|
Функция
|
Возвращаемое
значение
|
|
COUNT
|
Количество
значений в столбце или строк в таблице
|
|
SUM
|
Сумма
|
|
AVG
|
Среднее
|
|
MIN
|
Минимум
|
|
MAX
|
Максимум
|
Общий формат унарной агрегатной функции
следующий:
имя_функции([АLL | DISTINCT] выражение)
где DISTINCT указывает, что функция должна
рассматривать только различные значения аргумента, а ALL - все значения,
включая повторяющиеся (этот вариант используется по умолчанию). Например,
функция AVG с ключевым словом DISTINCT для строк столбца со значениями 1, 1, 1
и 3 вернет 2, а при наличии ключевого слова ALL вернет 1,5.
Агрегатные функции применяются во фразах SELECT
и HAVING. Здесь мы рассмотрим их использование во фразе SELECT. В этом случае
выражение в аргументе функции применяется ко всем строкам входной таблицы фразы
SELECT. Кроме того, во фразе SELECT нельзя использовать и агрегатные функции, и
столбцы таблицы (или выражения с ними) при отсутствии фразы GROUP BY, которую
мы рассмотрим в следующем разделе.
Функция COUNT имеет два формата. В первом случае
возвращается количество строк входной таблицы, во втором случае - количество
значений аргумента во входной таблице:
COUNT(*)([DISTINCT | ALL] выражение)
Простейший способ использования этой функции -
подсчет количества строк в таблице (всех или удовлетворяющих указанному
условию). Для этого используется первый вариант синтаксиса.
Запрос: Количество видов продукции, информация о
которых имеется в базе данных.COUNT(*) AS 'Количество видов продукции'Product
Во втором варианте синтаксиса функции COUNT в
качестве аргумента может быть использовано имя отдельного столбца. В этом
случае подсчитывается количество либо всех значений в этом столбце входной
таблицы, либо только неповторяющихся (при использовании ключевого слова
DISTINCT).
Запрос: Количество различных имен, содержащихся
в таблице Customer.
SELECT COUNT(DISTINCT FNAME)Customer
Использование остальных унарных агрегатных
функции аналогично COUNT за тем исключением, что для функций MIN и MAX
использование ключевых слов DISTINCT и ALL не имеет смысла. С функциями COUNT,
MAX и MIN кроме числовых могут использоваться и символьные поля. Если аргумент
агрегатной функции не содержит значений, функция COUNT возвращает 0, а все
остальные - значение NULL.
Запрос: Дата последнего заказа до 1 сентября
2010 года.
SELECT MAX(OrdDate)[Order]
WHERE OrdDate<'1.09.2010'
Задание для самостоятельной работы:
Сформулируйте на языке SQL запросы на выборку следующих данных:
Суммарная стоимость всех заказов;
Количество различных городов, содержащихся в
таблице Customer.
Запросы с группировкой строк
Описанные выше агрегатные функции применялись ко
всей таблице. Однако часто при создании отчетов появляется необходимость в
формировании промежуточных итоговых значений, то есть относящихся к данным не
всей таблицы, а ее частей. Для этого предназначена фраза GROUP BY. Она
позволяет все множество строк таблицы разделить на группы по признаку равенства
значений одного или нескольких столбцов (и выражений над ними). Фраза GROUP BY
должна располагаться вслед за фразой WHERE (если она отсутствует, то за фразой
FROM).
При наличии фразы GROUP BY фраза SELECT
применяется к каждой группе, сформированной фразой группировки. В этом случае и
действие агрегатных функций, указанных во фразе SELECT, будет распространяться
не на всю результирующую таблицу, а только на строки в пределах каждой группы.
Каждое выражение в списке фразы SELECT должно принимать единственное значение
для группы, то есть оно может быть:
константой;
агрегатной функцией, которая оперирует всеми
значениями аргумента в пределах группы и агрегирует их в одно значение
(например, в сумму);
выражением, идентичным стоящему во фразе GROUP
BY;
выражением, объединяющим приведенные выше
варианты.
Самым простым вариантом использования фразы
GROUP BY является группировка по значениям одного столбца.
Запрос: Количество клиентов по городам.
SELECT IdCity, COUNT(*) AS 'Кол-во
клиентов'
FROM CustomerBY IdCity
Если в запросе используются фразы и WHERE, и
GROUP BY, строки, не удовлетворяющие условию фразы WHERE, исключаются до
выполнения группировки. Вследствие этого группировка производится только по тем
строкам, которые удовлетворяют условию.
Запрос: Количество клиентов по городам с
фамилией ‘Иванов’.
SELECT IdCity, COUNT(*) AS 'Кол-во
клиентов'CustomerLName
= 'Иванов'BY
IdCity
SQL позволяет группировать строки таблицы и по
нескольким столбцам. В этом случае имена столбцов перечисляются во фразе GROUP
BY через запятую.
Запрос: Количество клиентов по каждой фамилии и
имени.
SELECT LName, FName,
COUNT(*)Customer
GROUP BY LName, FName
Для отбора строк среди полученных групп
применяется фраза HAVING. Она играет такую же роль для групп, что и фраза WHERE
для исходных таблиц, и может использоваться лишь при наличии фразы GROUP BY. В
предложении SELECT фразы WHERE, GROUP BY и HAVING обрабатываются в следующем
порядке.
Фразой WHERE отбираются строки, удовлетворяющие
указанному в ней условию;
Фраза GROUP BY группирует отобранные строки;
Фразой HAVING отбираются группы, удовлетворяющие
указанному в ней условию.
Значение условия, указываемого во фразе HAVING,
должно быть уникальным для всех строк каждой группы. Поэтому правила использования
имен столбцов и агрегатных функций во фразе HAVING такие же, как и для фразы
SELECT при наличии фразы GROUP BY. Это значит, что во фразе HAVING в качестве
операндов сравнения можно использовать только группируемые столбцы или
агрегатные функции.
Запрос: Список городов, количество клиентов из
которых больше 10.
SELECT IdCityCustomerBY IdCity
HAVING COUNT(*)>10
Задание для самостоятельной работы:
Сформулируйте на языке SQL запросы на выборку следующих данных:
Список всех заказов с указанием их суммарной
стоимости;
Список клиентов, которые за заданный период
(например, сентябрь 2010 года) совершили более 3 заказов.
Лабораторная работа №4. Основы
Transact SQL: Сложные (многотабличные запросы)
В SQL сложные запросы являются комбинацией
простых SQL-запросов. Каждый простой запрос в качестве ответа возвращает набор
записей (таблицу), а комбинация простых запросов возвращает результат тех или
иных операций над ответами на простые запросы.
В SQL сложные запросы получаются из других
запросов следующими способами:
вложением SQL-выражения запроса в SQL-выражение
другого запроса. Первый из них называют подзапросом, а второй - внешним или
основным запросом;
применением к SQL-запросам операторов
объединения и соединения наборов записей, возвращаемых запросами. Эти операторы
называют теоретико-множественными или реляционными.
Подзапросы
Подзапрос - это запрос на выборку данных,
вложенный в другой запрос. Подзапрос всегда заключается в круглые скобки и
выполняется до содержащего выражения. Внешний запрос, содержащий подзапрос,
если только он сам не является подзапросом, не обязательно должен начинаться с
оператора SELECT. В свою очередь, подзапрос может содержать другой подзапрос и
т. д. При этом сначала выполняется подзапрос, имеющий самый глубокий уровень
вложения, затем содержащий его подзапрос и т. д. Часто, но не всегда, внешний
запрос обращается к одной таблице, а подзапрос - к другой. На практике именно
этот случай наиболее интересен.
Простые подзапросы
Простые подзапросы характеризуются тем, что они
формально никак не связаны с содержащими их внешними запросами. Это
обстоятельство позволяет сначала выполнить подзапрос, результат которого затем
используется для выполнения внешнего запроса. Кроме простых подзапросов,
существуют еще и связанные (коррелированные) подзапросы, которые будут
рассмотрены в следующем разделе.
Рассматривая простые подзапросы, следует
выделить три частных случая:
подзапросы, возвращающие единственное значение;
подзапросы, возвращающие список значений из
одного столбца таблицы;
подзапросы, возвращающие набор записей.
Тип возвращаемой подзапросом таблицы определяет,
как можно ее использовать и какие операторы можно применять в содержащем
выражении для взаимодействия с этой таблицей. По завершении выполнения
содержащего выражения таблицы, возвращенные любым подзапросом, выгружаются из
памяти. Таким образом, подзапрос действует как временная таблица, областью
видимости которой является выражение (т. е. после завершения выполнения
выражения сервер высвобождает всю память, отведенную под результаты
подзапроса).
Подзапросы, возвращающие единственное значение
Допустим, из таблицы Customer требуется выбрать
данные обо всех клиентах из Казани. Это можно
сделать
с
помощью
следующего
запроса.*CustomerIdCity
= (SELECT idCity FROM City WHERE CityName = 'Казань')
В данном запросе сначала выполняется подзапрос
(SELECT idCity FROM City WHERE CityName = 'Казань'). Он возвращает единственное
значение (а не набор записей, поскольку по полю City организовано ограничение
уникальности) - уникальный идентификатор города Казань. Если сказать точнее, то
данный подзапрос возвращает единственную запись, содержащую единственное поле.
Далее выполняется внешний запрос, который выводит все столбцы таблицы Customer
и записи, в которых значение столбца IdCity равно значению, полученному с
помощью подзапроса. Таким образом, сначала выполняется подзапрос, а затем
внешний запрос, использующий результат подзапроса.
Задание для самостоятельной работы: По аналогии
с предыдущим примером сформулируйте запрос, возвращающий все заказы, в которых
содержится заданный товар (по названию товара).
Подзапросы, возвращающие список значений из
одного столбца таблицы
Подзапрос, вообще говоря, может возвращать
несколько записей. Чтобы в этом случае в условии внешнего оператора WHERE можно
было использовать операторы сравнения, требующие единственного значения,
используются кванторы, такие как ALL (все) и SOME (или ANY) (некоторый).
Рассмотрим общий случай использования запросов с
кванторами ALL и SOME. Пусть имеются две таблицы: T1, содержащая как минимум
столбец A, и T2, содержащая, по крайней мере, один столбец B. Тогда запрос с
квантором ALL можно сформулировать следующим образом:
SELECT A FROM T1 WHERE A оператор_сравнения
ALL (SELECT B FROM T2)
Здесь оператор_сравнения обозначает любой
допустимый оператор сравнения. Данный запрос должен вернуть список всех тех
значений столбца A, для которых оператор сравнения истинен для всех значений
столбца B.
Запрос с квантором SOME, очевидно, имеет аналогичную
структуру. Он должен вернуть список всех тех значений столбца A, для которых
оператор сравнения истинен хотя бы для какого-нибудь одного значения столбца B.
Запрос: Список всех клиентов, проживающих в
городах Казань или Елабуга.
SELECT *CustomerIdCity = SOME(SELECT
IdCity FROM City WHERE CityName IN ('Казань',
'Елабуга'))
Предыдущий запрос может быть также реализован и
с использованием оператора IN, который рассматривался в разделе “Фильтрация
данных”.
SELECT *CustomerIdCity IN (SELECT
IdCity FROM City WHERE CityName IN ('Казань',
'Елабуга'))
Напомним - он проверяет вхождение элемента во
множество, в качестве элемента может выступать имя столбца или скалярное
выражение, а в качестве множества - явно заданный список значений или
подзапрос. Использование подзапроса в качестве второго операнда IN также как и
кванторы позволяет избежать ограничения на единственность значения,
возвращаемого подзапросом.
С помощью оператора IN можно проверять не только
наличие значения в наборе значений, но и его отсутствие. Делается это
добавлением оператора отрицания NOT. Вот другой вариант предыдущего запроса:
SELECT *CustomerIdCity NOT IN
(SELECT IdCity FROM City WHERE CityName IN ('Казань',
'Елабуга'))
Этот запрос возвращает всех клиентов, кроме тех
которые проживают в городах Казань и Елабуга.
Аналогичный запрос с использование квантора ALL:
SELECT *CustomerIdCity != ALL(SELECT
IdCity FROM City WHERE CityName IN ('Казань',
'Елабуга'))
Задание для самостоятельной работы:
Cформулируйте запрос, возвращающий список всех клиентов (с указанием фамилии и
имени), совершивших заказ за определенный период времени.
Подзапросы, возвращающие набор записей
Подзапрос можно вставлять не только в операторы
WHERE и HAVING, но и в оператор FROM.
SELECT t.столбец1,
t.столбец2,
... , t.столбецn
FROM (SELECT ... ) t WHERE ...
Здесь таблице, возвращаемой подзапросом в
операторе FROM, присваивается псевдоним t, а внешний запрос выделяет столбцы
этой таблицы и, возможно, записи в соответствии с некоторым условием, которое
указано в операторе WHERE.
Связанные (коррелированные) подзапросы
Все приведенные до сих пор запросы не зависели
от своих содержащих выражений, т. е. могли выполняться самостоятельно и
представлять свои результаты для проверки. Связанный подзапрос
(коррелированный), напротив, зависит от содержащего выражения, из которого он
ссылается на один или более столбцов. В отличие от несвязанного подзапроса,
который выполняется непосредственно перед выполнением содержащего выражения,
связанный подзапрос выполняется по разу для каждой строки-кандидата (это
строки, которые предположительно могут быть включены в окончательные
результаты). Например, следующий запрос использует связанный подзапрос для
подсчета количества заказов у каждого клиента. Затем основной запрос выбирает
тех клиентов, у которых больше одного заказа.
SELECT *Customer c1 < (SELECT
COUNT(*) FROM [Order] r WHERE r.IdCust = c.IdCust)
Ссылка на c.idCust в самом конце подзапроса -
это то, что делает этот подзапрос связанным. Чтобы подзапрос мог выполняться,
основной запрос должен поставлять значения для с.IdCust. В данном случае
основной запрос извлекает из таблицы Customer все строки и выполняет по одному
подзапросу для всех клиентов, передавая в него соответствующий Id клиента при
каждом выполнении. Если подзапрос возвращает значение большее одного, условие
фильтрации выполняется и строка добавляется в результирующий набор.
Связанные подзапросы часто используются с
условиями сравнения (в предыдущем примере <) и вхождения в диапазон, но
самый распространенный оператор, применяемый в условиях со связанными
подзапросами, - это оператор EXISTS (существует). Оператор EXISTS применяется,
если требуется показать, что связь есть, а количество связей при этом не имеет
значения. Например, следующий запрос возвращает список всех товаров, которые
когда-либо заказывали.
SELECT IdProd, [Description]Product
pEXISTS (SELECT * FROM OrdItem oi WHERE oi.IdProd = p.IdProd)
При использовании оператора EXISTS подзапрос
может возвращать ни одной, одну или много строк, а условие просто проверяет,
возвращены ли в результате выполнения подзапроса строки (все равно сколько).
Если взглянуть на блок SELECT подзапроса, можно увидеть, что он состоит из
единственного литерала *. Для условия основного запроса имеет значение только
факт наличия возвращенных строк, а что именно было возвращено подзапросом - не
важно. Поэтому подзапрос может возвращать все, что вам вздумается, но все же
при использовании EXISTS принято задавать SELECT *.
Для поиска подзапросов, не возвращающих строки,
можно использовать оператор EXISTS совместно с оператором отрицания NOT. В
частности чтобы предыдущий запрос возвращал все товары, которые ни разу не
заказывались, его можно модифицировать следующим образом.
SELECT IdProd, [Description]Product
pNOT EXISTS (SELECT * FROM OrdItem oi WHERE oi.IdProd = p.IdProd)
Задание для самостоятельной работы:
Cформулируйте запрос, возвращающий список всех заказов с суммарной стоимость
более заданной величины.
Операции соединения
При проектировании базы данных стремятся
создавать таблицы, в каждой из которых содержалась бы информация об одном и
только одном типе сущности. Это облегчает модификацию базы данных и поддержку
ее целостности. Однако сущности могут быть взаимосвязанными. Клиенты связаны с
городами по признаку проживания, заказы осуществляют клиенты, товары входят в
состав заказов и т. д. Связь между таблицами устанавливается за счет размещения
столбца первичного ключа одной таблицы, которая называется родительской, в
другой взаимосвязанной таблице, которая называется дочерней. Столбец (или
совокупность столбцов) дочерней таблицы, определенный для связи с родительской
таблицей, называется внешним ключом. Так, например, таблица Customer содержит
столбец IdCity, который для каждой строки клиента содержит значение первичного
ключа того города, в котором проживает данный клиент. Наличие внешних ключей
является основой для инициирования поиска по многим таблицам.
Одна из наиболее важных особенностей предложения
SELECT - это способность использования связей между различными таблицами, а
также вывода содержащейся в них информации. Операция, которая приводит к
соединению из двух таблиц всех пар строк, для которых выполняется заданное
условие, называется соединением таблиц.
Соединение таблиц во фразе WHERE по равенству
значений столбцов различных таблиц
Соединение таблиц может быть указано во фразе
WHERE или во фразе FROM. Сначала рассмотрим первый вариант. Большинство
запросов, имеющих несколько таблиц во фразе FROM, содержат фразу WHERE, в
которой указаны условия, попарно сравнивающие столбцы из различных таблиц. Такое
условие называется условием соединения. В этом случае SQL предполагает
сцепление только тех пар строк из разных таблиц, для которых условие соединения
принимает истинное значение. Фраза WHERE помимо условия соединения может также
содержать другие условия, каждое из которых ссылается на столбцы соединенной
таблицы. Эти условия производят отбор строк соединенной таблицы.
Если таблицы соединяются по равенству значений
пары столбцов (группы столбцов) из различных таблиц, такая операция называется
соединением таблиц по равенству. Соединение по равенству позволяет соединить
только те пары строк, которые действительно взаимосвязаны друг с другом. Так,
например, мы можем соединить таблицы городов и клиентов по условию City.IdCity
= Customer.IdCity. В таком варианте мы соединяем таблицы осмысленно, так как
каждая строка таблицы Customer соединяется только с одной строкой
соответствующего города. На базе таблиц City и Customer мы получаем таблицу со
столбцами из обеих таблиц, имеющую строки с понятным смыслом. Можно также
сказать, что в таблицу Customer вместо столбца IdCity мы вставляем все
характеристики (столбцы) соответствующего города из таблицы City. Соединение
таблиц используется, когда необходимо вывести значения столбцов:
разных таблиц;
одной таблицы, но отвечающих условию, заданному
на другой таблице.
Эти два варианта, а также их комбинация,
характерны для любого вида соединения, а не только по равенству. Рассмотрим
следующие
примеры.FName,
LName, CityNameCustomer, CityCustomer.IdCity = City.IdCity
Этот запрос возвращает список всех клиентов с
указанием названий городов, в которых они проживают. Этот вид запросов
характерен тем, что фраза WHERE содержит только условие соединения, а список
фразы SELECT содержит имена столбцов из различных таблиц.
До тех пор, пока запрос относится к одной
таблице, обращение к столбцам по их именам не вызывает проблем - в таблице все
имена столбцов должны быть неповторяющимися. Однако как только запрос соединяет
несколько таблиц, может возникнуть неоднозначность при ссылках на столбцы с
одинаковыми именами из разных таблиц. Для разрешения этой неоднозначности во
фразах SELECT и WHERE (как и в некоторых других фразах) имена столбцов
необходимо уточнять именами таблиц. Запишем предыдущий запрос с полным
уточнением имен.Customer.FName, Customer.LName, City.CityName
FROM Customer, CityCustomer.IdCity =
City.IdCity
В этом запросе мы уточнили имена столбцов во
фразах SELECT и WHERE, хотя в предложение SELECT это было не обязательно, так
как используются неповторяющиеся имена. Тем не менее, рекомендуется при
соединении таблиц для наглядности уточнять имена столбцов. Однако на практике
для задания более лаконичных имен часто используют короткие синонимы таблиц, по
которым можно сослаться на них в любых других местах запроса. Синоним указывается
сразу после имени таблицы в предложении FROM. В частности предыдущий запрос с
использование синонимов для таблиц можно записать более компактным образом.
SELECT k.FName, k.LName,
c.CityNameCustomer k, City ck.IdCity = c.IdCity
Следующий запрос отбирает всех клиентов из
Казани с фамилией Иванов
SELECT K.IdCust, k.FNameCustomer k,
City ck.IdCity = c.IdCity AND k.LName = 'Иванов'
AND c.CityName = 'Казань'
В этом запросе помимо условия соединения
используется также отбор строк по условиям, заданным для разных
таблиц.позволяет формулировать запросы, которые предполагают использование трех
и более таблиц. При этом следует применять ту же методику соединения, что и для
двух таблиц. Рассмотрим простой пример соединения трех таблиц.
Запрос: Список всех клиентов, которые когда-либо
заказывали товар с кодом 1.
SELECT DISTINCT c.IdCust, c.FName,
c.LNameCustomer c, [Order] o, OrdItem oic.IdCust = o.IdCust AND o.IdOrd =
oi.IdOrd AND oi.IdProd = 1
Сформулируем общую процедуру составления
многотабличного запроса.
Определить множество таблиц, необходимых для
ответа на запрос. В это множество должны входить таблицы, на столбцах которых
сформулированы условия, а также те, столбцы которых необходимо вывести. Это так
называемые базовые таблицы запроса.
В структуре взаимосвязанных таблиц найти путь,
соединяющий базовые таблицы. Это так называемый путь вычисления запроса. В
результате вы получите перечень таблиц, необходимых для формулировки запроса.
Это так называемые таблицы запроса.
Во фразе FROM перечислить необходимые таблицы.
Во фразе WHERE соединить таблицы запроса и при
необходимости задать условия отбора строк в базовых таблицах запроса.
Во фразе SELECT перечислить выводимые столбцы.
Задание для самостоятельной работы:
Cформулируйте запрос, возвращающий список товаров в заданном заказе (по
заданному IdOrd). Результат должен включать следующие поля: название товара,
цена, количество, стоимость.
Соединения с использованием фразы FROM
Все рассмотренные выше типы и способы соединения
таблиц можно (и рекомендуется, поскольку соединения во фразе WHERE считаются
устаревшими) осуществлять и с помощью фразы FROM. В ней, в соответствии со
стандартом SQL, можно не только перечислить имена таблиц, участвующих в
запросе, но и указать их соединение, используя следующий синтаксис.
таблица [INNER | {FULL | LEFT | RIGHT} [OUTER]]
JOIN таблица {ON условие}
Внутреннее соединение
В операторе JOIN внутреннее соединение
указывается ключевым словом INNER (впрочем, его можно опустить, так как
соединение двух таблиц является внутренним по умолчанию). Условие соединения
указывается после ключевого слова ON. В этом случае внутреннее соединение с
помощью фразы FROM JOIN очень похоже на соединение с использованием фразы
WHERE. Запишем первый пример с предыдущего раздела с использование оператора JOIN.
Запрос: Список всех клиентов с указанием
названий городов, в которых они проживают
SELECT FName, LName,
CityNameCustomer k JOIN
City c ON k.IdCity = c.IdCity
При соединении с использованием фразы FROM
дополнительное условие можно для увеличения наглядности запроса помещать во
фразу WHERE. В этом случае второй пример с предыдущего раздела примет такой
вид.
Запрос: Список всех клиентов из Казани с
фамилией Иванов
SELECT K.IdCust, k.FNameCustomer k
INNER JOINc ON k.IdCity = c.IdCityk.LName = 'Иванов'
AND c.CityName = 'Казань'
Внешнее соединение
Все соединения таблиц, рассмотренные до сих пор,
являются внутренними. Во всех примерах вместо ключевого слова JOIN можно писать
INNER JOIN (внутреннее соединение). Из таблицы, получаемой при внутреннем
соединении, отбраковываются все записи, для которых нет соответствующих записей
одновременно в обеих соединяемых таблицах. При внешнем соединении такие
несоответствующие записи сохраняются. В этом и заключается отличие внешнего
соединения от внутреннего.
С помощью специальных ключевых слов LEFT OUTER,
RIGHT OUTER и FULL OUTER, написанных перед JOIN, можно выполнить соответственно
левое, правое и полное соединение. В SQL-выражении запроса таблица, указанная
слева от оператора JOIN, называется левой, а указанная справа от него - правой.
При левом внешнем соединении несоответствующие
записи, имеющиеся в левой таблице, сохраняются в результатной таблице, а
имеющиеся в правой - удаляются. Значения столбцов из правой таблицы во всех
строках, не имеющих соответствия с левой таблицей, принимают значение NULL.
При правом внешнем соединении несоответствующие
записи, имеющиеся в правой таблице, сохраняются в результатной таблице, а
имеющиеся в левой - удаляются. Значения столбцов из левой таблицы во всех
строках, не имеющих соответствия с правой таблицей, принимают значение NULL.
Соответственно левое и правое внешние соединения
различаются только порядком следования таблиц.
При полном внешнем соединении двух таблиц
результирующая таблица содержит все строки внутреннего соединения этих таблиц,
а также не включенные им строки и первой, и второй таблиц (дополненные
значениями NULL для отсутствующих столбцов).
В следующем примере возвращается полный список
городов с указанием количества клиентов из каждого из них
SELECT c.CityName, a.CountCityCity c
LEFT OUTER JOIN
(SELECT IdCity, COUNT(*) AS
CountCityCustomerBY IdCity) a ON c.IdCity = a.IdCity
ORDER BY c.CityName
Если в данном запросе заменить левое внешнее
соединение на внутреннее, то из результата будут потеряны города, из которых
нет ни одного клиента (проверьте это заменив LEFT OUTER JOIN на INNER JOIN и
объясните причину разницы). Обратите внимание, что таблица City соединяется не
с таблицей, а с подзапросом, которому задан псевдоним a.
Задание для самостоятельной работы:
Сформулируйте на языке SQL запросы на выборку следующих данных (с использование
оператора JOIN для соединения таблиц):
список всех товаров, которые когда-либо
заказывал заданный клиент;
список всех клиентов, не имеющих ни одного
заказа.
Множественные операции
Множественные операции выполняются над наборами
записей (таблицами), полученными в результате запросов, и, в свою очередь,
возвращают таблицу.
В стандарте SQL множественные операции имеют
следующий синтаксис:
запрос {UNION |
INTERSECT | EXCEPT} [DISTINCT | ALL] запрос
где запрос является предложением SELECT.
Отличаются эти операции тем, какие строки возвращенных запросами таблиц
отбираются в новую результирующую таблицу:- все строки таблиц, возвращенных
обоими запросами;- только те строки, которые имеются в таблицах обоих
запросов;- только те строки таблицы первого запроса, которых нет среди строк
таблицы второго запроса.
Запросы, содержащие множественные операторы,
называются составными.
Стандарт SQL определяет следующие правила
относительно повторяющихся строк в таблицах.
базовые таблицы не могут содержать повторяющихся
строк (это принципиальное требование реляционной модели данных);
результирующие таблицы запросов могут содержать
повторяющиеся строки, если это не запрещено ключевым словом DISTINCT во фразе
SELECT;
результирующие таблицы множественных операций не
могут содержать повторяющихся строк, если это не разрешено ключевым словом ALL.
Таким образом, именно ключевые слова ALL и
DISTINCT указывают, допускаются ли в результирующей таблице повторяющиеся
строки. В запросах при отсутствии явного указания предполагается использование
ключевого слова ALL, а во множественных операциях - DISTINCT.
Таблицы, используемые в качестве операндов
множественной операции, должны быть совместимы. Под этим подразумевается
следующее:
обе таблицы должны иметь одинаковое количество
столбцов;
соответствующие пары столбцов должны быть
одинаковых или совместимых типов.
Объединение наборов записей
Нередко требуется объединить записи двух или
более таблиц с похожими структурами в одну таблицу. Иначе говоря, к набору
записей, возвращаемому одним запросом, требуется добавить записи, возвращаемые
другим запросом. Для этого служит оператор UNION (объединение):
anpoc1 UNION Запрос2;
При этом в результатной таблице остаются только
отличающиеся записи. Чтобы сохранить в ней все записи, после оператора UNION
следует написать ключевое слово ALL.
К базе данных Sales сложно сформулировать
осмысленный запрос с объединением, который бы имел какую-либо практическую
ценность. Поэтому в качестве примера рассмотрим объединение результатов
выполнения запросов, возвращающих просто константные значения.
Запрос: Объединение с исключением дублирующих
строк
SELECT 1, 'Один'1,
'Один'
SELECT 2, 'Два'
Запрос: Объединение с сохранением дубликатов
SELECT 1, 'Один'ALL1,
'Один'
UNION ALL2, 'Два'
Пересечение наборов записей
Пересечение двух наборов записей осуществляется
с помощью оператора INTERSECT (пересечение), возвращающего таблицу, записи в
которой содержатся одновременно в двух наборах:
Запрос 1 INTERSECT Запрос2;
(SELECT 1, 'Один'2,
'Два'3,
'Три')
(SELECT 1, 'Один'2,
'Два'
UNION 4, 'Четыре')
Разность наборов записей
Для получения записей, содержащихся в одном
наборе и отсутствующих в другом, служит оператор EXCEPT(за исключением):
Запрос1 ЕХCЕРТ Запрос2;
(SELECT 1, 'Один'
UNION2, 'Два'3,
'Три')
(SELECT 1, 'Один'2,
'Два'4,
'Четыре')
Лабораторная работа №5. Основы
Transact SQL: Добавление, изменение и удаление данных в таблицах
Запросы, рассмотренные ранее, были направлены на
то, чтобы получить данные, содержащиеся в существующих таблицах базы данных.
Главным ключевым словом таких запросов на выборку данных является SELECT.
Запросы на выборку данных всегда возвращают виртуальную таблицу, которая
отсутствует в базе данных и создается временно лишь для того, чтобы представить
выбранные данные пользователю. При создании и дальнейшем сопровождении базы
данных обычно возникает задача добавления новых и удаления ненужных записей, а
также изменения содержимого ячеек таблицы. В SQL для этого предусмотрены
операторы INSERT (вставить), DELETE (удалить) и UPDATE (изменить). Запросы,
начинающиеся с этих ключевых слов, не возвращают данные в виде виртуальной
таблицы, а изменяют содержимое уже существующих таблиц базы данных. Запросы на
модификацию (добавление, удаление и изменение) данных могут содержать вложенные
запросы на выборку данных из той же самой таблицы или из других таблиц, однако
сами не могут быть вложены в другие запросы. Таким образом, операторы INSERT,
DELETE и UPDATE в SQL-выражении могут находиться только в самом начале.
Добавление новых записей
Для вставки записей в таблицу используется
оператор INSERT, который имеет несколько форм:INTO имяТаблицы VALUES
(списокЗначений)
вставляет запись в указанную таблицу и заполняет
эту запись значениями из списка, указанного за ключевым словом VALUES. При этом
первое в списке значение вводится в первый столбец таблицы, второе значение -
во второй столбец и т. д. Порядок столбцов задается при создании таблицы.
Данная форма оператора INSERT не очень надежна, поскольку нетрудно ошибиться в
порядке вводимых значений. Более надежной и гибкой является следующая
форма.INTO имяТаблицы (списокСтолбцов) VALUES (списокЗначений)
вставляет запись в указанную таблицу и вводит в
заданные столбцы значения из указанного списка. При этом в первый столбец из
списокСтолбцов вводится первое значение из списокЗначений, во второй столбец -
второе значение и т. д. Порядок имен столбцов в списке может отличаться от их
порядка, заданного при создании таблицы. Столбцы, которые не указаны в списке,
заполняются значением NULL. Рекомендуется использовать именно данную форму
оператора INSERT. Следующий запрос добавляет новую запись в справочник
городов.INTO City(CityName)('Калуга')
Обратите внимание, что столбец IdCity не
задается, поскольку он является счетчиком и заполняется СУБД автоматически.
INSERT INTO имяТаблицы
(списокСтолбцов)
SELECT ...
вставляет в указанную таблицу записи,
возвращаемые запросом на выборку. На практике нередко требуется загрузить в
одну таблицу данные из другой таблицы. Например, следующий запрос вставляет в
таблицу City сразу два города, возвращаемых запросом с объединением.
INSERT INTO City(CityName)'Уфа'
UNION'Волгоград'
Удаление записей
Для удаления записей из таблицы применяется
оператор DELETE:
DELETE FROM имяТаблицы
WHERE условие;
Данный оператор удаляет из указанной таблицы
записи (а не отдельные значения столбцов), которые удовлетворяют указанному
условию. Условие - это логическое выражение, различные конструкции которого
были рассмотрены в предыдущих лабораторных занятиях.
Следующий запрос удаляет записи из таблицы
Customer, в которой значение столбца LName равно 'Иванов':
DELETE FROM CustomerLName = 'Иванов'
Если таблица содержатся сведения о нескольких
клиентах с фамилией Иванов, то все они будут удалены.
В операторе WHERE может находиться подзапрос на
выборку данных (оператор SELECT). Подзапросы в операторе DELETE работают точно
так же, как и в операторе SELECT. Следующий запрос удаляет всех клиентов из
города Москва, при этом уникальный идентификатор города возвращается с помощью
подзапроса.
DELETE FROM CustomerIdCity IN
(SELECT IdCity FROM City WHERE CityName = 'Москва')
Transact-SQL расширяет стандартный SQL, позволяя
использовать в инструкции DELETE еще одно предложение FROM. Это расширение, в
котором задается соединение, может быть использовано вместо вложенного запроса
в предложении WHERE для указания удаляемых строк. Оно позволяет задавать данные
из второго FROM и удалять соответствующие строки из таблицы в первом
предложении FROM. В частности предыдущий запрос может быть переписан следующим
образомFROM Customer
FROM Customer k INNER JOINc ON
k.IdCity = c.IdCity AND c.CityName = 'Москва'
Операция удаления записей из таблицы является
опасной в том смысле, что связана с риском необратимых потерь данных в случае
семантических (но не синтаксических) ошибок при формулировке SQL-выражения.
Чтобы избежать неприятностей, перед удалением записей рекомендуется сначала
выполнить соответствующий запрос на выборку, чтобы просмотреть, какие записи
будут удалены. Так, например, перед выполнением рассмотренного ранее запроса на
удаление не помешает выполнить соответствующий запрос на выборку.
SELECT *Customer k INNER JOINc ON
k.IdCity = c.IdCity AND c.CityName = 'Москва'
Для удаления всех записей из таблицы достаточно
использовать оператор DELETE без ключевого слова WHERE. При этом сама таблица
со всеми определенными в ней столбцами сохраняется и готова для вставки новых
записей. Например, следующий запрос удаляет записи обо всех товарах.FROM
Product
Задание для самостоятельной работы: Сформулируйте
на языке SQL запрос на удаление всех заказов, не имеющих в составе ни одного
товара (т. е. все пустые заказы).
Изменение данных
Для изменения значений столбцов таблицы
применяется оператор UPDATE (изменить, обновить). Чтобы изменить значения в
одном столбце таблицы в тех записях, которые удовлетворяют некоторому условию,
следует выполнить такой запрос.имяТаблицы SET имяСтолбца = значение WHERE
условие;
За ключевым словом SET (установить) следует
выражение равенства, в левой части которого указывается имя столбца, а в правой
- выражение, значение которого следует сделать значением данного столбца. Эти
установки будут выполнены в тех записях, которые удовлетворяют условию в
операторе WHERE.
Чтобы одним оператором UPDATE установить новые
значения сразу для нескольких столбцов, вслед за ключевым словом SET
записываются соответствующие выражения равенства, разделенные
запятыми.имяТаблицы SET имяСтолбца1 = значение1, имяСтолбца2 = значение2, ... ,
имяСтолбцаN = значениеN WHERE условие;
Например, следующий запрос изменяет фамилию и
имя клиента с кодом 5.
UPDATE CustomerFName='Иван',
LName='Иванов'
WHERE IdCust = 5
Использование оператора WHERE в инструкции
UPDATE не обязательно. Если он отсутствует, то указанные в SET изменения будут
произведены для всех записей таблицы.
Так же как и в инструкции DELETE условие в
операторе WHERE инструкции UPDATE может содержать подзапросы, в том числе и
связанные.SQL расширяет стандартный SQL, позволяя использовать в инструкции
UPDATE предложение FROM (по аналогии с DELETE). Это расширение, в котором
задается соединение, может быть использовано вместо вложенного запроса в
предложении WHERE для указания обновляемых строк.
Если обновляемый объект тот же самый, что и
объект в предложении FROM, и в предложении FROM имеется только одна ссылка на
этот объект, псевдоним объекта указывать необязательно. Если обновляемый объект
встречается в предложении FROM несколько раз, одна и только одна ссылка на этот
объект не должна указывать псевдоним таблицы. Все остальные ссылки на объект в
предложении FROM должны включать псевдоним объекта.
Предположим, что требуется сделать 5% скидку по
тем заказам клиентов, суммарная стоимость которых превышает 1000. Для этого
следует изменить значения столбца Price, просто умножить их на 0,95. Однако эти
изменения должны быть выполнены, только если суммарная стоимость заказа
превышает 1000. Таким образом, в качестве критерия обновления записей в таблице
OrdItem может быть задан запрос возвращающий список всех заказов с суммарной
стоимостью более 1000.
UPDATE OrdItemPrice = Price *
0.95OrdItem o INNER JOIN
(SELECT IdOrd
FROM OrdItem
GROUP BY IdOrd
HAVING SUM(Qty*Price) > 1000) a
ON o.IdOrd = a.IdOrd
Операция изменения записей, как и их удаление,
связана с риском необратимых потерь данных в случае семантических ошибок при
формулировке SQL-выражения. Например, стоит только забыть написать оператор
WHERE, и будут обновлены значения во всех записях таблицы. Чтобы избежать
подобных неприятностей, перед обновлением записей рекомендуется выполнить
соответствующий запрос на выборку, чтобы просмотреть, какие записи будут
изменены. Например, перед выполнением приведенного ранее запроса на обновление
данных не помешает выполнить соответствующий запрос на выборку данных.
SELECT *OrdItem o INNER JOIN
(SELECT IdOrdOrdItemBY IdOrdSUM(Qty*Price)
> 1000) a ON o.IdOrd = a.IdOrd
Задание для самостоятельной работы:
Сформулируйте на языке SQL запрос имитирующий поступление на склад новой партий
определенного товара (Обновление столбца InStock в таблице Product).
Лабораторная работа №6.
Представления
Представления - это именованные запросы на
выборку данных (инструкции SELECT на языке T-SQL), хранящиеся в базе данных. В
запросах представления можно использовать, так же как и таблицы, независимо от
сложности их инструкций SELECT. Подобно таблицам представления также состоят из
полей и записей. Однако в отличие от таблиц они не содержат каких-либо данных
(за исключением материализованных (индексированных) представлений).
Представления всегда основываются на таблицах и используются для получения
данных, хранящихся в этих таблицах, в определенных разрезах. Представления
позволяют достичь более высокой защищенности данных, а также предоставляют
проектировщику средства настройки пользовательской модели.
Механизм представлений может использоваться по
нескольким причинам.
Он предоставляет мощный и гибкий механизм
защиты, позволяющий скрыть некоторые части базы данных от определенных
пользователей. Пользователь не будет иметь сведений о существовании каких-либо
атрибутов или кортежей, отсутствующих в доступных ему представлениях.
(Горизонтальное и вертикальное разбиение таблиц).
Он позволяет организовать доступ пользователей к
данным наиболее удобным для них образом, поэтому одни и те же данные в одно и
то же время могут рассматриваться разными пользователями совершенно различными
способами. (В частности переименование атрибутов).
Он позволяет упрощать сложные операции с
базовыми отношениями. Например, если представление будет определено на основе
соединения двух отношений, то пользователь сможет выполнять над ним простые
унарные операции выборки и проекции, которые будут автоматически преобразованы
средствами СУБД в эквивалентные операции с выполнением соединения базовых
отношений. Одной из важнейших причин использования представлений является стремление
к упрощению многотабличных запросов. После определения представления с
соединением нескольких таблиц можно будет использовать простейшие однотабличные
запросы к этому представлению вместо сложных запросов с выполнением того же
самого многотабличного соединения.
Все эти примеры демонстрируют определенную
степень логической независимости от данных, достигаемую за счет использования
представлений. Однако на самом деле представления позволяют добиться и более
важного типа логической независимости от данных, связанной с защитой
пользователей от реорганизаций концептуальной схемы. Например, если в отношение
будет добавлен новый атрибут, то пользователи не будут даже подозревать о его
существовании, пока определения их представлений не включают этот атрибут. Если
существующее отношение реорганизовано или разбито на части, то использующее его
представление может быть переопределено так, чтобы пользователи могли
продолжать работать с данными в прежнем формате.
Создание представлений в Management Studio
В утилите SQL Server Management Studio
представления можно создавать, редактировать, выполнять и вставлять в другие
запросы.
Поскольку представление является ничем иным, как
сохраненной инструкцией SELECT, его создание начинается с проектирования этой
инструкции. Инструкция SELECT, если она является корректной, может быть
вырезана и вставлена в представление практически из любого инструмента.
В утилите Management Studio представления
перечислены в собственном узле в каждой базе данных.
Команда «Создать представление» в контекстном
меню позволит запустить конструктор запросов в режиме создания представлений.
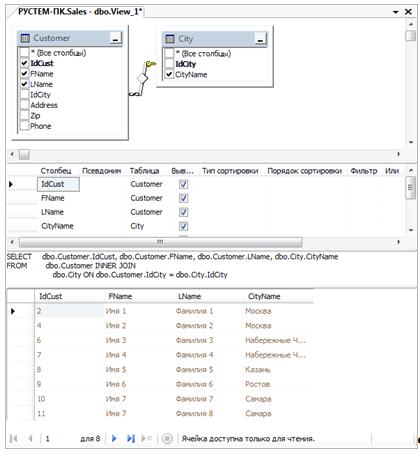
Рис. 6.1
Конструктор запросов утилиты Management Studio
способен одновременно отображать множество панелей, выбранных на панели
инструментов  .
.
Панель диаграммы (Область схемы). В запросе
может участвовать множество таблиц и представлений. Для связывания их
отношениями с целью формирования предложения FROM инструкции SELECT можно
использовать это графическое представление.
Панель сетки (Область условий). На этой панели
перечисляются отображаемые, фильтруемые и сортируемые столбцы.
Панель SQL. На этой панели можно в текстовом
виде увидеть и отредактировать формируемую инструкцию SELECT.
Панель результатов. Когда запрос выполняется с
помощью действия «Выполнить код SQL»  ,
на этой панели отображаются его результаты. Если результаты запроса остаются
нетронутыми долгое время, Management Studio запрашивает у пользователя
разрешение закрыть подключение к серверу.
,
на этой панели отображаются его результаты. Если результаты запроса остаются
нетронутыми долгое время, Management Studio запрашивает у пользователя
разрешение закрыть подключение к серверу.
Фактический код SQL отображается и редактируется
в панели SQL кода. Столбцы в представление можно добавлять в панелях диаграммы,
сетки и SQL кода. Функция добавления таблиц доступна в контекстном меню, а
также на панели инструментов. Здесь можно добавлять таблицы, другие
представления, синонимы и табличные функции.
Таблицы и другие представления могут быть
добавлены посредством перетаскивания их на панель диаграммы из окна
«Обозреватель объектов» или с помощью команды «Добавить таблицу»  на
панели инструментов или в контекстном меню.
на
панели инструментов или в контекстном меню.
Функция добавления производных таблиц  способна
добавить в предложение FROM представления в качестве источника данных
подзапрос. Код SQL этого подзапроса можно ввести вручную на панели SQL.
способна
добавить в предложение FROM представления в качестве источника данных
подзапрос. Код SQL этого подзапроса можно ввести вручную на панели SQL.
Кнопка «Проверить синтаксис SQL»  позволяет
проверить синтаксис введенных инструкций SQL. В то же время она не проверяет
имена таблиц, столбцов и представлений в инструкции SELECT.
позволяет
проверить синтаксис введенных инструкций SQL. В то же время она не проверяет
имена таблиц, столбцов и представлений в инструкции SELECT.
Кнопка «Сохранить»  панели
инструментов запускает сценарий фактического создания представления в базе
данных. Следует отметить, что для сохранения инструкция SELECT должна быть
свободна от ошибок.
панели
инструментов запускает сценарий фактического создания представления в базе
данных. Следует отметить, что для сохранения инструкция SELECT должна быть
свободна от ошибок.
После создания представления его можно
редактировать в Management Studio, выделяя название и выбирая в контекстном
меню команду «Проект».
Для тестирования инструкции SELECT представления
в конструкторе запросов щелкните на кнопке «Выполнить код SQL» или
нажмите клавишу <F5>.
Контекстное меню представления также содержит
команды управления его полнотекстовой индексацией и его переименования.
Свойства приложения содержат расширенные параметры и разрешения системы
безопасности. Для удаления представления из базы данных достаточно выделить
его, выбрать в контекстном меню команду «Удалить» или нажать одноименную
клавишу.
Создание представлений с помощью кода SQL
Представлениями можно управлять в редакторе
запросов, выполняя сценарии SQL, которые используют команды языка DDL: CREATE,
ALTER и DROP. Основной синтаксис создания представления следующий:VIEW
имя_представления AS инструкция_SELECT
Например, чтобы создать представление
v_Customer, возвращающее список клиентов с указанием города проживания,
программным путем, в окне запросов должна быть выполнена следующая команда.
CREATE VIEW
[dbo].[v_Customer]dbo.Customer.IdCust, dbo.Customer.FName, dbo.Customer.LName,
dbo.City.CityNamedbo.Customer INNER JOIN.City ON dbo.Customer.IdCity =
dbo.City.IdCity
Попытка создать представление, которое уже
существует, вызовет ошибку. Когда представление создано, инструкцию SELECT
можно с легкостью отредактировать с помощью команды ALTER:имя_представления AS
измененная_инструкция_SELECT
Если изменение представления предполагает и
изменение прав доступа на него, предпочтительнее удалить его и создать заново,
поскольку удаление представления также приводит и к удалению разрешений
доступа, установленных ранее.
Чтобы удалить представление из базы данных,
используйте команду DROP:VIEW имя_представления
Предложение ORDER BY и представления
Представления служат источником данных для
других запросов и не поддерживают сортировку внутри себя. Например, следующий
код извлекает данные из представления v_Customer и упорядочивает их по полям
LName и FName. Предложение ORDER BY не является частью представления
v_Customer, а применяется к нему с помощью вызова инструкции SQL:
SELECT IdCust, FName, LName,
CityNamedbo.v_Customer
ORDER BY LName, FName
Выполнение представлений
Представление не может быть выполнено само по
себе. Инструкция SELECT, на основе которой создано представление, может быть
выполнена, однако в этой форме, с технической стороны, инструкция SQL не
является представлением. Представление может быть полезно только как источник
данных в запросе.
Именно поэтому контекстное меню «Открыть
представление» утилиты Management Studio автоматически генерирует простой
запрос, извлекая из представления все столбцы. Представление отображает только
результаты. Однако включение других панелей конструктора запросов позволяет
увидеть и сам запрос, извлеченный из представления.
Панель SQL отобразит представление в предложении
FROM инструкции SELECT. Именно в такой форме на представление ссылаются
пользователи:* FROM v_Customer
Задание для самостоятельной работы: Создайте
представление возвращающее список заказов с указанием имени клиента и
количества товаров в каждом заказе. Таким образом, результат должен включать
следующие атрибуты: IdOrd, OrdDate, IdCust, FName, LName, Количество видов
товаров в заказе.
Лабораторная работа №7.
Программирование на T-SQL
Синтаксис и соглашения T-SQL
Правила формирования идентификаторов
Все объекты в SQL Server имеют имена
(идентификаторы). Примерами объектов являются таблицы, представления, хранимые
процедуры и т.д. Идентификаторы могут включать до 128 символов, в частности,
буквы, символы _ @ $ # и цифры. Первый символ всегда должен быть буквенным. Для
переменных и временных таблиц используются специальные схемы именования. Имя
объекта не может содержать пробелов и совпадать с зарезервированным ключевым
словом SQL Server, независимо от используемого регистра символов. Путем
заключения идентификаторов в квадратные скобки, в именах объектов можно
использовать запрещенные символы.
Завершение инструкции
Стандарт ANSI SQL требует помещения в конце
каждой инструкции точки с запятой. В то же время при программировании на языке
T-SQL точка с запятой не обязательна.
Комментарии
Язык T-SQL допускает использование комментариев
двух стилей: ANCI и языка С. Первый из них начинается с двух дефисов и
заканчивается в конце строки:
Также комментарии стиля ANSI могут вставляться в
конце строки инструкции:CityName - извлекаемые столбцыCity - исходная таблицаIdCity
= 1; -- ограничение на строки
Редактор SQL может применять и удалять
комментарии во всех выделенных строках. Для этого нужно выбрать соответствующие
команды в меню Правка или на панели инструментов  .
.
Комментарии стиля языка С начинаются с косой
черты и звездочки (/*) и заканчиваются теми же символами в обратной
последовательности. Этот тип комментариев лучше использовать для
комментирования блоков строк, таких как заголовки или большие тестовые запросы.
/*
Пример
многострочного
комментария
*/
Одним из главных достоинств комментариев стиля С
является то, что многострочные запросы в них можно выполнять, даже не
раскомментируя.
Пакеты T-SQL
Запросом называют одну инструкцию T-SQL, а
пакетом - их набор. Вся последовательность инструкций пакета отправляется
серверу из клиентских приложений как одна цельная единица.Server рассматривает
весь пакет как рабочую единицу. Наличие ошибки хотя бы в одной инструкции
приведет к невозможности выполнения всего пакета. В то же время грамматический
разбор не проверяет имена объектов и схем, так как сама схема может измениться
в процессе выполнения инструкции.
Файл сценария SQL и окно анализатора запросов
(Query Analyzer) может содержать несколько пакетов. В данном случае все пакеты разделяют
ключевые слова терминаторов. По умолчанию этим ключевым словом является GO, и
оно должно быть единственным в строке. Все другие символы (даже комментарии)
нейтрализуют разделитель пакета.
Отладка T-SQL
Когда редактор SQL обнаруживает ошибку, он отображает
ее характер и номер строки в пакете. Дважды щелкнув на ошибке, можно сразу же
переместиться к соответствующей строке.
В утилиту Management Studio версии SQL Server
2005 не включен отладчик языка T-SQL, - он присутствует в пакете Visual
Studio.Server предлагает несколько команд, облегчающих отладку пакетов. В
частности, команда PRINT отправляет сообщение без генерации результирующего
набора данных. Команду PRINT можно использовать для отслеживания хода
выполнения пакета. Когда анализатор запросов находится в режиме сетки,
выполните следующий пакет:
SELECT CityNameCityIdCity = 1;
PRINT 'Контрольная точка';
Результирующий набор данных отобразится в сетке
и будет состоять из одной строки. В то же время во вкладке «Сообщения»
отобразится следующий результат:
(строк обработано: 1)
Контрольная точка
Переменные
Переменные T-SQL создаются с помощью команды
DECLARE, имеющей следующий синтаксис:@Имя_Переменной Тип_Данных [,
@Имя_Переменной Тип_Данных, …]
Все имена локальных переменных должны начинаться
символом @. Например, для объявления локальной переменной UStr, которая хранит
до 16 символов Unicode, можно использовать следующую инструкцию:@UStr
varchar(16)
Используемые для переменных типы данных в
точности совпадают с существующими в таблицах. В одной команде DECLARE через
запятую может быть перечислено несколько переменных. В частности в следующем
примере создаются две целочисленные переменные a и b:
@a int,
@b int
Область определения переменных (т.е. срок их
жизни) распространяется только на текущий пакет. По умолчанию только что
созданные переменные содержат пустые значения NULL и до включения в выражения
должны быть инициализированы.
Задание значений переменных
В настоящее время в языке SQL предусмотрены два
способа задания значения переменной - для этой цели можно использовать оператор
SELECT или SET. С точки зрения выполняемых функций эти операторы действуют
почти одинаково, не считая того, что оператор SELECT позволяет получить
исходное присваиваемое значение из таблицы, указанной в операторе SELECT.
Оператор SET обычно используется для задания
значений переменных в такой форме, какая более часто встречается в процедурных
языках. В качестве типичных примеров применения этого оператора можно указать
следующие:@a = 1;@b = @a * 1.5
Обратите внимание на то, что во всех этих
операторах непосредственно осуществляются операции присваивания, в которых
используются либо явно заданные значения, либо другие переменные. С помощью
оператора SET невозможно присвоить переменной значение, полученное с помощью
запроса; запрос должен быть выполнен отдельно и только после этого полученный
результат может быть присвоен с помощью оператора SET. Например, попытка
выполнения такого оператора вызывает ошибку:@c int@c = COUNT(*) FROM City@c
а следующий оператор выполняется вполне успешно:
DECLARE @c int@c = (SELECT COUNT(*)
FROM City)
SELECT @c
Оператор SELECT обычно используется для
присваивания значений переменным, если источником информации, которая должна
быть сохранена в переменной, является запрос. Например, действия, осуществляемые
в приведенном выше коде, гораздо чаще реализуются с помощью оператора SELECT:
DECLARE @c int@c = COUNT(*) FROM
City
SELECT @c
Обратите внимание на то, что данный код немного
понятнее (в частности, он более лаконичен, хотя и выполняет те же действия).
Таким образом, можно, сформулировать следующее
общепринятое соглашение по использованию того и другого оператора.
Оператор SET используется, если должна быть
выполнена простая операция присваивания значения переменной, т.е. если
присваиваемое значение уже задано явно в форме определенного значения или в
виде какой-то другой переменной.
Оператор SELECT применяется, если присваивание
значения переменной должно быть основано на запросе.
Использование переменных в запросах SQL
Одним из полезных свойств языка T-SQL является
то, что переменные могут использоваться в запросах без необходимости создания
сложных динамических строк, встраивающих переменные в программный код.
Динамический SQL продолжает свое существование, но одиночное значение можно
изменить проще - с помощью переменной.
Везде, где в запросе может использоваться
выражение, может использоваться и переменная. В следующем примере
продемонстрировано использование переменной в предложении WHERE:@IdProd int;
SET @IdProd = 1;[Description]Product
WHERE IdProd = @IdProd;
Глобальные системные переменные
В SQL Server имеется более тридцати глобальных
переменных, не имеющих параметров, которые определяются и поддерживаются
системой. Все глобальные переменные имеют префикс в виде двух символов @. Вы
можете извлечь значение любой из них с помощью простого запроса SELECT, как в
следующем примере:@@CONNECTIONS
Здесь используется глобальная переменная
@@CONNECTIONS для извлечения количества подключений к SQL Server со времени
запуска программы.
Среди наиболее часто применяемых системных
переменных можно отметить следующие:
@@ERROR - Содержит номер ошибки, возникшей при
выполнении последнего оператора T-SQL в текущем соединении. Если ошибка не
обнаружена, содержит 0. Значение этой системной переменной переустанавливается
после выполнения каждого очередного оператора. Если требуется сохранить
содержащееся в ней значение, то это значение следует переносить в локальную
переменную сразу же после выполнения оператора, для которого должен быть
сохранен код ошибки.
@@IDENTITY - Содержит последнее
идентификационное значение, вставленное в базу данных в результате выполнения
последнего оператора INSERT. Если в последнем операторе INSERT не произошла
выработка идентификационного значения, системная переменная @@IDENTITY содержит
NULL. Это утверждение остается справедливым, даже если отсутствие
идентификационного значения было вызвано аварийным завершением при выполнении
оператора. А если с помощью одного оператора осуществляется несколько операций
вставки, этой системной переменной присваивается только последнее
идентификационное значение.
@@ROWCOUNT - Одна из наиболее широко
используемых системных переменных. Возвращает информацию о количестве строк,
затронутых последним оператором. Обычно применяется для контроля ошибок, отличных
от тех, которые относятся к категории ошибок этапа прогона программы. Например,
если в программе обнаруживается, что после вызова на выполнение оператора
DELETE с конструкцией WHERE количество затронутых строк равно нулю, то можно
сделать вывод, что произошло нечто непредвиденное. После этого сообщение об
ошибке может быть активизировано вручную.
! Следует отметить, что с версии SQL Server 2000
глобальные переменные принято называть функциями. Название глобальные сбивало
пользователей с толку, позволяя думать, что область действия таких переменных
шире, чем у локальных. Глобальным переменным часто ошибочно приписывалась
возможность хранить информацию, независимо от того, включена она в пакет либо
нет, что, естественно, не соответствовало действительности.
Средства управления потоком команд. Программные
конструкции
В языке T-SQL предусмотрена большая часть
классических процедурных средств управления ходом выполнения программы, в т.ч.
условная конструкция и циклы.
Оператор IF. . .ELSE
Операторы IF. . .ELSE действуют в языке T-SQL в
основном так же, как и в любых других языках программирования. Общий синтаксис
этого оператора имеет следующий вид:Логическое выражение SQL инструкция I BEGIN
Блок SQL инструкций END [ELSE SQL инструкция | BEGIN Блок SQL инструкций END]
В качестве логического выражения может быть
задано практически любое выражение, результат вычисления которого приводит к
возврату булева значения.
Следует учитывать, что выполняемым по условию
считается только тот оператор, который непосредственно следует за оператором IF
(ближайшим к нему). Вместо одного оператора можно предусмотреть выполнение по
условию нескольких операторов, объединив их в блок кода с помощью конструкции
BEGIN…END.
В приведенном ниже примере условие IF не
выполняется, что предотвращает выполнение следующего за ним оператора.1 =
0'Первая строка''Вторая строка'
Необязательная команда ELSE позволяет задать
инструкцию, которая будет выполнена в случае, если условие IF не будет
выполнено. Подобно IF, оператор ELSE управляет только непосредственно следующей
за ним командой или блоком кода заключенным между BEGIN…END.
Несмотря на то, что оператор IF выглядит
ограниченным, его предложение условия может включать в себя мощные функции,
подобно предложению WHERE. В частности это выражения IF EXISTS().
Выражение IF EXISTS() использует в качестве
условия наличие какой-либо строки, возвращенной инструкцией SELECT. Так как
ищутся любые строки, список столбцов в инструкции SELECT можно заменить
звездочкой. Этот метод работает быстрее, чем проверка условия @@ROWCOUNT>0,
потому что не требуется подсчет общего количества строк. Как только хотя бы
одна строка удовлетворяет условию IF EXISTS(), запрос может продолжать
выполнение.
В следующем примере выражение IF EXISTS
используется для проверки наличия у клиента с кодом 1 каких-либо заказов перед
удалением его из базы. Если по данному клиенту есть информация хотя бы по
одному заказу, удаление не производится.
IF EXISTS(SELECT * FROM [Order]
WHERE IdCust = 1)
PRINT 'Невозможно удалить клиента поскольку в
базе имеются связанные с ним записи'
ELSECustomerIdCust = 1
PRINT 'Удаление произведено успешно'
Операторы WHILE, BREAK и CONTINUE
Оператор WHILE в языке SQL действует во многом
так же, как и в других языках, с которыми обычно приходится работать программисту.
По сути, в этом операторе до начала каждого прохода по циклу проверяется
некоторое условие. Если перед очередным проходом по циклу проверка условия
приводит к получению значения TRUE, осуществляется проход по циклу, в противном
случае выполнение оператора завершается.
Оператор WHILE имеет следующий
синтаксис:Логическое выражение SQL инструкция I [BEGIN [BREAK] Блок SQL
инструкций [CONTINUE] END]
Безусловно, с помощью оператора WHILE можно
обеспечить выполнение в цикле только одного оператора (по аналогии с тем, как
обычно используется оператор IF), но на практике конструкции WHILE, за которыми
не следует блок BEGIN. . .END, соответствующий полному формату оператора,
встречаются редко.
Оператор BREAK позволяет немедленно выйти из
цикла, не ожидая того, как будет выполнен проход до конца цикла и произойдет
повторная проверка условного выражения.
Оператор CONTINUE позволяет прервать отдельную
итерацию цикла. Кратко можно описать действие оператора CONTINUE так, что он
обеспечивает переход в начало цикла WHILE. Сразу после обнаружения оператора
CONTINUE в цикле, независимо от того, где он находится, происходит переход в
начало цикла и повторное вычисление условного выражения (а если значение этого
выражения больше не равно TRUE, осуществляется выход из цикла).
Следующий короткий сценарий демонстрирует
использование оператора WHILE для создания цикла:
DECLARE @Temp int;@Temp = 0;@Temp
< 3@Temp;
SET @Temp = @Temp + 1;
Здесь в цикле целочисленная переменная @Temp
увеличивается с 0 до 3 и на каждой итерации ее значение выводится на экран.
Оператор RETURN
Оператор RETURN используется для останова
выполнения пакета, а следовательно, хранимой процедуры и триггера
(рассматриваются в следующих лабораторных занятиях).
Лабораторная работа №8. Хранимые
процедуры
Хранимая процедура - это наиболее часто
используемая в базах данных программная структура, представляющая собой
оформленный особым образом сценарий (вернее, пакет), который хранится в базе
данных, а не в отдельном файле. Хранимые процедуры отличаются от сценариев тем,
что в них допускается использование входных и выходных параметров, а также
возвращаемых значений, которые фактически не могут использоваться в обычном
сценарии.
Хранимая процедура представляет собой просто
имя, связанное с программным кодом T-SQL, который хранится и исполняется на
сервере. Она может содержать практически любые конструкции или команды,
исполнение которых поддерживается в SQL Server. Процедуры можно использовать
для изменения данных, возврата скалярных значений или целых результирующих
наборов. Хранимые процедуры, являются основным интерфейсом, который должен
использоваться приложениями для обращения к любым данным в базах данных.
Хранимые процедуры позволяют не только управлять доступом к базе данных, но
также изолировать код базы данных для упрощения обслуживания.
Как серверные программы хранимые процедуры имеют
ряд преимуществ.
Хранимые процедуры хранятся в компилированном
виде, поэтому выполняются быстрее, чем пакеты или запросы.
Выполнение обработки данных на сервере, а не на
рабочей станции, значительно снижает нагрузку на локальную сеть.
Хранимые процедуры имеют модульный вид, поэтому
их легко внедрять и изменять. Если клиентское приложение вызывает хранимую
процедуру для выполнения некоторой операции, то модификация процедуры в одном
месте влияет на ее выполнение у всех пользователей.
Хранимые процедуры можно рассматривать как
важный компонент системы безопасности базы данных. Если все клиенты
осуществляют доступ к данным с помощью хранимых процедур, то прямой доступ к
таблицам может быть запрещен, и все действия пользователей будут находиться под
контролем. Что еще важнее, хранимые процедуры скрывают от пользователя
структуру базы данных и разрешают ему выполнение только тех операций, которые
запрограммированы в хранимой процедуре.
Управление хранимыми процедурами
Хранимые процедуры управляются посредством
инструкций языка определения данных (DDL) CREATE, ALTER и DROP.
Общий синтаксис T-SQL кода для создания хранимой
процедуры имеет следующий вид:
CREATE PROC | PROCEDURE <procedure_name>
[ <@parameter> <data_type> [ = <default> ] [ OUT | OUTPUT ] ]
[ ,...n ] AS [ BEGIN ] <sql_statements> [ END ]
<procedure_option> ::= [
ENCRYPTION ] [ RECOMPILE ] [ EXECUTE_AS_Clause ]
Структура этого оператора соответствует
основному синтаксису CREATE <Object Туре> <Object Name>, лежащему в
основе любого оператора CREATE. Единственная отличительная особенность состоит
в том, что в нем допускается использовать ключевое слово PROCEDURE или PROC.
Оба эти варианта являются допустимыми: PROC является лишь сокращением от
PROCEDURE.
Каждая процедура должна иметь уникальное в
рамках базы данных имя (procedure_name), соответствующее правилам для
идентификаторов объектов.
Процедуры могут иметь любое число входных
параметров (@parametr) заданного типа данных (data_type), которые используются
внутри процедуры как локальные переменные. При выполнении процедуры для каждого
из объявленных формальных параметров должны быть переданы фактические значения.
Или же для входного параметра может быть определено значение по умолчанию
(default), которое должно быть константой или равняться NULL. В этом случае
процедуру можно выполнить без указания значения соответствующего аргумента.
Применение входных параметров необязательно.
Можно также указать выходные параметры
(помеченные как OUTPUT), позволяющие хранимой процедуре вернуть одно или
несколько скалярных значений в подпрограмму, из которой она была вызвана. При
создании процедур можно задать три параметра. При создании процедуры с
параметром ENCRYPTION SQL Server шифрует определение процедуры. При задании
параметра RECOMPILE SQL Server перекомпилирует хранимую процедуру при каждом ее
запуске. Параметр EXECUTE AS определяет контекст безопасности для процедуры.
В конце определения хранимой процедуры вслед за
ключевым словом AS должно быть приведено непосредственно тело процедуры
(sql_statements) в виде кода из одной или нескольких инструкций языка T-SQL.
Инструкция DROP удаляет хранимую процедуру из
базы данных. Инструкция ALTER изменяет содержимое всей хранимой процедуры. Для
внесения изменений предпочтительнее использовать инструкцию ALTER, а не
комбинацию инструкций удаления и создания, так как последний метод удаляет все
разрешения.
Пример хранимой процедуры без параметров
Самая простая хранимая процедура возвращает
результаты, не требуя никаких параметров. В этом плане она похожа на обычный
запрос. В следующем примере создается простая хранимая процедура, которая
извлекает информацию обо всех заказах, начиная с 01.01.2010.
CREATE PROCEDURE spr_getOrders
IdOrd, IdCust, OrdDate[Order](OrdDate >= '01.01.2010')
RETURN
Чтобы протестировать новую процедуру, откройте
новый запрос SQL Server и выполните следующий код.spr_getOrders
Команда EXECUTE или сокращенно EXEC выполняет
указанную хранимую процедуру.
В данном случае хранимая процедура вернет все
строки из таблицы Order, в которых значение поля OrdDate больше 1 января 2010
года, в соответствии с содержащимся в нем запросом на выборку.
Применение входных параметров
Хранимая процедура предоставляет определенные
процедурные возможности (а если она применяется в инфраструктуре .NET, такие
возможности становятся весьма значительными), а также обеспечивает повышение
производительности, но в большинстве обстоятельств хранимая процедура не
позволяет добиться многого, если не предусмотрена возможность передать ей
некоторые данные, указывающие на то, какие действия должны быть выполнены с ее
помощью. В частности основная проблема, связанная с предыдущей хранимой
процедурой (spr_getOrders), состоит в ее статичности. Если пользователям
потребуется информация о заказах за другой период времени, то эта процедура им
не поможет. Поэтому необходимо предусмотреть возможность передачи в нее
соответствующих входных параметров, которые позволили бы динамически изменять
период выборки.
Параметры, передаваемые хранимой процедуре,
перечисляются через запятую в инструкции CREATE (ALTER) PROCEDURE
непосредственно после ее имени. При объявлении входного параметра необходимо
указать имя параметра, тип данных и возможно значение по умолчанию. В общем
случае объявление входного параметра имеет следующий вид:
@parameter_name [AS] datatype [= default|NULL]
Правила определения входных параметров во многом
аналогичны объявлению локальных переменных. Каждый из параметров должен
начинаться с символа @. Для хранимой процедуры он является локальной
переменной. Как и все локальные переменные, параметры должны объявляться с
допустимыми встроенными или определяемыми пользователями типами данных СУБД SQL
Server.
Значительные различия между объявлениями
параметров хранимых процедур и объявлениями переменных начинают впервые
обнаруживаться, когда дело касается значений, заданных по умолчанию. Прежде
всего, при инициализации переменным всегда присваиваются NULL-значения, а на
параметры это правило не распространяется. В действительности, если в
объявлении параметра не предусмотрено заданное по умолчанию значение, то
подразумевается, что этот параметр должен быть обязательным и что при вызове
хранимой процедуры должно быть указано его начальное значение. Чтобы задать
предусмотренное по умолчанию значение, необходимо добавить знак равенства (=)
после обозначения типа данных, а затем указать применяемое по умолчанию
значение. Благодаря этому пользователи получают возможность при вызове хранимой
процедуры принимать решение о том, следует ли задать другое значение параметра
или воспользоваться значением, предусмотренным по умолчанию.
В следующем примере хранимая процедура
spr_getOrders дополняется двумя входными параметрами, позволяющими явно указать
период выборки.
ALTER PROCEDURE [dbo].[spr_getOrders]
@dateBegin datetime,
@dateEnd datetimeIdOrd, IdCust,
OrdDate[Order](OrdDate BETWEEN @dateBegin AND @dateEnd)
RETURN
При вызове хранимой процедуры фактические
значения параметров могут быть заданы либо с учетом позиции, либо по имени, а в
самой вызываемой хранимой процедуре способ, применяемый для передачи
параметров, не играет особой роли, поскольку для всех параметров, независимо от
способа их передачи в процедуру, используется одинаковый формат объявления.
Если хранимой процедуре передается множество параметров с учетом их позиции в
объявлении, то они должны сохранять порядок, указанный в определении. Можно
также передавать параметры в любом порядке, но при этом указывать их имена.
Если эти два метода смешиваются, то после первого явного указания имени
параметра все остальные должны использовать тот же метод.
В следующих трех примерах продемонстрированы
вызовы хранимых процедур и передача им параметров с использованием исходного
порядка и имен:
EXEC spr_getOrders '01.01.2010',
'01.07.2010'spr_getOrders
@dateBegin = '01.01.2010',
@dateEnd = '01.07.2010'spr_getOrders
'01.01.2010', @dateEnd = '01.07.2010'
В объявлении хранимой процедуры для двух
указанных параметров не были предусмотрены значения, применяемые по умолчанию,
поэтому оба параметра рассматриваются как обязательные. Это означает, что для
успешного вызова хранимой процедуры необходимо предоставить оба параметра. В
этом можно легко убедиться, осуществив попытку снова вызвать хранимую
процедуру, указав только один параметр или вообще не указывая параметры.
Применение выходных параметров
Выходные параметры позволяют хранимой процедуре
возвращать данные вызывающей программе. Для определения выходных параметров
используется ключевое слово OUT[PUT], которое обязательно как при определении
процедуры, так и при ее вызове. В самой хранимой процедуре выходные параметры
являются локальными переменными. В вызывающей процедуре или пакете выходные
переменные должны быть предварительно определены, чтобы получить результирующие
значения. Когда выполнение хранимой процедуры завершается, текущее значение
параметра передастся локальной переменной вызывающей программы.
В следующем примере выходной параметр
используется для возвращения уникального идентификатора вновь добавленного
товара.
CREATE PROCEDURE spr_addProduct
@Description nvarchar(100),
@InStock int = 0,
@IdProd int
OUTProduct([Description], InStock)(@Description, @InStock)@IdProd = @@IDENTITY
Пример вызова:@IdProd
int
EXEC spr_addProduct
@Description = N'Новый товар',
@IdProd = @IdProd OUTPUT@IdProd as
N'@IdProd'
Обратите внимание на то, что при вызове
процедуры переданы значения не для всех параметров. Параметр InStock являются
необязательным, поскольку для него указано значение по умолчанию в виде нуля,
которое и будет использовано, в случае если для него не будет явно
предоставлено другое значение. При этом если бы вызов хранимой процедуры и
передача значений происходили с использованием позиционных параметров, то
пришлось бы заполнять каждую позицию в списке параметров, по меньшей мере, до
того, как встретился бы последний параметр, для которого должно быть
предусмотрено значение.
Подтверждение успешного или неудачного
завершения работы с помощью возвращаемых значений. Использование команды
RETURN.
Любая вызываемая на выполнение хранимая
процедура возвращает значение, независимо от того, предусмотрен ли в ней
возврат значения или нет. По умолчанию после успешного завершения процедуры
СУБД SQL Server автоматически возвращает значение, равное нулю.
Чтобы передать некоторое возвращаемое значение
из хранимой процедуры обратно в вызывающий код, достаточно применить оператор
RETURN:[<Целое число>]
Обратите внимание на то, что возвращаемое
значение должно быть обязательно целочисленным.
Возвращаемые значения предназначены
исключительно для указания на успешное или неудачное завершение хранимой
процедуры и позволяют даже обозначить степень или характер успеха или неудачи.
Использование возвращаемого значения для возврата фактических данных, таких как
идентификационное значение или данные о количестве строк, затронутых хранимой
процедурой, рассматривается как недопустимая практика программирования.
Возвращаемое значение 0 указывает на успешное выполнение процедуры и
установлено по умолчанию. Компания Microsoft зарезервировала значения от -99 до
-1 для служебного пользования. Разработчикам для возвращения состояния ошибки
пользователю рекомендуется использовать значения -100 и меньше.
Одной из наиболее важных особенностей оператора
RETURN является то, что его выполнение приводит к безусловному завершению
работы и выходу из хранимой процедуры. Это означает, что, независимо от
местонахождения оператора RETURN в коде хранимой процедуре, после его
выполнения больше не будет выполнена ни одна строка кода. Под безусловным
завершением работы подразумевается, что действие, предусмотренное оператором
RETURN, осуществляется независимо от того, в каком месте кода он
обнаруживается. С другой стороны, допускается наличие в коде хранимой процедуры
нескольких операторов RETURN, а выполнение этих операторов происходит, только
если к этому приводит обычная структура управления процессом выполнения кода.
В предыдущем примере при попытке добавления в
таблицу Product информации о новом товаре с дублирующим названием могла
произойти ошибка, поскольку по наименованию товара организовано ограничение
уникальности. Расширим хранимую процедуру spr_addProduct, предусмотрев
предварительную проверку на наличие указанного товара в базе и индикацию об
успешности операции через выходной параметр.
ALTER PROCEDURE
[dbo].[spr_addProduct]
@Description nvarchar(100),
@InStock int = 0,
@IdProd int OUTEXISTS(SELECT * FROM
Product WHERE [Description] = @Description)-100Product([Description],
InStock)(@Description, @InStock) @IdProd
= @@IDENTITY0
При вызове хранимой процедуры, если ожидается
выходное значение, команда EXEC должна использовать целочисленную
переменную:@локальная_переменная = имя_хранимой_процедуры;
DECLARE@return_value int,
@IdProd int
EXEC@return_value = spr_addProduct
@Description = N'Новый товар',
@IdProd = @IdProd OUTPUT
@return_value
= 0
BEGIN
PRINT 'Товар
успешно добавлен'
SELECT @IdProd as N'@IdProd'
ELSE'При добавлении товара произошла ошибка'
SELECT 'Return Value' =
@return_value
Задание для самостоятельной работы: Создайте
хранимые процедуры, реализующие следующие действия:
Возврат списка всех заказов содержащих заданный
товар (по IdProd).
Определение количества клиентов, не имеющих ни
одного заказа. Результат должен возвращаться через выходной параметр.
Удаление из базы данных информации об
определенном клиенте (по IdCust). Если с данных клиентом имеются связанные
записи (заказы) удаление должно быть отменено. Возвращаемое значение должно
определять успешность выполнения операции.
Лабораторная работа №9. Функции
данная база триггер ссылка
Системные функцииServer содержит богатый набор
встроенных системных функций, которые формально подразделяются на следующие
группы: статистические, функции настройки, функции работы с курсором, функции
даты и времени, математические, функции работы с наборами строк, функции
безопасности, строковые, системные статистические, функции обработки текста и
изображений и прочие. Полный список системных функций, сгруппированных в
отдельные папки по вышеуказанным категориям, можно увидеть в Management Studio
в узле «Программирование - Функции - Системные функции» дерева обозревателя
объектов. Рассмотрим некоторые из наиболее часто используемых скалярных
(возвращающих одно значение) встроенных системных функций.
Информационные функции
В архитектуре "клиент/сервер" полезно
знать, кем является конкретный клиент. В этом смысле очень полезными окажутся
следующие четыре функции, особенно при сборе информации для аудита._name().
Возвращает имя текущего клиента, каким он представился базе данных. Когда
пользователю открыт доступ к базе данных, его имя может отличаться от регистрационного
имени входа на сервер._sname(). Возвращает регистрационное имя пользователя,
под которым он вошел на SQL Server. Даже если тот был аутентифицирован как член
одной из групп пользователей Windows, функция все равно возвращает имя его
учетной записи Windows._name(). Возвращает имя рабочей станции
пользователя._name(). Возвращает имя приложения, подключенного к SQL Server.
Пример использования:_NAME() AS 'Имя
пользователя БД',
SUSER_SNAME() AS 'Имя
входа',_NAME()
AS 'Имя
рабочей
станции',_NAME()
AS 'Имя
приложения'
Строковые функцииServer поддерживает больше двух
десятков функций для манипулирования строками. Рассмотрим несколько самых
полезных из них.(строка, начальная_позиция, длина). Возвращает фрагмент строки.
Первым параметром является сама строка, вторым - номер символа, с которого
вырезается фрагмент, третьим - длина вырезаемого фрагмента. Например,
результатом инструкции SELECT SUBSTRING('abcdefg', 3, 2) будет подстрока
‘cd’.(строка, позиция_вставки, число_удаляемых_символов, вставляемая_строка).
Противоположная по характеру функции substring(), функция stuff() вставляет
одну строку в другую; при этом в позиции вставки может быть удалено заданное
количество символов исходной строки. Например, результатом инструкции SELECT
STUFF('abcdefg', 3, 2, '123') будет строка 'ab123efg'.(строка, строка).
Заменяет заданные фрагменты строки другой строкой. Например, функция
REPLACE('abacad', 'a', 'e') возвращает строку ‘ebeced’(символ_поиска, строка,
начальная_позиция). Возвращает позицию заданного символа в строке. Например,
инструкция SELECT CHARINDEX('c', 'abcdefg', 1) вернет результат 3.(%шабпон%,
строка). Выполняет поиск по шаблону, который может содержать в строке символы
макроподстановки. В следующем примере ищется первое вхождение в строку символа
с или d: SELECT PATINDEX('%[cd]%', 'abdedefg'). Результатом данного запроса
будет число 3.(строка, число) и Left(строка, число). Возвращает крайнюю правую
или левую часть строки. Например, результатом запроса SELECT LEFT('abcdefg',2)
будет ‘ab’(строка). Возвращает длину строки.(строка) и Ltrim(строка). Эти
функции удаляют соответственно пробелы в начале и в конце строки.(строка) и
Lower(строка). Преобразует символы строки соответственно в верхний или нижний
регистр.
Функции работы с датой и временем
Для манипулирования значениями даты и времени
SQL Server предлагает девять функций. Некоторые из этих функций используют
аргумент datepart, определяющий фрагмент, к которому применяется операция. В
следующей таблице перечислены все возможные значения аргумента datepart.
|
Константа
|
Значение
|
|
yy
или yyyy
|
Год
|
|
qq
или q
|
Квартал
|
|
mm
или m
|
Месяц
|
|
wk
или ww
|
Неделя
|
|
dw
или w
|
День
недели
|
|
dy
или y
|
День
года
|
|
dd
или d
|
День
|
|
hh
|
Час
|
|
mi
или n
|
Минута
|
|
ss
или s
|
Секунда
|
|
ms
|
Миллисекунда
|
Например, функция DATEADD принимает в качестве
аргументов маркер datepart, величину приращения и исходную дату. Она возвращает
результат добавления указанной величины в единицах, указанных в аргументе
datepart, к текущей дате. Таким образом, чтобы добавить к текущей дате три дня,
вы можете использовать следующий код:DATEADD(d, 3, GETDATE())
Ниже приведен полный список доступных функций
даты и времени.(datepart, величина, дата_начала). Добавляет к дате указанную
величину.(datepart, величина, дата_начала). Выводит количество единиц времени,
заданных в аргументе datepart, между двумя датами.(datepart, дата). Возвращает
текстовые имена (например, имя месяца или дня недели), соответствующие заданной
дате.(datepart, дата). Извлекает определенный фрагмент из заданной даты.(дата).
Извлекает день из даты.. Возвращает текущее время и дату.. Возвращает текущую
дату и время, преобразованное в формат универсального синхронизированного
времени (UTC).(дата). Извлекает месяц из даты.(дата). Извлекает год из даты.
В следующем примере запрос возвращает список
всех заказов сделанных в сентябре месяце с указанием дня недели:
SELECT *, DATENAME(dw, OrdDate) AS 'День
недели'[Order]MONTH(OrdDate)
= 9
Функции преобразования данных
Для явных преобразований одно типа данных в
другой в SQL Server используют функции cast() и convert().(исходные_данные AS
тип_данных). Стандарт ANSI SQL рекомендует явное преобразование одного типа
данных в другой. Даже если такое преобразование может быть выполнено неявно
сервером, использование функции cast() гарантирует получение нужного типа.
Функция cast() программируется несколько отлично от других. Вместо разделения
двух своих аргументов запятой используется ключевое слово AS, за которым
следует требуемый тип данных, например:
SELECT [Description], 'Остаток
на
складе:
' + CAST(InStock AS varchar(10))
FROM Product(тип_данных, выражение [, стиль]).
Эта функция возвращает значение, преобразованное в другой тип данных с
произвольным форматированием. Эта функция не предусмотрена стандартом ANSI SQL.
Первым ее аргументом является желаемый тип данных, применяемый к выражению.
Аргумент стиль предполагает применение к результату некоторого стиля. Стиль
обычно применяется при преобразовании из типа даты-времени в символьный и
наоборот. Как правило, одно- или двухцифровой стиль предполагает двухцифровой
год, а трехцифровой - четырехцифровой год. К примеру, стиль 1 подразумевает
следующий формат данных: 01/01/03, в тоже время стиль 3 - 01/01/2003.
Пример:CONVERT(nvarchar(25), GETDATE(), 1)CONVERT(nvarchar(25), GETDATE(), 100)
Функции для обработки пустых значений
Часто пустое значение нужно преобразовать в
некоторое допустимое, чтобы данные можно было понять или чтобы выражение имело
результат. Пустые значения требуют специальной обработки при использовании в
выражениях, и язык SQL содержит ряд функций, специально предназначенных для
работы с пустыми значениями. Функции isnull () и coalesce() преобразуют пустые
значения в пригодные для использования, а функция nullif() создает пустое
значение, если выполняется определенное условие.
Наиболее часто используемой функцией,
предназначенной для работы с пустыми значениями, является isnull(). Эта функция
в качестве аргумента принимает одно выражение или столбец, а также
подстановочное значение. Если первый аргумент является допустимым значением
(т.е. не пустым), эта функция возвращает его. Однако если первый аргумент
представляет собой пустое значение, то возвращается значение второго аргумента.
Общий синтаксис функции следующий:(исходное_выражение, замещающее_значение).
Следующий пример подставляет строку 'не указан'
вместо пустого значения там, где для клиента не определен телефон:
SELECT FName, LName, ISNULL(Phone, 'не
указан')
AS Phone
FROM Customer
Функция coalesce() принимает список выражений
или столбцов и возвращает первое значение, которое окажется не пустым. Ее общий
синтаксис следующий:(выражение, выражение, ...)
В следующем примере продемонстрирована функция
coalesce(), возвращающая первое непустое значение (в данном случае это 3):
SELECT COALESCE(NULL, 1+NULL, 1+2, 'abc'))
Иногда пустое значение нужно создать на месте
заменяющего его суррогатного. Если база данных заполнена значениями n/a, - или
пустыми строками там, где должны находиться пустые значения, вы можете
воспользоваться функцией nullif() и расчистить базу данных.
Функция nullif() принимает два аргумента. Если
они равны, то возвращается пустое значение, в противном случае возвращается
первый параметр.
Следующий фрагмент кода преобразует все пробелы
в столбце FName в пустые значения.
SELECT
NULLIF(LTRIM(RTRIM(FName)),'') AS FName
FROM Customer
Пользовательские функции
Кроме широкого выбора встроенных функций SQL
Server предоставляет также возможность создавать свои собственные функции,
содержащие часто используемый код.
Пользовательские функции обладают следующими
преимущества:
С их помощью можно внедрить в запросы сложную
логику.
Создавая новые функции, можно проектировать
сложные выражения.
Эти функции обладают всеми достоинствами
представлений, поскольку могут использоваться в предложении FROM инструкции
SELECT и в выражениях и могут быть задействованы в схеме. К тому же
пользовательские функции могут принимать параметры, в то время как
представления - нет.
Они обладают достоинствами хранимых процедур,
так как могут быть скомпилированы и оптимизированы таким же способом.
Главным аргументом против использования
пользовательских функций является вопрос переносимости. Пользовательские
функции привязаны к SQL Server, и любую базу данных, использующую множество
таких функций, будет сложно или даже невозможно перенести на другую платформу
СУБД без существенной переработки. Эта задача усложняется тем, что также должны
быть переписаны и все инструкции SELECT, в которые внедрены пользовательские
функции. Если в будущем планируется развертывание базы данных на других
платформах, то лучше заменить все пользовательские функции представлениями или
хранимыми процедурами.
Пользовательские функции во многом аналогичны
хранимым процедурам, но отличаются от них перечисленными ниже особенностями:
Пользовательские функции могут возвращать
значения, относящиеся к большинству типов данных SQL Server. Не допускается
использовать в качестве типов возвращаемых значений лишь такие типы, как text,
ntext, image, cursor и timestamp.
Пользовательские функции не должны иметь
побочных эффектов. По существу, в пользовательских функциях не допускается
выполнение каких-либо действий, выходящих за пределы действия самой функции.
Например, в них нельзя модифицировать таблицы, отправлять электронную почту и
вносить изменения в значения параметров системы или базы данных.
Пользовательские функции во многом аналогичны
функциям, используемым в классических языках программирования. Эти функции
принимают несколько параметров и возвращают одно значение. Различия между
пользовательскими функциями SQL Server и функциями многих процедурных языков программирования
состоят в том, что в них передача параметров осуществляется по значению,
поэтому для них не предусмотрен способ передачи параметров, подобный применению
ссылки или передачи указателей. Тем не менее пользовательские функции удобны
тем, что позволяют возвращать данные в виде специальной таблицы.
Пользовательские функции подразделяются на три
типа:
Скалярные, возвращающие одно значение.
Внедренные табличные, аналогичные
представлениям.
Сложные табличные, создающие в программном коде
результирующий набор данных.
Скалярные функции
Скалярными называют те функции, которые
возвращают одно значение. Эти функции могут принимать множество параметров,
выполнять вычисления, но в результате выдают одно значение. Эти функции могут
использоваться в любых выражениях, даже участвующих в ограничениях проверки.
Значение возвращается функцией с помощью оператора return - эта команда должна
завершать скалярную функцию.
В скалярных пользовательских функциях не
допускаются операции обновления базы данных, но в то же время они могут
работать с локальными временными таблицами. Они не могут возвращать данные BLOB
(двоичные большие объекты) таких типов, как text, image и ntext, равно как
табличные переменные и курсоры.
Скалярные функции создаются, изменяются и
удаляются с помощью тех же инструкций DDL, что и другие объекты, хотя синтаксис
немного отличается, чтобы определить возвращаемое значение:FUNCTION имя_функции
(входные_параметры) RETURNS тип_данных AS BEGIN текст_ функции RETURN выражение
END
В списке входных параметров должны быть указаны
типы данных и, в случае необходимости, значения по умолчанию, аналогично
хранимым процедурам (параметр = умолчание). Параметры функции отличаются от
параметров хранимых процедур тем, что даже если определены значения по
умолчанию, параметры все равно должны присутствовать в вызове функции (т.е.
параметры с определенными по умолчанию значениями все равно обязательны). Чтобы
запросить значение по умолчанию при вызове функции, ей передается ключевое
слово default.
Следующая скалярная функция выполняет простую
арифметическую операцию; ее второй параметр имеет значение по умолчанию:
CREATE FUNCTION dbo.Multiply (@A
int, @B int = 3)INT@A * @B
END
Скалярные функции могут использоваться в любом
месте выражений, где допустимо одно значение. Пользовательские скалярные
функции должны всегда вызываться с помощью двухкомпонентного имени
(владелец.имя). В следующем примере продемонстрирован вызов ранее созданной
функции Multiply:dbo.Multiply(3,4)dbo.Multiply(7, DEFAULT)
Следующий код создает функцию, возвращающую имя
заданного клиента в формате Фамилия И.
CREATE FUNCTION getFICust (@IdCust
int)varchar(25)@result varchar(25)@result = 'NULL'@result = LName + ' ' +
SUBSTRING(FName, 1, 1) + '.'CustomerIdCust = @IdCust@result
Тестирование созданной
функции:dbo.getFICust(IdCust)
AS CustNameCustomerBY LName, FName
Задание для самостоятельной работы: Создайте
скалярные пользовательские функции, возвращающие:
Количество товара на складе по заданному
уникальному идентификатору товара;
Суммарную стоимость товаров в заданном заказе.
Внедренные табличные функции
Второй тип пользовательских функций очень похож
на представления. Оба обрамляют сохраняемую инструкцию SELECT. Внедренные
табличные функции имеют все достоинства представлений, добавляя к ним
использование параметров и возможность компиляции. Как и в представлениях, если
инструкция SELECT обновляема, то обновляемой является и функция.
Внедренная табличная функция не имеет в своем
теле блока BEGIN ... END - вместо этого возвращается результирующий набор
данных инструкции SELECT в виде таблицы с заданным именем:
CREATE FUNCTION имя_функции
(параметры)
RETURNS Table AS RETURN (инструкция_SELECT)
Следующая внедренная табличная функция является
функциональным эквивалентом представления v_Customer созданного в лаб. занятии
№6.
CREATE FUNCTION fCustomers ()TABLE
(Customer.IdCust, Customer.FName,
Customer.LName, City.CityNameCustomer INNER JOINON Customer.IdCity =
City.IdCity
)
Для извлечения данных с помощью функции
fCustomers вызовите ее в предложении FROM инструкции SELECT:
SELECT *dbo.fCustomers()BY LName,
FName
Одним из преимуществ внедренных табличных
функций по сравнению с представлениями является возможность первых включать
параметры в предварительно скомпилированные инструкции SELECT. Представления не
могут иметь параметров и обычно ограничивают результат с помощью добавления
предложения WHERE в инструкцию SELECT, вызывающую представление. В качестве
примера рассмотрим функцию возвращающую список клиентов из заданного города.
CREATE FUNCTION [dbo].[fCustomersForCity]
(@IdCity int = NULL)TABLE
(IdCust, FName, LNameCustomerIdCity
= @IdCity OR @IdCity IS NULL
)
Если функция вызывается с параметром по
умолчанию, то возвращается список всех клиентов:
SELECT
*dbo.fCustomersForCity(DEFAULT)
Если же в качестве параметра передается
уникальный идентификатор города, то скомпилированная инструкция SELECT в
функции вернет только клиентов из города с заданным
кодом:*dbo.fCustomersForCity(1)
Табличные функции с множеством инструкций
Пользовательские табличные функции с множеством
инструкций комбинируют способность скалярных функций содержать сложный
программный код со способностью внедренных табличных функций возвращать
результирующий набор данных. Этот тип функций создает табличную переменную, а
затем заполняет ее в теле функции. Сформированная таблица впоследствии
возвращается функцией и может использоваться в инструкциях SELECT.
Главным преимуществом таких функций является то,
что результирующий набор данных может формироваться в пакете инструкций, а
затем напрямую использоваться в инструкциях SELECT. Это позволяет использовать
этот тип функций вместо хранимых процедур.
Синтаксис, используемый для создания табличных
функций с множеством инструкций, практически такой же, как и для создания
скалярных функций:FUNCTION имя_функиии (входные_параметры) RETURNS @имя_таблицы
TABLE (столбцы) AS BEGIN Программный код заполнения табличной переменной RETURN
END
Следующая процедура позволяет создать табличную
пользовательскую функцию с множеством инструкций, которая возвращает основной
результирующий набор данных.
В начале инструкции CREATE FUNCTION создается
табличная переменная.
В теле функции с помощью инструкций INSERT
заполняют переменную.
После выполнения функции значение табличной
переменной передается во внешнюю процедуру как результат функции.
Запишем предыдущую функцию в виде
многооператорной функции.
CREATE FUNCTION
[dbo].[fCustomersByCity2]
(
@IdCity int = NULL
)
@Result TABLE
(int,nvarchar(20),nvarchar(20)
)(@IdCity IS NULL)@ResultIdCust,
FName, LNameCustomer@ResultIdCust, FName, LNameCustomerIdCity = @IdCity
END
Задание для самостоятельной работы: Создайте
пользовательские функции, возвращающие:
Список всех товаров, которые не были ни разу
заказаны
Список всех заказов за заданный период времени.
Лабораторная работа №10. Обработка
ошибок. Управление транзакциями. Триггеры
Обработка ошибок. Блок TRY…CATCH.
Стандартным способом перехвата и обработки
ошибок в Transact-SQL (начиная с версии SQL Server 2005) является использование
конструкции TRY...CATCH, который напоминает обработку исключений, применяемую
во многих языках программирования (Delphi, C++, C# и т.д.).
Общий синтаксис конструкции TRY...CATCH
следующий:
BEGIN TRY { инструкции
T-SQL } END TRY BEGIN CATCH [ { инструкции
T-SQL } ] END CATCH [ ; ]
Конструкция TRY…CATCH состоит из двух частей:
блок TRY и блок CATCH. При обнаружении ошибки в инструкции T-SQL внутри блока
TRY управление передается блоку CATCH, где эта ошибка может быть обработана.
Блок TRY начинается с инструкции BEGIN TRY и
завершается инструкцией END TRY. Между ними могут быть помещены одна или
несколько инструкций T-SQL, при выполнении которых может произойти ошибка.
За блоком TRY сразу же должен следовать блок
обработки ошибок CATCH. Блок CATCH начинается с инструкции BEGIN CATCH и
завершается инструкцией END CATCH. В Transact-SQL каждый блок TRY ассоциирован
только с одним блоком CATCH.
По завершении обработки исключения блоком CATCH
управление передается первой инструкции T-SQL, следующей за инструкцией END
CATCH. Если инструкция END CATCH является последней инструкцией хранимой
процедуры или триггера, управление возвращается коду, вызвавшему эту хранимую
процедуру или триггер. Инструкции T-SQL в блоке TRY, следующие за инструкцией,
вызвавшей ошибку, не выполняются.
Если в блоке TRY ошибок нет, управление
передается инструкции, следующей непосредственно за связанной с ней инструкцией
END CATCH. Если инструкция END CATCH является последней инструкцией хранимой
процедуры или триггера, управление передается инструкции, вызвавшей эту
хранимую процедуру или триггер.
Рассмотрим следующий пример:TRY'Первая попытка';
-Имитация ошибки (деление на ноль)
DECLARE @i int@i = 5/0'Вторая
попытка';TRYCATCH
PRINT 'Секция обработки ошибки';CATCH;'Третья
попытка';
В результате выполнения данного блока кода будет
получен следующий результат:
Первая попытка
Секция обработки ошибки
Третья попытка
В этом примере SQL Server выполняет секцию TRY,
пока не встречает строку имитирующую ошибку (в данном случае деление на ноль).
После этого все последующие инструкции в блоке TRY (в данном случае вывод
сообщения о второй попытке) пропускаются, и управление передается в секцию
CATCH. Следом за блоком CATCH выполняется следующая по порядку инструкция,
выводящая сообщение о третьей попытке.
Если в данном примере закомментировать строку,
вызывающую ошибку, блок TRY будет выполнен полностью, а блок CATCH -
проигнорирован:
Первая попытка
Вторая попытка
Третья попытка
Активация сообщений об ошибках вручную.
Инструкция RAISERROR
Чтобы вернуть произвольное сообщение об ошибке в
вызывающую процедуру или клиентское приложение, используют команду RAISERROR.
Синтаксис этой команды следующий:( сообщение или
номер ошибки, степень_серьезности, состояние, [ дополнительные_аргументы ])
Степень серьезности ошибки является указанием на
то, какие меры следует принимать с учетом этой ошибки. Система обозначений
степеней серьезности ошибок в СУБД SQL Server охватывает широкий спектр
сообщений об ошибках, включая те, которые по существу являются информационными
(со значениями степеней серьезности 1-18), считаются относящимися к системному
уровню (19-25) и даже рассматриваются как катастрофические (20-25). При
возникновении ошибок со степенями серьезности 20 и выше автоматически
завершается работа пользовательских соединений. Если необходимо завершить выполнение
процедуры и активировать в клиентской программе ошибку, как правило,
указывается степень серьезности 16.
Обозначение состояния представляет собой
произвольную величину. Этот параметр оператора RAISERROR был введен в действие
с учетом того, что одна и та же ошибка может возникнуть в несколько местах
кода. А параметр с обозначением состояния предоставляет возможность передать
вместе с сообщением своего рода маркер участка кода, который показывает, где
именно произошла ошибка. Числа с обозначением состояния могут находиться в
пределах от 1 до 127.
Замените в предыдущем примере строку с ошибкой
деления на ноль командой, генерирующей пользовательскую ошибку:('Имитация
ошибки',16,1)
Управление транзакциями
Концепция транзакций - неотъемлемая часть любой
клиент-серверной базы данных.
Под транзакцией понимается неделимая с точки
зрения воздействия на БД последовательность операторов манипулирования данными
(чтения, удаления, вставки, модификации), приводящая к одному из двух возможных
результатов: либо последовательность выполняется целиком, если все операторы
правильные, либо вся транзакция откатывается, если хотя бы один оператор не
может быть успешно выполнен. Обработка транзакций гарантирует целостность
информации в базе данных. Таким образом, транзакция переводит базу данных из
одного целостного состояния в другое.
Для примера рассмотрим базу данных, управляющую
банковскими счетами. Предположим, что необходимо перевести деньги с одного
счета на другой. Это предполагает две операции:
уменьшение баланса исходящего счета;
увеличение баланса принимающего счета.
Если одна из этих операций завершается ошибкой,
вторая также должна быть отменена, в противном случае база данных потеряет
целостность. Эти две операции совместно составляют единую транзакцию, которая
может быть либо целиком выполнена, либо целиком отменена.
Большинство выполняемых действий производится в
теле транзакций. По умолчанию каждая команда выполняется как самостоятельная
транзакция. При необходимости пользователь может явно указать ее начало и конец,
чтобы иметь возможность включить в нее несколько команд. Для этого используются
следующие команды:TRAN[SACTION] - объявление начала транзакции (в журнале
транзакций фиксируются первоначальные значения изменяемых данных и момент
начала транзакции).TRAN[SACTION] - фиксация транзакции (если в теле транзакции
не было ошибок, то эта команда предписывает серверу зафиксировать все
изменения, сделанные в транзакции, после чего в журнале транзакций помечается,
что изменения зафиксированы и транзакция завершена).TRAN[SACTION] - откат
транзакции (когда сервер встречает эту команду, происходит откат транзакции
(отмена всех изменений), восстанавливается первоначальное состояние системы и в
журнале транзакций отмечается, что транзакция была отменена).
Рассмотрим следующий пример.
Откройте новое окно запроса и выберите Sales в
качестве активной базы данных
Введите и выполните следующий запросTRANSACTION
Будет запущена транзакция. Все модификации
данных в этом соединении не будут видны для других соединений.
Введите и выполните следующий запросCity('Новый
город')
Чтобы проверить, что модификация прошла успешно,
введите и выполните следующий запрос*City
В таблице появилась новая запись, но эти
изменения видны только в данном соединении
Откройте новое окно запроса, введите и выполните
в нем предыдущий запрос. Запрос не вернет результатов, поскольку он ждет
завершения транзакции, запущенной в другом окне.
Вернитесь в первое окно, введите и выполните
следующий запросTRANSACTION
Модификация данных отменена. Вернитесь во второе
окно. Обратите внимание, что запрос выполнился и вернул данные. Добавленная
строка отсутствует.
Операция оформления нового заказа предполагает
добавление новых записей сразу в две таблицы: Order и OrdItem. Реализуем данную
двойную операцию в виде единой транзакции:TRAN
BEGIN
TRY[Order](IdCust)(2)OrdItem(IdOrd,IdProd,Qty,Price)(SCOPE_IDENTITY(),1,1,5)TRYCATCHTRAN('Ошибка',16,1)CATCH
COMMIT TRAN
Триггеры
Триггер, подобно хранимой процедуре,
представляет собой сохраненный на сервере набор инструкций T-SQL. Главное
отличие заключается в том, что его невозможно выполнить вручную с помощью
команды EXEC. Триггер вызывается на выполнение не пользователем, а
прикрепляется к определенной таблице и инициируется самим сервером баз данных
как отклик на события вставки, обновления и удаления данных из этой таблицы,
т.е. триггер выполняется автоматически как часть самого оператора модификации
данных. Триггер на вставку запускается, когда в таблицу вставляется новая
запись. Триггер на удаление запускается, когда из таблицы удаляется некоторая
запись. Триггер на обновление запускается, когда некоторая запись таблицы
изменяется. Кроме того можно определить триггер реагирующий сразу на несколько
разных типов операций модификации, например на обновление и вставку. Триггер
выполняется внутри того же пространства транзакции, что и оператор модификации
данных, поэтому откат транзакции в триггере отменяет и саму исходную операцию
модификации данных.
Триггеры - наиболее мощный инструмент
поддержания целостности базы данных, поскольку они могут выполнять любые
необходимые для поддержания целостности данных действия:
Сравнивать предшествующие и новые версии данных.
В большинстве случаев в момент выполнения триггера необходимо знать, какие
изменения были выполнены исходным оператором модификации данных. Сведения об
этом можно найти в таблицах inserted (вставленные) и deleted (удаленные),
которые становятся доступны внутри триггера. Эти таблицы - фактически
представления строк в файле регистрации транзакции, которые были изменены
оператором и имеют структуры и имена столбцов, идентичные таблице, которая
изменилась. Таким образом, оценить, какие именно изменения были произведены в
таблице, можно исследуя содержимое таблиц inserted и deleted, как показано в
следующей таблице, и соответственно предпринимать те или иные действия в
зависимости от обнаруженных различий.
|
Оператор
|
Содержимое
таблицы inserted
|
Cодержимое
таблицы deleted
|
|
INSERT
|
Добавленные
строки
|
Пусто
|
|
UPDATE
|
Новые
строки
|
Старые
строки
|
|
DELETE
|
Удаленные
строки
|
Осуществлять отмену недопустимых модификаций
посредством отката транзакции. Это возможно благодаря тому, что триггер
запускается в рамках транзакции исходной операции модификации данных.
Осуществлять считывание из других таблиц.
Изменять другие таблицы.
Выполнять хранимые процедуры и функции.
Как правило, триггеры используют для реализации
сложных ограничений целостности, которые не могут быть обработаны посредством
типов данных, обычных ограничений, декларативной ссылочной целостностью,
например, реализация сложных ограничений столбцов или генерирование сложных
значений по умолчанию, основанных на данных в других строках или таблицах.
Потребность в триггерах возникает тогда, когда
требуется автоматическая реакция базы данных на определенные действия
пользователя. К примеру, когда из рабочей таблицы удаляется запись, вполне
возможно, что необходимо сохранить ее в некоторой дополнительной архивной
таблице для последующего аудита. Это можно осуществить, создав триггер на
удаление в первой таблице. В момент удаления записи этот триггер будет вызван
на выполнение. В это время он еще будет иметь доступ ко всем удаляемым данным и
сможет их скопировать в какое-либо другое место.
Триггеры также используют в более сложной и
гибкой форме ограничений. Ограничения лимитированы только пределами одной
таблицы, в то время как триггеры потенциально имеют доступ ко всей базе данных.
Предположим, что необходимо разрешить принимать заказы только от тех клиентов,
которые не имеют задолженностей по уже имеющимся счетам. В этом случае можно
создать триггер на вставку, который проверяет данное правило и в случае
необходимости отменяет исходную операцию вставки (откатывает транзакцию) с
выбросом соответствующего сообщения об ошибке.
Общий синтаксис запроса на создания триггера
выглядит следующим образом:TRIGGER имя_триггера ON имя_таблицы AFTER { [ INSERT
] [ , ] [ UPDATE ] [ , ] [ DELETE ] } AS { инструкции T-SQL }
При создании триггера указывается его имя, имя
таблицы, для которой он определяется, и события, при возникновении которых он
должен выполняться (перечисление после ключевого слова AFTER). Эти события
соответствуют трем операциям модификации данных: вставка, обновление и
удаление. При этом триггер запускается один раз на каждую операцию модификации
данных вне зависимости от количества затронутых этой операцией записей.
Определим в таблице City триггер, отслеживающий
все изменения в данной таблице. Для хранения информации обо всех операциях
модификации, выполняемых над данными в этой таблице, создадим специальную
таблицу sysCityAudit со следующими столбцами: IdOperation (уникальный
идентификатор операции), TypeOp (тип операции: вставка, обновление или
удаление), IdCity, CityName, DateAndTime (дата и время выполнения операции),
UserName (имя пользователя, изменившего данные). Запрос на создание данной
таблицы приведен ниже:TABLE [dbo].[sysCityAudit](
[IdOperation] [int] IDENTITY(1,1)
NOT NULL,
[TypeOp] [varchar](50) NOT NULL,
[IdCity] [int] NOT NULL,
[CityName] [nvarchar](20) NULL,
[DateAndTime] [datetime] NOT NULL
CONSTRAINT [DF_sysCityAudit_DateAndTime] DEFAULT (getdate()),
[UserName] [nvarchar](256) NOT NULL
CONSTRAINT [DF_sysCityAudit_UserName] DEFAULT (user_name()),[PK_sysCityAudit]
PRIMARY KEY CLUSTERED
(
[IdOperation] ASC
)WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Запрос на создание триггера, отслеживающего все
изменения в таблице City:
CREATE TRIGGER [dbo].[tr_CityAudit]
ON [dbo].[City]INSERT,DELETE,UPDATENOCOUNT ON;EXISTS(SELECT * FROM inserted)
AND EXISTS(SELECT * FROM deleted)sysCityAudit(TypeOp,IdCity,CityName)'Обновление',
IdCity, CityNameinsertedIF EXISTS(SELECT * FROM inserted)
--sysCityAudit(TypeOp,IdCity,CityName)'Вставка',
IdCity, CityNameinsertedsysCityAudit(TypeOp,IdCity,CityName)'Удаление',
IdCity, CityNamedeleted
END
Проверьте работоспособность вновь созданного
триггера. Для этого произведите в таблице City различные изменения и убедитесь,
что подробная информация о них была записана в таблицу sysCityAudit.
Для демонстрации применения триггера, в качестве
инструмента ограничивающего возможные операции с данными в таблице в
соответствии с определенными бизнес-правилами, создадим триггер, запрещающий
оформлять заказы от клиентов из Москвы (к базе данных Sales сложно сформулировать
осмысленное бизнес-правило, требующее использование триггера, поэтому пример
весьма искусственный).
CREATE TRIGGER
[dbo].[tr_OrderConstraint] ON [dbo].[Order]INSERT,UPDATENOCOUNT
ON;EXISTS(SELECT *inserted AS i INNER JOINAS cust ON i.IdCust = cust.IdCust
INNER JOINAS c ON cust.IdCity = c.IdCityc.CityName = N'Москва')TRANSACTION
RAISERROR('Оформление заказов для клиентов из
Москвы запрещено',16,1)
Поскольку триггер выполняется в рамках
транзакции соответствующей ей операции модификации данных для отмены самой
операции достаточно выполнить команду ROLLBACK TRANSACTION. Кроме того в случае
попытки нарушения заданного бизнес-правила желательно с помощью команды
RAISEERROR отправить пользователю сообщение об ошибке c ее подробным описание.
Задание для самостоятельной работы: Создайте триггер, запрещающий добавлять в
заказ товары, отсутствующие на складе.
Лабораторная работа №11. Система
безопасности SQL Server
Система безопасности SQL Server основана на
концепции защищаемых объектов (securables), т.е. объектов, на которые можно
назначать разрешения, и принципалов (principles), т.е. объектов, которым можно
назначать разрешения. Принципалами могут быть логины на уровне сервера,
пользователи и роли на уровне базы данных. Роли назначаются пользователям.
Разрешения на доступ к объектам могут предоставляться как непосредственно
пользователям, так и через роли. Каждый объект имеет своего владельца, и права
собственности также влияют на разрешения.
Общая схема системы безопасности SQL Server
Рис. 11.1
Server использует двухэтапную схему
аутентификации. На уровне сервера пользователь распознается по своему
идентификатору (LoginID), который может быть либо именем входа SQL Server, либо
группой или учетной записью Windows. После входа на сервер пользователь
получает те права, которые были назначены ему администратором на уровне
сервера, в частности с помощью фиксированных серверных ролей. Если пользователь
принадлежит роли sysadmin, то он имеет полный доступ ко всем функциям сервера,
а также ко всем базам данных и объектам на нем.
Для получения доступа к базе данных логин
пользователя должен быть сопоставлен с соответствующим ему идентификатором
пользователя (UserID), который специфичен для каждой базы данных. Вполне
возможна ситуация, когда пользователь был распознан в SQL Server, но у него нет
доступа ни к одной из баз данных. Также возможно и обратное: пользователю
открыт доступ к базам данных, но он не был распознан сервером. Перемещение базы
данных и ее разрешений на другой сервер без параллельного перемещения имен
входа сервера может привести к возникновению таких "осиротевших"
пользователей.
На уровне базы данных пользователю может быть
предоставлен определенный набор разрешений с помощью назначения ему фиксированных
ролей базы данных. Все пользователи автоматически становятся членами
стандартной роли public, у которой по умолчанию нет никаких разрешений.
Пользовательские роли - это дополнительные роли, служащие в качестве групп.
Роли может быть разрешен доступ к объектам базы данных, а пользователю могут
быть назначены роли.
Разрешения к объектам назначаются с помощью
инструкций GRANT (предоставить), REVOKE (отозвать) и DENY (запретить). Запрет
привилегии замещает собой ее предоставление, а предоставление привилегии
замещает собой ее отзыв. Пользователю может быть предоставлено множество
разрешений к объекту (индивидуальных, наследованных от роли, обеспеченных
принадлежностью к роли public). Если какая-либо из этих привилегий запрещена,
для пользователя блокируется доступ к объекту. В противном случае, если
какая-либо из привилегий предоставляет разрешение, пользователь получает доступ
к объекту.
Разрешения объекта достаточно детализированы.
Существуют отдельные разрешения для каждого из возможных действий (SELECT,
INSERT, UPDATE, RUN и т.д.) над объектом.
Выбор типа логина и настройка режима
аутентификацииServer поддерживает два типа логинов (имен входа):
логин Windows (логин для локальной учетной
записи Windows, логин для доменной учетной записи Windows, логин для группы
Windows);
логин SQL Server.
При использовании логинов Windows в системные
таблицы базы данных master записывается информация об идентификаторе учетной
записи или группы Windows (но не пароль). Аутентификация (т. е. проверка имени
пользователя и пароля) производится обычными средствами Windows при входе
пользователя на свой компьютер.
При использовании логина SQL Server пароль для
этого логина (точнее, его хэшированное значение) хранится вместе с
идентификатором логина в базе данных master. При подключении пользователя к
серверу ему придется указать имя логина и пароль.
Предпочтительный вариант логина для пользователя
- это логин Windows, при этом не для учетной записи, а для группы (лучше всего
для локальной доменной группы). Преимуществ у такого решения множество:
пользователю достаточно помнить один пароль -
для входа на свой компьютер;
повышается уровень защищенности SQL Server. Это
происходит, по крайней мере, за счет того, что пароль не будет передаваться по
сети открытым текстом, как это происходит по умолчанию при использовании команд
CREATE LOGIN и ALTER LOGIN. Кроме того, хэши Windows более защищены, чем хэши
логинов SQL Server;
проверка при входе пользователя производится
быстрее.
Эти преимущества справедливы для любых логинов
Windows: как для учетных записей, так и для групп. Но при использовании логинов
для групп Windows появляются дополнительные преимущества:
снижается размер системных таблиц базы данных
master, в результате чего аутентификация производится быстрее. На одном сервере
SQL Server вполне может быть несколько тысяч логинов для пользователей Windows
или, что значительно удобнее, всего пара десятков логинов для групп;
значительно упрощается предоставление разрешений
для новых учетных записей.
Использование логинов SQL Server может быть
обусловлено следующей причиной: очень часто на предприятиях администрированием
SQL Server и домена Windows занимаются разные люди, которым сложно
согласовывать свои действия. Логины SQL Server позволяют администратору базы
данных быть независимым от администратора домена. Кроме того, у логинов SQL
Server есть и другие преимущества, которые принимаются во внимание
разработчиками:
на предприятии вполне может не оказаться домена
Windows (если, например, сеть построена на основе NetWare или UNIX);
пользователи SQL Server могут не входить в домен
(например, если они подключаются к SQL Server из филиалов или через
Web-интерфейс с домашнего компьютера).
Таким образом, выбор используемых типов логинов
зависит от многих факторов и в каждом конкретном случае решение принимается
индивидуально. Логины Windows - это удобство и защищенность, логины SQL Server-
это большая гибкость и независимость от администратора сети.
При установке SQL Server одним из решений,
которые следует принять, является выбор используемого режима аутентификации.
В режиме аутентификации Windows SQL Server
полностью доверяет (делегирует) аутентификацию операционной системе.
В смешанном режиме аутентификация Windows и
самого сервера сосуществуют независимо друг от друга.
Третьего варианта, в котором использование
логинов Windows было бы запрещено, не предусмотрено: логины этого типа доступны
всегда.
Установленный при инсталляции режим
аутентификации можно изменить в утилите Management Studio выбрав нужный
переключатель в группе «Серверная проверка подлинности» на странице
«Безопасность» диалогового окна «Свойства сервера».
Рис. 11.2
Установите переключатель в положение «Проверка
подлинности SQL Server и Windows». Таким образом, вы включите смешанный режим аутентификации,
в котором и будут выполняться остальные упражнения. Для того чтобы изменение
режима аутентификации вступило в силу сервер нужно перезапустить.
Создание логина и настройка его параметров
Логины любого типа создаются одинаково:
при помощи графического интерфейса - из окна
«Создание имени входа». Это окно открывается с помощью команды «Создать имя
входа…» контекстного меню узла «Безопасность | Имена входа» дерева обозревателя
объектов в SQL Server Management Studio;

Рис. 11.3
из скрипта - при помощи команды CREATE LOGIN.
Например, команда на создание логина SQL Server
с именем User1 и паролем P@sswOrd (для всех остальных параметров будут приняты
значения по умолчанию) может выглядеть так:
CREATE LOGIN User1 WITH PASSWORD =
'P@sswOrd';
Если вы создаете логин Windows, вам потребуется
выбрать соответствующую учетную запись или группу Windows.
Если вы создаете логин SQL Server, вам придется
ввести его имя и пароль. Пароль всегда чувствителен к регистру, а логин -
только тогда, когда чувствительность к регистру была определена при установке
SQL Server. Конечно, кроме имени и пароля для логинов можно определить
множество других параметров. Некоторые из них перечислены ниже.
База данных по умолчанию, к которой по умолчанию
будет подключаться пользователь при входе на SQL Server. По умолчанию
используется база данных master. Как правило, менять этот параметр не следует:
код для перехода к нужной базе данных при подключении обеспечивает клиентское
приложение.
Язык по умолчанию - язык, который будет
использоваться по умолчанию данным пользователем во время сеансов. В основном
он влияет на формат даты и времени, которые возвращает SQL Server. В
большинстве случаев для этого параметра оставляется значение по умолчанию (т. е.
язык, настроенный на уровне всего сервера), если о другом значении специально
не просит разработчик.
На вкладке «Состояние» свойств логина можно
настроить для этого логина дополнительные параметры:
Разрешение на подключение к ядру СУБД - по
умолчанию для всех логинов устанавливается значение «Предоставить», т. е.
подключаться к SQL Server разрешено. Значение «Запретить», как правило,
используется только в одном случае - когда вы предоставляете доступ на SQL
Server логину для группы Windows, а одному или нескольким членам этой группы
доступ нужно запретить. Поскольку явный запрет всегда имеет приоритет перед
разрешением, то достаточно будет создать свои собственные логины Windows для
этих пользователей и установить для них значение «Запретить».
Имя входа (Включено/Отключено) - конечно, все
логины по умолчанию включены. Обычно отключать их приходится только в ситуации,
когда какой-то пользователь увольняется или переходит на другую работу. Чтобы
сэкономить время, достаточно просто отключить данный логин, а при появлении
пользователя со схожими рабочими обязанностями переименовать этот логин,
поменять пароль и включить. Заниматься предоставлением разрешений заново в этом
случае не придется.
Имя входа заблокировано - установить этот флажок
вы не можете (только снять его). Учетная запись пользователя блокируется
автоматически после нескольких попыток неверного ввода пароля для логина SQL
Server, если такая блокировка настроена на уровне операционной системы, а для
логина установлен флажок «Требовать использование политики паролей».
Рис. 11.4
Разрешения на уровне сервера. Фиксированные
серверные роли
Создав логины, вы обеспечиваете пользователям
возможность входа на SQL Server. Но сам по себе вход на сервер ничего не дает:
пользователю нужны также права на выполнение определенных действий. Обычно для
этой цели создаются пользователи или роли баз данных и им предоставляются
разрешения (как это сделать, будет рассмотрено в следующем разделе). Однако
есть и другой способ. Если вам нужно предоставить пользователю права на уровне
всего сервера, а не отдельной базы данных, можно воспользоваться серверными
ролями.
На графическом экране работа с ролями сервера
производится или из свойств логина (вкладка «Роли сервера»), или из свойств самой
серверной роли (узел «Роли сервера» дерева обозревателя объектов Management
Studio).

Рис. 11.5
Отметим несколько моментов, связанных с
серверными ролями:
набор серверных ролей является фиксированным. Вы
не можете создавать свои серверные роли (в отличие от ролей базы данных);
для предоставления прав на уровне всего сервера
необязательно использовать серверные роли. Вы вполне можете предоставить эти
права напрямую логину (при помощи вкладки «Разрешения» окна свойств сервера).
По умолчанию каждый логин обладает на уровне всего сервера двумя правами:
CONNECT SQL (т. е. подключаться к серверу, это право предоставляется логину
напрямую) и VIEW ANY DATABASE (т. е. просматривать список баз данных, это право
пользователь получает через серверную роль public);
серверные роли используются только в специальных
случаях. Для большинства пользователей настраивать их не нужно.
Рис. 11.6
Серверных ролей не так много, поэтому приведем
их полный список с комментариями:- права этой роли автоматически получают все,
кто подключился к SQL Server, и лишить пользователя членства в этой роли
нельзя. Обычно эта роль используется для предоставления разрешений всем
пользователям данного сервера;- логин, которому назначена эта роль, получает
полные права на весь SQL Server (и возможность передавать эти права другим
пользователям);- эта роль для оператора, который обслуживает сервер. Можно
изменять любые настройки работы сервера и отключать сервер, но получать доступ
к данным и изменять разрешения нельзя;- эта роль для того, кто выдает
разрешения пользователям, не вмешиваясь в работу сервера. Он может создавать
логины для обычных пользователей, изменять их пароли, предоставлять разрешения
в базах данных. Однако предоставить кому-либо административные права или
изменять учетную запись администратора эта роль не позволяет;- роль для
сотрудников, которые выполняют массовые загрузки данных в таблицы SQL Server;-
эта роль позволяет создавать базы данных на SQL. Server (а тот, кто создал базу
данных, автоматически становится ее владельцем);- эта роль позволяет выполнять
любые операции с файлами баз данных на диске;- эта роль предназначена для
выполнения единственной обязанности: закрытия пользовательских подключений к серверу
(например, зависших);- права этой роли позволяют подключать внешние серверы SQL
Server.
Пользователи баз данных. Схемы
После создания логинов следующая задача -
спуститься на уровень базы данных и создать пользователей базы данных.
Пользователи баз данных - это специальные объекты, которые создаются на уровне
базы данных и используются для предоставления разрешений в базе данных (на
таблицы, представления, хранимые процедуры и т.д.).
Логины и пользователи баз данных - это
совершенно разные объекты. Разделение логинов и пользователей баз данных
обеспечивает большую гибкость. Например, пользователь, который входит от имени
одного и того же логина, сможет работать в разных базах данных от имени разных
пользователей.
Создать пользователя базы данных можно:
В среде Management Studio вызвав команду
«Создать пользователя…» в контекстном меню подузла «Безопасность |
Пользователи» узла конкретной базы данных дерева обозревателя объектов. В
открывшемся окне «Пользователь базы данных - Создать», снимок экрана с которым
приведен ниже, необходимо указать два обязательных параметра: имя нового
пользователя и выбрать соответствующий ему логин (Windows или SQL Server).
При помощи команды CREATE USER.

Рис. 11.7
Изменение свойств пользователя и его удаление
производится из того же контейнера в Management Studio, что и создание
пользователя, а также при помощи команд ALTER USER/DROP USER.
В SQL Server 2000 и в более старых версиях
объект пользователя базы данных нес на себе двойную нагрузку: во-первых, он
использовался для предоставления разрешений в базе данных, а во-вторых, имя
пользователя базы данных использовалось для идентификации объектов. Например,
обращение к таблице по полному ее имени могло выглядеть так: SELECT * FROM MyServer.MyDatabase.User1.Table1;
Если разработчик использовал в коде приложения
просто имя объекта (например, SELECT * FROM Table1), то при подключении к
серверу из этого приложения от имени другого пользователя могли возникнуть
проблемы, поскольку вместо User1 подставлялось текущее имя пользователя (а если
объект с таким полным именем не был обнаружен, то имя специального пользователя
dbo).
Начиная с версии SQL Server 2005 эти две функции
разделены. Для предоставления разрешений в базе данных, как и раньше, используется
объект пользователя, а для именования объектов в базе данных используется
специальный объект схема. Запрос с использованием полного формата имени в SQL
Server теперь должен выглядеть так:
SELECT * FROM
MyServer.MyDatabase.Schema1.Table1;
Схема формально определяется как набор объектов
в базе данных, объединенных общим пространством имен. Проще всего представить
себе схему как некий логический контейнер в базе данных, которому могут
принадлежать таблицы, представления, хранимые процедуры, пользовательские
функции, ограничения целостности, пользовательские типы данных и другие объекты
базы данных. Этот контейнер удобно использовать как для именования объектов и
их логической группировки, так и для предоставления разрешений. Например, если
в базе данных есть набор таблиц со связанными данными, удобно поместить их в
одну схему и предоставлять пользователям разрешения на эту схему (т. е. на этот
набор таблиц).
Пользователю можно назначить схему по умолчанию.
В эту схему SQL Server будет по умолчанию помещать объекты, которые создает
этот пользователь. Кроме того, искать объекты, к которым обращается
пользователь (например, в случае запроса вида SELECT * FROM Table1), SQL Server
также будет в первую очередь в его схеме по умолчанию.
Применение схемы дает ряд дополнительных
преимуществ по сравнению со старым подходом:
нескольким пользователям можно назначить одну и
ту же схему по умолчанию, что может быть удобно при разработке приложений;
несколько пользователей (через группы Windows
или роли баз данных) могут владеть одной и той же схемой. При этом один
пользователь может являться владельцем сразу нескольких схем;
при удалении пользователя из базы данных не
придется переименовывать его объекты;
упрощается предоставление разрешений для наборов
объектов в базе данных.
Список схем можно увидеть в подузле
«Безопасность | Схемы» узла конкретной базы данных дерева обозревателя объектов
Management Studio.
При создании любой базы данных в ней
автоматически создаются четыре специальных пользователя:(от database owner) -
пользователь-владелец базы данных. Он автоматически создается для того логина,
от имени которого была создана эта база данных. Конечно же, как владелец, он
получает полные права на свою базу данных (при помощи встроенной роли базы
данных db_owner);(гость) - этот специальный пользователь предназначен для
предоставления разрешений всем логинам, которым не соответствует ни один
пользователь в базе данных. По умолчанию у этого пользователя нет права login
для базы данных, и, следовательно, работать он не будет. Этот пользователь
используется чаще всего для предоставления разрешений логинам на какие-то
учебные/тестовые базы данных или на базы данных-справочники, доступные только
на чтение;_SCHEMA - этому пользователю не может соответствовать ни один логин.
Его единственное значение - быть владельцем схемы INFORMATION_SCHEMA, в которой
хранятся представления системной информации для базы данных;- этому
специальному пользователю, как и INFORMATION_SCHEMA, не могут соответствовать
логины. Он является владельцем схемы sys, которой принадлежат системные объекты
базы данных.
Роли базы данных
Обычно после создания логина и пользователя базы
данных следующее, что нужно сделать, - предоставить пользователю разрешения в
базе данных. Один из способов сделать это - воспользоваться ролями базы данных.
Роли базы данных - это специальные объекты,
которые используются для упрощения предоставления разрешений в базах данных. В
отличие от серверных ролей, которые могут быть только встроенными, роли баз
данных могут быть как встроенными, так и пользовательскими. Встроенные роли баз
данных обладают предопределенным набором разрешений, а пользовательские роли
можно использовать для группировки пользователей при предоставлении разрешений.
Обычно пользовательские роли используются только для логинов SQL Server,
поскольку для группировки логинов Windows обычно удобнее и проще использовать
группы Windows.
Вначале перечислим встроенные роли баз данных:-
эта специальная роль предназначена для предоставления разрешений сразу всем
пользователям базы данных. Специально сделать пользователя членом этой роли или
лишить его членства невозможно. Все пользователи базы данных получают права
этой роли автоматически._owner - этой роли автоматически предоставляются полные
права на базу данных. Изначально права этой роли предоставляются только
специальному пользователю dbo, а через него - логину, который создал эту базу
данных;_accessadmin - роль для сотрудника, ответственного за пользователей базы
данных. Этот сотрудник получит возможность создавать, изменять и удалять
объекты пользователей баз данных, а также создавать схемы. Других прав в базе
данных у него нет;_securityadmin- эта роль дополняет роль db_accessadmin.
Сотрудник с правами этой роли получает возможность назначать разрешения на
объекты базы данных и изменять членство во встроенных и пользовательских ролях.
Прав на создание и изменение объектов пользователей у этой роли
нет;_backupoperator - эта роль дает право выполнять резервное копирование базы
данных;_ddladmin - эта роль применяется в редких ситуациях, когда пользователю
необходимо дать право создавать, изменять и удалять любые объекты в базе
данных, не предоставляя прав на информацию, которая содержится в существующих
объектах;_datareader и db_datawriter - эти встроенные роли дают право просматривать
и изменять соответственно (в том числе добавлять и удалять) любую информацию в
базе данных. Очень часто пользователю необходимо дать права на чтение и запись
информации во всех таблицах базы данных, не предоставляя ему лишних
административных разрешений (на создание и удаление объектов, изменение прав и
т. п.). Самый простой вариант в этой ситуации - воспользоваться этими двумя
ролями._denydatareader и db_denydatawriter- эти роли противоположны ролям
db_datareader и db_datawriter. Роль db_ denydatareader явно запрещает
просматривать какие-либо данные, а db_denydatawriter запрещает внесение
изменений. Явный запрет всегда имеет приоритет перед явно предоставленными
разрешениями. Обычно эти роли используются в ситуации, когда "разрешаем
всем, а потом некоторым запрещаем".
Как уже говорилось ранее, в отличие от серверных
ролей, роли баз данных вы можете создавать самостоятельно. Это можно сделать из
контекстного меню узла «Безопасность | Роли | Роли базы данных» обозревателя
объектов в Management Studio или при помощи команды CREATE ROLE.
Рис. 11.8
Кроме имени роли, при создании можно также
указать ее владельца (если это не указано, владельцем роли автоматически станет
создавший ее пользователь базы данных). Если вы создаете роль при помощи
графического интерфейса, вы можете сразу назначить роль владельцем схемы в базе
данных и назначить пользователей, которые будут обладать правами этой роли.
Встроенным ролям назначены предопределенные
права, изменить которые невозможно. Предоставление прав пользовательским ролям
производится точно так же, как и обычным пользователям базы данных.
Предоставление прав на объекты в базе данных
Работа с разрешениями производится одинаково для
всех объектов базы данных:
на вкладке «Разрешения» свойств этого объекта
(эта вкладка предусмотрена не для всех объектов, для которых можно предоставить
разрешения);
на странице «Защищаемые объекты» окна свойств
пользователя или роли;
при помощи команд GRANT (предоставить
разрешение), DENY (явно запретить что-то делать) и REVOKE (отменить явно
предоставленное разрешение или запрет).
Начиная c версии 2005, в SQL Serve появилась
возможность предоставлять разрешения на уровне схемы. К схеме в SQL Server
могут относиться таблицы, представления, хранимые процедуры, пользовательские
функции, ограничения целостности, пользовательские типы данных и другие
объекты, на которые приходится предоставлять разрешения чаще всего. Если вы
назначите пользователю разрешения на схему, то он получит разрешения на все объекты
этой схемы.
Далее перечислены разрешения, которые можно
предоставить на уровне схемы. Мы приведем только разрешения для этого объекта,
поскольку разрешения схемы включают в себя разрешения, которые можно
предоставить другим объектам, например, разрешения SELECT для таблиц и
представлений и EXECUTE для хранимых процедур.- возможность вносить любые
изменения в свойства объекта (за исключением смены владельца).- тот, кому
предоставлено такое разрешение, получает полные права как на сам объект, так и
на информацию в нем.- возможность удалять существующую информацию в таблицах.
Применяется к таблицам, представлениям и столбцам.- право запускать на
выполнение. Применяется к хранимым процедурам и функциям.- право на вставку
новых данных в таблицы. Применяется к таблицам, представлениям и столбцам.-
разрешение, которое можно предоставить для проверки ограничений целостности.
Например, пользователь может добавлять данные в таблицу с внешним ключом, а на
таблицу с первичным ключом ему нельзя предоставлять права на просмотр. В этом
случае на таблицу с первичным ключом ему можно предоставить право REFERENCES -
и он сможет производить вставку данных в таблицу с внешним ключом, не получая
лишних прав на главную таблицу. Это разрешение можно предоставлять на таблицы,
представления, столбцы и функции.- право на чтение информации. Предоставляется
для таблиц, представлений, столбцов и табличных функций.OWNERSHIP - право на
принятие на себя владения данным объектом. Владелец автоматически обладает
полными правами на свой объект. Такое право можно назначить для любых
объектов.- возможность вносить изменения в существующие записи в таблице.
Предоставляется на таблицы, представления и столбцы.DEFINITION - право на
просмотр определения для данного объекта. Предусмотрено для таблиц,
представлений, процедур и функций.
Для каждого разрешения мы можем установить три
значения:- разрешение предоставлено явно;GRANT - разрешение не только
предоставлено данному пользователю, но он также получил право предоставлять это
разрешение другим пользователям. Можно предоставлять, конечно, только вместе с
GRANT;- явный запрет на выполнение действия, определенного данным разрешением.
Как в любых системах безопасности, явный запрет имеет приоритет перед явно
предоставленными разрешениями.
Из кода Transact-SQL разрешения можно
предоставлять командами GRANT, DENY и REVOKE. Например, чтобы предоставить
пользователю User1 возможность просматривать данные в таблице Table1 в схеме
dbo, можно воспользоваться командой: GRANT
SELECT ON
dbo.Table1
TO User1;
Лишить его ранее предоставленного права можно
при помощи команды: REVOKE
SELECT ON
dbo.Table1
TO User1;
Некоторые рекомендации, связанные с
предоставлением разрешений:
В большинстве реальных задач используются
десятки и даже сотни таблиц и других объектов базы данных. Предоставлять
каждому пользователю разрешения на каждый из этих объектов очень неудобно. Если
есть возможность, удобнее использовать разрешения на уровне схемы или всей базы
данных.
Существует общий принцип: не стоит обращаться из
клиентского приложения к таблицам базы данных напрямую. Для изменения данных
лучше использовать хранимые процедуры, а для запросов на чтение - хранимые
процедуры или представления. Причина проста: если потребуется поменять
структуру вашей базы данных (например, какую-то таблицу поделить на текущую и
архивную или добавить новый столбец) не потребуется вносить изменения в
клиентское приложение. Это следует помнить и при предоставлении разрешений.
Отметим также, что при помощи хранимых процедур можно очень просто реализовать дополнительные
проверки в добавление к обычным разрешениям;Server позволяет настраивать
разрешения на уровне отдельных столбцов. На практике лучше не пользоваться
такими разрешениями из-за падения производительности и усложнения системы
разрешений. Если пользователю можно видеть не все столбцы в таблице (например,
ему не нужны домашние телефоны сотрудников), то правильнее будет создать
представление или хранимую процедуру, которые будут отфильтровывать ненужные
столбцы.
Задание для самостоятельной работы:
Создайте логин SQL Server «Admin» и назначьте ей
роль sysadmin;
Создайте в базе данных роль «Saler» и назначьте
ей разрешения на выборку данных из всех таблиц, изменение данных в таблицах
Order, OrdItem и запуск хранимой процедуры spr_getOrders;
Создайте логин SQL Server «Ivanov» и сопоставьте
его с одноименным пользователем в базе данных Sales. Назначьте созданному
пользователю роль Saler.