыми ассоциированы
макросы StartBtn_Click(), и InitBtn_Click()и Run_Iterations() соответственно;
входные ячейки Число эпох R8C6, Скорость обучения R15C5 и R15C6, Доля
эпох взаимодействия R17C5, Число нейронов R4C9, Ширина карты R5C9, Число
прогонов R12C9;
ячейку Флаг включения итераций R4C6, устанавливается и сбрасывается
программно c помощью управляющих макросов StartBtn_Click() и InitBtn_Click();
таблицу задания детерминированной начальной конфигурации КА (начального
положения нейронов) в диапазоне ячеек R23C20:R52C23 (рис. 3.12а);

Рис. 3.13. Входной порт данных табличной модели ИНС Кохонена

Рис. 3.14. Нейрон-победитель и соседние нейроны из окружения фон Неймана

Рис. 3.15. Приращения координат нейронов для активной выборки 2 после
двух эпох обучения
флажок Фиксировать и связанную с ним ячейку R7C9, предназначен для
фиксации состояния нейронов слоя Кохонена после завершения обучения ИНС;
прочие вспомогательные ячейки, обеспечивающие управление ИНС и
визуализацию процесса ее обучения.
В ячейках табличной модели используются формулы:
Пользовательский интерфейс:
[R5C6]:=eNum*smplNums ¢ число итераций
[R6C6]:=ЕСЛИ(start=1;cnt+1;0) ¢ счетчик итераций
[R9C6]:=ЕСЛИ(start=1;ЦЕЛОЕ(cnt/smplNums);0) ¢ счетчик эпох
[R9C5]:=eCnt ¢ предыдущее значение счетчика эпох
[R10C6]:=ЕСЛИ(start=1;ЕСЛИ(ОСТАТ(cnt;smplNums)=0;smplNums;
ОСТАТ(cnt;smplNums));0) ¢ счетчик итераций эпохи
[R12C6]:=Выборки!R2C7 ¢ число учебных образов
[R13C6]:=ЕСЛИ(start=1;ОСТАТ(cnt;smplNums)+1;0) ¢ номер текущего образа
[R16C6]:=ЕСЛИ(eCnt<R17C6;R15C5;R15C6) ¢ текущая скорость обучения
[R17C6]:=ЦЕЛОЕ(Ni*R17C5) ¢ число эпох взаимодействия
Входной порт данных:
[R57C21]:=curSmpl
[R60C20:R60C23]:=СМЕЩ(Выборки!R14C3;k;R59C)
Входной порт данных работает следующим образом. В каждой итерации
процесса обучения ИНС в ячейку R57C21 из именованной ячейки curSmpl копируется
номер текущего учебного образа k. По этому номеру с помощью функции Excel
СМЕЩ() в ячейки R60C20:R60C23 входного порта данных с рабочего листа Выборки
(диапазон ячеек Выборки!R14C4:R8014C7) считываются координаты k-го учебного
образа активной выборки. Полученные через этот порт координаты текущего
учебного образа поступают на входы R64C20:R64C23 слоя нейронов Кохонена
(рис.3.35б), в конечном счете, определяя номер очередного нейрона-победителя.
Входы слоя нейронов Кохонена:
[R64C20:R64C23]:=R[-4]C
Слой нейронов Кохонена:
[R65C20:R94C23]:=ЕСЛИ(fix;RC;ЕСЛИ(start=1;
ЕСЛИ(И(ieCnt<=smplNums;ОСТАТ(cnt;smplNums)=0);
RC+ЕСЛИ(R[51]C24=0;0;R[51]C/R[51]C24);RC);R[-42]C))
[R65C24:R94C24]:=ЕСЛИ(start=1;КОРЕНЬ(СУММКВРАЗН(R64C[-4]:R64C[-1];
RC[-4]:RC[-1]));0)
[R95C24]:=МИН(R[-30]C:R[-1]C)
[R97C22]:=ПОИСКПОЗ(R95C24;R65C24:R94C24;0)-1
[R97C23]:=ОСТАТ(winner;L)
[R97C24]:=ЦЕЛОЕ(winner/L)
Окружение нейрона-победителя:
[R102C29:R106C34]:=RC28*L+R101C+0*cnt
[R108C29:R112C34]:=ЕСЛИ(RC28*L+R101C=winner;1;ЕСЛИ(ИЛИ(И(ABS(RC28-j)=1;
ABS(R101C-i)=0);И(ABS(RC28-j)=0;ABS(R101C-i)=1)); ЕСЛИ(eCnt<R17C6;1;0);0))
Приращения координат нейронов:
[R149C19:R178C19]:=ЕСЛИ(ИНДЕКС(ЕСЛИ(slct>2;Set1;Set);winner+1;
RC18+1)=1;ИНДЕКС(R108C29:R112C34;ЦЕЛОЕ(RC18/L)+1;ОСТАТ(RC18;L)+1);0)
[R149C20:R178C23]:=ЕСЛИ(ОСТАТ(cnt;smplNums)<>0;RC+teta*
(R64C-R[-84]C)*RC19;0)
[R149C24:R178C24]:=ЕСЛИ(start=1;ЕСЛИ(ОСТАТ(cnt;smplNums)<>0;
ЕСЛИ(RC19=1;RC+1;RC);0);0)
[R149C25:R178C25]:=ЕСЛИ(start=1;ЕСЛИ(ОСТАТ(cnt;smplNums)<>0;
ЕСЛИ(RC18=winner;RC+1;RC);0);0)
Предыдущие приращения координат нейронов:
[R116C20:R145C23]:=R[33]C
[R116C24:R145C25]:=ЕСЛИ(R[33]C=0;0;R[33]C+1)
Для удобства работы пользователей на рабочий лист Обучение внедрены
управляющие кнопки Обучение, Сброс и Выполнить. С первыми двумя кнопками
ассоциированы универсальные макросы StartBtn_Click() и InitBtn_Click() точно
такие же, как и в предыдущих итерационных моделях КА, с кнопкой Выполнить
ассоциирован макрос Run_Iterations(), имитирующий многократное нажатие кнопки
Старт: Sub Run_Iterations()
Dim Ni As Integeri As Integer=Range("Ni")i=1 To
Ni.Run "Лист1.StartBtn_Click"
NextSub
Кнопка Выполнить и связанный с ней макрос Run_Iterations() запускают Ni
циклов итераций обучения нейронной сети, кнопка Пуск и макрос StartBtn_Click()
запускает один цикл обучения ИНС, состоящий из Nr=smplNums×eNums итераций (как отмечалось, при
eNums=1/smplNums выполняется ровно одна итерация), кнопка Сброс и макрос
StopBtn_Click() приводят ИНС в исходное необученное состояние.
Для запуска процесса обучения нейронной сети нужно выполнить следующие
действия:
. В ячейках пользовательского интерфейса Число эпох (R8C6), Скорость
обучения (R15C5, R15C6), Доля эпох взаимодействия (R17C5), Число нейронов
(R4C9), Ширина карты (R5C9), Число прогонов (R12C9) задать значения требуемых
параметров обучения (рис. 3.11).
. Нажать кнопку Сброс для приведения нейронов ИНС Кохонена в начальное
необученное состояние.
. Запустить итерации обучения нейронной сети при заданных параметрах,
нажав кнопку Выполнить.
Заметим, что после обучения сети в течение заданного числа эпох можно, не
сбрасывая состояние нейронов сети, повторно нажать кнопку Выполнить, и
продолжить процесс обучения дальше. Перед повторным нажатием кнопки Выполнить можно
также изменить содержимое ячейки R8C6, увеличивая или уменьшая число эпох,
которое будет выполнено в следующих итерациях.
Созданную табличную модель ИНС Кохонена легко модифицировать в нескольких
отношениях:
. Вместо окружения фон Неймана в обучающем клеточном автомате
использовать окружение Мура, введя для этого на самоорганизующейся карте
Кохонена в дополнение к вертикально-горизонтальным связям еще и диагональные
связи.
. Вместо суммирующего КА использовать внешне суммирующий обучающий
клеточный автомат. Например, обучение нейрона-победителя можно вести с большей
скоростью, чем обучение нейронов его окружения.
. Для избирательного разрыва связей между нейронами на самоорганизующейся
карте Кохонена использовать более наглядный и удобный интерфейс, используя
вместо матрицы смежностей табличную модель самоорганизующейся карты, как
показано на рис. 3.16.

Рис. 3.16. Табличная модель самоорганизующейся карты Кохонена: а)
окружение фон Неймана, б) окружение Мура
Здесь для примера в обучающем клеточном автомате с окружением фон Неймана
оставлены только горизонтальные связи между нейронами (рис. 3.16а), а в КА с
окружением Мура - диагональные (рис. 3.16б).
В заключение лишний раз подчеркнем, что результаты модельных
экспериментов с табличной моделью ИНС Кохонена, представленные на рис.3.14
справа, убедительно подтверждают справедливость теоретических выводов раздела
3.4.1 о возможности обучения нейронной сети с помощью непрерывного клеточного
автомата.
3.5 Обучение
сети
Обучение сети выполняется в пакетном режиме, т.е. КА переходит в новое
состояние один раз в конце каждой эпохи подачи учебных образов. При этом в
итерациях эпохи выполняется расчет будущего состояния КА. Учебные образы в
итерациях эпохи могут подаваться на входы нейронной сети Кохонена в
произвольном порядке, например, последовательно.
Проверка работоспособности предложенного алгоритма обучения ИНС Кохонена
производилась с помощью табличной модели Excel. Слой нейронов Кохонена включает
30 нейронов, взаимодействующих между собой таким образом, чтобы топологически
они образовывали 5 независимых одномерных решеток (клеточных автоматов) по 6
нейронов в каждой.
Третья выборка содержит 150 учебных образов известной задачи Фишера о
цветках ириса, широко используемой в качестве типовой выборки при классификации
образов с помощью ИНС на базе многослойных персептронов. В нашем случае выборка
содержит три класса цветков ириса, по 50 образов в каждом классе. При этом,
чтобы обеспечить неискаженную графическую иллюстрацию процесса обучения сети в
двумерном пространстве, используются только два главных параметра цветков ириса
из четырех, которых, как показывает опыт, тем не менее достаточно для
удовлетворительной классификации цветков ириса.
Для обучения сети мы возьмем 120 образцов из выборки "Ирисы
Фишера", а 30 образцов оставим для тестирования сети. Будем использовать
образцы:
1-40
51-90
101-140
Для этого нужно в столбце "Тип" поставить цифру "2"
(рис. 3.17)
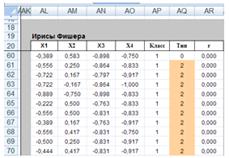
Рис. 3.17. Ирисы Фишера
На рабочем листе "Выборки" из выпадающего списка выбираем номер
нужной обучаемой последовательности (рис.3.18).

Рис. 3.18. Выбор обучающей последовательности из списка.
После выбора происходит автоматический переход на рабочий лист
"Обучение" (рис. 3.19)

Рис. 3.19. Рабочий лист "Обучение"
После перехода нужно выбрать связи между нейронами. В меню выбора связей
ставим маркер на пункт "Все связи" (рис.3.20).

Рис. 3.20. Меню выбора связей
Выбор связей между нейронами можно сделать вручную (рис. 3.21).

Рис. 3.21.Таблица выбора связей
В таблице управления обучением сети в строке "Число образцов"
стоит цифра 130, это значит что исключенные образцы в обучении будут неактивны.
В поле число прогонов ставим 200 эпох обучения и нажимаем кнопку
"Выполнить" (рис. 3.22).

Рис. 3.22. Таблица управления обучением сети
Запустится обучение сети. После 200 циклов обучения нероны будут иметь
положение показанное на рис. 3.21.

Рис. 3.21.Обучение сети
Из этого можно сделать вывод о том, что сеть функционирует. Далее нужно
будет протестировать сеть на точность кластеризации.
.6 Создание
табличной модели обученной сети
После обучения сети сформировался диапазон слой нейронов Кохонена (рис.
3.22). Скопируем таблицу в новый лист MS Excel. И назовем его ИНС.

Рис. 3.22. Слой нейронов Кохонена
С помощью данной табличной модели можно классифицировать двумерные
образцы, подавая их на вход. Для подачи на вход нужен входной порт данных (рис.
3.23).

Рис. 3.23. Входной порт данных табличной модели ИНС Кохонена
Входной порт данных работает следующим образом. Из именованной ячейки
curSmpl копируется номер текущего учебного образа k. По этому номеру с помощью
функции Excel СМЕЩ() в ячейки входного порта данных считываются координаты k-го
учебного образа активной выборки. Полученные через этот порт координаты
текущего учебного образа поступают на входы слоя нейронов Кохонена (рис.3.35б),
в конечном счете, определяя номер очередного нейрона-победителя.
Для образцов выборки создадим рабочий лист "Выборки", с
которого данные будут поступать на входной порт (рис. 3.24).

Рис. 3.24. Рабочий лист "Выборки"
Для ввода обучающих образцов на входной порт данных используем следующие
формулы:
. в проименованную ячейку "к" введем R[3]C[-1]:R[3]C[2]
. в ячейки[R11C5:R11C6]:= =СМЕЩ(Выборки!R[-5]C;k;0)
Теперь данные из таблицы "Выборки" могут поступать на входной
порт данных.
С помощью таблицы подстановки (рис.3.25) определим к каким кластерам
относятся образцы. В столбце "к" указан номер образца, в столбце
"winner" - нейрон- победитель.

Рис. 3.25. Таблица подстановки
На листе "Выборки" создадим дополнительный столбец с номером
кластера (рис. 3.26)

Рис. 3.26. Лист "Выборки"
На данном рисунке видно какой класс образцов кластеризует каждый нейрон.
Это означает, что к образцам отнесены кластеры (табл. 3.1).
Номер кластера в таблице соответствует номеру соответствующего нейрона на
карте Кохонена. Видим, что во 2-ом и 3-ем классах встречаются одинаковые
нейроны (2, 22).
Это говорит о том, что классификация образцов на границе классов
происходит неоднозначно и встречаются пересечения.
Табл. 3.1
Классификация нейронов
|
1 класс
|
2 класс
|
3 класс
|
|
12
|
0
|
2
|
|
18
|
1
|
3
|
|
19
|
2
|
4
|
|
24
|
6
|
4
|
|
25
|
7
|
8
|
|
26
|
13
|
9
|
|
14
|
10
|
|
14
|
10
|
|
15
|
11
|
|
20
|
16
|
|
21
|
16
|
|
22
|
17
|
|
27
|
22
|
|
28
|
23
|
|
|
28
|
Если сформировать произвольный образец, то карта Кохонена должна указать
его принадлежность к тому или иному кластеру:
.7
Тестирование сети
Для тестирования работоспособности табличной модели ИНС Кохонена
использовались четыре двумерных и одна четырехмерная выборки образов,
графические представления которых показаны на рис. 3.27 слева.

Рис. 3.27. Вид самоорганизующейся карты Кохонена для трех тестовых
выборок учебных образов перед и после выполнения 25 циклов итераций (скорость
обучения h=1, доля эпох
взаимодействия 0.7).
Первая выборка содержит 8000 учебных образов равномерно распределенных по
плоскости карты.
Вторая выборка содержит 4000 учебных образов, пространственное
распределение которых в проекции на самоорганизующеюся карту Кохонена имеет
круговое распределение.
Выборка 3 состоит из 150 норированных образцов на плоскости задачи Ирисы
Фишера.
Выборка 4 так же состоит из образцов задачи Ирисы Фишера, но уже с 4-мя
координатами.
Выборка 5 включает в себя 2000 образцов на плоскости с треугольным
расположением.
Третья выборка содержит 150 учебных образов известной задачи Фишера о
цветках ириса, широко используемой в качестве типовой выборки при классификации
образов с помощью ИНС на базе многослойных персептронов. В нашем случае выборка
содержит три класса цветков ириса, по 50 образов в каждом классе. При этом
чтобы обеспечить неискаженную графическую иллюстрацию процесса обучения сети в
двумерном пространстве, используются только два главных параметра цветков ириса
из четырех, которых, как показывает опыт, тем не менее достаточно для
удовлетворительной классификации цветков ириса.
Основным отличием данной выборки от двух предыдущих является то, что
третий класс ее учебных образов пространственно отделен от образов других
классов. Поэтому в первой фазе обучения ИНС Кохонена несколько нейронов на
самоорганизующейся карте оказываются связанными как с нейронами-победителями,
находящимися в области учебных образов первых двух классов, так с
нейронами-победителями, находящимися в области учебных образов третьего класса
и, следовательно, в ходе обучения увлекаются то в одну, то в другую область
пространства образов. Именно эти нейроны, имеющие в пространстве образов
промежуточное положение, являются "мертвыми", т.е. ни разу не
выигрывают во второй фазе обучения ИНС Кохонена.
Тестирование сети на выборке "Ирисы фишера"
После того как нейронная сеть обучена, мы можем выполнить ее
тестирование. При этом будет проверена способность сети к распознаванию всех
или некоторых векторов.
Рассмотрим задачу распознавании образов, которую часто берут за образец
при проверке методов. Это - задача Фишера об ирисах. Точный тест Фишера - тест
статистической значимости, используемый в анализе таблиц сопряжённости для
выборок маленьких размеров. Назван именем своего изобретателя Р. Фишера.
Относится к точным тестам значимости, поскольку не использует приближения
большой выборки (асимптотики при размере выборки стремящемся к бесконечности).
На создание этого теста Фишера побудило высказывание Муриэль Бристоль, которая
утверждала, будто была в состоянии обнаружить, в какой последовательности чай и
молоко были налиты в её чашку. Тест обычно используется, чтобы исследовать
значимость взаимосвязи между двумя переменными в факторной таблице размерности
(таблице сопряжённости признаков). Величина вероятности теста вычисляется, как
если бы значения на границах таблицы известны. Например, в случае с дегустацией
чая госпожа Бристоль знает число чашек с каждым способом приготовления (молоко
или чай сначала), поэтому якобы предоставляет правильное число угадываний в
каждой категории. Как было указано Фишером, в предположении нуль-гипотезы о
независимости испытаний это ведёт к использованию гипергеометрического
распределения для данного счёта в таблице.
С большими выборками в этой ситуации может использоваться тест
хи-квадрат. Однако этот тест не является подходящим, когда математическое
ожидание значений в любой из ячеек таблицы с заданными границами оказывается
ниже 10: вычисленное выборочное распределение испытуемой статистической
величины только приблизительно равно теоретическому распределению хи-квадрат, и
приближение неадекватно в этих условиях (которые возникают, когда размеры
выборки малы, или данные очень неравноценно распределены среди ячеек таблицы).
Тест Фишера, как следует из его названия, является точным и может поэтому
использоваться независимо от особенностей выборки. Тест становится
трудновычислимым для больших выборок или хорошо уравновешенных таблиц, но, к
счастью, именно для этих условий хорошо применим критерий Пирсона.
Для тестирования сети необходимо ввести на вход неизвестные образцы. На
(табл. 3.2) показана обученная сеть.
Для тестирования возьмем 30 образцов с явной принадлежностью к
определенному нейрону, т.е. образец должен находиться к одному нейрону ближе
чем к остальным.
Табл. 3.2
Координаты нейронов обученой сети Кохонена
|
|
Слой нейронов Кохонена
|
|
|
|
|
0,0000
|
0,0000
|
X3
|
X4
|
r(x-wi)
|
|
0
|
0,0000
|
0,0000
|
0,2203
|
0,1944
|
0,0000
|
|
1
|
0,0000
|
0,0000
|
0,3555
|
0,3332
|
0,0000
|
|
2
|
0,0000
|
0,0000
|
0,3164
|
0,4167
|
0,0000
|
0,0000
|
0,0000
|
0,3729
|
0,5833
|
0,0000
|
|
4
|
0,0000
|
0,0000
|
0,4305
|
0,8500
|
0,0000
|
|
5
|
0,0000
|
0,0000
|
0,6320
|
0,9048
|
0,0000
|
|
6
|
0,0000
|
0,0000
|
0,1864
|
0,1667
|
0,0000
|
|
7
|
0,0000
|
0,0000
|
0,1299
|
0,1111
|
0,0000
|
|
8
|
0,0000
|
0,0000
|
0,1866
|
0,3332
|
0,0000
|
|
9
|
0,0000
|
0,0000
|
0,3983
|
0,5000
|
0,0000
|
|
10
|
0,0000
|
0,0000
|
0,5738
|
0,6905
|
0,0000
|
|
11
|
0,0000
|
0,0000
|
0,9435
|
0,7500
|
0,0000
|
|
12
|
0,0000
|
0,0000
|
-0,8004
|
-0,7222
|
0,0000
|
|
13
|
0,0000
|
0,0000
|
0,0049
|
0,0116
|
0,0000
|
|
14
|
0,0000
|
0,0000
|
-0,0004
|
-0,1661
|
0,0000
|
|
15
|
0,0000
|
0,0000
|
0,2543
|
0,2499
|
0,0000
|
|
16
|
0,0000
|
0,0000
|
0,5593
|
0,4167
|
0,0000
|
|
17
|
0,0000
|
0,0000
|
0,7966
|
0,5000
|
0,0000
|
|
18
|
0,0000
|
0,0000
|
-0,8373
|
-0,8333
|
0,0000
|
|
19
|
0,0000
|
0,0000
|
-0,9322
|
-0,8833
|
0,0000
|
|
20
|
0,0000
|
0,0000
|
-0,1920
|
-0,2361
|
0,0000
|
|
21
|
0,0000
|
0,0000
|
0,1153
|
-0,0250
|
0,0000
|
|
22
|
0,0000
|
0,0000
|
0,3559
|
0,1833
|
0,0000
|
|
23
|
0,0000
|
0,0000
|
0,6269
|
0,2502
|
0,0000
|
|
24
|
0,0000
|
0,0000
|
-0,8767
|
-0,9167
|
0,0000
|
|
25
|
0,0000
|
0,0000
|
-0,8039
|
-0,9167
|
0,0000
|
|
26
|
0,0000
|
0,0000
|
-0,8712
|
-1,0000
|
0,0000
|
|
27
|
0,0000
|
0,0000
|
0,2203
|
-0,0278
|
0,0000
|
|
28
|
0,0000
|
0,0000
|
0,2542
|
0,0833
|
0,0000
|
|
29
|
0,0000
|
0,0000
|
0,5586
|
0,0834
|
0,0000
|
|
|
|
|
|
Минимальное расстояние
|
0,0000
|
|
|
|
|
Winner
|
i
|
j
|
|
|
|
|
0
|
0
|
0
|
Для тестирования возьмем из выборки неиспользованные образцы (табл. 3.3):
- 1 класс (с 41 по 50)
2 класс (с 91 по 100)
1 класс (с 141 по 150)
Табл.3.3
Выборка для тестирования
|
Выборка для тестирования 41-50, 91-100, 141-150
|
|
n
|
X1
|
X2
|
X3
|
X4
|
Класс
|
Кластер
|
|
1
|
0
|
0
|
-0,86441
|
-0,83333
|
1
|
18
|
|
2
|
0
|
0
|
-0,79661
|
-0,91667
|
1
|
25
|
|
3
|
0
|
0
|
-0,86441
|
-1
|
1
|
26
|
|
4
|
0
|
0
|
-0,89831
|
-0,83333
|
1
|
19
|
|
5
|
0
|
0
|
-0,76271
|
-0,83333
|
1
|
18
|
|
6
|
0
|
0
|
-0,83051
|
-0,83333
|
1
|
18
|
|
7
|
0
|
0
|
-0,76271
|
-0,91667
|
1
|
25
|
|
8
|
0
|
0
|
-0,83051
|
-0,75
|
1
|
12
|
|
9
|
0
|
0
|
-0,83051
|
-0,91667
|
1
|
25
|
|
10
|
0
|
0
|
-0,83051
|
-0,91667
|
1
|
25
|
|
11
|
0
|
0
|
-0,32203
|
-0,16667
|
2
|
20
|
|
12
|
0
|
0
|
0,050847
|
0
|
2
|
13
|
|
13
|
0
|
0
|
0,254237
|
0,083333
|
2
|
28
|
|
14
|
0
|
0
|
-0,11864
|
0
|
2
|
13
|
|
15
|
0
|
0
|
0,322034
|
0,166667
|
2
|
22
|
|
16
|
0
|
0
|
0,016949
|
0
|
2
|
13
|
|
17
|
0
|
0
|
0,016949
|
0
|
2
|
13
|
|
18
|
0
|
0
|
0,152542
|
0,083333
|
2
|
7
|
|
19
|
0
|
0
|
0,288136
|
0,083333
|
2
|
28
|
|
20
|
0
|
0
|
0,355932
|
0,333333
|
2
|
1
|
|
21
|
0
|
0
|
0,627119
|
0,416667
|
3
|
16
|
|
22
|
0
|
0
|
0,627119
|
0,75
|
3
|
10
|
|
23
|
0
|
0
|
0,666667
|
3
|
10
|
|
24
|
0
|
0
|
0,728814
|
1
|
3
|
5
|
|
25
|
0
|
0
|
0,389831
|
0,583333
|
3
|
3
|
|
26
|
0
|
0
|
0,457627
|
0,5
|
3
|
9
|
|
27
|
0
|
0
|
0,525424
|
0,666667
|
3
|
10
|
|
28
|
0
|
0
|
0,355932
|
0,583333
|
3
|
3
|
|
29
|
0
|
0
|
0,389831
|
0,916667
|
3
|
4
|
|
30
|
0
|
0
|
0,694915
|
1
|
3
|
5
|
После этого проводим кластерезацию образцов и сравниваем полученный выход
с требуемым. Заносим данные в (табл. 3.4).
Сравнивая табл. и табл. видим, что фактические и требуемые значения
совпадают, карта Кохонена указывает принадлежность к тому или иному кластеру
верно.
Табл.3.4
Классификация тестовых образцов
|
Образцы 41-50, 91-100, 141-150
|
|
1 класс
|
2 класс
|
3 класс
|
|
|
1
|
3
|
|
12
|
7
|
4
|
|
18
|
13
|
5
|
|
19
|
20
|
9
|
|
25
|
22
|
10
|
|
26
|
28
|
16
|
Можно сделать вывод о том, что созданная нейронная сеть обучена и
работает корректно.
.8 Создание,
обучение и тестирование сети Кохонена в Matlab
.8.1
Обоснование выбора среды для создания сети
Программное обеспечение, позволяющее работать с картами Кохонена, сейчас
представлено множеством инструментов. К инструментарию, включающему реализацию
метода карт Кохонена, относятся Matlab Neural Network Toolbox, SoMine,
Statistica, NeuroShell, NeuroScalp, Deductor и множество других.
Это инструменты, включающие только реализацию метода самоорганизующихся
карт, так и нейропакеты с целым набором структур нейронных сетей, среди которых
- и карты Кохонена; также данный метод реализован в некоторых универсальных
инструментах анализа данных. Исходя из специфики решаемых сетью задач, можно
сформулировать требования к интегрированной среде для моделирования процессов:
сбор и обработка информации;
возможность математических вычислений;
наглядный вывод результатов моделирования;
наличие оптимизационных процедур;
открытость архитектуры;
интеграция с офисными приложениями;
возможность использования программных модулей, написанных на других
языках программирования.
Всем указанным требованиям отвечает интегрированная среда математического
моделирования MATLAB.
3.8.2
Архитектура сети
Промоделированная архитектура самоорганизующейся карты Кохонена в MATLAB
NNT показана на рис. 328.

Рис. 3.28 . Архитектура самоорганизующейся карты Кохонена
Эта архитектура аналогична структуре слоя Кохонена за исключением того,
что здесь не используются смещения. Конкурирующая функция активации возвращает
1 для элемента выхода  , соответствующего победившему нейрону; все другие элементы
вектора равны 0.
, соответствующего победившему нейрону; все другие элементы
вектора равны 0.
Однако в сети Кохонена выполняется перераспределение нейронов,
соседствующих с победившим нейроном. При этом можно выбирать различные
топологии размещения нейронов и различные меры для вычисления расстояний между
нейронами.
.8.3 Создание
сети
Для создания самоорганизующейся карты Кохонена в составе ППП MATLAB NNT
предусмотрена М-функция newsom. По условиям задачи нам требуется создать сеть
для обработки двухэлементных векторов входа с диапазоном изменения элементов от
-1 до 1 и от -1 до 1 соответственно. Предполагается использовать гексагональную
сетку размера 6x5. Тогда для формирования такой нейронной сети достаточно
воспользоваться оператором:
net = newsom([-1 1; -1 1], [6 5]).layers{1}=: [6 5]:
'linkdist': [30x30 double]: 'initwb': 'netsum': [2x30 double]: 30: 'hextop':
'compet': [1x1 struct]

Рис. 3.29. Начальные входы нейрнов.
Из анализа характеристик этой сети следует, что она использует по
умолчанию гексагональную топологию hextop и функцию расстояния linkdist.
Для обучения сети зададим следующие 120 двухэлементных векторов входа, а
30 образцов, по 10 из каждого класса оставим для тестирования сети:
=[-0.86 -0.86 … n; 0.58 0.41 … n]
Построим на топографической карте начальное расположение нейронов карты
Кохонена (рис. 3.30):
hold on(P(1,;),P(2,:), '*к','markersize',10)

Рис. 3.30 . Расположение выборки обучающих образцов
Векторы входа помечены символом * и расположены по периметру рисунка, а
начальное расположение нейронов соответствует точке с координатами (1, 0.5).
.8.4 Обучение
сети
Обучение самоорганизующейся карты Кохонена реализуется повекторно
независимо от того, выполняется обучение сети с помощью функции trainwbl или
адаптация с помощью функции adaptwb. В любом случае функция learnsom выполняет
настройку элементов весовых векторов нейронов.
Прежде всего определяется нейрон-победитель и корректируются его вектор
весов и векторы весов соседних нейронов согласно соотношению:
 (3.8)
(3.8)
где  - параметр скорости обучения;
- параметр скорости обучения;  - массив параметров соседства для
нейронов, расположенных в окрестности нейрона-победителя i, который вычисляется
по соотношению:
- массив параметров соседства для
нейронов, расположенных в окрестности нейрона-победителя i, который вычисляется
по соотношению:
 (3.9)
(3.9)
где  - элемент выхода нейронной сети;
- элемент выхода нейронной сети;  - расстояние между нейронами i и j;
- расстояние между нейронами i и j;  - размер окрестности
нейрона-победителя.
- размер окрестности
нейрона-победителя.
Весовые векторы нейрона-победителя и соседних нейронов изменяются в
зависимости от значения параметра соседства. Веса нейрона-победителя изменяются
пропорционально параметру скорости обучения, а веса соседних нейронов - пропорционально
половинному значению этого параметра.
Процесс обучения карты Кохонена включает 2 этапа: этап упорядочения
векторов весовых коэффициентов в пространстве признаков и этап подстройки. При
этом используются следующие параметры обучения сети (таблица 3.4):
Табл. 3.4
Параметры обучения сети
|
Параметры обучения и настройки карты Кохонена
|
Значение по умолчанию
|
|
Количество циклов обучения
|
neе.trainParamepochs
|
N
|
>1000
|
|
Количество циклов на этапе упорядочения
|
netinputWeights{1,1}.learnParam.order_steps
|
S
|
1000
|
|
Параметр скорости обучения на этапе упорядочения
|
net.inputWeights{1,1}.leamParam.order_lr
|
order_lr
|
0.9
|
|
Параметр скорости обучения на этапе подстройки
|
net.inputWeights{1,1}.learnParam.tune_lr
|
tune
|
0.02
|
|
Размер окрестности на этапе подстройки
|
net.inputWeights(1,1).learnParam.tune_nd
|
tune_nd
|
1
|
В процессе построения карты Кохонена изменяются 2 параметра: размер
окрестности и параметр скорости обучения.
Этап упорядочения. На этом этапе используется фиксированное количество
шагов. Начальный размер окрестности назначается равным максимальному расстоянию
между нейронами для выбранной топологии и затем уменьшается до величины,
используемой на этапе подстройки в соответствии со следующим правилом:
 (3.10)
(3.10)
где
 - максимальное расстояние между нейронами;
- максимальное расстояние между нейронами;  - номер текущего шага.
- номер текущего шага.
Параметр скорости обучения изменяется по правилу:
 ) (3.11)
) (3.11)
Таким образом, он уменьшается от значения order_lr до значения tune_lr.
Этап подстройки. Этот этап продолжается в течение оставшейся части
процедуры обучения. Размер окрестности на этом этапе остается постоянным и
равным:
= tune_nd + 0.00001 (3.12)
Параметр скорости обучения изменяется по следующему правилу:
 (3.13)
(3.13)
Параметр скорости обучения продолжает уменьшаться, но очень медленно, и
именно поэтому этот этап именуется подстройкой. Малое значение окрестности и
медленное уменьшение параметра скорости обучения хорошо настраивают сеть при
сохранении размещения, найденного на предыдущем этапе. Число шагов на этапе
подстройки должно значительно превышать число шагов на этапе размещения. На
этом этапе происходит тонкая настройка весов нейронов по отношению к набору
векторов входа.
Как и в случае слоя Кохонена, нейроны карты Кохонена будут
упорядочиваться так, чтобы при равномерной плотности векторов входа нейроны
карты Кохонена также были распределены равномерно. Если векторы входа
распределены неравномерно, то и нейроны на карте Кохонена будут иметь тенденцию
распределяться в соответствии с плотностью размещения векторов входа.
Таким образом, при обучении карты Кохонена решается не только задача
кластеризации входных векторов, но и выполняется частичная классификация.
Выполним обучение карты:
Зададим количество циклов обучения равным 500:
net.trainParam.epochs = 500.trainParam.show = 100= train
(net, P)(P(1,:),P(2,:), '*',
'markersize',10)on(net.iw{1*1},net.layers{1}.distances)
Результат обучения представлен на рис. 3.31.

Рис. 3.31. Карта Кохонена обученная
Положение нейронов и их нумерация определяются массивом весовых векторов,
который для данного примера имеет вид:
.IW{l}=
. -0.8545 -0.8994
2. -0.7932 -0.8143
. -0.2709 -0.2603
. 0.1882 0.2544
. 0.3662 0.5626
. 0.4867 0.7698
. -0.8393 -0.8660
. -0.3886 -0.3762
. 0.1418 0.1526
. 0.2705 0.3433
. 0.4644 0.6633
. 0.5763 0.8375
. -0.5093 -0.5309
. -0.2643 -0.2911
. 0.1246 0.0871
. 0.2464 0.2180
. 0.3882 0.3787
. 0.6330 0.6630
. -0.0016 -0.1233
. 0.0864 -0.0209
. 0.1945 0.0661
. 0.3692 0.2297
. 0.5971 0.4455
. 0.7805 0.6008
. -0.0040 -0.1857
. 0.0668 -0.0835
. 0.1446 -0.0139
. 0.2837 0.0732
. 0.5270 0.2719
. 0.7390 0.4789
Пронумеруем на карте Кохонена кластеры и линией отделим один класс от
другого (рис. 3.32).

Рис. 3.32. Карта Кохонена в Matlab
Если промоделировать карту Кохонена на массиве обучающих векторов входа,
то будет получена принадлежность нейронов к определенному классу (табл. 3.5):
Табл. 3.5
Классификация нейронов
|
1 класс
|
2 класс
|
3 класс
|
|
1
|
3
|
4
|
|
2
|
4
|
5
|
|
7
|
9
|
6
|
|
10
|
10
|
|
15
|
12
|
|
16
|
17
|
|
19
|
18
|
|
20
|
22
|
|
21
|
23
|
|
22
|
24
|
|
25
|
29
|
|
26
|
30
|
|
27
|
|
|
28
|
|
Это означает, что векторы входов 1, 2, 7 отнесены к классу с номером 1,
векторы 3,4, 9, 10, 15, 16, 19, 20, 21, 22, 25, 26, 27, 28 - к клаccу 2,
векторы 4, 5, 6, 10, 12, 17, 18, 22, 23, 24, 29, 30 - к классcу 3. Номер
кластера в таблице соответствует номеру соответствующего нейрона на карте
Кохонена. Видим, что во 2-ом и 3-ем классах встречаются одинаковые нейроны. Это
говорит о том, что классификация образцов на границе классов происходит
неоднозначно и встречаются пересечения.
Если сформировать произвольный вектор входа, то карта Кохонена должна
указать его принадлежность к тому или иному кластеру:
а = sim(net,[1; 1])
а = (12,1) 1.
В данном случае представленный вектор входа отнесен к кластеру с номером
12. Векторов такого сорта в обучающей последовательности не было. Можно сделать
вывод, что сеть обучена и может классифицировать неизвестные векторы.
.8.5
Тестирование сети
Для проверки правильности обучения построенной нейронной сети в
нейроимитаторах предусмотрены специальные средства ее тестирования. В сеть
вводится некоторый сигнал, который, как правило, не совпадает ни с одним из
входных сигналов примеров обучающей выборки. Далее анализируется получившийся
выходной сигнал сети.
Тестирование обученной сети может проводиться либо на одиночных входных
сигналах, либо на тестовой выборке, которая имеет структуру, аналогичную обучающей
выборке, и также состоит из пар (<вход>, <требуемый выход>).
Обычно, обучающая и тестовая выборки не пересекаются. Тестовая выборка строится
индивидуально для каждой решаемой задачи.
Для тестирования сети необходимо ввести на вход неизвестные образцы. На
(рис. 13) показана обученная сеть. Для тестирования возьмем 12 образцов с явной
принадлежностью к определенному нейрону, т.е. образец должен находиться к
одному нейрону ближе чем к остальным.
Для тестирования возьмем из выборки неиспользованные образцы (табл. 1):
1 класс (с 41 по 50)
2 класс (с 91 по 100)
1 класс (с 141 по 150)
Сформируем последовательности векторов для каждого класс отдельно и
промоделируем карту Кохонена на полученных массивах:
- 1 класс=[-0.898 -0.864 -0.796
-0.864 -0.898 -0.762 -0.830 -0.762 -0.830 -0.830 -0.830; -0.75 -0.833
-0.916 -1 -0.833 -0.833 -0.83333 -0.916 -0.75 -0.916 -0.916]
a = sim(net,P)=
(2,1) 1
(7,2) 1
(1,3) 1
(1,4) 1
(7,5) 1
(2,6) 1
(7,7) 1
(7,8) 1
(2,9) 1
(1,10) 1
(1,11) 1
- 2 класс
P=[-0.32 0.05 0.25 -0.11 0.32 0.01 0.01 0.15 0.28 0.35; -0.16
0 0.08 0.16 0 0 0.083 0.08 0.33]
а =
sim(net,P)
a =
(3,1) 1
(20,2) 1
(28,3) 1
(19,4) 1
(22,5) 1
(20,6) 1
(20,7) 1
(15,8) 1
(28,9) 1
(19,10) 1
3 класс=[0.627 0.627 0.491 0.728
0.389 0.457 0.525 0.355 0.389 0.694; 0.416 0.75 0.666 1 0.583 0.5 0.666
0.583 0.916 1]= sim(net,P)
a =
(23,1) 1
(18,2) 1
(11,3) 1
(12,4) 1
(5,5) 1
(5,6) 1
(11,7) 1
(5,8) 1
(6,9) 1
(12,10) 1
После этого проводим кластерезацию образцов и сравниваем полученный выход
с требуемым. Заносим данные в (табл. 3.6).
Табл. 3.6
Классификация тестовых образцов
|
1 класс2 класс3 класс
|
|
|
|
1
|
3
|
4
|
|
2
|
4
|
5
|
|
7
|
9
|
6
|
|
|
10
|
10
|
|
|
15
|
12
|
|
|
16
|
17
|
|
|
19
|
18
|
|
|
20
|
22
|
|
|
21
|
23
|
|
|
22
|
24
|
|
|
25
|
29
|
|
|
26
|
30
|
|
|
27
|
11
|
|
|
28
|
|
Сравнивая табл. 3.5 и табл. 3.6 видим, что фактические и требуемые
значения совпадают, карта Кохонена указывает принадлежность к тому или иному
кластеру верно. Во втором классе встречается 22-ой кластер, который не
однозначно классифицирует образцы.
Можно сделать вывод о том, что созданная нейронная сеть обучена и
работает корректно. Нейроны с номерами 4, 10, 22 классифицируют неоднозначно,
потому что находятся в зоне границы двух классов. Для решения этой проблемы
можно увеличить количество нейронов в сети.
.9 Сравнение
результатов кластеризации в Matlab и Excel
Теперь для более объективной оценки работы нейронной сети обучим
нейронную сеть 4000 образцов.
Построим на топографической карте начальное расположение нейронов карты
Кохонена (рис. 3.33):
hold on(P(1,;),P(2,:), '*к','markersize',10)

Рис. 3.33 . Расположение выборки из 4000 обучающих образцов
Векторы входа помечены символом * и, а начальное расположение нейронов
соответствует точке с координатами (1, 0.5).
Обучение сети
Прежде всего определяется нейрон-победитель и корректируются его вектор
весов и векторы весов соседних нейронов согласно соотношению:
Весовые векторы нейрона-победителя и соседних нейронов изменяются в
зависимости от значения параметра соседства.
Веса нейрона-победителя изменяются пропорционально параметру скорости
обучения, а веса соседних нейронов - пропорционально половинному значению этого
параметра.
Выполним обучение карты:
Зададим количество циклов обучения равным 500:
net.trainParam.epochs = 500.trainParam.show = 100= train
(net, P)(P(1,:),P(2,:), '*',
'markersize',5)on(net.iw{1*1},net.layers{1}.distances)
Результат обучения представлен на рис. 3.34.

Рис. 3.34 . Карта Кохонена обученная
Положение нейронов и их нумерация определяются массивом весовых векторов,
который для данного примера имеет вид рис. 3.35:

Рис. 3.35. Массив весовых векторов
Заключение
На основе проведенных исследований предложен принципиально новый метод
распознавания образов с помощью неординарного алгоритма и программной
реализации, осуществляющей функционирование новой разделенной структуры
искусственной нейронной сети (ИНС), использующей нейро-матричную реализацию для
классификации обрабатываемых данных. Основные результаты диссертационной работы
следующие:
На основе анализа и обработки специальной литературы и ресурсов Интернет
были проработаны, выявлены и применены принципы и знания из теории
нейробиологии, нейроинформатики, кибернетики, искусственного интеллекта,
искусственных нейронных сетей и нейросетвой самоорганизации, персептронов,
кластеризации и категоризации объектов, анализа сцен, машинного распознавания
образов, теории множеств, дискретной математики. Для исследования проблемы была
введена большая база данных (БД) из эталонных образов, состоящая из
разновидностей пяти выборок данных для обучения нейронной сети.
1. Антонов А.С. Введение в параллельные
вычисления. Методическое пособие / А.С. Антонов. - М.: Изд-во МГУ, 2002. - 70
с.
2. Букатов А.А., Дацюк В.Н., Жегуло А.И.
Программирование многопроцессорных вычислительных систем / А.А. Букатов, В.Н.
Дацюк, А.И. Жегуло. - Ростов-на-Дону: Изд-во ООО "ЦВВР", 2003. - 208
с.
3. Буцев А.В., Первозванский А.А.
Локальная аппроксимация на искусственных нейросетях / А.В. Буцев // Автоматика
и Телемеханика 1995. №9. С. 127-136
4. Вальковский В.А., Котов В.Е., Марчук
А.Г., Миренков Н.Н. Элементы параллельного программирования / В.А. Вальковский,
В.Е. Котов, А.Г. Марчук, Н.Н. Миренков. - М.: Радио и связь, 1983. - 240 с.
5. Вапник В.Н. Восстановление
зависимостей по эмпирическим данным / В.Н. Вапник. - М.: Наука, 1980, 520 с.
6. Васильев Д. Знакомьтесь, Erlang / Д.
Васильев // Системный администратор. - 2009. - №8
7. Воеводин В.В. Математические модели и
методы в параллельных процессах / В.В. Воеводин. - М.: Наука, 1986, 296 с.
8. Воеводин В.В., Воеводин Вл.В.
Параллельные вычисления / В.В. Воеводин, Вл.В. Воеводин. - СПб.ГУ, 1997. - 308
с.
9. Воронцов, К. В., Лекции по
искусственным нейронным сетям // К.В. Воронцов. - Воронеж, 2007. - 29 с.
10. Галушкин А.И. Нейронные сети. Основы
теории / А.И. Галушкин. - М.: Горячая линия - Телеком, 2012. - 496 с.
11. Галушкин А.И. Нейронные сети: история
развития: учеб. Пособие для вузов / А.И. Галушкин, Я.З. Цыпкин. - М.: ИПРЖ,
2001. - 839 с.
12. Герасименко М.С. Вычисление
искусственных нейронных сетей на вычислительных кластерах или ЛВС / М.С.
Герасименко / Вестник Воронежского государственного университета, Серия:
Системный анализ и информационные технологии, №1, 2010. - С. 120-125
13. Головко В.А. Нейронные сети:
обучение, организация и применение / В.А. Головко. - М.: ИПРЖР, 2001, 256 с.
14. Горбань А.Н. Обобщенная
аппроксимационная теорема и вычислительные возможности нейронных сетей / А. Н.
Горбань // Сибирский журнал вычислительной математики - 1998. - Т. 1, №1. - С.
12-24
15. Горбань А.Н. Обучение нейронных сетей
/ А.Н. Горбань. - М.: Параграф, 1990. - 160 с.
16. Городняя Л.В. Основы функционального
программирования. Курс лекций / Л.В. Городняя. - М.: Интернет-университет
информационных технологий, 2004. 280 с.
17. Демиденко Е.З. Оптимизация и
регрессия / Е.З. Демиденко. - М.: Наука, 1989. - 293с.
18. Дорогов А.Ю. Быстрые нейронные сети /
А.Ю. Дорогов. - СПб.: СПУ, 2002. - 80 с.
19. Ионов С.Д. Распределенная потоковая
нейронная сеть / С.Д. Ионов // Современные проблемы математики: тез. 42-й
Всеросс. молодежн. шк.-конф., 30 янв. - 6 февр. 2011 г. Екатеринбург: ИММ УрО
РАН, 2011. С. 288-290
20. Калинин А.В. Математическое и
программное обеспечение массивнопараллельных вычислений в распределенных
системах на базе аппарата нейронных сетей: Дис. канд. техн. наук. - Воронеж,
2003. - 157 с.
21. Калинин А.В., Подвальный, С.Л.
Технология нейросетевых распределенных вычислений / А.В. Калинин, С.Л.
Подвальный. - Воронеж: ВГУ, 2004. - 121 с.
22. Каллан Р. Основные концепции
нейронных сетей / Р. Каллан. - М.: Вильямс, 2001. - 288 с.
23. Классификация параллельных
вычислительных систем. [Электронный ресурс]. - Режим доступа:
http://ru.wikipedia.org/wiki/Классификация параллельных вычислительных систем.
24. Королюк В.С. Справочник по теории
вероятностей и математической статистике / В.С. Королюк, Н.И. Портенко, А.В.
Скротоход, А.Ф. Турбин. - М.: Наука, Главная редакция физико-математической
литературы, 1985. - 640 с.
25. Красовский Г.И., Филаретов Г.Ф.
Планирование эксперимента / Г.И. Красовский, Г.Ф. Филаретов. - Минск: изд-во
БГУ, 1982. - 302 с.
26. Крил П. Функциональное
программирование - друг параллелизма / П. Крил // Открытые системы. - 2010. -
№8
27. Круглов В.В. Нечеткая логика и
искусственные нейронные сети // В.В. Круглов, М.И. Дли, Р.Ю. Голунов: Учеб.
пособие. - М.: Физматлит, 2001. - 224 с.
28. Нейронные сети. STATISTICA Neural
Networks: Методология и технологии современного анализа данных / Под редакцией
В.П. Боровикова. - 2-е изд., перераб. и доп. - М.: Горячая линия - Телеком,
2008. - 288 с.
29. Оссовский С. Нейронные сети для
обработки информации / Пер. с польского И.Д. Рудинского. - М.: Финансы и
статистика, 2002. - 344 с.
30. Официальный сайт Emergent Neural Network Simulation System
[Электронный ресурс]. - Режим доступа:
http:
//grey.colorado. edu/emergent/index.php.
31. Официальный сайт FANN [Электронный
ресурс]. - Режим доступа: http://leenissen.dk/fann/wp.
32. Официальный сайт IBM [Электронный
ресурс]. - Режим доступа: http://ibm.com.
33. Официальный сайт Mathworks
[Электронный ресурс]. - Режим доступа: http: //www.mathworks .com.
34. Официальный сайт Neurosolutions
[Электронный ресурс]. - Режим доступа: http: //www.neurosolutions .com.
35. Официальный сайт Oracle VirtualBox
[Электронный ресурс]. - Режим доступа: http://www.virtualbox.org.
36. Официальный сайт PCSIM [Электронный
ресурс]. - Режим доступа: http: //www.lsm.tugraz.at/pcsim.
37. Официальный сайт STATISTICA Automated
Neural Networks - автоматизированные нейронные сети [Электронный ресурс]. -
Режим доступа: http://www.statsoft.ru/products/STATISTICA_Neural_Networks
38. Официальный сайт VMWare [Электронный
ресурс]. - Режим доступа: http:// www.vmware.com.
39. Официальный сайт Wolfram Mathematica
[Электронный ресурс]. - Режим доступа: http://www.wolfram.com.
40. Поляк Б.Т. Введение в оптимизацию /
Б.Т. Поляк. М.: Наука, 1983. - 384 с.
41. Розенблатт Ф. Принципы нейродинамики:
Перцептрон и теория механизмов мозга / Ф. Розенблатт. - М. Мир, 1965. - 480 с.
42. Рутковская Д. Нейронные сети,
генетические алгоритмы и нечеткие системы / Д. Рутковская и др. - М. Горячая
линия - Телеком, 2004. - 452 с.
2011. Сидняев Н.И. Введение в теорию
планирования эксперимента: учеб. пособие / Н.И. Сидняев, Н.Т. Вилисова. - М.:
изд-во МГТУ им. Н.Э. Баумана, - 463 с.
43. Тархов Д.А. Нейронные сети. Модели и
алгоритмы. Кн. 18 / Д.А. Тархов. - М.: Радиотехника, 2005. - 256 с.: ил.
44. Хайкин С. Нейронные сети: полный
курс, 2-e издание.: Пер. с ант. -М. Издательский дом "Вильямс", 2006.
- 1104 с.: ил. - Парал. тит. ант.
45. Чезарини Ф., Томпсон, С.
Программирование в Erlang / Ф. Чезарини, С. Томпсон. - М.: ДМК Пресс, 2012. -
488 с.
46. Hopfield J.J. Neural networks and physical systems with emergent
collective computational abilities / J.J. Hopfield, Proceedings of National
Academy of Sciences, vol. 79 no. 8, 1982. - pp. 2554-2558
47. Hornik K., Stinchcombe M., White H. Multilayer feedforward networks are
universal approximators, Neural Netw., vol. 2, no. 5, pp. 359-366, 1989
48. IBM BladeCenter HS22 Technical Introduction [Электронный ресурс]. - Режим доступа: http: //www.redbooks .ibm.com/redpapers/pdfs/redp453 8.
pdf.
49. Leshno M., Lin V.Y., Pinkus A., Schocken S. Multilayer feedforward
networks with a nonpolynomial activation function can approximate any function,
Neural Netw., vol. 6, no. 6, pp. 861-867, 1993
50. Levenberg K A method for the solution of certain problems in least
squares, Quart. Appl. Math., vol. 2, pp. 164-168, 1944