Вычисление двойного интеграла c использованием средств параллельного программирования MPI
Министерство
образования и науки Российской Федерации
Федеральное
государственное бюджетное образовательное учреждение высшего профессионального
образования
Вятский
государственный университет
Факультет
автоматики и вычислительной техники
Кафедра
электронных вычислительных машин
Отчет по
лабораторной работе №8
по
дисциплине:
Вычислительные
машины, комплексы и системы
Тема:
Вычисление
двойного интеграла c
использованием средств параллельного программирования MPI
Выполнил
студент группы ВМ-41
Проверил:
преподаватель кафедры ЭВМ
Мельцов В.Ю.
Киров 2012
Постановка задачи:
Составить программу, реализующую расчёт двойного
интеграла с использованием средств параллельного программирования.
Краткие теоретические сведения:
Двойные интегралы обладают такими же свойствами,
как и определённые интегралы (линейность, аддитивность, формулы среднего
значения и т.д.).
Двойной интеграл в декартовых
координатах
Пусть функция  определена
и непрерывна в замкнутой ограниченной области D плоскости 0xy.
определена
и непрерывна в замкнутой ограниченной области D плоскости 0xy.
Разобьём область D произвольным образом на
элементарные ячейки  , в каждой из
которых зафиксируем точку:
, в каждой из
которых зафиксируем точку:
 .
.
Составим сумму:
 ,
,
называемую интегральной, которая соответствует
данному разбиению D на части и данному выбору точек 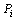 .
.
Если существует предел последовательности
интегральных сумм  при
при  -диаметр
ячеек
-диаметр
ячеек 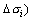 и
этот предел не зависит ни от способа разбиения области D на элементарные
ячейки, ни от выбора точек
и
этот предел не зависит ни от способа разбиения области D на элементарные
ячейки, ни от выбора точек 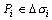 , то он называется
двойным интегралом от функции f(x,y) по области D и обозначается
, то он называется
двойным интегралом от функции f(x,y) по области D и обозначается 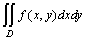 .
.
Листинг
программы:
#include <iostream>
#include <ctime>
#include "mpi.h"
namespace std;
//----------------- Эта функция считает значение
функции
*X^2*Y+2*Y^3
double Func ( double X , double Y )
{( 5*X*X*Y-2*Y*Y*Y );
}
//------- Эта функция возвращает случайное число
в диапозоне от 0 до 1
double GetRandom ()
{(double) rand ()/RAND_MAX;
}
//----------------- Эта функция считает интеграл
--------------------DoubleIntegrall ( long long N , // Количество отрезков
интегрированияAX , double BX ,// Интервал откуда
берем случайные значения
для XAY , double BY )// Интервал откуда берем
случайные значения
для Y
{HX = BX-AX , HY = BY-AY ,x, y, f =
0;long i;
( i=0; i<N; i++ )
{= (double) ( GetRandom ()*HX + AX
);= (double) ( GetRandom ()*HY + AY );=+ Func ( x , y );
}
( HX*HY*f/N );
}
//------------------- MAIN
-------------------------------main(int argc, char *argv[])
{My_Rank; /* ранг текущего процесса */NumProcs;
/* общее число процессов */AX , AY; /* левый конец интервала */BX , BY; /*
правый конец интервала */long N; /* число точек разбиения */LenX; /*LenY; /*
длина отрезка интегрирования для текущего
процесса*/Local_AX , Local_AY;/* левый конец
интервала для текущего
процесса */Local_BX , Local_BY; /* правый конец
интервала для текущего
процесса */long Local_N; /* число точек
разбиения для текущего процесса */Local_Res;/* значение интеграла в текущем
процессе */Result; /* результат интегрирования */WTime; /* время работы
программы */
/* Инициализация
ГСЧ
*/( ( unsigned ) time ( NULL ) );
/* Начать работу с MPI */_Init(&argc,
&argv);
cout.setf(ios::fixed);.precision(0);
/* Получить номер текущего процесса в группе
всех процессов */
MPI_Comm_rank(MPI_COMM_WORLD,
&My_Rank);
/* Получить общее количество запущенных
процессов */
MPI_Comm_size(MPI_COMM_WORLD,
&NumProcs);
/* Получить данные */
if (My_Rank == 0)
{<< "Input initial X:
";>> AX;<< "Input final X: ";>> BX;
<< "Input initial Y:
";>> AY;<< "Input final Y: ";>> BY;
<< "Input number of
random value: ";
cin >> N;
}
/* Рассылаем данные из процесса 0 остальным */
/* Синхронизация
процессов
*/_Barrier(MPI_COMM_WORLD);
/* Запускаем
таймер
*/= MPI_Wtime();
/* Вычисляем отрезок интегрирования для текущего
процесса */
LenX = (BX-AX)/NumProcs;=
(BY-AY)/NumProcs;
_N = N/NumProcs;_AX = AX +
My_Rank*LenX;_BX = Local_AX + LenX;_AY = AY + My_Rank*LenY;_BY = Local_AY +
LenY;
/* Вычислить интеграл на каждом из процессов */
Local_Res = DoubleIntegrall
(Local_N, Local_AX, Local_BX, Local_AY,
Local_BY);
/* Сложить все ответы и передать процессу 0 */
MPI_Reduce(&Local_Res,
&Result, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
/* Синхронизация
процессов
*/_Barrier(MPI_COMM_WORLD);
/* Вычисляем
время
работы
*/= MPI_Wtime() - WTime;
/* Напечатать
ответ
*/(My_Rank == 0)
{<< "Integral X:[ "
<< AX << ";" << BX
<< "] Y:[ " <<
AY << ";" << BY << "] = ";
.setf(ios::fixed);.precision(16);<<
"Result: " << Result << endl;<< "Working time:
" << WTime;.get();
}
/* Заканчиваем работу с MPI */_Finalize();
двойной интеграл параллельный программирование
return 0;
}
Программа выполнялась на одном и двух узлах,
содержащих по два четырехядерных процессора. Результаты работы программы на
одном узле представлены в таблице 1 и на рисунке 1:
Таблица
1
Результаты работы программы
|
Кол-во
входных значений Кол-во потоков
|
1
|
2
|
4
|
8
|
16
|
|
9000
|
0.0007537975907326
|
0.0004366477951407
|
0.0002305461093783
|
0.0001368187367916
|
0.0013112705200911
|
|
90000
|
0.0075306361541152
|
0.0041533205658197
|
0.0020909076556563
|
0.0010627051815391
|
0.0012023178860545
|
|
900000
|
0.0747467903420329
|
0.0415767226368189
|
0.0205570114776492
|
0.0104573350399733
|
0.0158112971112132
|
|
9000000
|
0.6697816345840693
|
0.3893552813678980
|
0.2064179945737124
|
0.1102980962023139
|
0.1532170288264751
|
|
90000000
|
6.4390025129541755
|
3.5495505714789033
|
1.7656840458512306
|
0.9044017465785146
|
0.9163652779534459
|

Рисунок 1 - Результаты работы программы на одном
узле
Результаты работы программы на двух узлах
представлены в таблице 2 и на рисунке 2:
Таблица
2
Результаты работы программы
|
Кол-во
входных значений / Кол-во потоков
|
1
|
2
|
4
|
16
|
|
9000
|
0.0007815938442945
|
0.0004680063575506
|
0.0002564573660493
|
0.0001599360257387
|
0.0001156572252512
|
|
90000
|
0.0074913846328855
|
0.0047103753313422
|
0.0021183555945754
|
0.0011150157079101
|
0.0005718600004911
|
|
900000
|
0.0757572539150715
|
0.0415737889707088
|
0.0208176597952843
|
0.0104006938636303
|
0.0052353022620082
|
|
9000000
|
0.6576117919757962
|
0.3760839011520147
|
0.1871296493336558
|
0.1041500391438603
|
0.0524644199758768
|
|
90000000
|
6.4406823348253965
|
3.5316434074193239
|
1.7737049683928490
|
0.8969459105283022
|
1.0058119120076299
|

Рисунок 2 - Результаты работы программы на двух
узлах
Таблица
3
Результаты работы программы на одном узле
|
Кол-во
входных данных
|
1
поток
|
2
потока
|
4
потока
|
|
время
|
время
|
ускорение
|
время
|
ускорение
|
|
9000
|
0,0007537975
|
0,0004366477
|
0,0003171498
|
0,0002305461
|
0,0002061016
|
|
90000
|
0,0075306361
|
0,0041533205
|
0,0033773156
|
0,0020909073
|
0,0020624129
|
|
900000
|
0,0747467903
|
0,0415767226
|
0,0331700677
|
0,0205570114
|
0,0210197111
|
|
9000000
|
0,6697816345
|
0,3893552813
|
0,2804263532
|
0,2064179945
|
0,1829372867
|
|
90000000
|
6,4390025129
|
2,8894519415
|
1,7656840458
|
1,7838665256
|
|
8
потоков
|
16
потоков
|
|
время
|
ускорение
|
время
|
ускорение
|
|
9000
|
0,0001368187
|
0,0000937273
|
0,0013112705
|
-0,0011744517
|
|
90000
|
0,0010627051
|
0,0010282024
|
0,0012023178
|
-0,0001396127
|
|
900000
|
0,0104573350
|
0,0100996764
|
0,0158112971
|
-0,0053539620
|
|
9000000
|
0,1102980962
|
0,0961198983
|
0,1532170288
|
-0,0429189326
|
|
90000000
|
0,9044017465
|
0,8612822992
|
0,9163652779
|
-0,0119635313
|
|
|
|
|
|
|
|
Таблица
4
Результаты работы программы на двух узлах
|
Кол-во входных данных
|
1 поток
|
2 потока
|
4 потока
|
|
время
|
время
|
ускорение
|
время
|
ускорение
|
|
9000
|
0,00078159384
|
0,00046800635
|
0,0003135875
|
0,00025645736
|
0,0002115490
|
|
90000
|
0,00749138463
|
0,00471037533
|
0,0027810093
|
0,00211835559
|
0,0025920197
|
|
900000
|
0,07575725391
|
0,04157378897
|
0,0341834649
|
0,02081765979
|
0,0207561292
|
|
9000000
|
0,65761179197
|
0,37608390115
|
0,2815278908
|
0,18712964933
|
0,1889542518
|
|
90000000
|
3,53164340741
|
2,9090389274
|
1,77370496839
|
1,7579384390
|
|
8 потоков
|
16 потоков
|
|
время
|
ускорение
|
время
|
ускорение
|
|
9000
|
0,00015993602
|
0,0000965213
|
0,00011565722
|
0,0000442788
|
|
90000
|
0,00111501570
|
0,0010033399
|
0,00057186000
|
0,0005431557
|
|
900000
|
0,01040069386
|
0,0104169659
|
0,00523530226
|
0,0051653916
|
|
9000000
|
0,10415003914
|
0,0829796102
|
0,05246441997
|
0,0516856192
|
|
90000000
|
0,89694591052
|
0,8767590579
|
1,00581191200
|
-0,1088660015
|
Выводы
На основе результатов работы программы можно
сделать следующие выводы:
¾ Использование двух потоков для
решения данной задачи, уменьшает время ее выполнения в два раза, так как
количество входных значений на интервале разделяется между двумя ядрами;
¾ При небольшом значении входных
данных (n=9000) увеличение
потоков с 1 до 8, дает выигрыш во времени примерно в 7 раз;
¾ Данная задача выполнялась на узле,
содержащем два четырехядерных процессора, поэтому при увеличении потоков до 16
происходит незначительное уменьшение времени решения данной задачи, так как в
данном случае на каждое ядро процессора приходится по 2 потока;